







 本文详细介绍了Kafka的消息数据结构,包括消息头部、Key和Value,以及时间戳和位移(Offset)。此外,阐述了Topic和Partition的概念,解释了Partition如何通过位移确保消息的有序性。Kafka的副本机制,包括Leader和Follower Replicas,以及ISR(In-Sync Replicas)的重要性被深入探讨,强调了ISR在保证消息不丢失中的作用。最后,讨论了如何通过配置Partition数量来优化系统性能和高可用性。
本文详细介绍了Kafka的消息数据结构,包括消息头部、Key和Value,以及时间戳和位移(Offset)。此外,阐述了Topic和Partition的概念,解释了Partition如何通过位移确保消息的有序性。Kafka的副本机制,包括Leader和Follower Replicas,以及ISR(In-Sync Replicas)的重要性被深入探讨,强调了ISR在保证消息不丢失中的作用。最后,讨论了如何通过配置Partition数量来优化系统性能和高可用性。
先说一个题外话,就是 Kafka 名字的由来:
I thought that since Kafka was a system optimized for writing using a writer’s name would make sense. I had taken a lot of lit classes in college and liked Franz Kafka. Plus the name sounded cool for an open source project.
Kafka 三位原作者之一 Jay Kreps:因为Kafka 系统的写操作性能特别强,所以找个作家的名字来命名似乎是一个好主意。我在大学时上了很多文学课,非常喜欢 Franz Kafka。另外为开源项目起 Kafka 这个名字听上去很酷。
消息的数据结构
Kafka 中的消息格式由很多字段组成,其中的很多宇段都是用于管理消息的元数据字段,对用户来说是完全透明的。Kafka 消息格式共经历过 3 次变迁,它们被分别称为 VO、V1 和 V2 版本。V1 版本消息的完整格式如下图所示:
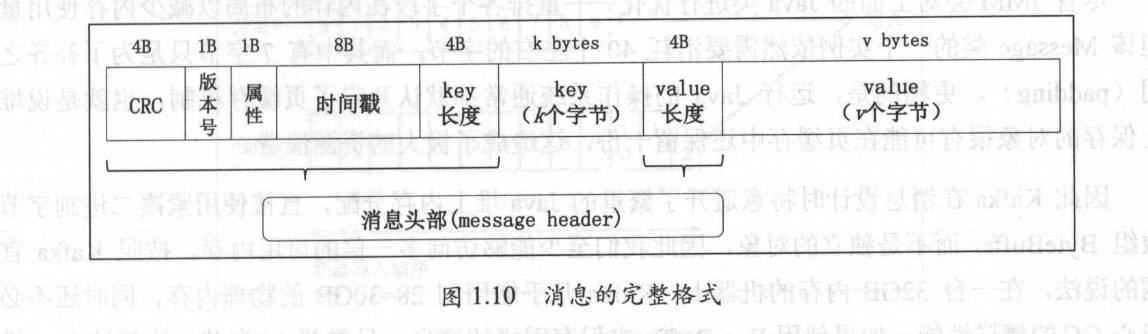
消息由消息头部、 key 和 value 组成。消息头部包括消息的 CRC 码、消息版本号、属性、时间戳、键长度和消息体长度等信息。
- Key:消息键,对消息做 partition 时使用,即决定消息被保存在某 topic 下的哪个 partition。
- Value:消息体,保存实际的消息数据。
- Timestamp:消息发送时间戳,用于流式处理及其他依赖时间的处理语义。如果不指定则取当前时间。
Kafka 为消息的属性字段分配了 1 字节 。 目前只使用了最低的 3 位用于保存消息的压缩类型,其余 5 位尚未使用。当前只支持 4 种压缩类型:0(无压缩)、1(GZIP)、2(Snappy)和 3(LZ4)。
Kafka 在消息设计时直接使用紧凑二进制字节数组 ByteBuffer。当出现 Kafka broker 进程崩溃时,堆内存上的数据也一并消失,但页缓存的数据依然存在。下次 Kafka broker 重启后可以继续提供服务。
topic 和 partition
topic 只是一个逻辑概念,代表了一类消息,也可以认为是消息被发送到的地方。通常我们可以使用 topic 来区分实际业务,比如业务 A 使用一个 topic,业务 B 使用另外一个 topic 。
Kafka 中的 topic 通常都会被多个消费者订阅,因此出于性能的考量,Kafka 并不是 topic-message 的两级结构,而是采用了 topic-partition-message 的三级结构来分散负载。从本质上说,每个 Kafka topic 都由若干个 partition 组成,如图下图所示。
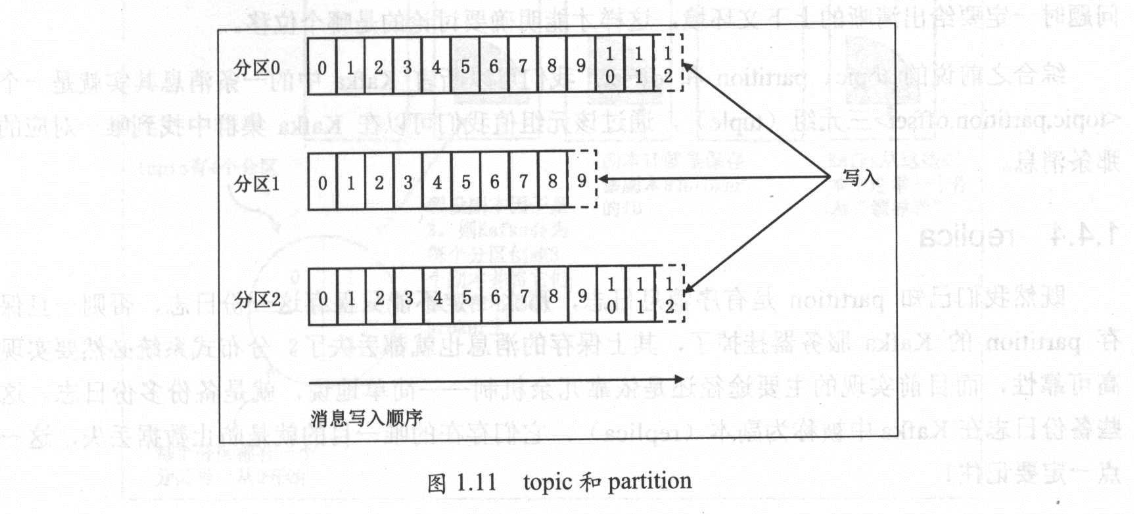
这张来自 Kafka 官网的 topic 和 partition 关系图非常清楚地表明了它们二者之间的关系:topic 是由多个 partition 组成的,而 Kafka 的 partition 是不可修改的有序消息序列,也可以说是有序的消息日志。每个 partition 有自己专属的 partition 号,通常是从 0 开始的。用户对 partition 唯一能做的操作就是在消息序列的尾部追加写入消息。partition 上的每条消息都会被分配一个唯一的序列号——按照 Kafka 的术语来讲,该序列号被称为位移(offset)。该位移值是从 0 开始顺序递增的整数。位移信息可以唯一定位到某 partition 下的一条消息。
Kafka 的 partition 实际上并没有太多的业务含义,它的引入就是单纯地为了提升系统的吞吐量,因此在创建 Kafka topic 的时候可以根据集群实际配置设置具体的 partition 数,实现整体性能的最大化。
位移(offset)
关于 offset,需要区分是消费者端的 offset 还是 topic partition 下的每条消息的位移。
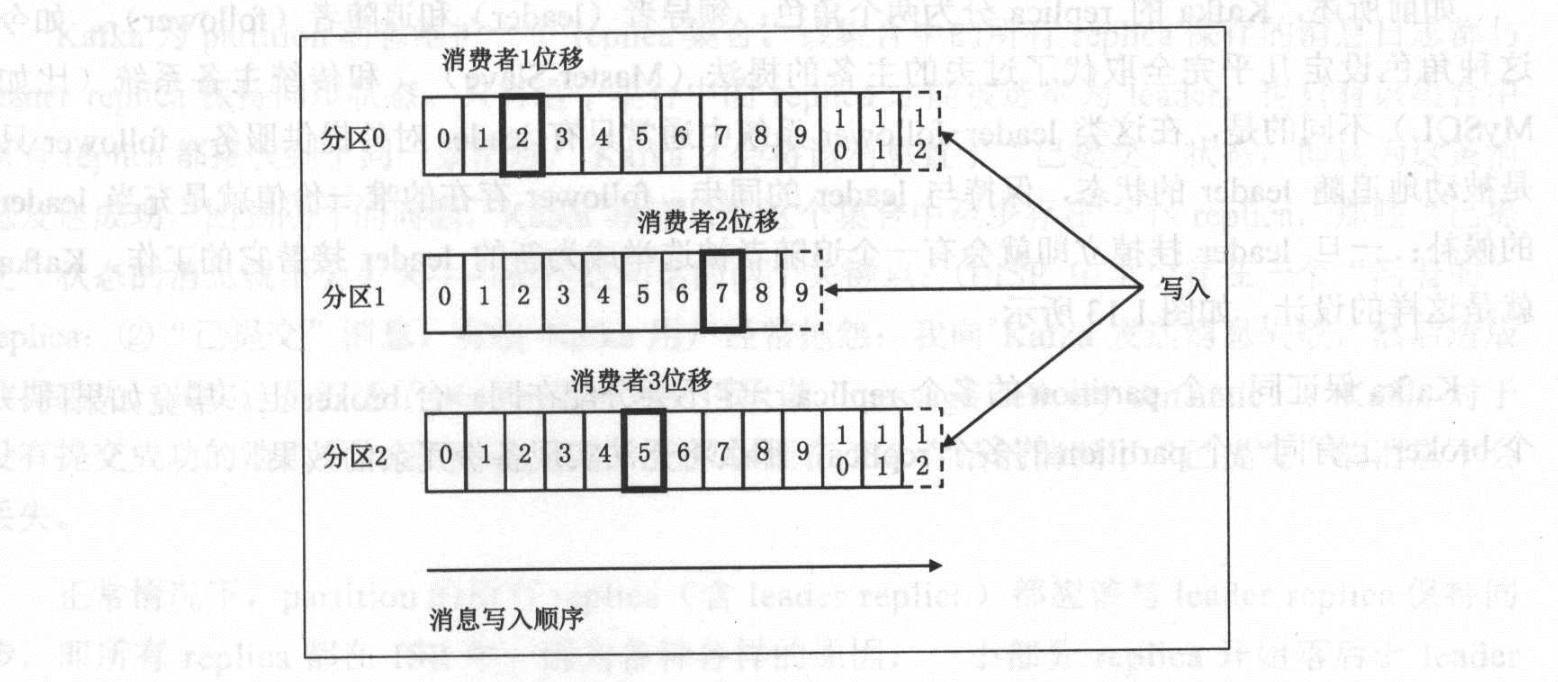
如上图所示,每条消息在某个 partition 的位移是固定的,但消费该 partition 的消费者的位移会随着消费进度不断前移,但终究不可能超过该分区最新一条消息的位移。
其实,Kafka 中的一条消息其实就是一个<topic,partition,offset>三元组(tuple),通过该元组值我们可以在 Kafka 集群中找到唯一对应的那条消息。
replica
我们已知 partition 是有序消息日志,那么一定不能只保存这一份日志,否则一旦保存 partition 的 Kafka 服务器挂掉了,其上保存的消息也就都丢失了。分布式系统必然要实现
高可靠性,而目前实现的主要途径还是依靠冗余机制——简单地说,就是备份多份日志。这
些备份日志在 Kafka 中被称为副本(replica),它们存在的唯一目的就是防止数据丢失。
副本分为两类:领导者副本(leader replica)和追随者副本(follower replica)。follower
replica 是不能提供服务给客户端的,也就是说不负责响应客户端发来的消息写入和消息消费请
求。它只是被动地向领导者副本(leader replica)获取数据,而一旦 leader replica 所在的
broker 宕机,Kafka 会从剩余的 replica 中选举出新的 leader 继续提供服务。
leader 和 follower
Kafka 的 replica 分为两个角色:领导者(leader)和追随者(follower)。和传统主备系统(比如 MySQL)不同的是,在这类 leader-follower 系统中通常只有 leader 对外提供服务,follower 只 是被动地追随 leader 的状态,保持与 leader 的同步。follower 存在的唯一价值就是充当 leader 的候补:一旦 leader 挂掉立即就会有一个追随者被选举成为新的 leader 接替它的工作。Kafka 就是这样的设计,如下图所示:
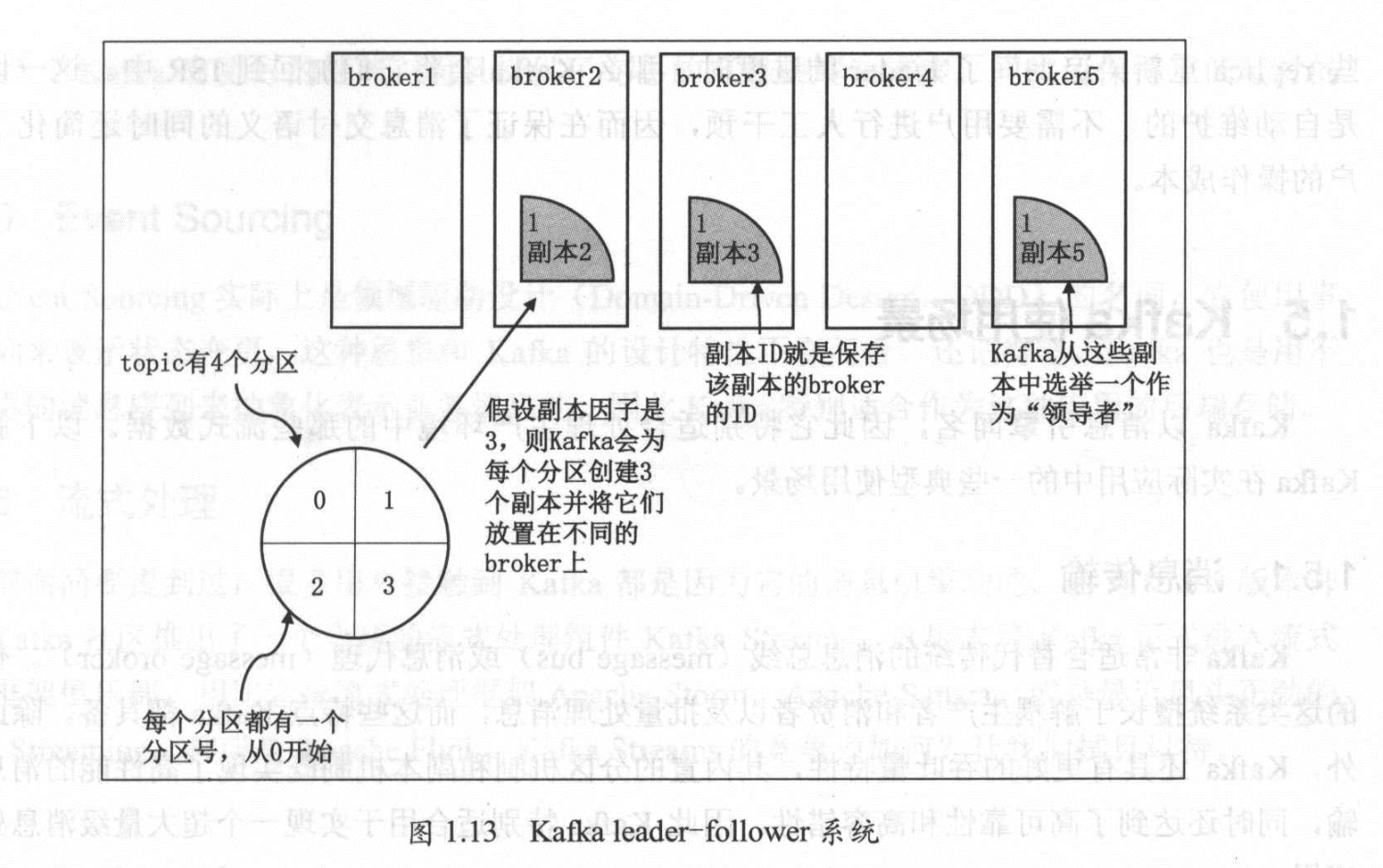
Kafka 保证同一个 partition 的多个 replica 一定不会分配在同一台 broker 上。毕竟如果同一个 broker 上有同一个 partition 的多个 replica,那么将无法实现备份冗余的效果。
ISR
ISR 的全称是 in-sync replica,翻译过来就是与 leader replica 保持同步的 replica 集合。这是一个特别重要的概念。前面讲了很多关于 Kafka 的副本机制,比如一个 partition 可以配置 N 个 replica,那么这是否就意味着该 partition 可以容忍 N-1 个 replica 失效而不丢失数据呢?答案是“否”!
Kafka 为 partition 动态维护一个 replica 集合。该集合中的所有 replica 保存的消息日志都与 leader replica 保持同步状态。只有这个集合中的 replica 才能被选举为 leader,也只有该集合中所有 replica 都接收到了同一条消息,Kafka 才会将该消息置于“已提交”状态,即认为这条消息发送成功。回到刚才的问题,Kafka 承诺只要这个集合中至少存在一个 replica,那些“已提交”状态的消息就不会丢失-记住这句话的两个关键点:
- ISR 中至少存在一个“活着的”replica;
- “已提交”消息。
有些 Kafka 用户经常抱怨:我向 Kafka 发送消息失败,然后造成数据丢失。其实这是混淆了 Kafka 的消息交付承诺(message delivery semantic):Kafka 对于没有提交成功的消息不做任何交付保证,它只保证在 ISR 存活的情况下“已提交”的消息不会丢失。
正常情况下,partition 的所有 replica(含 leader replica)都应该与 leader replica 保持同步,即所有 replica 都在 ISR 中。因为各种各样的原因,一小部分 replica 开始落后于 leader replica 的进度。当滞后到一定程度时,Kafka 会将这些 replica“踢”出 ISR。相反地,当这些 replica 重新“追上”了 leader 的进度时,那么 Kafka 会将它们加回到 ISR 中。这一切都是自动维护的,不需要用户进行人工干预,因而在保证了消息交付语义的同时还简化了用户的操作成本。

















 674
674

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









