







NO.5 CORRECT TEXT(第五题 正确文本)
Problem Scenario 13 : You have been given following mysql database details as well as other info.(问题场景13:已经提供了以下mysql数据库详细信息和其他信息)
user=retail_dba
password=cloudera
database=retail_db
jdbc URL = jdbc:mysql://quickstart:3306/retail_db
Please accomplish following.(请完成如下任务)
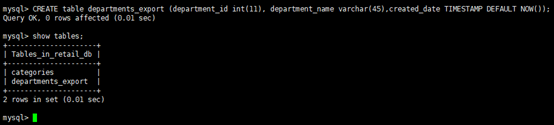
1. Create a table in retailedb with following definition.(在retailedb中创建具有以下定义的表)
CREATE table departments_export (department_id int(11), department_name varchar(45),created_date TIMESTAMP DEFAULT NOW());
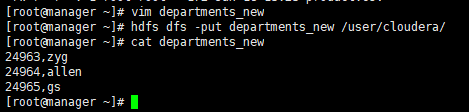
2. Now import the data from following directory into departments_export table,(现在将以下目录中的数据导入到departments_export表中)
/user/cloudera/departments_new
Answer:(答)
See the explanation for Step by Step Solution and configuration.(请参阅逐步解决方案和配置的说明)
Explanation:(说明)
Solution :(解决方案)
Step 1 : Login to musql db(登录MySQL数据库)
mysql –u retail_dba –p’cloudera’
show databases;
use retail_db;
show tables;

Step 2 : Create a table as given in problem statement.(按照问题陈述中的说明创建一个表)
CREATE table departments_export (department_id int(11), department_name varchar(45),created_date TIMESTAMP DEFAULT NOW());
show tables;
Step 3 : Export data from /user/cloudera/departments_new to new table departments_export (将数据从/user/cloudera/departments_new导到表departments_export中)
| 造 数据:
|

sqoop export -connect jdbc:mysql://quickstart:3306/retail_db \
--username retaildba \
--password cloudera \
--table departments_export \
-export-dir /user/cloudera/departments_new \
-batch
| sqoop export -connect jdbc:mysql://manager:3306/retail_db --username root \ --password yeexun123 \ --table departments_export \ -export-dir /user/cloudera/departments_new \ -batch 部分执行过程:
|


Step 4 : Now check the export is correctly done or not. (现在检查导出是否正确完成)
mysql –u retail_dba –p’cloudera’
show databases;
use retail _db;
show tables;
select * from departments_export;

NO.6 CORRECT TEXT(第六题 正确文本)
Problem Scenario 35 : You have been given a file named spark7/EmployeeName.csv(id,name).(问题场景35:您已获得一个名为spark7/EmployeeName.csv (id,name)文件)
EmployeeName.csv
E01,Lokesh
E02,Bhupesh
E03,Amit
E04,Ratan
E05,Dinesh
E06,Pavan
E07,Tejas
E08,Sheela
E09,Kumar
E10,Venkat
1. Load this file from hdfs and sort it by name and save it back as (id,name) in results directory.
However, make sure while saving it should be able to write In a single file.(从hdfs加载这个文件并按name排序,然后在results目录中将其另存为(id,name)。请确保在保存时能够在单个文件中写入)
Answer:(答)
See the explanation for Step by Step Solution and configuration.(请参阅逐步解决方案和配置的说明)
Explanation:(说明)
Solution:(解决方案)
Step 1 : Create file in hdfs (We will do using Hue). However, you can first create in local filesystem and then upload it to hdfs.(在hdfs中创建文件(我们将使用HUE)。另外,您可以先在本地文件系统中创建文件,然后将其上传到hdfs)
| 使用HUE创建文件或目录,在线编辑文件步骤: 首先登录HUE界面,然后
我们把文件放到/user/cloudera目录下
复制以上内容,最后保存。 可以在hdfs上查看到:
或者在本地创建后,使用put命令上传: 1.vim EmployeeName.csv 2.hdfs dfs –put EmployeeName.csv /user/cloudera/ 我这里就不演示了,因为已经使用HUE创建好了。 |







Step 2 : Load EmployeeName.csv file from hdfs and create PairRDDs(从hdfs加载EmployeeName.csv文件并创建pairdds)
val name = sc.textFile("spark7/EmployeeName.csv")
val namePairRDD = name.map(x=> (x.split(",")(0),x.split(",")(1)))
Step 3 : Now swap namePairRDD RDD.(现在交换namePairRDD RDD)
val swapped = namePairRDD.map(item => item.swap)
step 4: Now sort the rdd by key.(现在按key对rdd进行排序)
val sortedOutput = swapped.sortByKey()
Step 5 : Now swap the result back(现在把结果换回来)
val swappedBack = sortedOutput.map(item => item.swap)
Step 6 : Save the output as a Text file and output must be written in a single file.(将输出保存为文本文件,输出必须写入单个文件)
swappedBack. repartition(1).saveAsTextFile("spark7/result.txt")
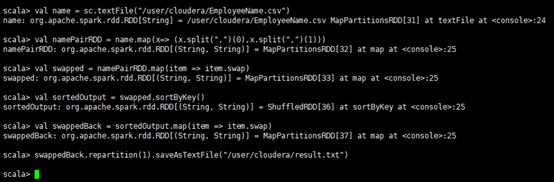
检查一下结果:

Spark仍然是新建了一个目录result.txt,然后在这个目录下把数据都保存在了part-00000文件中。但确实是把所有的文件合并生成一个part文件。可能题中的意思就是想要这样的结果吧。

Spark的保存模式的设定注定了在保存数据的时候只能新建目录,如果想把数据增加到原有的目录中,单独作为一个文件,就只能借助于Hadoop的HDFS操作(后续讲解spark时再介绍)。

















 2286
2286











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











