






1. 通过网络配置命令,让主机可以上网。 ip, netmask, gateway, dns,主机名。相关命令总结,最终可以通过这些配置让你的主机上网。
ip address show(或ip a s) 显示系统中所有网络接口的详细信息
ip address add 192.168.1.200/24 dev eth0 给eth0接口添加一个 IP 地址192.168.1.200,子网掩码为/24
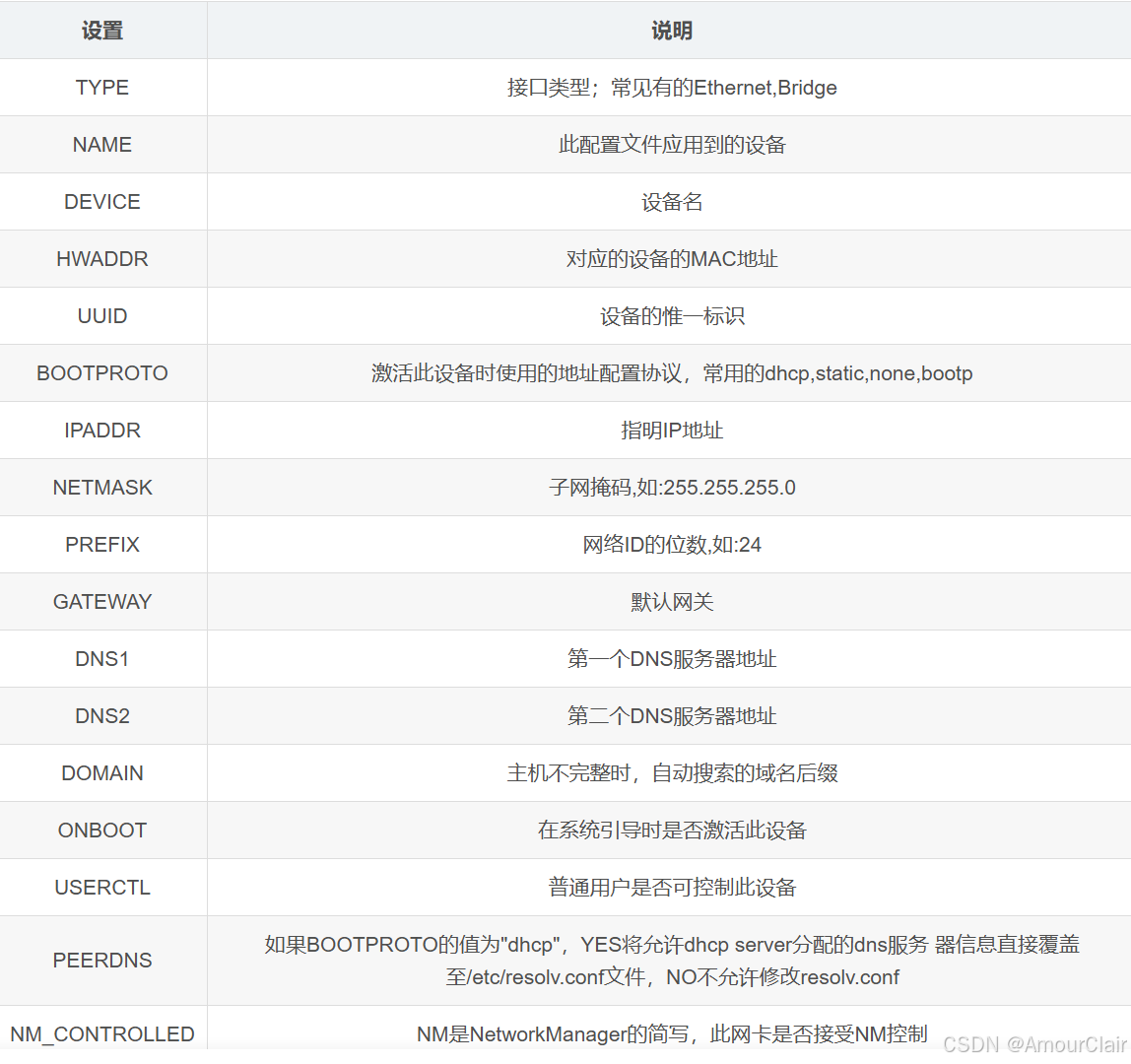
2. 解析/etc/sysconfig/network-scripts/ifcfg-eth0配置格式。
3. 基于配置文件或命令完成bond0配置
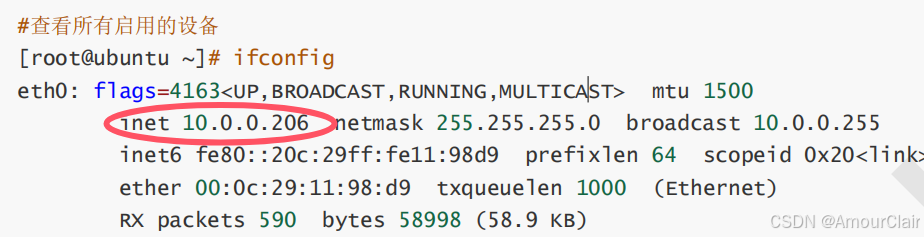
4. 通过ifconfig命令结果找到ip地址
[root@server11 ~]# ifconfig eth0|grep -w inet|awk '{print $2}' 192.168.9.11
5. 使用脚本判断 你主机所在网络内在线的主机IP有哪些? ping通则在线
#!/bin/bash
# 网络前缀,例如 192.168.1.
NETWORK_PREFIX="192.168.1."
# 开始和结束的IP地址范围
START=1
END=254
# 输出在线主机的列表
echo "扫描在线主机"
# 遍历IP地址范围
for ip in $(seq $START $END); do
# 构造完整的IP地址
FULL_IP="${NETWORK_PREFIX}${ip}"
# 使用ping命令检查主机是否在线(发送1个数据包,等待时间为1秒)
ping -c 1 -W 1 $FULL_IP > /dev/null 2>&1
# 检查ping命令的退出状态码
if [ $? -eq 0 ]; then
# 如果ping成功,则输出该IP地址
echo "$FULL_IP 在线"
fi
done
echo "完成."
6. 使用while read line和/etc/passwd,计算用户id总和
#!/bin/bash
# 初始化用户ID总和为0
sum_uid=0
# 使用while循环和read命令逐行读取/etc/passwd文件
while IFS=: read -r username password uid gid comment home shell; do
# 累加用户ID到总和中
sum_uid=$((sum_uid + uid))
done < /etc/passwd
# 输出用户ID总和
echo "用户ID总数为: $sum_uid"
7. 总结索引数组和关联数组,字符串处理,高级变量使用及示例
关联数组与普通数组区别:
关联数组要先声明,才能使用,普通数组可以不用声明
关联数组可以自定义下标,普通数组必须用数字
#普通数组可以不事先声明,直接使用
declare -a ARRAY_NAME
#关联数组必须先声明,再使用
declare -A ARRAY_NAME
注意:两者不可相互转换
#索引数组
#赋值
[rocky@server11 ~]$ test1=({1..6})
#打印全部值
[rocky@server11 ~]$ echo ${test1[*]}
1 2 3 4 5 6
#打印单个值
[rocky@server11 ~]$ echo ${test1[0]}
1
#打印索引
[rocky@server11 ~]$ echo ${!test1[@]}
0 1 2 3 4 5
#遍历数组
[rocky@server11 ~]$ for i in ${!test1[@]};do echo ${test1[i]};done
1
2
3
4
5
6
#数组切片
#取出索引值及其之后索引的元素
[rocky@server11 ~]$ echo ${test1[@]:1}
2 3 4 5 6
[rocky@server11 ~]$ echo ${test1[@]:2}
3 4 5 6
#取出跳过几个元素之后的几个元素
[rocky@server11 ~]$ echo ${test1[@]:2:2}
3 4
#关联数组
#声明
[rocky@server11 ~]$ declare -A test
#赋值
[rocky@server11 ~]$ test=([a]=1 [b]=2 [c]=3)
#显示所有数组
[rocky@server11 ~]$ declare -A
declare -A BASH_ALIASES=()
declare -A BASH_CMDS=()
declare -A test=([c]="3" [b]="2" [a]="1" )
#打印单个值
[rocky@server11 ~]$ echo ${test[a]}
1
#打印全部值
[rocky@server11 ~]$ echo ${test[*]}
3 2 1
#打印索引
[rocky@server11 ~]$ echo ${!test[@]}
c b a
#遍历数组
[rocky@server11 ~]$ for i in ${!test[@]};do echo ${test[$i]};done
3
2
1
当执行echo ${test[i]}时,i被当作索引来使用,但对于关联数组来说,它的索引是字符串(如name和age),而不是按照数字顺序的索引。所以这种方式不能正确地访问关联数组中的元素,因为它没有按照关联数组键值对的正确方式来获取元素。
#删除数组
unset Arrayname
unset Arrayname[key]
字符串处理
#字符串切片
[root@ubuntu2204 ~]# str=abcd1234
#取字符串长度
[root@ubuntu2204 ~]# echo ${#str}
8
#返回字符串变量var中从第2个字符后(不包括第2个字符)的字符开始,到最后的部分
[root@ubuntu2204 ~]# echo ${str:2}
cd1234
#返回字符串变量var中从第2个字符后(不包括第2个字符)的字符开始,长度为4的部分
[root@ubuntu2204 ~]# echo ${str:2:4}
cd12
#取字符串的最右侧3个字符, 注意:冒号后必须有一空白字符
[root@ubuntu2204 ~]# echo ${str: -3}
234
#从最左侧跳过2字符,一直向右取到距离最右侧-1字符之前的内容,即:掐头去尾
[root@ubuntu2204 ~]# echo ${str:2:-1}
cd123
#先从最右侧向左取到6个字符开始,再向右取到距离最右侧-2字符之间的内容,注意:-length前空格,并且length必须大于offset,即[-6,-2)
[root@ubuntu2204 ~]#echo ${str: -6:-2}
cd12
#查找并替换
[root@ubuntu2204 ~]# str=abcd1234abcd12345
#从左到右,替换第一个123为XYZ
[root@ubuntu2204 ~]# echo ${str/123/XYZ}
abcdXYZ4abcd12345
#从左到右,替换所有123为XYZ
[root@ubuntu2204 ~]# echo ${str//123/XYZ}
abcdXYZ4abcdXYZ45
#替换行首的abc为XYZ
[root@ubuntu2204 ~]# echo ${str/#abc/XYZ}
XYZd1234abcd12345
#替换行尾的12345为XYZ
[root@ubuntu2204 ~]# echo ${str/%12345/XYZ}
abcd1234abcdXYZ
#查找并删除
[root@ubuntu2204 ~]# str=abcd1234abcd12345
#从左到右删除第一个1234
[root@ubuntu2204 ~]# echo ${str/1234}
abcdabcd12345
#从左到右删除所有1234
[root@ubuntu2204 ~]# echo ${str//1234}
abcdabcd5
#删除行首abcd
[root@ubuntu2204 ~]# echo ${str/#abcd}
1234abcd12345
#删除行尾12345
[root@ubuntu2204 ~]# echo ${str/%12345}
abcd1234abcd
#字符大小写转换
[root@ubuntu2204 ~]# str=abcd1234ABCD12345
#所有小写转大写
[root@ubuntu2204 ~]# echo ${str^^}
ABCD1234ABCD12345
#所有大写转小写
[root@ubuntu2204 ~]# echo ${str,,}
abcd1234abcd12345
#tr实现大小写转换
[root@ubuntu2204 ~]# echo $str | tr 'a-z' 'A-Z'
ABCD1234ABCD12345
#模糊匹配变量名
[root@ubuntu2204 ~]# file1=a;file2=b;file3=c
[root@ubuntu2204 ~]# echo ${!file*}
file1 file2 file3
[root@ubuntu2204 ~]# echo ${!file@}
file1 file2 file3
[root@ubuntu2204 ~]# str=abcd1234abcd1234
#删除第一次出现的cd及其左边的内容
[root@ubuntu2204 ~]# echo ${str#*cd}
1234abcd1234
#删除左边第一个ab
[root@ubuntu2204 ~]# echo ${str#ab}
cd1234abcd1234
#删除最后第一次出现的cd及其左边的内容
[root@ubuntu2204 ~]# echo ${str##*cd}
1234
[root@ubuntu2204 ~]# echo ${str##ab}
cd1234abcd1234
#取文件名
[root@ubuntu2204 ~]# nginx_url=http://nginx.org/download/nginx-1.20.2.tar.gz
[root@ubuntu2204 ~]# echo ${nginx_url##*/}
nginx-1.20.2.tar.gz
[root@ubuntu2204 ~]# str=abcd1234abcd12345
#从右边开始查找,删除第一个ab及右边的字符串
[root@ubuntu2204 ~]# echo ${str%ab*}
abcd1234
#删除右边的12345
[root@ubuntu2204 ~]# echo ${str%12345}
abcd1234abcd
#从右边开始查找,删除最后一个123及右边的字符串
[root@ubuntu2204 ~]# echo ${str%%123*}
abcd
#删除右边第一12345
[root@ubuntu2204 ~]# echo ${str%%12345}
abcd1234abcd
[root@ubuntu2204 ~]# url=http://www.magedu.com:8080
[root@ubuntu2204 ~]# echo ${url##*:}
8080
[root@ubuntu2204 ~]# echo ${url%%:*}
http
高级变量
#高级变量赋值
$str 为变量名,expr 为具体字符串
这些组合可以省掉一些 if,else 的判断代码
[root@ubuntu2204 ~]# str1=abc
[root@ubuntu2204 ~]# echo ${str1-xyz}
abc
[root@ubuntu2204 ~]# str1=""
[root@ubuntu2204 ~]# echo ${str1-xyz}
[root@ubuntu2204 ~]#
[root@ubuntu2204 ~]# unset str1
[root@ubuntu2204 ~]# echo ${str1-xyz}
xyz
类似于
if [ -v str1 ];then
echo $str1
else
echo "xyz"
fi
#判断变量是否被定义
[root@ubuntu2204 ~]# unset x
[root@ubuntu2204 ~]# test -v x
[root@ubuntu2204 ~]# echo $?
1
#注意 [ ] 中需要空格,否则会报下面错误
[root@ubuntu2204 ~]# [-v x]
-bash: [-v: command not found
[root@ubuntu2204 ~]# [ -v x ]
[root@ubuntu2204 ~]# echo $?
1
#有类型变量
Shell变量一般是无类型的,但是bash Shell提供了declare和typeset两个命令用于指定变量的类型,两
个命令是等价的
declare [-aAfFgilnrtux] [-p] [name[=value] ...]
#选项:
-f #显示已定义的所有函数名及其内容
-F #仅显示已定义的所有函数名
-p #显示每个变量的属性和值
-a #声明或显示定义为数组的变量
-A #将变量定义为关联数组
-i #声明或显示定义为整型的变量
-l #声明或显示定义为小写的变量
-n #变量引用另外一个变量的值
-r #声明或显示只读变量
-t #声明或显示具有trace(追踪)属性的变量
-u #声明或显示定义为大写的变量
-x #显示环境变量和函数,相当于export
#变量间接引用
eval
[root@ubuntu2204 ~]# CMD=whoami
[root@ubuntu2204 ~]# echo $CMD
whoami
[root@ubuntu2204 ~]# eval $CMD
root
[root@ubuntu2204 ~]# n1=6
[root@ubuntu2204 ~]# echo {1..$n1}
{1..6}
#两次展开
[root@ubuntu2204 ~]# eval echo {1..$n1}
1 2 3 4 5 6
#间接变量引用
[root@ubuntu2204 ~]# ceo=name
[root@ubuntu2204 ~]# name=mage
[root@ubuntu2204 ~]# echo ${!ceo}
mage
[root@ubuntu2204 ~]# tmp2=${!ceo}
[root@ubuntu2204 ~]# echo $tmp2
mage
8. 求10个随机数的最大值与最小值
#!/bin/bash
# 初始化最大值和最小值
max_value=0
min_value=101 # 初始化为一个比100大的数,确保第一次比较时能正确更新
# 生成并遍历10个随机数
for i in {1..10}; do
# 生成一个1到100之间的随机数
random_value=$(( RANDOM % 100 + 1 ))
# 更新最大值
if (( random_value > max_value )); then
max_value=$random_value
fi
# 更新最小值
if (( random_value < min_value )); then
min_value=$random_value
fi
done
# 输出最大值和最小值
echo "最大值为: $max_value"
echo "最小值为: $min_value"
9. 使用递归调用,完成阶乘算法实现
#!/bin/bash
# 阶乘函数
factorial() {
local n=$1
if (( n <= 1 )); then
echo 1
else
local prev=$(factorial $((n - 1)))
echo $((n * prev))
fi
}
# 读取用户输入
read -p "请输入一个正整数: " number
# 检查输入是否为正整数
if ! [[ "$number" =~ [0-9]+$ ]] || (( number <= 0 )); then
echo "请输入一个正整数!"
exit 1
fi
# 调用阶乘函数并输出结果
result=$(factorial "$number")
echo "The factorial of $number is: $result"
10. 解析进程和线程的区别? 解析进程的结构
进程的结构通常包括以下几个主要部分:
-
程序段(Text Segment):
- 程序段包含了程序的机器指令代码,这些代码在被操作系统加载到内存后,用于执行程序的逻辑。
- 在内存中,程序段通常是只读的,以防止程序被意外修改。
-
数据段(Data Segment):
- 数据段用于存储程序在运行时使用的全局变量和静态变量。
- 它包括已初始化的全局变量和静态变量,这些变量在程序运行期间可以被读取和修改。
-
进程控制块(Process Control Block, PCB):
- PCB是操作系统用来管理和控制进程的数据结构。
- 它包含了进程的各种信息,如程序代码存放位置、进程状态、对资源的占用情况、运行信息等。
-
- PCB是操作系统进行资源分配和调度的关键数据结构。
-
此外,进程还可能包含以下部分:
-
BSS段(Block Started by Symbol Segment):
- BSS段用于存储未初始化的全局变量和静态变量。
- 与数据段不同,BSS段在内存中不占用实际的存储空间,因为它只包含变量名,而不包含具体的初始值。
-
堆区(Heap):
- 堆区用于动态内存分配,程序员可以在运行时请求分配任意大小的内存块。
- 这些内存块通常用于存储程序在运行过程中创建的对象或数据结构。
-
栈区(Stack):
- 栈区用于存储函数的局部变量、函数参数以及返回地址等信息。
- 每当函数调用发生时,都会在栈上分配一个新的栈帧(stack frame),用于保存该次函数调用的相关信息。
- 栈区的大小通常是有限的,过多的递归调用或过大的局部变量可能会导致栈溢出。
-
进程的结构使得操作系统能够有效地管理和调度进程,确保它们能够正确地执行并共享系统资源。同时,进程的结构也提供了足够的灵活性,以支持各种复杂的程序设计和运行时需求
11. 结合进程管理命令,说明进程各种状态
12. 说明IPC通信和RPC通信实现的方式
IPC(进程间通信)和RPC(远程过程调用)是两种不同但相关的通信机制,它们在实现方式上有一些显著的区别。以下是它们各自实现方式的详细说明:
IPC(进程间通信)实现方式
IPC允许在同一计算机的不同进程之间进行通信。常见的IPC实现方式包括:
-
管道(Pipe):
- 管道是一种最基本的IPC机制,提供单向通信。一个进程将数据写入管道的一端,另一个进程从另一端读取数据。
-
消息队列(Message Queue):
- 消息队列允许多个进程之间通过消息进行异步通信。消息队列支持优先级和消息长度等属性。
-
共享内存(Shared Memory):
- 共享内存允许多个进程访问同一块内存区域,从而实现高效的数据共享和通信。通常与信号量一起使用以同步对共享内存的访问。
-
信号(Signal):
- 信号是一种异步通信机制,用于通知进程某个事件的发生。例如,一个进程可以向另一个进程发送信号以请求其执行某个操作或终止。
-
套接字(Socket):
- 套接字不仅用于网络通信,也可以用于同一计算机上的进程间通信。通过套接字,进程可以建立连接并交换数据。
RPC(远程过程调用)实现方式
RPC允许一个计算机程序通过网络调用另一个计算机程序中的子程序(远程过程),并获取返回值。RPC的实现通常包括以下步骤:
-
接口定义:
- RPC需要定义一个接口,描述远程服务的方法、参数和返回类型。这可以通过IDL(接口定义语言)来完成,如Apache Thrift的Thrift IDL或gRPC的Protocol Buffers IDL。
-
代码生成:
- 根据IDL文件,RPC框架可以自动生成客户端和服务器的存根代码。这些代码负责序列化和反序列化调用请求和结果,以及通过网络发送和接收消息。
-
网络传输:
- RPC框架底层通常使用TCP/IP、UDP等网络协议进行通信。为了优化性能和可靠性,一些RPC框架还支持更高级的网络传输协议,如HTTP/2。
-
序列化和反序列化:
- RPC框架需要一种高效的序列化机制来将调用请求和结果转换为字节流进行传输。常见的序列化格式包括JSON、XML、Protobuf等。
-
服务注册与发现:
- 在大规模分布式系统中,服务注册与发现是实现节点间通信的关键。RPC框架通常集成服务注册中心(如Eureka、Consul、Zookeeper等),以便客户端能够发现远程服务的地址并进行调用。
-
负载均衡和容错:
- RPC框架通常支持负载均衡机制,以提高系统的可用性和吞吐量。同时,它们还提供容错机制以应对网络故障、服务宕机等异常情况,如超时重试、服务降级等。
总结
- IPC主要关注在同一计算机的不同进程之间进行通信,实现方式包括管道、消息队列、共享内存、信号和套接字等。
- RPC则允许通过网络调用远程程序中的子程序,并获取返回值,实现方式包括接口定义、代码生成、网络传输、序列化和反序列化、服务注册与发现、负载均衡和容错等。
两者在实现方式和应用场景上有明显的区别,但都是为了在不同程序或进程之间实现有效的通信和数据交换。
13. 总结Linux,前台和后台作业的区别,并说明如何在前台和后台中进行状态转换
前台作业:通过终端启动,且启动后一直占据终端
后台作业:可通过终端启动,但启动后即转入后台运行(释放终端)
让作业运行于后台
运行中的作业: Ctrl+z #使占据终端的进程暂停,让出终端
尚未启动的作业: COMMAND &
后台作业虽然被送往后台运行,但其依然与终端相关;退出终端,将关闭后台作业。
如果希望送往后台后,剥离与终端的关系
nohup COMMAND &>/dev/null &
screen;COMMAND
tmux;COMMAND
fg [[%]JOB_NUM] #把指定的后台作业调回前台
bg [[%]JOB_NUM] #让送往后台的作业在后台继续运行
kill [%JOB_NUM] #终止指定的作业
查看当前终端所有作业:
[root@ubuntu ~]# jobs
[1] Stopped ping www.baidu.com
[2]- Stopped ./a.sh 123
[3]+ Stopped ./a.sh 456
14. 实现定时任务,每日凌晨1点,删除指定文件
0 1 * * * /bin/rm /path/to/your/file
15. 实现定时任务每月月初对指定文件进行压缩
0 0 1 * * /usr/bin/tar -czf /path/to/destination/archive-$(date +\%Y\%m).tar.gz /path/to/your/file
16. 通过shell编程完成,30鸡和兔的头,80鸡和兔的脚,分别有几只鸡,几只兔?
#!/bin/bash
# 初始化头数和脚数
heads=30
legs=80
# 循环遍历可能的鸡的数量
for chickens in $(seq 1 $heads); do
# 计算兔的数量
rabbits=$((heads - chickens))
# 检查是否满足脚数总和的条件
if [ $((2 * chickens + 4 * rabbits)) -eq $legs ]; then
echo "鸡的数量: $chickens"
echo "兔的数量: $rabbits"
exit 0 # 找到解后退出循环
fi
done
# 如果没有找到解,则输出无解信息
echo "无解"
exit 1
17. 结合编程的for循环,条件测试,条件组合,完成批量创建100个用户,
1)for遍历1…100
2)先id判断是否存在
3)用户存在则说明存在,用户不存在则添加用户并说明已添加。
#!/bin/bash
# 遍历1到100的数字
for i in $(seq 1 100); do
# 构造用户名,这里假设用户名为user1, user2, ..., user100
USERNAME="user$i"
# 使用id命令检查用户是否存在
if id "$USERNAME" &>/dev/null; then
# 如果用户存在,则输出消息
echo "用户 $USERNAME 已存在"
else
# 如果用户不存在,则创建用户并输出消息
useradd "$USERNAME"
if [ $? -eq 0 ]; then
echo "用户 $USERNAME 已添加"
else
echo "用户添加失败 $USERNAME."
fi
fi
done
echo "结束."

















 13万+
13万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









