







原创作品 转载请注明出http://blog.csdn.net/always2015/article/details/47322551
最近刚接触GPU高性能编程,感觉并行编程太高大上了。他的强大的并行计算也成为了全球研究的热点。下面的程序是在配置好了编译和运行CUDA C代码环境的基础上运行的第一个示例程序。具有纪念的意义。本文的例程是基于教材《GPU高性能编程CUDA编程实战》,这是一本很经典的一步cuda入门参考书,废话不多说,我已经迫不及待去感受cuda的魅力啦。
工程建立
1、打开VS2010,新建–>项目,建立一个空的win32控制台应用程序。如下图所示:
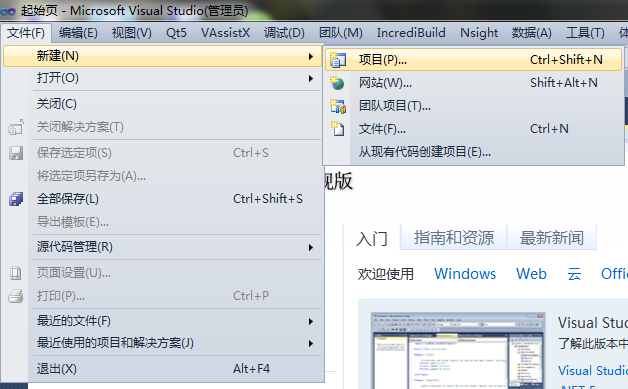
并且给该工程命名为cuda_test,单击确定。
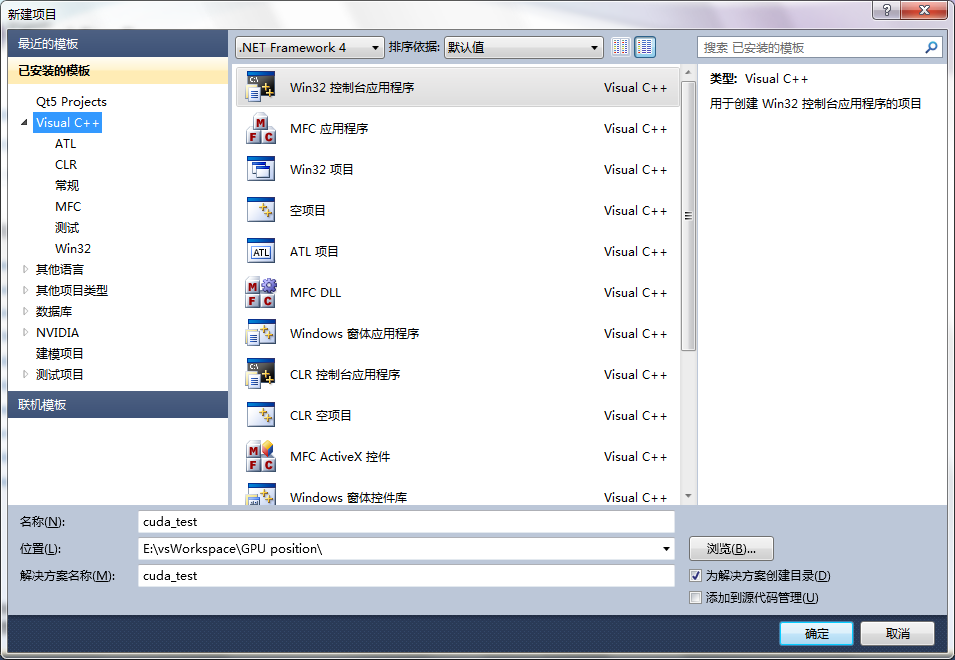
2、然后在下一个窗口中点击“下一步”,然后再在下一个窗口中的”附加选项“中选择”空项目“。点击完成,如图:
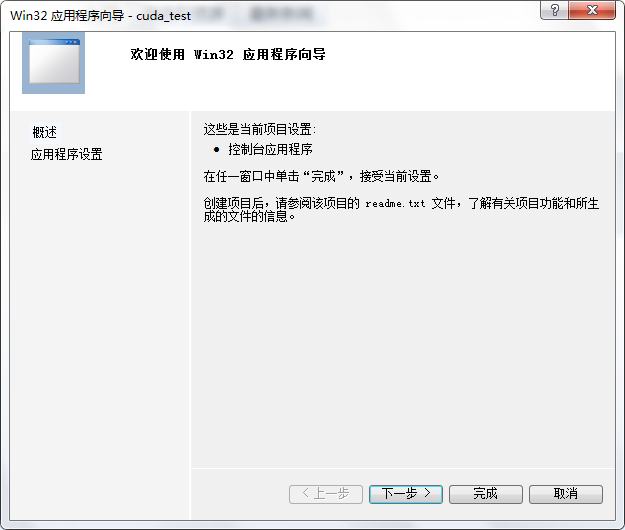
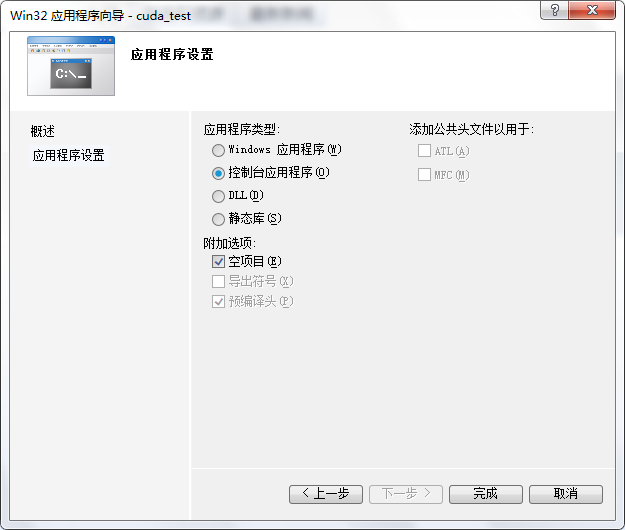
3、这样我们就进入了工程的界面,右键源文件—–>添加—->新建项。
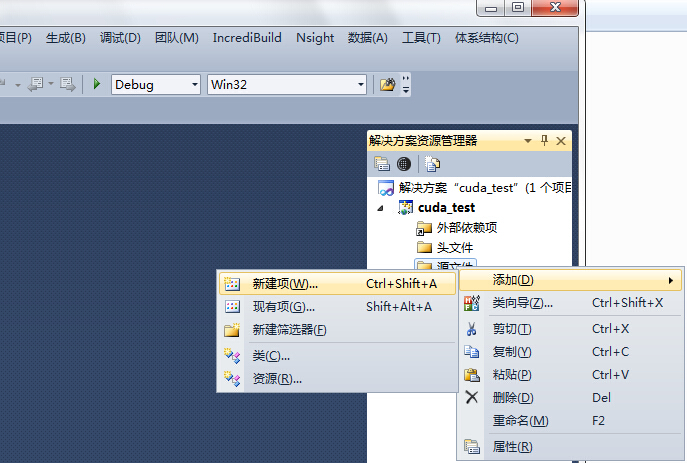
4、在打开的对话框中选择建立一个cuda格式的文件,即:NVIDIA CUDA6.0下的code——>CUDA C/C++ file,然后随便起一个名字main,点击添加。
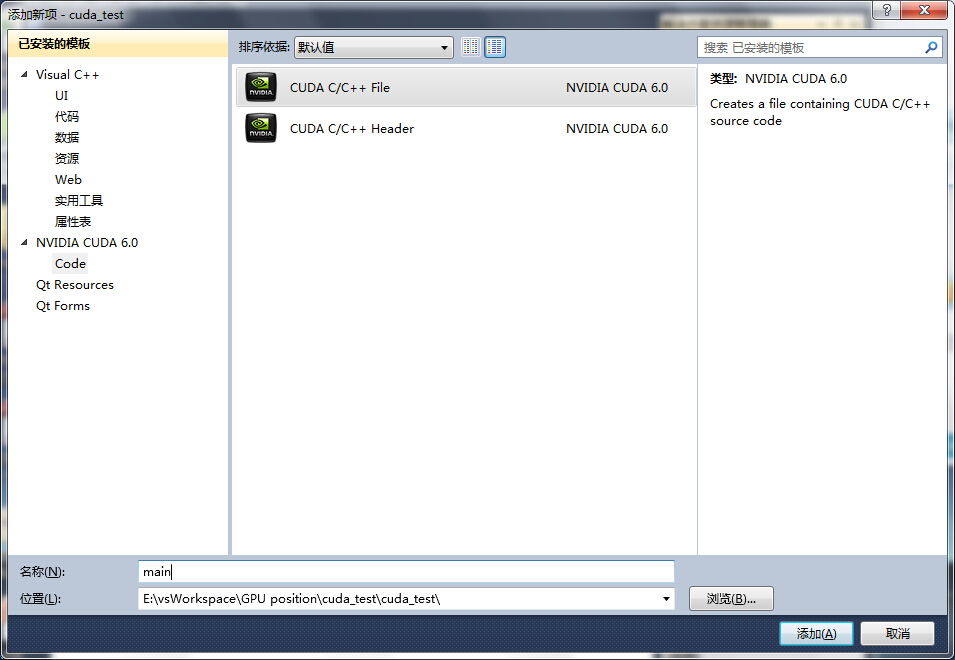
5、右键工程—>生成自定义 如下:
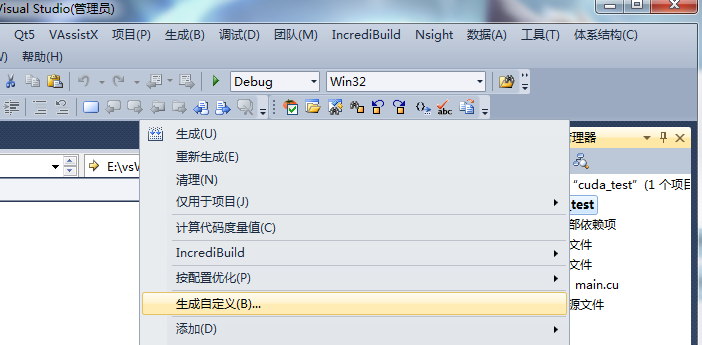
弹出的窗口中选择CUDA6.0 .
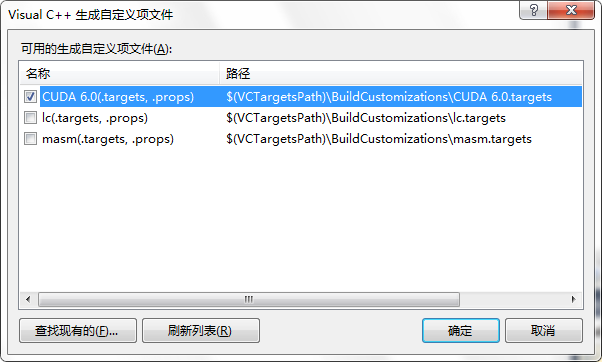
6、右键项目—->属性,将项类型设置为:CUDA C/C++。如下图。
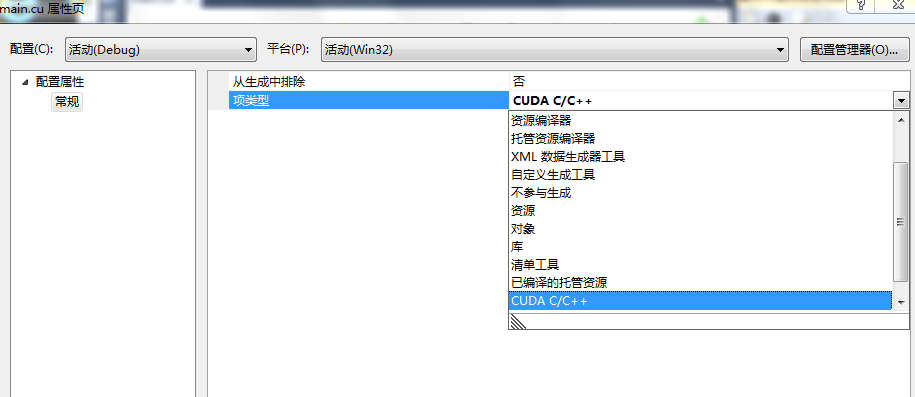
至此,平台已经搭建完毕,下面我们就可以运行一个代码来测试一下:
#include<cudahead/common/book.h>
#include<stdio.h>
__global__ void add(int a,int b,int*c)
{
*c=a+b;
}
int main(void)
{
int c;
int *dev_c;
HANDLE_ERROR(cudaMalloc((void**)&dev_c,sizeof(int)));
add<<<1,1>>>(2,7,dev_c);
HANDLE_ERROR(cudaMemcpy(&c,dev_c,sizeof(int),cudaMemcpyDeviceToHost));
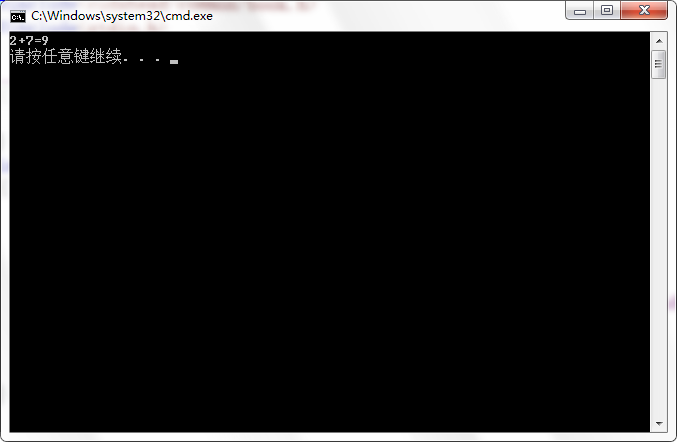
printf("2+7=%d\n",c);
cudaFree(dev_c);
return 0;
}注意:上述代码的头文件book.h是《GPU高性能编程CUDA编程实战》整本书例程编写的一个头文件,在运行这个代码是需要包含进去,否则肯定会报错。
运行结果如下:
我们知道在GPU设备上执行的函数称为核函数(Kernel).但是编译器怎么区分函数应该在哪个地方运行呢。我们看到代码就知道了。CUDA C中,增加了global修饰符,这个修饰符告诉编译器这个函数在GPU上运行而不是CPU上运行。
还有就是通过cudaMalloc()来分配内存,这个函数类似于C语言的malloc。但是该函数作用是告诉我们是在GPU上分配内存。第一个参数是指针,指向用于保存的新分配内存的变量。第二个是所分配内存的大小。HANDLE_ERROR(),是一个宏,作为本代码的一个辅助部分,定义在book.h中。这个宏是判断函数调用是否返回了一个错误的值。cudaMemcpy()可以说是GPU内存和主机内存的一个接口,这里的意思是将GPU中内存dev-c的值复制给主机的c。因为在GPU上的指针是不能访问CPU上的内存的,所以通过cudaMemcpy来访问GPU的内存。注意cudaMemcpy最后一个参数是cudaMencpyDeviceToHost,这个参数告诉我们运行时源指针是在GPU内存的一个指针,目的指针是一个CPU内存一个指针。这个函数类似于C语言的Memcpy。要释放cudaMalloc分配的内存,需要调用cudaFree释放,这和函数free行为很类似。















 4015
4015

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









