







超详细Python爬虫自学整理从基础内容开始到进阶(不断更新)(Anaconda中的Spyder)
本文通过学习其他网站的内容,展示自己学习的过程,标出出现的问题并给出解决方案。本文多数是引用,也含有大量自己查找资料和试错进行的补充。
由于2020.5.2更新主页,下面爬取我的主页可能暂时无法使用,会出现RemoteDisconnected,目前正在解决这个问题,请大家先用其它网页爬取测试。
2020.5.4我已重新更改robots.txt文件,现在可以不用User Agent模拟便可以直接访问了,但是由于主页更新,显示的内容会与下面图片不同,正在重新建立新二级域名用于爬虫学习。
2020.5.5 我在根目录新建一个文件夹用于学习爬取,下面alvincr.com全部替换成 alvincr.com/study/Welcome_to_CentOS.html即可,你也可以直接在浏览器输入这个网站,查看实际文本。
目录
Table of Contents
超详细Python爬虫自学整理从基础内容开始到进阶(不断更新)(Anaconda中的Spyder)
一.网页构造:
-
1.网页标签
网页一般由三部分组成,分别是 HTML(超文本标记语言)、CSS(层叠样式表)和 JScript(活动脚本语言)。
HTML
HTML 是整个网页的结构,相当于整个网站的框架。带“<”、“>”符号的都是属于 HTML 的标签,并且标签都是成对出现的。
常见的标签如下:
备注:其中div全称:DIVision,是层叠样式表中的定位技术
href是Hypertext Reference的缩写。 意思是指定超链接目标的URL
/
<br/>表示换行操作,全称break (在编译md文件时使用\是字符转义,
为换行,\ <br>则直接输出<br>)
-
2.CSS图形样式
CSS 表示样式,<style type="text/css">表示下面引用一个 CSS,在 CSS 中定义了外观。
JScript
JScript 表示功能。交互的内容和各种特效都在 JScript 中,JScript 描述了网站中的各种功能。
-
3.JScript
JScript 表示功能。交互的内容和各种特效都在 JScript 中,JScript 描述了网站中的各种功能。
如果用人体来比喻,HTML 是人的骨架,并且定义了人的嘴巴、眼睛、耳朵等要长在哪里。CSS 是人的外观细节,如嘴巴长什么样子,眼睛是双眼皮还是单眼皮,是大眼睛还是小眼睛,皮肤是黑色的还是白色的等。JScript 表示人的技能,例如跳舞、唱歌或者演奏乐器等。
在我搭建自己的博客的时候借鉴t他人的模板里面经常会看到一些JScript插件,这些插件可以实现非常丰富的功能,例如人机交互的图案(移动鼠标将会在相应的位置出现图形),酷炫的效果等等。
以下是我未将主页上传到服务器,仅仅搭建好Apache+php+mysql(LAMP)时的效果,个人主页暂时未上传。目前可以访问alvincr.com并使用ctrl+u进行查看源代码
二.关于爬虫的合法性
几乎每一个网站都有一个名为 robots.txt 的文档,当然也有部分网站没有设定 robots.txt。对于没有设定 robots.txt 的网站可以通过网络爬虫获取没有口令加密的数据,也就是该网站所有页面数据都可以爬取。如果网站有 robots.txt 文档,就要判断是否有禁止访客获取的数据。
搜索引擎获取一个新网站的 URL:
(1) 新网站向搜索引擎主动提交网址:(如百度 http://zhanzhang.baidu.com/linksubmit/url)
(2) 在其他网站上设置新网站外链(尽可能处于搜索引擎爬虫爬取范围)
(3) 搜索引擎和 DNS 解析服务商(如 DNSPod 等) 合作, 新网站域名将被迅速抓取。
但是搜索引擎蜘蛛的爬行是被输入了一定的规则的, 它需要遵从一些命令或文件的内容, 如标注为 nofollow 的链接, 或者是 Robots 协议。
Robots 协议(也叫爬虫协议、 机器人协议等) , 全称是“网络爬虫排除标准”(Robots Exclusion Protocol) , 网站通过 Robots 协议告诉搜索引擎哪些页面可以抓取, 哪些页面不能抓取, 例如:
淘宝网: https://www.taobao.com/robots.txt
腾讯网: http://www.qq.com/robots.txt
以淘宝网为例,在浏览器中访问 https://www.taobao.com/robots.txt, 这里不允许baidu进行爬取,但是我即便使用google登录同样也显示的是上面的文档,在谷歌搜索相关资料,大家说是淘宝整个网站都不给爬取。所以放弃对淘宝进行爬取,随便找一个网站看他的robots文档,若能进行爬取再使用爬取功能。实在找不到可以爬取我的小水管主页。
这里不允许baidu进行爬取,但是我即便使用google登录同样也显示的是上面的文档,在谷歌搜索相关资料,大家说是淘宝整个网站都不给爬取。所以放弃对淘宝进行爬取,随便找一个网站看他的robots文档,若能进行爬取再使用爬取功能。实在找不到可以爬取我的小水管主页。
三 .爬虫软件的工作流程
不想了解基础的可跳过
爬虫的比喻:如果我们把互联网比作一张大的蜘蛛网,那一台计算机上的数据便是蜘蛛网上的一个猎物,而爬虫程序就是一只小蜘蛛,沿着蜘蛛网抓取自己想要的猎物/数据.
爬虫的定义:向网站发起请求,获取资源后分析并提取有用数据的程序
-
1.抓取网页
搜索引擎网络爬虫的基本工作流程如下:
首先选取一部分的种子 URL, 将这些 URL 放入待抓取 URL 队列;
取出待抓取 URL, 解析 DNS 得到主机的 IP, 并将 URL 对应的网页下载下来, 存储进已下载网页库中, 并且将这些 URL 放进已抓取 URL 队列。
分析已抓取 URL 队列中的 URL, 分析其中的其他 URL, 并且将 URL 放入待抓取 URL队列, 从而进入下一个循环…
注:大意是:要爬取alvincr.com,首先给定alvincr.com这个种子url,然后从这个种子找使用的外链链接进行爬取,在爬取的时候以及我们看到的都是网页名称,例如alvincr.com,但是计算机在爬取时要找到这个网页在哪台主机上,要找到主机就需要主机的ip,DNS解析便是将alvincr.com找到对应的ip地址,然后连接对应主机并将内容全部下载到本地。
-
2.数据存储
搜索引擎通过爬虫爬取到的网页, 将数据存入原始页面数据库。 其中的页面数据与用户浏览器得到的 HTML 是完全一样的。
搜索引擎蜘蛛在抓取页面时, 也做一定的重复内容检测, 一旦遇到访问权重很低的网站上有大量抄袭、 采集或者复制的内容, 很可能就不再爬行。
-
3请求与相应
- 请求方式:
3.1.1.常用的请求方式:GET,POST
3.1.2其他请求方式:HEAD,PUT,DELETE,OPTHONS
响应:
3.2.1、响应状态: 200:代表成功 301:代表跳转 404:文件不存在 403:权限 502:服务器错误
3.2.2、响应头: Respone header set-cookie:可能有多个,是来告诉浏览器,把cookie保存下来。
3.2.3、网页源代码: preview 最主要的部分,包含了请求资源的内容,如网页html、图片和二进制数据等。
四 .实现爬虫的语言
1.php:可以实现爬虫。php被号称是全世界最优美的语言,但是php在实现爬虫中支持多线程和多进程方面做的不好。
2.java:可以实现爬虫。java可以非常好的处理和实现爬虫,是唯一可以与python并驾齐驱且是python的头号劲敌。但是java实现爬虫代码较为臃肿,重构成本较大。
3.c、c++:可以实现爬虫。但是使用这种方式实现爬虫纯粹是是某些人(大佬们)能力的体现,却不是明智和合理的选择。
4.python:可以实现爬虫。python实现和处理爬虫语法简单,代码优美,支持的模块繁多,学习成本低,具有非常强大的框架(scrapy等)
注:最终使用的是python,IDE(Integrated Drive Electronics,集成编译环境)使用的是Anaconda,也可以使用Pycharm,一开始我使用的是Pycharm,但是出现了很多BUG,可能是我BUG体质引起的,然后专用Anaconda自带的Spyder,不管用哪个实际使用都一样,但是Anconada还有很多其它的功能,集成效果更好。
另附Pycharm使用指南:https://mp.weixin.qq.com/s?__biz=MzU2ODYzNTkwMg==&mid=2247483976&idx=1&sn=ffb8362d88371c805823da9ba408b9b2&chksm=fc8bbad9cbfc33cfccdb68caaea78b412b016302826312beeae09317d98aeb495736b80e1f02&scene=21#wechat_redirect
Spyder使用指南:https://zhuanlan.zhihu.com/p/67080268
五.用 Python 登录网页
在spyder中任意新建一个项目(按ctrl+n可以快速新建)
用 Python 来爬取这个网页的一些基本信息. 首先要做的, 是使用 Python 来登录这个网页, 并打印出这个网页 HTML 的 source code. 注意, 因为网页中存在中文, 为了正常显示中文, read() 完以后, 我们要对读出来的文字进行转换, decode() 成可以正常显示中文的形式.
备注:由于我的网页目前没有上传,显示是全英文,但是自己的服务器可以自己随便折腾,也不会对他人造成困扰,因此下面仍然用我自己的网页进行爬取,后面如果上传自己的主页,爬取出来的内容可能会不同
五.简单爬取网页
-
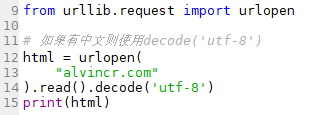
1.使用urlopen操作进行爬取
from urllib.request import urlopen
html = urlopen(
“http://www.alvincr.com/” ).read().decode(‘utf-8’)
print(html)
图片版含备注:lib全称:Library即库,urllib即链接库,从链接库中导入urlopen开源链接命令。
-
2.使用get操作
import requests
url=‘http://www.alvincr.com/’
strhtml=request.get(url)
print(strhtml.text)
图片版:

爬取结果:
备注:Str 函数 返回代表一数值的 Variant (String)。可包含任何有效的数值表达式。
注意:无论是使用哪种方式,一定一定不要写网站的简称,例如:如果我将http://www.alvincr.com/写成alvincr.com则输出错误


如果仍然不能爬取,请检测大小写以及中英文输入法问题
六.简单匹配网页内容
print 出来这就证明了我们能够成功读取这个网页的所有信息了. 但我们还没有对网页的信息进行汇总和利用. 我们发现, 想要提取一些形式的信息, 合理的利用 tag 的名字十分重要.
这里我们使用 Python 的正则表达式 RegEx 进行匹配文字,可以认为RegEx就是正则表达式,正则表达式的目的便是为了匹配文字或是找到你想要的内容,类似于Win10中的查找,只不过使用正则表达式更为灵活,可以更加随心所欲的过滤和查找内容, 筛选信息。
pattern1 = “alvin”
pattern2 = “com”
pattern3 = “linux”
string = “http://alvincr.com.html”
print(pattern1 in string)
print(pattern2 in string)
print(pattern3 in string)

备注:测试发现string可以随意改名,但是改成string-test就无法运行
七.普通匹配网页内容
如果需要找到潜在的多个可能性文字, 我们可以使用 [] 将可能的字符囊括进来. 比如 [ab] 就说明我想要找的字符可以是 a 也可以是 b. 这里我们还需要注意的是, 建立一个正则的规则, 我们在 pattern 的 “” 前面需要加上一个 r 用来表示这是正则表达式, 而不是普通字符串. 通过下面这种形式, 如果字符串中出现 “add” 或者是 “adm”, 它都能找到.
-
1.匹配字符串
from urllib.request import urlopen
import re
html = urlopen(
“http://www.alvincr.com/”).read().decode(‘utf-8’)
print(html)
#multiple patterns (“add” or “adm”)
ptn = r"ad[dm]"
print(re.search(ptn, html))

匹配结果
备注:PTN是分组传送网的英文缩写,全称为Packet Transport Network
注意:在使用re.search时要首先调用re,否则输出:NameError: name ‘re’ is not defined。方法为在首行添加:import re**
-
2.匹配标题
如果我们想用代码找到这个网页的 title, 我们就能这样写. 选好要使用的 tag 名称
from urllib.request import urlopen
import re
html = urlopen(“http://www.alvincr.com/”).read().decode(‘utf-8’)
res=re.findall(r"",html)
print("\nPage title is ",res[0])

从浏览器按F12可以看到网页的源代码 可以看到标题就是Welcome to CentOS
可以看到标题就是Welcome to CentOS
注意:
res=re.findall(r"",html)要写完整
比如写成res=re.findall(r"",html),则显示error: nothing to repeat
写成res=re.findall(r"",html),则显示IndexError: list index out of range
写成res=re.findall(r"",html),显示error: nothing to repeat
备注:
?表示找到匹配内容就停止,不继续匹配,必须跟在*或者+后边用
.表示除\n之外的任意字符
*表示匹配0-无穷
+表示匹配1-无穷
-
3.学习中遇到的名词
什么是CDNJS:

CDNJS 是一个互联网上的 JavaScript 资料库,访问速度非常快。CDNJS 上提供了众多可以直接在网页上引用的JavaScript 库,实现用户浏览网站的最佳速度体验,也就是说是一个放JS插件的文库。
XHR 是什么:
XHR是XMLHttpRequest 对象,也是ajax功能实现所依赖的对象。它提供了对 HTTP 协议的完全的访问,包括做出 POST 和 HEAD 请求以及普通的 GET 请求的能力。XMLHttpRequest 可以同步或异步地返回 Web 服务器的响应,并且能够以文本或者一个 DOM 文档的形式返回内容。
ajax是什么:
ajax 主要是实现页面和 web 服务器之间数据的异步传输。Ajax 即“Asynchronous Javascript And XML”(异步 JavaScript 和 XML),是指一种创建交互式网页应用的网页开发技术。能够在无需重新加载整个网页的情况下,能够更新部分网页的技术。通过在后台与服务器进行少量数据交换,Ajax 可以使网页实现异步更新。
-
4.重点:找所有的链接
八.进阶网页匹配
随用随看,无需全部记忆
链接:https://ahkcn.github.io/docs/misc/RegEx-QuickRef.htm
主要功能及对应命令:
-
按类型匹配:
\d:任何数字
\D:不是数字
\s:任意空白字符如[\t\n\r\f\v]
\w:任意大小写字母和数字和“”
\:匹配
.:匹配任何字符
^:匹配开头
$:匹配结尾
?:前面的字符可有可无 -
重复匹配
*:重复零次或多次
+:重复一次或多次
[h,n]:重复n至m次
[n]:重复n次 -
分组
使用()
在(\d+)组里,找到的是数字,其中\d代表任何数字
在(.+)组里,会找到“Date:”后面的所有内容,其中.是匹配所有字符,+重复一次或多次
match.group返回所有组里的内容
?P<名字>给组自定义名字 -
findall
找到全部的匹配项 -
replace
re.sub()通过正则表达式匹配上一些形式的字符串然后再替代掉这些字符串 -
split切割

九
问题:
-
1.爬虫陷阱
爬虫会跟踪所有之前没有访问过的链接。但是,当网站根据用户请求动态生成页面内容,这样就会出现无限多的网页,就像俄罗斯无限套娃一样,一层套一层,无限循环,直到把机器困死。
陷阱一:网站地图不正确
网站地图是一个非常实用的网站工具,对于用户和蜘蛛来说,一副完整、正确的网站地图都能很好地识别整个网站的架构,从而更好地扫瞄和爬行网站。由于一些站长对于代码的不熟悉,以及对网站的架构不熟悉,就随便选了一个权威性不好的工具来制作了一副不完整或不正确的网站地图,最后的结果就是让蜘蛛爬行时陷入其中,最终“迷路”了。
挑选一个权威性好的工具来制作网站地图,比如站长工具、百度站长平台工具等,假如自己对网站比较熟悉,最好能够自己手工制作,并亲身多次测试,保证好网站地图的正确性和完整性。
陷阱二:网站的死链接数量巨大
死链接就是就是返回代码为404的错误页面链接,这类链接通常产生于网站改版后、或者网站更换域名后。死链接的存在对于用户体验和蜘蛛爬行来说都是非常不好的。死链接无疑就是阻挡追施蛛的爬行,当蜘蛛接二连三地碰到这些不该浮上的死链接时,就会产生对网站的不信任,最终会放弃爬行网站。
(1)提交死链接。利用百度站长平台的“死链提交”工具来提交网站死链,具体说明请参考百度站长工具。
(2)对死链接举行重定向或者删除,假如死链接的位置不是很重要,可以把其重定向到首页,假如位置比较重要,数量也比较多,就可以挑选删除死链接,可以使用工具来删除。
陷阱三:网址包含参数过多
尽管百度优化指南官方表明,目前百度搜索机器人也能像谷歌机器人一样收录动态参数网站,但是静态化url的网站永久要比动态化url收录更有优势。因此,假如你的网站像下面的网址一样,那就可能会导致蜘蛛爬行不顺畅了:
在挑选做站程序前,一定要考虑该程序是否支持网站url静态化,并且在日后维护中也要注意网站url是否真正做到静态化,尽量舍弃包含参数的动态网址的做法。
陷阱四:网站过多锚文本
网站锚文本过多,造成内链链轮。外部链轮相信大家都会认识,但是其实内部链接也是可以产生链轮的。无数站长为了提升关键词排名,不惜使用过多的锚文本,然后造成页面之间的链接轮回效应,最后也让蜘蛛走进了无底洞,无法走出来了。
清除过往的,带有链接交叉性的锚文本,并且尽量做到需要时才添加锚文本,滥用锚文本只会让百度蜘蛛更一步不认可你的网站。
总结起来便是:1.蜘蛛网不完整,爬取出错;2.蜘蛛网太大,爬到死也爬不完;3.蜘蛛网弹性太大,实际要走的比看起来长;4.蜘蛛网和其它蜘蛛网连起来了,或者是蜘蛛在同一个蜘蛛网上循环爬。


-
2.出现RemoteDisconnected
RemoteDisconnected: Remote end closed connection without response
我在更新我的主页之后(2020.5.2),使用上述命令无法爬取我的主页,原因是服务器限制了User-Agent的访问,由于这次搭建使用的是集成环境,并没有自定义设置具体环境,这也是爬取很多网站会遇到的问题,因为这些网站会检测连接的对象,当并非是认为操作的时候,就不再提供服务。
解决方法:使用User Agent来模拟浏览器访问
2020.5.4我已重新更改robots.txt文件,现在可以不用User Agent模拟便可以直接访问了。
- 3.使用User Agent来模拟浏览器访问
引用内容的链接:
核心引用:
Python爬虫入门教程:超级简单的Python爬虫教程:
http://c.biancheng.net/view/2011.html
部分补充:
python爬虫的原理介绍:
https://blog.csdn.net/wapecheng/article/details/93519747
爬虫的基本原理:
https://zhuanlan.zhihu.com/p/66375984
什么是爬虫陷阱















 2276
2276











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









