






FGSM
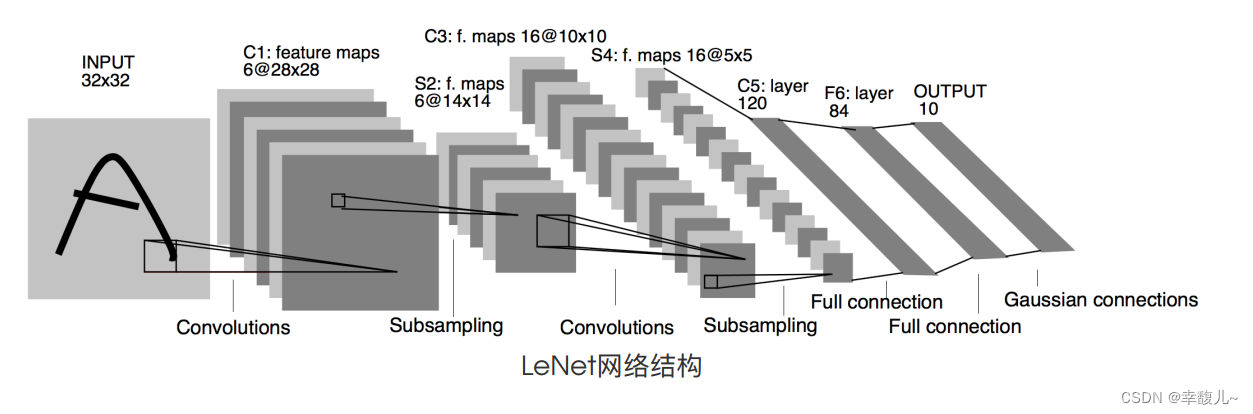
先训练一个神经网络的模型 LeNet
下载数据集并可视化
# 这句话的作用:即使是在Python2.7版本的环境下,print功能的使用格式也遵循Python3.x版本中的加括号的形式
from __future__ import print_function
import torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
from torch import nn
#加载数据集
mnist_train=torchvision.datasets.MNIST(root='datasets',train=True,download=True,transform=torchvision.transforms.ToTensor())
mnist_test=torchvision.datasets.MNIST(root='datasets',train=False,download=True,transform=torchvision.transforms.ToTensor())
# print(len(mnist_train))60000
# print(len(mnist_test))10000
imgs,target=mnist_train[0]
# print(feature.shape,label)打印图像大小torch.Size([1, 28, 28]),标签5
dataloader=DataLoader(mnist_test,batch_size=64,num_workers=0)#每次加载64张,num_workers 参数是用于指定用于数据加载的子进程数量的参数
step=0
writer=SummaryWriter(log_dir='runs/mnist')#可视化,在terminal中注意使用绝对路径
for data in dataloader:
imgs,target=data
writer.add_images(tag='train',img_tensor=imgs,global_step=step)
step+=1
writer.close()
此处注意先激活环境,然后使用绝对路径

模型搭建
#定义lenet模型
from torch import nn
class LeNet(nn.Module):
def __init__(self):
super(LeNet,self).__init__()
self.model1=nn.Sequential(
nn.Conv2d(in_channels=1, out_channels=6, kernel_size=5, padding=2),
nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2),
nn.Conv2d(in_channels=6, out_channels=16, kernel_size=5),
nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2),
nn.Flatten(),
nn.Linear(in_features=16 * 5 * 5, out_features=120),
nn.Sigmoid(),
nn.Linear(120, 84),
nn.Sigmoid(),
nn.Linear(in_features=84, out_features=10)
)
def forward(self,x):
return self.model1(x)
# leNet=LeNet()
# print(leNet)

完整代码
# 这句话的作用:即使是在Python2.7版本的环境下,print功能的使用格式也遵循Python3.x版本中的加括号的形式
from __future__ import print_function
import torch.optim
import torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
from torch import nn
#加载数据集
mnist_train=torchvision.datasets.MNIST(root='datasets',train=True,download=True,transform=torchvision.transforms.ToTensor())
mnist_test=torchvision.datasets.MNIST(root='datasets',train=False,download=True,transform=torchvision.transforms.ToTensor())
dataloader_train=DataLoader(mnist_train,batch_size=64,num_workers=0)
dataloader_test=DataLoader(mnist_test,batch_size=64,num_workers=0)
#模型搭建
class LeNet(nn.Module):
def __init__(self):
super(LeNet,self).__init__()
self.model1=nn.Sequential(
nn.Conv2d(in_channels=1, out_channels=6, kernel_size=5, padding=2),
nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2),
nn.Conv2d(in_channels=6, out_channels=16, kernel_size=5),
nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2),
nn.Flatten(),
nn.Linear(in_features=16 * 5 * 5, out_features=120),
nn.Sigmoid(),
nn.Linear(120, 84),
nn.Sigmoid(),
nn.Linear(in_features=84, out_features=10)
)
def forward(self,x):
return self.model1(x)
#创建模型
leNet=LeNet()
#损失函数
loss_fn=nn.CrossEntropyLoss()
#优化器
learning_rate=1e-2
optimizer=torch.optim.Adam(leNet.parameters(),lr=learning_rate)
total_train_step=0#记录训练次数
epoch=10#训练次数
writer=SummaryWriter(log_dir='runs/LeNet')
#训练
for i in range(epoch):
print("-------第{}轮训练开始-------".format(i+1))
leNet.train()
train_loss=0
for data in dataloader_train:
imgs,target=data
outputs=leNet(imgs)
loss=loss_fn(outputs,target)
optimizer.zero_grad()
loss.backward()#反向传播
optimizer.step()#更新参数
total_train_step+=1
train_loss+=loss.item()
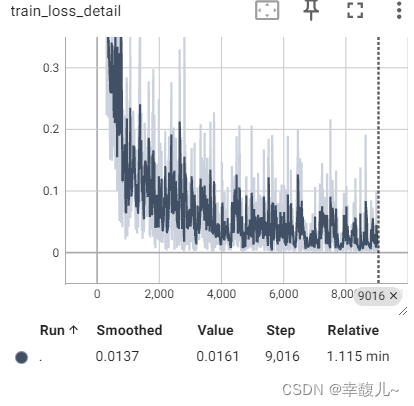
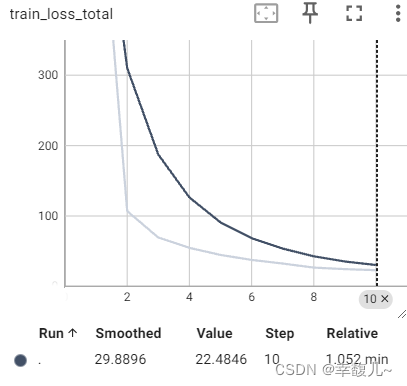
writer.add_scalar('train_loss_detail',loss.item(),total_train_step)
writer.add_scalar('train_loss_total',train_loss,i+1)
leNet.eval() # 测试模式
total_test_loss = 0 # 当前轮次模型测试所得损失
total_accuracy = 0 # 当前轮次精确率
with torch.no_grad(): # 关闭梯度反向传播
for data in dataloader_test:
imgs, targets = data
outputs = leNet(imgs)
loss = loss_fn(outputs, targets)
total_test_loss = total_test_loss + loss.item()
accuracy = (outputs.argmax(1) == targets).sum()
total_accuracy = total_accuracy + accuracy
writer.add_scalar("test_loss", total_test_loss, i + 1)
writer.add_scalar("test_accuracy", total_accuracy / len(mnist_test), i + 1)
torch.save(leNet,'models/LeNet.pth')#注意这里必须要手动建母文件models,否则会报错
# leNet=torch.load('./models/LeNet') 加载模型
writer.close()

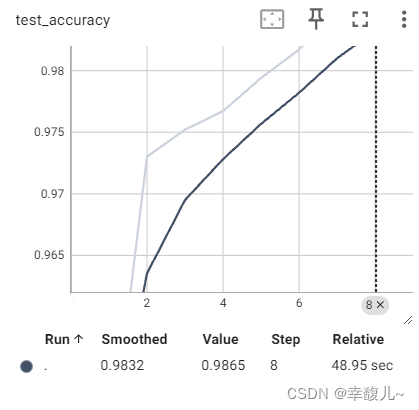
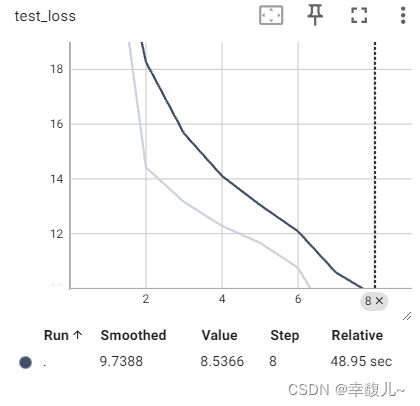
FGSM
剪切
在迭代更新过程中,随着迭代次数的增加,部分像素值可能会溢出。比如超出0到1 的范围,此时需将这些值用0或者1 代替,最后才能生成有效的图像。该过程确保了新样本的各个像素和在原样本各像素的某一邻域内,不至于失真。
import numpy as np
import torch.utils.data
from torch import nn
from torchvision import datasets, transforms
import torch.nn.functional as F
import matplotlib.pyplot as plt
import os
os.environ['KMP_DUPLICATE_LIB_OK']='TRUE'
epsilons=[0,.05,.1,.15,.2,.25,.3]
pretrained_model='models/LeNet.pth'
test_loader=torch.utils.data.DataLoader(
datasets.MNIST('datasets/MNIST',train=False,download=True,transform=transforms.ToTensor()),
batch_size=1,
shuffle=True#是否对训练数据进行洗牌的操作
)
#定义网络模型
class LeNet(nn.Module):
def __init__(self):
super(LeNet,self).__init__()
self.model1=nn.Sequential(
nn.Conv2d(1,6,5,2),
nn.Sigmoid(),
nn.AvgPool2d(6,2),
nn.Conv2d(6,16,5,1),
nn.Sigmoid(),
nn.AvgPool2d(2,2),
nn.Flatten(),
nn.Linear(16*5*5,120),
nn.Sigmoid(),
nn.Linear(120,84),
nn.Sigmoid(),
nn.Linear(84,10)
)
def forward(self,x):
return self.model1(x)
model=torch.load('models/LeNet.pth')
# print(model)
#在评估模式下设置模型
model.eval()
def fgsm_attack(image,epsilon,data_grad):
"""
:param image: 被攻击的图像
:param epsilon: 扰动值的范围
:param data_grad:图像的梯度
:return:扰动后的图像
"""
#收集数据梯度的元素符号
sign_data_grad=data_grad.sign()
#通过调整输入图像的每个像素来创建扰动图像
perturbed_image=image+epsilon*sign_data_grad
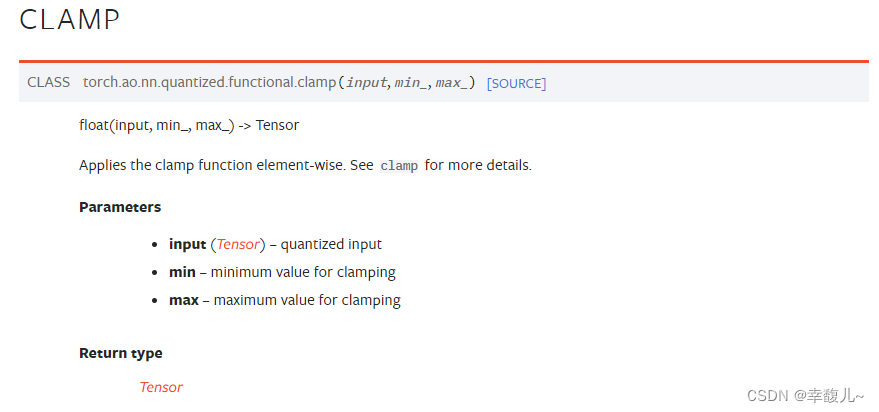
#添加剪切以维持【0,1】范围
perturbed_image=torch.clamp(perturbed_image,0,1)
return perturbed_image
#开始攻击
def test(model,test_loader,epsilon):
#计数器
correct=0
adv_examples=[]
#循环遍历测试集中的所有示例
for data,target in test_loader:
data.requires_grad=True#用于指示是否要对张量进行梯度运算
output=model(data)
init_pred=output.max(1,keepdim=True)[1]
#如果初始预测是错误的,不断地攻击
if init_pred.item()!=target.item():
continue
#计算损失
loss=F.nll_loss(output,target)
model.zero_grad()
loss.backward()
data_grad=data.grad.data
perturbed_data=fgsm_attack(data,epsilon,data_grad)#使用fgsm进行攻击
output=model(perturbed_data)#重新分类收到扰乱的图像
#检查是否成功
final_pred=output.max(1,keepdim=True)[1]
if final_pred.item()==target.item():
correct=correct+1
if(epsilon==1)and (len(adv_examples)<5):
adv_ex=perturbed_data.squeeze().detach().cpu().numpy()
adv_examples.append((init_pred.item(),final_pred.item(),adv_ex))
else:
#用于可视化
if len(adv_examples)<5:
adv_ex = perturbed_data.squeeze().detach().cpu().numpy()
adv_examples.append((init_pred.item(), final_pred.item(), adv_ex))
#计算该epsilon的最终准确度
final_acc=correct/float(len(test_loader))
print("Epsilon: {}\tTest Accuracy = {} / {} = {}".format(epsilon, correct, len(test_loader), final_acc))
return final_acc,adv_examples
accuracies=[]
examples=[]
#开始测试
for eps in epsilons:
acc,ex=test(model,test_loader,eps)
accuracies.append(acc)
examples.append(ex)
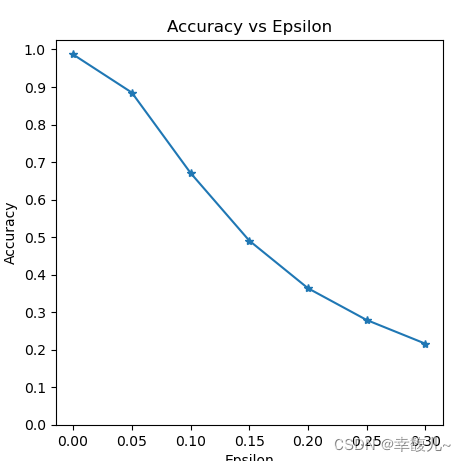
plt.figure(figsize=(5, 5))
plt.plot(epsilons, accuracies, "*-")
plt.yticks(np.arange(0, 1.1, step=0.1))
plt.xticks(np.arange(0, .35, step=0.05))
plt.title("Accuracy vs Epsilon")
plt.xlabel("Epsilon")
plt.ylabel("Accuracy")
plt.show()
# 在每个epsilon上绘制几个对抗样本的例子
cnt = 0
plt.figure(figsize=(8, 10))
for i in range(len(epsilons)):
for j in range(len(examples[i])):
cnt += 1
plt.subplot(len(epsilons), len(examples[0]), cnt)
plt.xticks([], [])
plt.yticks([], [])
if j == 0:
plt.ylabel("Eps: {}".format(epsilons[i]), fontsize=14)
orig, adv, ex = examples[i][j]
plt.title("{} -> {}".format(orig, adv))
plt.imshow(ex, cmap="gray")
plt.tight_layout()
plt.show()

















 1494
1494











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









