









Vision-Language Models are Zero-Shot Reward Models for Reinforcement Learning
@inproceedings{
rocamonde2024visionlanguage,
title={Vision-Language Models are Zero-Shot Reward Models for Reinforcement Learning},
author={Juan Rocamonde and Victoriano Montesinos and Elvis Nava and Ethan Perez and David Lindner},
booktitle={The Twelfth International Conference on Learning Representations},
year={2024},
url={https://openreview.net/forum?id=N0I2RtD8je}
}GitHub - AlignmentResearch/vlmrm
1. 环境配置
git clone https://github.com/AlignmentResearch/vlmrm.git
pip install -e ".[dev]"2. docker
(或者不用docker也可以的)
2.1 配置docker
sudo apt-get update
sudo apt-get install ca-certificates curl gnupg
sudo install -m 0755 -d /etc/apt/keyrings
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo gpg --dearmor -o /etc/apt/keyrings/docker.gpg
sudo chmod a+r /etc/apt/keyrings/docker.gpg
echo \
"deb [arch="$(dpkg --print-architecture)" signed-by=/etc/apt/keyrings/docker.gpg] https://download.docker.com/linux/ubuntu \
"$(. /etc/os-release && echo "$VERSION_CODENAME")" stable" | \
sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
sudo apt-get update
sudo apt-get install --yes \
docker-ce \
docker-ce-cli \
containerd.io \
docker-buildx-plugin \
docker-compose-pluginsudo apt install --yes ubuntu-drivers-common
sudo ubuntu-drivers autoinstalldistribution=$(. /etc/os-release;echo $ID$VERSION_ID)
curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add -
curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list
sudo apt-get update && sudo apt-get install -y nvidia-container-toolkit nvidia-docker2
sudo systemctl restart dockergedit ~/.bashrc
export DOCKER_USER=<your_username>
export WANDB_API_KEY=<your_api_key>
source ~/.bashrc如果之前没有设置docker_user, please reference:
docker login
2.2 troubleshooting
(1) MUJOCO_EGL_DEVICE_ID
报错:RuntimeError: The MUJOCO_EGL_DEVICE_ID environment variable must be an integer between 0 and -1 (inclusive), got 0.
网上的方法是加一句:
import os; os.environ["MUJOCO_GL"] = "egl"; os.environ["MUJOCO_EGL_DEVICE_ID"] = "0"; import mujoco但是试了没用。后来自己好了。泪目。
(2)Docker启动容器报错:Unknown runtime specified nvidia
报错:docker: Error response from daemon: unknown or invalid runtime name: nvidia
sudo gedit /etc/docker/daemon.json{
"runtimes": {
"nvidia": {
"path": "nvidia-container-runtime",
"runtimeArgs": []
}
},
"default-runtime": "nvidia"
}
我是没有"default-runtime": "nvidia"。也不确定是不是改完就好了。因为后面重新安装了一次。
(3)报错:docker: Error response from daemon: failed to create task for container: failed to create shim task: OCI runtime create failed: runc create failed: unable to start container process: error during container init: error running hook #0: error running hook: exit status 1, stdout: , stderr: Auto-detected mode as 'legacy' nvidia-container-cli: initialization error: nvml error: driver/library version mismatch: unknown.
重启之。
sudo systemctl restart docker3. run
3.1 docker下测试test_fps.py
docker run -it --rm --gpus=all --runtime=nvidia \
$DOCKER_USER/vlmrm:latest \
python3 /root/vlmrm/test_fps.py3.1.1 代码分析
test_fps.py用于在一个虚拟环境中创建和运行多个强化学习环境,并测试其每秒帧数(FPS)
import multiprocessing
import time
import typer
from numpy import array
from stable_baselines3.common.vec_env import DummyVecEnv
import gymnasium
from vlmrm.contrib.sb3.make_vec_env import make_vec_env
from vlmrm.contrib.sb3.subproc_vec_env import SubprocVecEnv
from vlmrm import envs
import os
# multiprocessing:用于获取CPU核心数量。
# time:用于计算时间和FPS。
# typer:用于创建命令行接口。
# numpy.array:用于创建数组。
# stable_baselines3.common.vec_env.DummyVecEnv 和 gymnasium:用于创建和管理强化学习环境。
# make_vec_env 和 SubprocVecEnv:用于创建并行环境。
# os:用于设置环境变量。def main(n_envs: int = 0):
# 设置环境变量 MUJOCO_EGL_DEVICE_ID
os.environ['MUJOCO_EGL_DEVICE_ID'] = '0'
# 打印环境变量以确认设置正确
print(f"MUJOCO_EGL_DEVICE_ID: {os.environ['MUJOCO_EGL_DEVICE_ID']}")
print(f"n_envs: {n_envs}")
if n_envs == 0:
n_envs = multiprocessing.cpu_count()
print(f"n_envs: {n_envs}") # n_envs = 24
# make_env函数用于创建一个指定的Gym环境
def make_env():
env = gymnasium.make(
"vlmrm/CLIPRewardedHumanoid-v4",
episode_length=200,
render_mode="rgb_array"
)
return env
# 创建多个并行环境
# SubprocVecEnv 用于多进程环境,DummyVecEnv 用于单进程环境。
# 设置渲染尺寸为 (480, 480, 3)
venv = make_vec_env(
make_env,
vec_env_cls=SubprocVecEnv if n_envs > 1 else DummyVecEnv,
# vec_env_kwargs=dict(render_dim=(480, 480)),
vec_env_kwargs=dict(render_dim=(480, 480, 3)),
n_envs=n_envs,
verbose=True,
)
# 运行并测试环境:
# 打印使用的环境数量并重置环境。
# 开始时间计数器并初始化帧计数。
# 在一个无限循环中,每步采样动作并执行。
# 每10帧打印一次当前的FPS和总帧数
print(f"Benchmarking FPS with {n_envs} environments. {venv}")
venv.reset()
base_time = time.time()
frames = 0
while True:
venv.step(array([venv.action_space.sample() for _ in range(n_envs)]))
image_array = venv.get_images()
frames += 1
if frames % 10 == 0:
print(
f"fps: {frames * n_envs / (time.time() - base_time)}. Total frames "
f"{frames * n_envs}. Type {type(image_array)}"
)3.1.2 troubleshooting
报错
ValueError: could not broadcast input array from shape (480,480,3) into shape
(480,480)
解决:原始代码设置的渲染尺寸是 (480, 480) 改为 (480, 480, 3)
# vec_env_kwargs=dict(render_dim=(480, 480)),
vec_env_kwargs=dict(render_dim=(480, 480, 3)),3.2 在本地环境training
后面没有用docker环境进行训练
3.2.1 config.yaml
作者提供的是
env_name: Humanoid-v4 # RL environment name
base_path: /data/runs/training # Base path to save logs and checkpoints
seed: 42 # Seed for reproducibility
description: Humanoid training using CLIP reward
tags: # Wandb tags
- training
- humanoid
- CLIP
reward:
name: clip
pretrained_model: ViT-g-14/laion2b_s34b_b88k # CLIP model name
# CLIP batch size per synchronous inference step.
# Batch size must be divisible by n_workers (GPU count)
# so that it can be shared among workers, and must be a divisor
# of n_envs * episode_length so that all batches can be of the
# same size (no support for variable batch size as of now.)
batch_size: 1600
alpha: 0.5 # Alpha value of Baseline CLIP (CO-RELATE)
target_prompts: # Description of the goal state
- a humanoid robot kneeling
baseline_prompts: # Description of the environment
- a humanoid robot
# Path to pre-saved model weights. When executing multiple runs,
# mount a volume to this path to avoid downloading the model
# weights multiple times.
cache_dir: /root/.cache
rl:
policy_name: MlpPolicy
n_steps: 100000 # Total number of simulation steps to be collected.
n_envs_per_worker: 2 # Number of environments per worker (GPU)
episode_length: 200 # Desired episode length
learning_starts: 100 # Number of env steps to collect before training
train_freq: 200 # Number of collected env steps between training iterations
batch_size: 64 # SAC buffer sample size per gradient step
gradient_steps: 1 # Number of samples to collect from the buffer per training step
tau: 0.005 # SAC target network update rate
gamma: 0.99 # SAC discount factor
learning_rate: 3e-4 # SAC optimizer learning rate
logging:
checkpoint_freq: 800 # Number of env steps between checkpoints
video_freq: 800 # Number of env steps between videos
tensorboard_freq: 800 # Number of env steps between tensorboard logs一些要改的地方:
(1) [Errno 13] Permission denied: '/root/.cache'
cache_dir 改为
cache_dir: /home/username/vlmrm/.cache(2) [Errno 13] Permission denied: '/data'
base_path 改为
base_path: /home/username/vlmrm/data/runs/training(3) 配置验证错误: 提示在进行 CLIP-rewarded 训练时,self.rl.n_envs=2 和 self.rl.episode_length=200 的乘积必须能被 self.reward.batch_size=1600 整除,以确保所有批次的大小相同。
报错内容:
ValidationError: 1 validation error for Config
Value error, (self.rl.n_envs=2) * (self.rl.episode_length=200) must be
divisible by (self.reward.batch_size=1600) so that all batchesare of the same
size. [type=value_error, input_value={'env_name':
'Humanoid-v4...54b9280bef90ef20cd0e30'}, input_type=dict]
For further information visit https://errors.pydantic.dev/2.2/v/value_error改为:
# batch_size: 1600
batch_size: 400不需要改的warning:
(1) Pydantic 提示字段 model_checkpoint 和 model_base_path 与受保护的命名空间 model_ 冲突。可以通过设置 model_config['protected_namespaces'] = () 来解决这个警告。
UserWarning: Field "model_checkpoint" has conflict with protected namespace "model_".
You may be able to resolve this warning by setting `model_config['protected_namespaces'] = ()`.
这个我还没动。
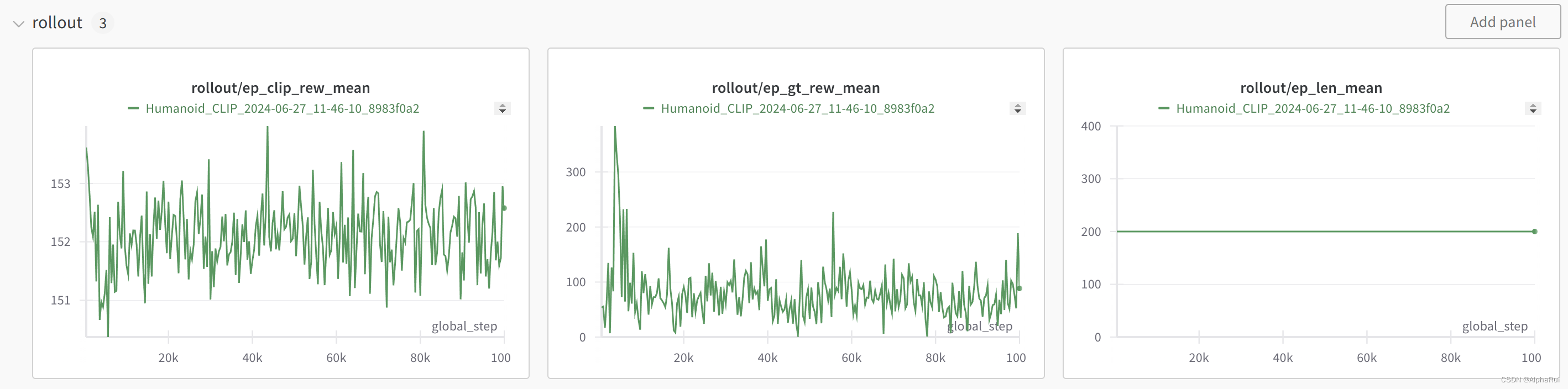
4. 复现结果



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









