







文章目录
事务需要保证原子性。 但是偏偏有时候事务在执行到一半时会出现一些情况,比如下面这些情况:
- 事务执行过程中可能遇到各种错误,比如服务器本身的错误、操作系统错误,甚至是突然断电导致的错误;
- 程序员可以在事务执行过程中手动输入 ROLLBACK 语句结束当前事务的执行。
这两种情况都会导致事务执行到一半就结束,但是事务在执行过程中可能已经修改了很多东西。为了保证事务的原子性,我们需要改回原来的样子,这个过程就称为回滚(rollback)。
这就造成了一个假象:这个事务看起来什么都没做,所以符合原子性要求(有时候仅需要对部分语句进行回滚,有时候需要对整个事务进行回滚)。
回滚的实现方式大致如下:
- INSERT:插入一条记录时,将这条记录的主键记录下来,回滚时根据这个主键删除即可。
- DELETE:删除一条记录时,将这条记录的内容记录下来,回滚时重新插入到表中即可。
- UPDATE:修改一条记录时,将被更新的列的旧值记录下来,回滚时将这些值更新回去即可。
这里需要注意的一点是,由于查询操作(SELECT)并不会修改任何用户记录,所以在执行查询操作时,并不需要记录相应的 undo 日志。MySQL 把这些为了回滚而记录的东西称为撤销日志 (undo log)。
undo 日志的格式
为了实现事务的原子性,InnoDB 存储引擎在实际进行记录的增删改操作时,都需要先把对应的 undo 日志记下来。一般每对一条记录进行一次改动,就对应着一条 undo 日志。但在某些更新记录的操作中,也可能会对应着 2 条 undo 日志。一个事务在执行过程中可能新增、删除、更新若干条记录,也就是说需要记录很多条对应的 undo 日志。这些 undo 日志会从 0 开始编号,也就是说根据生成的顺序分别称为第 0 号 undo 日志、第 1 号 undo 日志······第 n 号 undo 日志等。这个编号也称为 undo no。
这些 undo 日志被记录到类型为 FlL_PAGE_UNDO_LOG(对应的十六进制是 0x0002)的页面中。这些页面可以从系统表空间中分配,也可以从一种专门存放 undo 日志的表空间(undo tablespace)中分配。
INSERT 操作对应的 undo 日志

- end of record:下一条 undo 日志开始时在页面中的地址。
- undo type:日志类型,即 TRX_UNDO_INSERT_REC。
- undo no:日志编号,一个事务中,日志编号从 0 开始,只要事务没提交,每生成一条 undo 日志,该日志的 undo no 就增加 1。
- table id:本条 undo 日志对应的记录所在表的table id。
- 主键各列信息:主键的每个列占用的存储空间大小和真实值。
- start of record:上一条 undo 日志结束,本条开始时在页面中的地址。
在插入一条数据时,会向聚簇索引和所有二级索引都插入一条记录,但是 undo 日志只会记录一条针对聚簇索引的日志。聚簇索引记录和二级索引记录是一一对应的,回滚 INSERT 操作时,根据这条记录的主键信息进行对应的删除操作,把聚簇索引和二级索引中相应的记录都删掉。DELETE 和 UPDATE 操作同理,都是针对聚簇索引记录的改动来记录 undo 日志。
DELETE 操作对应的 undo 日志
删除一条记录的 2 个阶段
- 将记录的 deleted_ flag 标识位设置为 1。这个阶段称为 delete mark。此时记录既不是正常记录,也不是己删除记录,而是一个处于中间状态的记录。此时这条记录并没有加入到垃圾链表中。在删除语句所在的事务提交之前,被删除的记录一直都处于这种中间状态。中间状态是为了实现MVCC。

- 当该删除语句所在的事务提交之后,会有专门的线程来真正地把记录删除掉。即把该记录从正常记录链表中移除,并且加入到垃圾链表中。然后还要调整-些页面的其他信息,比如页面中的用户记录数量 PAGE_N_RECS、上次插入记录的位置 PAGE_LAST_INSERT、垃圾链表头节点的指针 PAGE_FREE、页面中可重用的字节数量 PAGE_GARBAGE。以及页目录的一些信息等。这个阶段称为 purge。
在阶段 2 执行完后,这条记录就算是真正地被删除掉了。这条己删除记录占用的存储空间也就可以重新利用了。
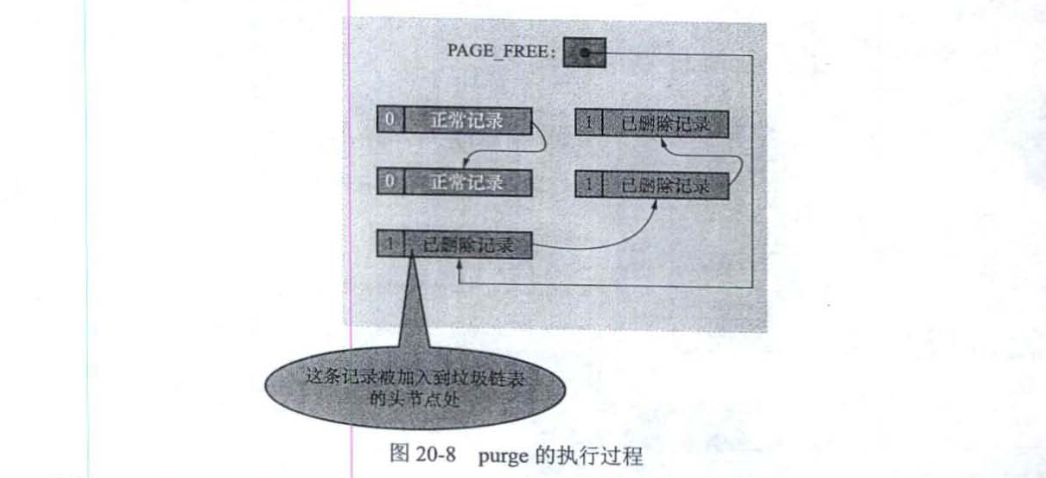
在执行一条删除语句的过程中,在删除语句所在的事务提交之前,只会经历 delete mark 阶段。而一旦事务提交,我们也就不需要再回滚这个事务了。 所以在设计 undo 日志时,只需要考虑对删除操作在阶段 1 所做的影响进行回滚就好了。下图是类型为 TRX_UNDO_DEL_MARK_REC 的 undo 日志的完整结构。

- 对一条记录进行 delete mark 操作前,需要把该记录的 trx_id 和 roll_pointer 隐藏列的旧值都记到对应的 undo 日志中的 trx_id 和 roll_pointer 属性中。这样就可以通过 undo 日志的 roll_pointer 属性找到上一次对该记录进行改动时产生的 undo 日志。比如在一个事务中,我们先插入了一条记录,然后又执行该记录的删除操作:
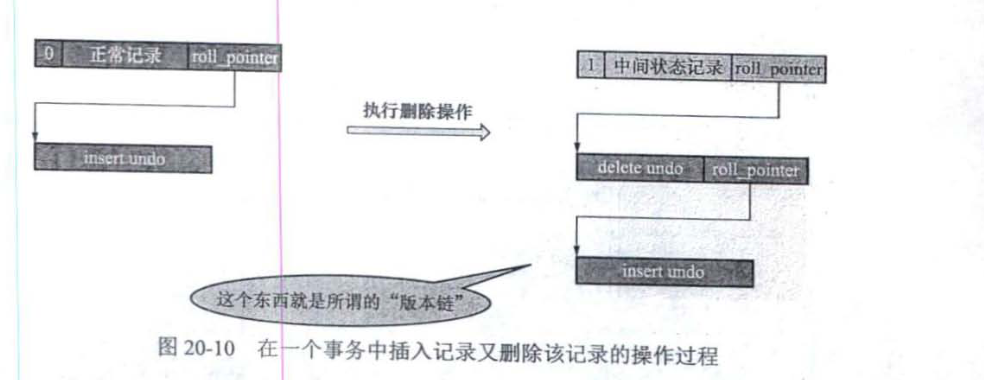
在执行完 delete mark 操作后,中间状态记录、 delete mark 操作产生的 undo 日志以及 INSERT 操作产生的 undo 日志就串成了一个链表。这个链表称为版本链。 - 与类型为 TRX_UNDO_INSERT_REC 的 undo 日志不同,类型为 TRX_UNDO_DEL_MARK_REC 的 undo 日志还多了一个索引列各列信息的内容。也就是说,如果某个列被包含在某个索引中,那么它的相关信息就应该记录到这个索引列各列的信息部分。所谓的“相关信息”包括该列在记录中的位置(用 pos 表示)、该列占用的存储空间大小(用 len 表示)、该列实际值(用 value 表示)。所以,索引列各列信息存储的内容实质上就是<pos,len,value>的一个列表。这部分信息主要在事务提交后使用,用来对中间状态的记录进行真正的删除(即在阶段 2,也就是 purge 阶段中使用)。
UPDATE 操作对应的 undo 日志
不更新主键
就地更新(in-place update)
在更新记录时,对于被更新的每个列来说,如果更新后的列与更新前的列占用的存储空间一样大,那么可以进行就地更新,也就是直接在原记录的基础上修改对应列的值。但是,只要有任何一个被更新的列在更新前比更新后占用的存储空间大,或者在更新前比更新后占用的存储空间小,就不能进行就地更新。
先删除旧记录,再插入新纪录
在不更新主键的情况下,如果有任何一个被更新的列在更新前和更新后占用的存储空间大小不一致,那么就需要先把这条旧记录从聚簇索引页面中删除,然后再根据更新后列的值创建一条新的记录并插入到页面中。
这里所说的删除并不是delete mark操作,而是真正地删除掉,也就是把这条记录从正常记录链表中移除并加入到垃圾链表中,并且修改页面中相应的统计信息(比如 PAGE_FREE、PAGE_GARBAGE 等信息)。不过,这里执行真正删除操作的线程并不是在 DELETE 语句
中进行 purge 操作时使用的专门的线程,而是由用户线程同步执行真正的删除操作。在真正删除之后,紧接着就要根据各个列更新后的值来创建一条新记录,然后把这条新记录插入到页面中。
如果新创建的记录占用的存储空间不超过旧记录占用的空间,那么可以直接重用加入到垃圾链表中的旧记录所占用的存储空间,否则需要在页面中新申请一块空间供新记录使用。如果本页面内已经没有可用的空间,就需要进行页面分裂操作,然后再插入新记录。
上述两种情况的 undo log 类型为 TRX_UNDO_UPD_EXIST_REC,如下图所示:
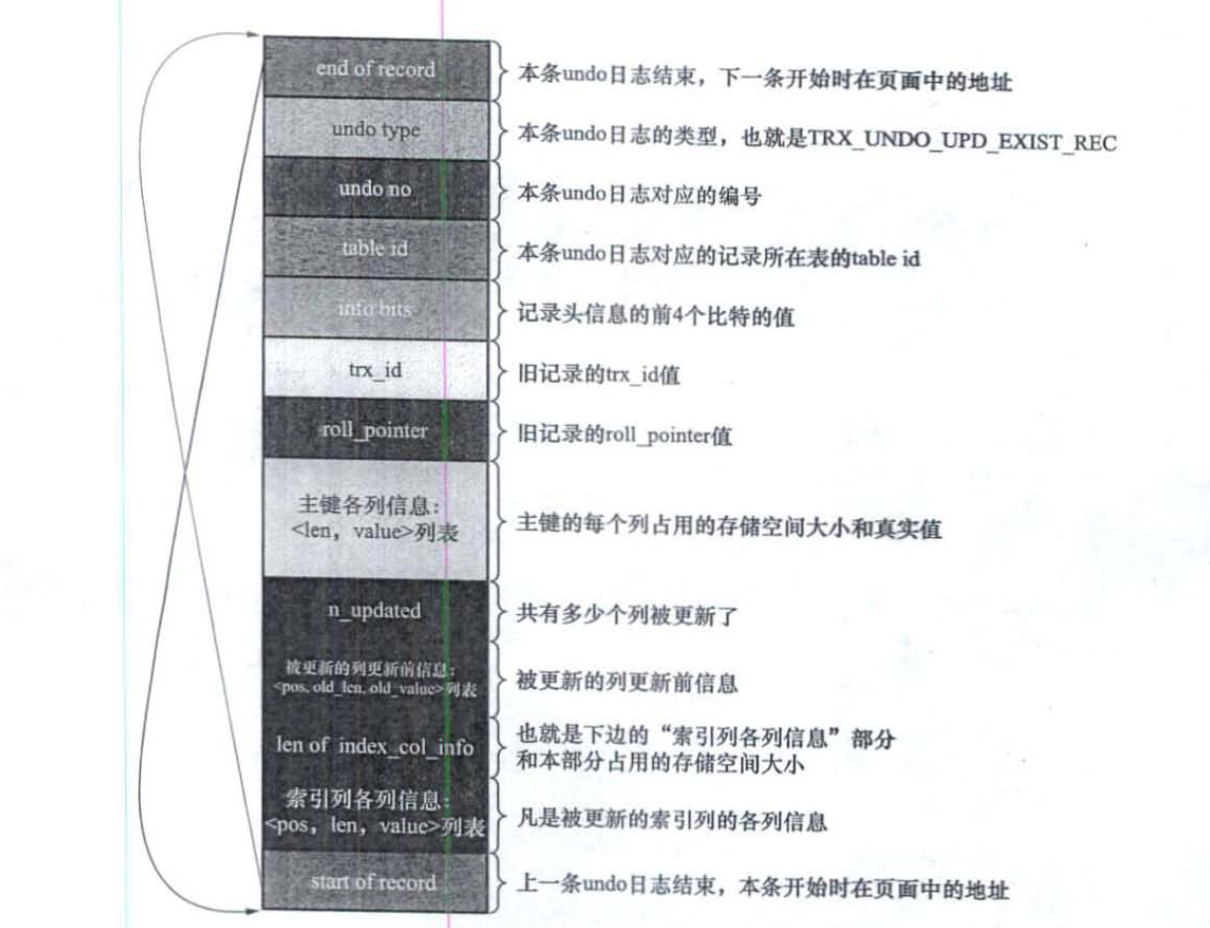
- n_updated 属性表示在本条 UPDATE 语句执行后将有几个列被更新,后边跟着的
<pos,old_len,old_value>列表中的 pos、old_len 和 old_value 分别表示被更新列在记录中的位置、更新前该列占用的存储空间大小、更新前该列的真实值。 - 如果在 UPDATE 语句中更新的列包含索引列,那么也会添加“索引列各列信息”这个部分,否则不会添加这个部分。
更新主键
若 UPDATE 语句更新了主键,则分为两步进行处理:
- 将旧记录进行 delete mark 操作。
在 UPDATE 语句所在的事务提交前,对旧记录只执行一个 delete mark 操作,在事务提交后才由专门的线程执行 purge 操作,从而把它加入到垃圾链表中。之所以只对旧记录执行 delete mark 操作,是因为别的事务也可能同时访问这条记录,如果把它真正删除并加入到垃圾链表后,别的事务就访问不到了。这个功能就是 MVCC。 - 根据更新后各列的值创建一条新纪录,并将其插入到聚簇索引中。
由于更新后的记录主键值发生了改变,所以需要重新从聚簇索引中定位这条记录所在位置,然后把它插进去。针对 UPDATE 语句更新记录主键值的这种情况,在对该记录进行
delete mark 操作时,会记录一条类型为 TRX_UNDO_DEL_MARK_REC 的 undo 日志;之后插入新记录时,会记录一条类型为 TRX_UNDO_INSERT_REC 的 undo 日志。也就是说,每对一条记录的主键值进行改动,都会记录 2 条 undo 日志。
增删改操作对二级索引的影响
一个表可以拥有一个聚簇索引以及多个二级索引,对于二级索引记录来说,INSERT 操作和 DELETE 操作与在聚簇索引中执行时产生的影响差不多,但是 UPDATE 操作稍微有点儿不同。如果我们的 UPDATE 语句中没有涉及二级索引的列,那么就不需要对二级索引执行任何操作。相反,如果在 UPDATE 语句中涉及了二级索引的列,由于这个语句涉及了 key1 列,而 key1 列又包含在二级索引 idx_key1 中,所以这相当于更新了二级索引的键值。更新了二级索引记录的键值,就意味着要进行下面这两个操作。
- 对旧的二级索引记录执行 delete mark 操作。
- 根据更新后的值创建一条新的二级索引记录,然后在二级索引对应的 B+树中重新定位到它的位置并插进去。
另外需要强调的一点是,虽然只有聚簇索引记录才有 trx_id、roll_pointer 这些属性,不过每当我们增删改一条二级索引记录时,都会影响这条二级索引记录所在页面的 Page Header 部分中一个名为 PAGE_MAX_TRX_ID 的属性。这个属性代表修改当前页的最大的事务 id。
为事务分配 Undo 页面链表的详细过程
我们以事务对普通表的记录进行改动为例,来梳理一下事务执行过程中分配 Undo 页面链表时的完整过程。
- 事务在执行过程中对普通表的记录进行首次改动之前,首先会到系统表空间的第 5 号页面中分配一个回滚段(其实就是获取一个 Rollback Segment Header 页面的地址)。一旦某个回滚段被分配给了这个事务,那么之后该事务再对普通表的记录进行改动时,就不会重复分配了。
使用传说中的 round-robin(循环使用)方式来分配回滚段。比如,当前事务分配了第 0 号回滚段,那么下一个事务就要分配第 33 号回滚段,再下一个事务就要分配第 34 号回滚段。简单来说就是这些回滚段被轮着分配给不同的事务。 - 在分配到回滚段后,首先看一下这个回滚段的两个 cached 链表有没有已经缓存的 undo slot。如果事务执行的是 INSERT 操作,就去回滚段对应的 insert undo cached 链表中看看有没有缓存的 undo slot;如果事务执行的是 DELETE 操作,就去回滚段对应的 update undo cached 链表中看看有没有缓存的 undo slot。如果有缓存的 undo slot,就把这个缓存的 undo slot 分配给该事务。
- 如果没有缓存的 undo slot 可供分配,那么就要到 Rollback Segment Header 页面中找一个可用的 undo slot 分配给当前事务。
- 找到可用的 undo slot 后,如果该 undo slot 是从 cached 链表中获取的,那么它对应的 Undo Log Segment 就已经分配了;否则需要重新分配一个 Undo Log Segment,然后从该 Undo Log Segment 中申请一个页面作为 Undo 页面链表的 first undo page,并把该页 的页号填入获取的 undo slot 中。
- 然后事务就可以把 undo 日志写入到上面申请的 Undo 页面链表中了。
对临时表的记录进行改动时,步骤与上面一样。不过需要再强调一次,如果一个事务在执行过程中既对普通表的记录进行了改动,又对临时表的记录进行了改动,那么需要为这个事务分配 2 个回滚段。并发执行的不同事务其实也可以被分配相同的回滚段,只要分配不同的 undo slot 就可以了。
undo 日志在崩溃恢复时的作用
在服务器因为崩溃而恢复的过程中,首先需要按照 redo log 将各个页面的数据恢复到崩溃之前的状态,这样可以保证已经提交的事务的持久性。但是这里仍然存在一个问题,就是那些没有提交的事务写的 redo 日志可能也已经刷盘,那么这些未提交的事务修改过的页面在 MySQL 服务器重启时可能也被恢复了。
为了保证事务的原子性,有必要在服务器重启时将这些未提交的事务回滚掉。那么,怎么找到这些未提交的事务呢?这个工作又落到了 undo 日志头上。
我们可以通过系统表空间的第 5 号页面定位到 128 个回滚段的位置,在每一个回滚段 的 1024 个 undo slot 中找到那些值不为 FIL_NULL 的 undo slot,每一个 undo slot 对应着个 Undo 页面链表。然后从 Undo 页面链表第一个页面的 Undo Segment Header 中找到 TRX_UNDO_STATE 属性,该属性标识当前 Undo 页面链表所处的状态。如果该属性的值为 TRX_UNDO_ACTIVE,则意味着有一个活跃的事务正在向这个 Undo 页面链表中写入 undo 日志。然后再在 Undo Segment Header 中找到 TRX_UNDO_LAST_LOG 属性,通过该属性可以找到本 Undo 页面链表最后一个 Undo Log Header 的位置。从该 Undo Log Header 中可以找到对应事务的事务 id 以及一些其他信息,则该事务 id 对应的事务就是未提交的事务。通过 undo 日志中记录的信息将该事务对页面所做的更改全部回滚掉,这样就保证了事务的原子性。
总结
为了保证事务的原子性,设计 InnoDB 的大叔引入了 undo 日志。undo 日志记载了回滚一个操作所需的必要内容。
在事务对表中的记录进行改动时,才会为这个事务分配一个唯一的trx_id。事务 id 值是一个递增的数字。先被分配 id 的事务得到的是较小的事务 id,后被分配 id 的事务得到的是较大的事务 id。未被分配事务 id 的事务的事务 id 默认是 0。聚簇索引记录中有一个 trx_id隐藏列,它代表对这个聚簇索引记录进行改动的语句所在的事务对应的事务 id。
InnoDB 针对不同的场景设计了不同类型的 undo 日志,比如 TRX_UNDO_INSERT_REC、TRX_UNDO_DEL_MARK_REC、TRX_UNDO_UPD_EXIST_REC 等。类型为 FIL_PAGE_UNDO_LOG 的页面是专门用来存储 undo 日志的,我们简称为 Undo 页面。
在一个事务执行过程中,最多分配 4 个 Undo 页面链表,分别是:
- 针对普通表的 insert undo 链表;
- 针对普通表的 update undo 链表;
- 针对临时表的 insert undo 链表;
- 针对临时表的 update undo 链表。
只有在真正用到这些链表的时候才去创建它们。
每个 Undo 页面链表都对应一个 Undo Log Segment。Undo 页面链表的第一个页面中有一个名为 Undo Log Segment Header 的部分,专门用来存储关于这个段的一些信息。
同一个事务向一个 Undo 页面链表中写入的 undo 日志算是一个组,每个组都以一个
Undo Log Header 部分开头。
一个 Undo 页面链表如果可以被重用,需要符合下面的条件:
- 该链表中只包含一个 Undo 页面;
- 该 Undo 页面已经使用的空间小于整个页面空间的 3/4。
每一个 Rollback Segment Header 页面都对应着一个回滚段,每个回滚段包含 1024 个 undo slot,一个 undo slot 代表一个 Undo 页面链表的第一个页面的页号。目前,InnoDB 最多支持 128 个回滚段,其中第 0 号、第 33~127 号回滚段是针对普通表设计的,第 1~32 号回滚段是针对临时表设计的。
我们可以选择将 undo 日志记录到专门的 undo 表空间中,在 undo 表空间中的文件大到一定程度时,可以自动将该 undo 表空间截断为小文件。















 1000
1000











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









