







文章目录
Redis有 5 种基础数据结构,分别为: String(字符串)、List(列表)、Hash(字典)、 Set (集合)和 Zset (有序集合)
String
- Redis 所有的数据结构都以唯一的 key 字符串作为名称,然后通过这个唯一 key 值来获取相应的 value 数据。
- Redis 的字符串是动态字符串,是可以修改的字符串,内部结构的实现类似于 Java 的 ArrayList,采用预分配冗余空间的方式来减少内存的频繁分配。内部为当前字符串分配的实际空间 capacity 一般要高于实际字符串长度 len。当字符串长度小于 1MB 时,扩容都是加倍现有的空问。如果字符串长度超过 1MB,扩容时一次只会多扩 1MB 的空间。需要注意的是字符串最大长度为 512MB。
- 字符串由多个字节组成,每个字节又由 8 个 bit 组成,如此可以将一个字符串看成很多 bit 的组合,即 bitmap(位图)数据结构。
应用场景
- 缓存用户信息,将用户信息结构体使用 JSON 序列化成字符串,然后将序列化后的字符串塞进 Redis 来缓存。
常用命令
- expire
对 key 设置过期时间,到时间会被自动删除。> set name quintin > expire name 5 # 5s 后自动过期 > setex name 5 quintin # 5s 后过期,等价于 set+expire - setnx
如果 key 不存在就执行 set 创建。若已存在,则创建不成功。> setnx name quintin - incr
如果 value 是一个整数,还可以对它进行自增操作。范围是在 signed long 的最大值和最小值之间,超出了这个范围,Redis 会报错。> set age 30 > incr age
List
- Redis 的列表相当于 Java 语言里面的 LinkedList,list 的插入和删除操作非常快,时间复杂度为 O(1),但是索引定位很慢,时间复杂度为 O(n)。
- 列表中的每个元素都使用双向指针顺序,串起来可以同时支持前向后向遍历。当列表弹出了最后一个元素之后,该数据结构被自动删除,内存被回收。
- Redis 底层存储的不是一个简单的 Linkedlist,而是称之为“快速链表”(quicklist)的一个结构。首先在列表元素较少的情况下,会使用一块连续的内存存储,这个结构是 ziplist,即压缩列表。它将所有的元素彼此紧挨着一起存储,分配的是一块连续的内存。当数据量比较多的时候才会改成 quicklist。因为普通的链表需要的附加指针空问太大,会浪费空间,还会加重内存的碎片化,比如某普通链表里存的只是 int 类型的数据,结构上还需要两个额外的指针 prev 和 next。所以 Redis 将链表和 ziplist 结合
起来组成了quicklist,也就是将多个 ziplist 使用双向指针串起来使用。quicklist 既满足了快速的插入删除性能,又不会出现太大的空间冗余。

应用场景
- Redis 的列表结构常用来做异步队列使用。将需要延后处理的任务结构体序列化成字符串,塞进 Redis 的列表,另一个线程从这个列表中轮询数据进行处理。
常用命令
List 可以模拟数组、队列和栈(吃多了拉是队列,吃多了吐是栈)。
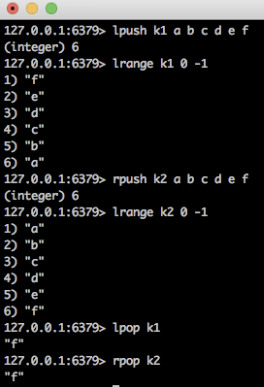
- lpush、lpop
同向命令模拟栈(后进先出) - lpush、rpop
反向命令模拟队列(先进先出),常用于消息排队和异步逻辑处理。它可以确保元素的访问顺序性。
- lindex、lset
模拟数组
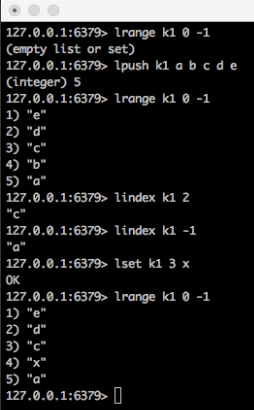
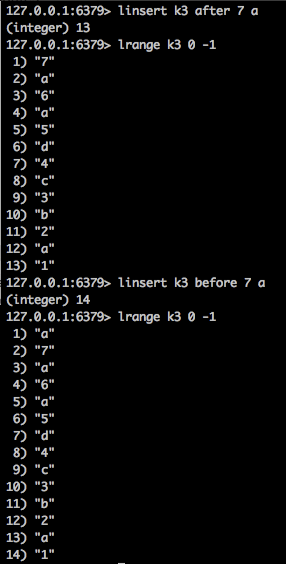
- linsert
在列表的元素前或者后插入元素。当指定元素不存在于列表中时,不执行任何操作。
当列表不存在时,被视为空列表,不执行任何操作。
如果 key 不是列表类型,返回一个错误。
- lrem
根据参数 COUNT 的值,移除列表中与参数 VALUE 相等的元素。- count > 0 : 从表头开始向表尾搜索,移除与 VALUE 相等的元素,数量为 COUNT 。
- count < 0 : 从表尾开始向表头搜索,移除与 VALUE 相等的元素,数量为 COUNT 的绝对值。
- count = 0 : 移除表中所有与 VALUE 相等的值

- ltrim
删除区间之外的值,保留区间内的值redis 127.0.0.1:6379> RPUSH mylist "hello" (integer) 1 redis 127.0.0.1:6379> RPUSH mylist "hello" (integer) 2 redis 127.0.0.1:6379> RPUSH mylist "foo" (integer) 3 redis 127.0.0.1:6379> RPUSH mylist "bar" (integer) 4 redis 127.0.0.1:6379> LTRIM mylist 1 -1 OK redis 127.0.0.1:6379> LRANGE mylist 0 -1 1) "hello" 2) "foo" 3) "bar" - blpop
移出并获取列表的第一个元素, 如果列表没有元素会阻塞列表直到等待超时或发现可弹出元素为止。
Hash
- <Key,<Key,Value>>
- Redis 的字典相当于 Java 语言里面的 HashMap,是无序字典,内部存储了很多键值对。实现结构上与 Java 的 HashMap 也是一样的,都是“数组 + 链表”的二维结构。发生 hash 碰撞时,采用「拉链法」将碰撞的元素使用链表串接起来。关于 HashMap 解决 Hash 冲突的原理可以移步博主的浅析JAVA集合框架之HashMap。
- 因为Java 的 HashMap,在字典很大时,rehash 是个耗时的操作,需要一次性rehash。 Redis 为了追求高性能,不能堵塞服务,所以采用了渐进式 rehash 策略。
- 渐进式 rehash 会在 rehash 的同时,保留新旧两个 hash 结构,查询时会同时查询两个 hash 结构,然后在后续的定时任务以及 hash 操作指令中,循序渐进地将旧 hash 的内容一点点地迁移到新的 hash 结构中。当搬迁完成了,就会新的 hash 结构取而代之。当 hash 移除了最后一个元素之后,该数据结构被自动删除,内存被回收。

应用场景
- hash 结构也可以用来存储用户信息,与字符串需要一次性全部序列化整个对象不同,hash 可以对用户结构中的每个字段单独存储。这样当我们需要获取用户信息时可以进行部分获取。而以整个字符串的形式去保存用户信息的话,就只能一次性全部读取,这样就会浪费网络流量。hash 也有缺点,hash 结构的存储消耗要高于单个字符串。
- 电商网站内,统计一个商品被浏览的次数(hincrbyfloat)。
常用命令
- hset、hmset、hget、hkeys、hvals
现在有一个员工信息,姓名,年龄,性别,身高,体重。然后设计一个结构,将其存储于redis中。
使用 String:
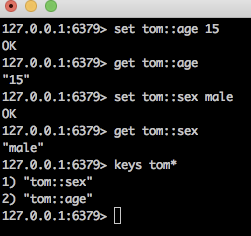
使用Hash:

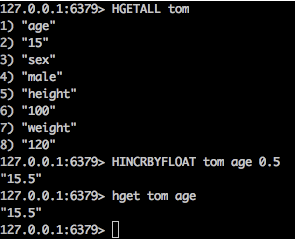
没有对比就没有伤害啊。 - hincrbyfloat
为哈希表中的字段值加上指定浮点数增量值。
如果指定的字段不存在,那么在执行命令前,字段的值被初始化为 0 。
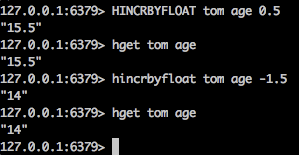
减法就加一个负数好咯。
Set
- Redis 的集合相当于 Java 语言里面的 Hashset, 它内部的键值对是无序的、唯一的。它的内部实现相当于一个特殊的字典,字典中所有的value 都是一个值 NULL。当集合中最后一个元素被移除之后,数据结构被自动删除,内存被回收。
- 有了 List 为什么还要有 Set 呢?
| 插入时是否有序 | 可否重复 | |
|---|---|---|
| List | 是 | 是 |
| Set | 否 | 否 |
应用场景
公司年会抽奖(srandmember)。
常用命令
-
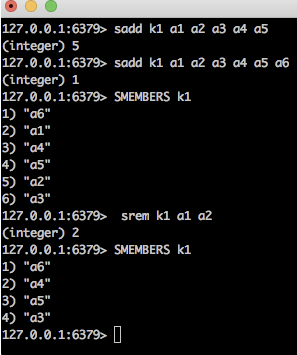
sadd
向集合添加一个或多个成员

-
sinter
返回给定所有给定集合的交集。 不存在的集合 key 被视为空集。 当给定集合当中有一个空集时,结果也为空集(根据集合运算定律)。

-
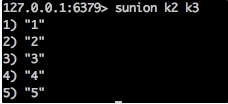
sunion
并集
-
sdiff
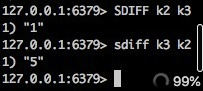
差集,第一个key的集合与后面所有key的集合的差集
-
srandmember
正数:取出一个去重的结果集(不能超过已有集)
负数:取出一个带重复的结果集(一定满足你的数量要求)
0:不返回
SRANDMEMBER 一个很经典的用法就是拿来抽奖。
正数:不能重复中奖
负数:可以重复中奖

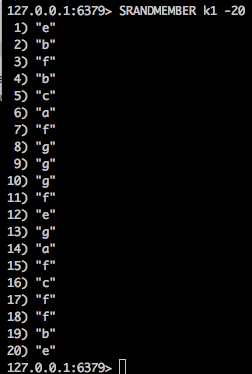
8个人分20个礼物,可以重复中奖 (礼物数 > 人数)
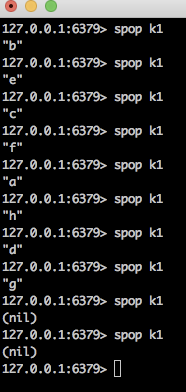
年会抽奖,1个1个抽,没人最多中一次
Sorted Set
- Sorted Sort 是有序的 Set。这里的有序指的是排序。因为 S 开头的命令被 Set 占了,所以 Sorted Set 的命令都是 Z 开头。
- 它类似于 Java 的 Sortedset 和 HashMap 的结合体,一方面它是一个 set,保证了内部 value 的唯一性,另一方面它可以给每个 value 赋予一个 score, 代表这个 value 的排序权重。它的内部实现用的是一种叫作「跳跃列表 」的数据结构。
- zset中最后一个 value 被移除后,数据结构被自动删除,内存被回收。
应用场景
- zset 可以用来存储粉丝列表,valve 值是粉丝的用户 ID,score 是关注时间。我们可以对粉丝列表按关注时间进行排序。
- zset 还可以用来存储学生的成绩,value 值是学生的 ID,score 是他的考试成绩。我们对成绩按分数进行排序就可以得到他的名次。
- 音乐APP中歌曲播放量排行榜。根据播放量倒叙排列(zunionstore)。
常用命令
- zadd

- zrange

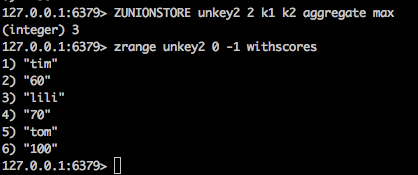
- zunionstore

- zrem
用于移除有序集中的一个或多个成员,不存在的成员将被忽略。
当 key 存在但不是有序集类型时,返回一个错误。
注意: 在 Redis 2.4 版本以前, ZREM 每次只能删除一个元素。# 测试数据 redis 127.0.0.1:6379> ZRANGE page_rank 0 -1 WITHSCORES 1) "bing.com" 2) "8" 3) "baidu.com" 4) "9" 5) "google.com" 6) "10" # 移除单个元素 redis 127.0.0.1:6379> ZREM page_rank google.com (integer) 1 redis 127.0.0.1:6379> ZRANGE page_rank 0 -1 WITHSCORES 1) "bing.com" 2) "8" 3) "baidu.com" 4) "9" # 移除多个元素 redis 127.0.0.1:6379> ZREM page_rank baidu.com bing.com (integer) 2 redis 127.0.0.1:6379> ZRANGE page_rank 0 -1 WITHSCORES (empty list or set) # 移除不存在元素 redis 127.0.0.1:6379> ZREM page_rank non-exists-element (integer) 0
跳跃表(Skip List)
跳跃表是一种基于有序链表的扩展,简称跳表。
跳跃表插入节点流程
时间复杂度 O(logN)空间复杂度 O(N)
- 新节点和各层索引节点逐一比较,确定原链表的插入位置 O(logN)。
- 把新节点插入到原链表 O(1)。
- 利用抛硬币的随机方式,决定新节点是否提升为上一层索引。结果为“正”,则提升并继续抛硬币,结果为“负”则停止 O(logN)。
跳跃表删除节点流程
时间复杂度O(logN)
- 自上而下,查找第一次出现节点的索引,并逐层找到每一层对应的节点 O(logN)。
- 删除每一层查找的节点,如果该层只剩一个节点,删除一整个层(原链表除外) O(logN)。















 158
158











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









