







NO.7 CORRECT TEXT(第七题 正确文本)
Problem Scenario 89 : You have been given below patient data in csv format,patientID,name,dateOfBirth,lastVisitDate(您已收到以下csv格式的患者数据,包括:患者ID,患者名字,患者出生日期,最后拜访日期)
1001,Ah Teck,1991-12-31,2012-01-20
1002,Kumar,2011-10-29,2012-09-20
1003,Ali,2011-01-30,2012-10-21
Accomplish following activities.(完成以下活动)
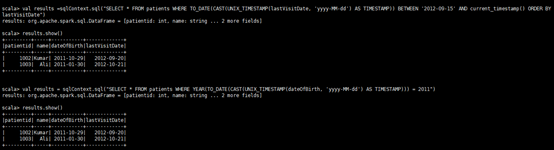
1 . Find all the patients whose lastVisitDate between current time and '2012-09-15'(查找lastVisitDate 在当前时间和'2012-09-15'之间的所有患者)
2 . Find all the patients who born in 2011(查找出生在2011年的患者)
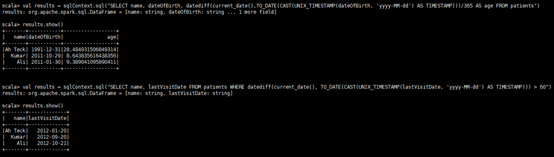
3 . Find all the patients age(查找所有患者的年龄)
4 . List patients whose last visited more than 60 days ago(列出最近一次就诊时间超过60天的患者)
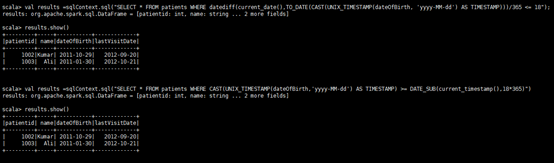
5 . Select patients 18 years old or younger(选出18岁或18岁以下的患者)
Answer:(答)
See the explanation for Step by Step Solution and configuration.(请参阅逐步解决方案和配置的说明)
Explanation:(说明)
Solution :(解决方案)
Step 1:数据准备
hdfs dfs -mkdir sparksql3
hdfs dfs -put patients.csv sparksql3/
我这里为了方便目录管理,与考试环境不一样(练习的时候目录自定义即可)

Step 2 : Now in spark shell(现在使用命令spark-shell命令开启窗口)
// SQLContext entry point for working with structured data
//用于处理结构化数据的SQLContext入口
val sqlContext = new org.apache.spark.sql.SQLContext(sc)
// this is used to implicitly convert an RDD to a DataFrame.
//这用于隐式地将RDD转换为DataFrame
import sqlContext.implicits._
// Import Spark SQL data types and Row.
//导入Spark SQL数据类型和行
import org.apache.spark.sql._
// load the data into a new RDD
//将数据加载到新的RDD中
val patients = sc.textFile("/user/cloudera/sparksql3/patients.csv")
// Return the first element in this RDD
//返回此RDD中的第一个元素
patients.first()
//define the schema using a case class
//使用case类定义模式
case class Patient(patientid: Integer, name: String, dateOfBirth:String , lastVisitDate:String)
// create an RDD
//创建RDD
val patRDD = patients.map(_.split(",")).map(p => Patient(p(0).toInt,p(1),p(2),p(3)))
patRDD.first()
patRDD.count()
// change RDD of Product objects to a DataFrame
//将RDD转换为DataFrame
val patDF = patRDD.toDF()
// register the DataFrame as a temp table
// 注册 DataFrame 作为临时表
patDF.registerTempTable("patients")
// Select data from table
//从表中筛选数据
val results = sqlContext.sql("SELECT * FROM patients")
// display dataframe in a tabular format
//展现结果
results.show()
//Find all the patients whose lastVisitDate between current time and '2012-09-15'
//查找lastVisitDate 在当前时间和'2012-09-15'之间的所有患者
val results =sqlContext.sql("SELECT * FROM patients WHERE TO_DATE(CAST(UNIX_TIMESTAMP(lastVisitDate, 'yyyy-MM-dd') AS TIMESTAMP)) BETWEEN '2012-09-15' AND current_timestamp() ORDER BY lastVisitDate")
results.show()
//Find all the patients who born in 2011
//查找出生在2011年的患者
val results = sqlContext.sql("SELECT * FROM patients WHERE YEAR(TO_DATE(CAST(UNIX_TIMESTAMP(dateOfBirth, 'yyyy-MM-dd') AS TIMESTAMP))) = 2011")
results. show()
//Find all the patients age
//查找所有患者的年龄
val results = sqlContext.sql("SELECT name, dateOfBirth, datediff(current_date(),TO_DATE(CAST(UNIX_TIMESTAMP(dateOfBirth, 'yyyy-MM-dd') AS TIMESTAMP)))/365 AS age FROM patients")
results.show()
//List patients whose last visited more than 60 days ago
//列出最近一次就诊时间超过60天的患者
val results = sqlContext.sql("SELECT name, lastVisitDate FROM patients WHERE datediff(current_date(), TO_DATE(CAST(UNIX_TIMESTAMP(lastVisitDate, 'yyyy-MM-dd') AS TIMESTAMP))) > 60")
results. show();
//Select patients 18 years old or younger
//选择18岁或18岁以下的患者
val results =sqlContext.sql("SELECT * FROM patients WHERE datediff(current_date(),TO_DATE(CAST(UNIX_TIMESTAMP(dateOfBirth, 'yyyy-MM-dd') AS TIMESTAMP)))/365 <= 18");
results. show();
(或者:
val results =sqlContext.sql("SELECT * FROM patients WHERE CAST(UNIX_TIMESTAMP(dateOfBirth,'yyyy-MM-dd') AS TIMESTAMP) >= DATE_SUB(current_timestamp(),18*365)")
results.show()
)
代码与结果如下:


在使用spark-shell命令启动交互窗口时,web UI:http://manager:4040

我们登录http://manager:4040,有兴趣的可以自己看一下

NO.8 CORRECT TEXT
Problem Scenario 40 : You have been given sample data as below in a file called spark15/file1.txt(问题场景40:在一个名为spark15/file1.txt的文件中提供了如下示例数据)
3070811,1963,1096,,"US","CA",,1,
3022811,1963,1096,,"US","CA",,1,56
3033811,1963,1096,,"US","CA",,1,23
Below is the code snippet to process this tile.(下面是处理此文件的代码段)
val field= sc.textFile("spark15/file1.txt")
val mapper = field.map(x=> A)
mapper.map(x => x.map(x=> {B})).collect
Please fill in A and B so it can generate below final output(请填写A和B,生成下面最终输出的结果)
Array(Array(3070811,1963,109G, 0, "US", "CA", 0,1, 0),Array(3022811,1963,1096, 0, "US", "CA", 0,1, 56),Array(3033811,1963,1096, 0, "US", "CA", 0,1, 23))
Answer:(答)
See the explanation for Step by Step Solution and configuration.
Explanation:(说明)
Solution :(解决方案)
A. x.split(",")
B. if (x.isEmpty) 0 else x
| 数据准备: 可以使用HUE在线创建/user/cloudera/file1.txt 或者使用:
代码与结果如下:
|

NO.9 CORRECT TEXT
Problem Scenario 46 : You have been given below list in scala (name,sex,cost) for each work done.( 问题场景46:在scala中为您列出了每项工作的清单(name,sex,cost))
List( ("Deeapak" , "male", 4000), ("Deepak" , "male", 2000), ("Deepika" , "female",
2000),("Deepak" , "female", 2000), ("Deepak" , "male", 1000) , ("Neeta" , "female", 2000))
Now write a Spark program to load this list as an RDD and do the sum of cost for combination of name and sex (as key)(现在编写一个Spark程序,以RDD的形式加载这个列表,并计算名称和性别(作为key)组合的成本之和)
Answer:(答)
See the explanation for Step by Step Solution and configuration.
Explanation:(说明)
Solution :(解决方案)
Step 1 : Create an RDD out of this list(创建一个RDD)
val rdd=sc.parallelize(List(("Deeapak","male",4000),("Deepak","male",2000),("Deepika","female",2000),("Deepak","female",2000),("Deepak","male",1000),("Neeta","female",2000)))
Step 2 : Convert this RDD in pair RDD(将此RDD转换为成对RDD)
val byKey = rdd.map({case (name,sex,cost) => (name,sex)->cost})
Step 3 : Now group by Key(现在按key分组)
val byKeyGrouped = byKey.groupByKey
Step 4 : Nowsum the cost for each group(现在把每组的费用加起来)
val result = byKeyGrouped.map{case ((id1,id2),values) => (id1,id2,values.sum)}
Step 5 : Save the results (保存结果)
result.repartition(1).saveAsTextFile("spark12/result.txt")

查看保存的内容:


















 366
366











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











