






RHS:https://github.com/acoboh/query-filter-jpa/blob/main/README.md
规则:
查询字段名:查询条件(条件值) 关系符 查询字段名:查询条件(条件值) ...
查询条件有:
‒ eq: 等于
‒ gt: 大于
‒ gte: 大于等于
‒ lt: 小于
‒ lte: 小于等于
‒ ne: 不等于
‒ cn: 包含
‒ ncn: 不包含
‒ re: 正则
‒ sw: 以xxx开头
‒ ew: 以xxx结尾
关系符有:
‒ and: 与
‒ or: 或
排序:
在最后边使用 sort 关键字排序,如果逆序排序,就在字段前加个负号(-)。如:sort(a) 或者 sort(-a)
例:
有如下一个表:
id gene mid e10
1 abc1 23 12
2 test1 35 32
3 abc2 16 21
// 查询 gene = abc1
query = gene:eq(abc1)
得到:
abc1 23 12
虽然这样也能查出来,但是最好用下面这样的命令:
query = id:eq(1)
这样可以提高查询效率
// 查询 mid > 10 且 小于 20
query = mid:gt(10) and mid:lt(20)
得到:
abc2 16 21
// 查询 gene 包含 abc 并按 gene 顺序排序
query = gene:cn(abc) sort(gene)
得到:
abc1 23 12
abc2 16 21
// 查询 gene 包含 abc 并按 gene 逆序排序
query = gene:cn(abc) sort(-gene)
得到:
abc2 16 21
abc1 23 12
【注】不能任意使用空格 只能在两个元素之间使用空格。支持用括号()来表示优先级。
代码
点击查看代码
import re
import pandas as pd
from functools import lru_cache
class QueryManage:
"""Convert the query statement to pandas syntax"""
# operate map
OPR_MAP = {
"eq": lambda x, y: f"['{x}']=={y}",
"gt": lambda x, y: f"['{x}']>{y}",
"gte": lambda x, y: f"['{x}']>={y}",
"lt": lambda x, y: f"['{x}']<{y}",
"lte": lambda x, y: f"['{x}']<={y}",
"ne": lambda x, y: f"['{x}']!={y}",
"cn": lambda x, y: f"['{x}'].str.contains('{y}')",
"ncn": ("~", lambda x, y: f"['{x}'].str.contains('{y}')"),
"sw": lambda x, y: f"['{x}'].str.contains(r'^{y}')",
"ew": lambda x, y: f"['{x}'].str.contains(r'{y}$')",
# 're': '',
}
# relationship map
RLP_MAP = {"and": "&", "or": "|"}
# sort
SORT = lambda x: (
f"sort_values('{x.replace('-', '')}',ascending=False)"
if "-" in x
else f"sort_values('{x}')"
)
# pattern filter field
# PFF = re.compile(f"(?P<field>(\w+)):(?P<operate>(\w+))\((?P<value>(\w+))\)")
PFF = re.compile(
f"(?P<leftParen>(^\(*))(?P<field>(\w+)):(?P<operate>(\w+))\((?P<value>(\w+))\)(?P<rightParen>(\)*$))"
)
# pattern filter sort
PFS = re.compile(r"sort\((-*\w+)\)")
def __init__(self, resource: pd.DataFrame):
self.resource = resource
def _validCheck(self, condition: list):
assert condition[-1] not in self.__class__.RLP_MAP, ValueError("query invalid")
def _parse(self, condition: list):
cond = ""
sort = ""
switch = False
for elem in condition:
switch = not switch
if switch:
patRes = self.__class__.PFF.match(elem)
assert patRes, ValueError("query invalid")
if patRes.group("leftParen"):
cond += "("
opr = self.__class__.OPR_MAP.get(patRes.group("operate"))
assert opr, ValueError(f"invalid operate {patRes.group('operate')}")
if isinstance(opr, tuple):
sign, opr_ = opr
cond += f"({sign}self.resource{opr_(patRes.group('field'), patRes.group('value'))})"
else:
cond += f"(self.resource{opr(patRes.group('field'), patRes.group('value'))})"
if patRes.group("rightParen"):
cond += ")"
else:
rlp = self.__class__.RLP_MAP.get(elem.lower())
if rlp:
cond += rlp
else:
# sort field
fs = self.__class__.PFS.findall(elem)
assert fs, ValueError("query invalid")
sort = self.__class__.SORT(fs[0])
return cond, sort
@lru_cache(maxsize=10)
def query(self, condition: str):
try:
cond = condition.strip().split(" ")
self._validCheck(cond)
cond, sort = self._parse(cond)
print("cond: ", cond, sort)
return (
eval(f"self.resource[{cond}].{sort}")
if sort
else eval(f"self.resource[{cond}]")
)
except AttributeError:
raise ValueError("query invalid")
if __name__ == "__main__":
df = pd.DataFrame({"a": [1, 2, 3, 4, 5], "b": ["abc", "bcd", "cfg", "adv", "ecf"]})
qm = QueryManage(df)
# a==2
res = qm.query("a:eq(2)")
print("a==2 :\n", res)
# a==2 or a==4
res = qm.query("a:eq(2) or a:eq(4)")
print("a==2 or a==4 :\n", res)
# b.contains('b') and a==1
res = qm.query("b:cn(b) and a:eq(1)")
print("b.contains('b') and a==1 :\n", res)
# ~b.contains('a')
res = qm.query("b:ncn(a)")
print("~b.contains('a') :\n", res)
# a>1 sort(-a)
res = qm.query("a:gt(1) sort(-a)")
print("a>1 sort(-a) :\n", res)
# (a ==1 or a==3) and b.contains('f')
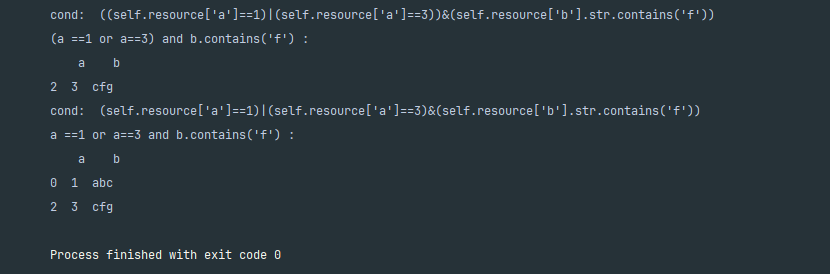
res = qm.query("(a:eq(1) or a:eq(3)) and b:cn(f)")
print("(a ==1 or a==3) and b.contains('f') :\n", res)
# a ==1 or a==3 and b.contains('f')
res = qm.query("a:eq(1) or a:eq(3) and b:cn(f)")
print("a ==1 or a==3 and b.contains('f') :\n", res)
# b.startwith(a)
res = qm.query("b:sw(a)")
print("b.startwith(a) :\n", res)
# b.endwith(c)
res = qm.query("b:ew(c)")
print("b.endwith(c) :\n", res)执行结果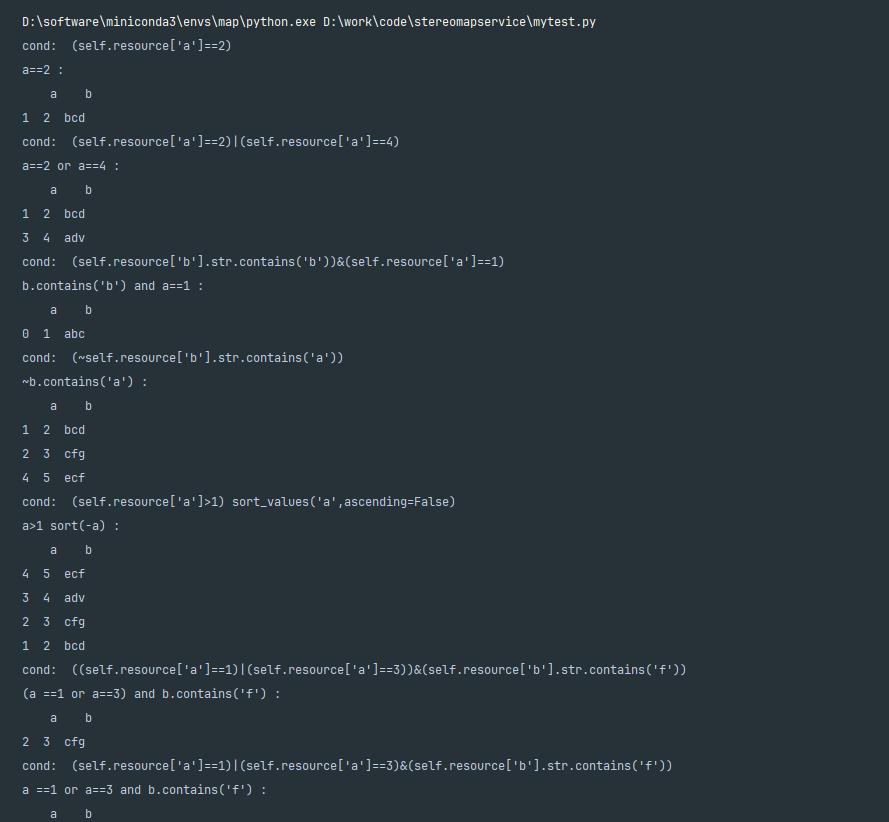















 3198
3198

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









