







十二、java内存模型
JMM 即 Java Memory Model,它定义了主存、工作内存抽象概念,底层对应着 CPU 寄存器、缓存、硬件内存、CPU 指令优化等。
JMM 体现在以下几个方面:
- 原子性 - 保证指令不会受到线程上下文切换的影响
- 可见性 - 保证指令不会受 cpu 缓存的影响
- 有序性 - 保证指令不会受 cpu 指令并行优化的影响
1. 可见性
static boolean flag = true;
public static void main(String[] args) throws InterruptedException {
new Thread(() -> {
System.out.println("t1 start...");
while (flag) {
}
System.out.println("t1 end...");
}, "t1").start();
Thread.sleep(1000);
flag = false; // 主线程修改了flag为false,t1线程也不会停止
}
分析:
- 初始状态, t 线程刚开始从主内存读取了 run 的值到工作内存。
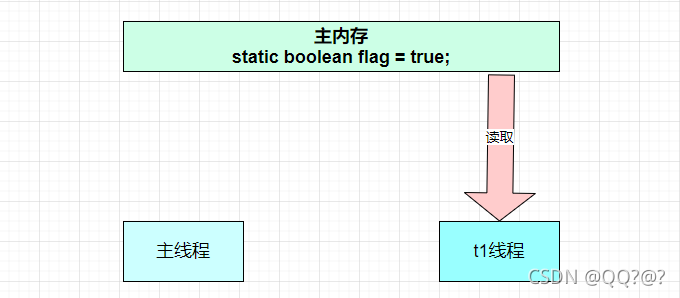
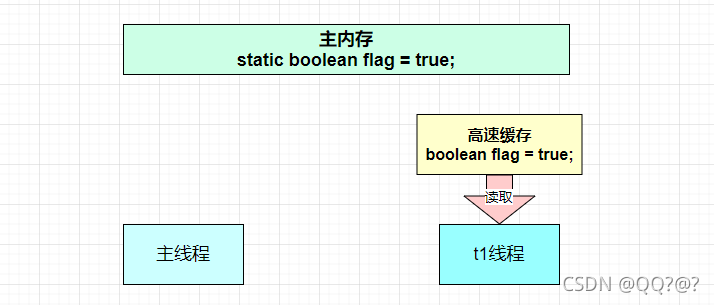
- 因为 t 线程要频繁从主内存中读取 run 的值,JIT 编译器会将 run 的值缓存至自己工作内存中的高速缓存中,减少对主存中 run 的访问,提高效率
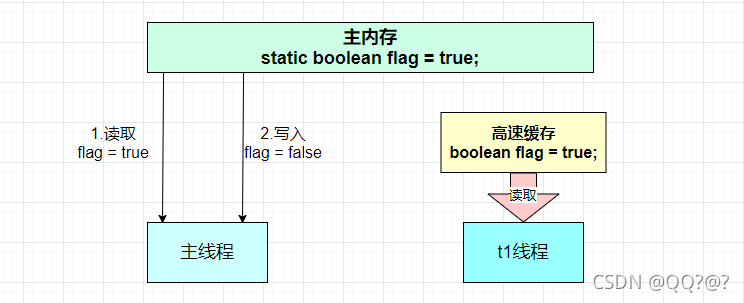
- 1 秒之后,main 线程修改了 run 的值,并同步至主存,而 t 是从自己工作内存中的高速缓存中读取这个变量的值,结果永远是旧值
解决方法
volatile(易变关键字)
它可以用来修饰成员变量和静态成员变量,他可以避免线程从自己的工作缓存中查找变量的值,必须到主存中获取它的值,线程操作 volatile 变量都是直接操作主存
volatile static boolean flag = true;
public static void main(String[] args) throws InterruptedException {
new Thread(() -> {
System.out.println("t1 start...");
while (flag) {
}
System.out.println("t1 end...");
}, "t1").start();
Thread.sleep(1000);
flag = false; // 主线程修改了flag为false,t1线程也不会停止
}
1.同步模式 – 犹豫模式 (Balking)
Balking (犹豫)模式用在一个线程发现另一个线程或本线程已经做了某一件相同的事,那么本线程就无需再做了,直接结束返回
public class Test19 {
public static void main(String[] args) throws InterruptedException {
TPTVolatile tptVolatile = new TPTVolatile();
tptVolatile.start();
tptVolatile.start();
// zhihu
}
}
class TPTVolatile {
private Thread thread;
private volatile boolean stop = false;
private volatile boolean started = false;
public void start() {
// 检查是否已经启动过
synchronized (this) {
if (started) return;
started = true;
}
thread = new Thread(() -> {
while (true) {
if (stop) {
System.out.println(Thread.currentThread().getName() + " 料理后事");
break;
}
try {
Thread.sleep(1000);
System.out.println("执行监控记录");
} catch (InterruptedException e) {
System.out.println("打断监控线程");
}
}
}, "监控线程");
thread.start();
}
public void stop() {
stop = true;
thread.interrupt();
}
}
2. 有序性
int num = 0;
boolean ready = false;
// 线程1 执行此方法
public void actor1(I_Result r) {
if(ready) {
r.r1 = num + num;
} else {
r.r1 = 1;
}
}
// 线程2 执行此方法
public void actor2(I_Result r) {
num = 2;
ready = true;
}
I_Result 是一个对象,有一个属性 r1 用来保存结果,问,可能的结果有几种?
- 情况1:线程1 先执行,这时 ready = false,所以进入 else 分支结果为 1
- 情况2:线程2 先执行 num = 2,但没来得及执行 ready = true,线程1 执行,还是进入 else 分支,结果为1
- 情况3:线程2 执行到 ready = true,线程1 执行,这回进入 if 分支,结果为 4(因为 num 已经执行过了)
- 还有一种诡异的结果为0,这种情况下是:线程2 执行 ready = true,切换到线程1,进入 if 分支,相加为 0,再切回线程2 执行 num = 2
这种现象叫做指令重排,是 JIT 编译器在运行时的一些优化
volatile 修饰的变量,可以禁用指令重排,这样就不会有0这样的结果出现了
int num = 0;
boolean volatile ready = false;
// 线程1 执行此方法
public void actor1(I_Result r) {
if(ready) {
r.r1 = num + num;
} else {
r.r1 = 1;
}
}
// 线程2 执行此方法
public void actor2(I_Result r) {
num = 2;
ready = true;
}
3. volatile原理
volatile 的底层实现原理是内存屏障,Memory Barrier(Memory Fence)
- 对 volatile 变量的写指令后会加入写屏障
- 对 volatile 变量的读指令前会加入读屏障
1. 保证可见性
写屏障(sfence)保证在该屏障之前的,对共享变量的改动,都同步到主存当中
public void actor2(I_Result r) {
num = 2;
ready = true; // ready 是 volatile 赋值带写屏障
// 写屏障
}
而读屏障(lfence)保证在该屏障之后,对共享变量的读取,加载的是主存中最新数据
public void actor1(I_Result r) {
// 读屏障
// ready 是 volatile 读取值带读屏障
if(ready) {
r.r1 = num + num;
} else {
r.r1 = 1;
}
}
2. 保证有序性
写屏障会确保指令重排序时,不会将写屏障之前的代码排在写屏障之后
public void actor2(I_Result r) {
num = 2;
ready = true; // ready 是 volatile 赋值带写屏障
// 写屏障
}
读屏障会确保指令重排序时,不会将读屏障之后的代码排在读屏障之前
public void actor1(I_Result r) {
// 读屏障
// ready 是 volatile 读取值带读屏障
if(ready) {
r.r1 = num + num;
} else {
r.r1 = 1;
}
}
3. 不能保证原子性
不能解决指令交错:
- 写屏障仅仅是保证之后的读能够读到最新的结果,但不能保证读跑到它前面去
- 而有序性的保证也只是保证了本线程内相关代码不被重排序
4. 单例模式–双重检查锁问题(volatile禁止指令重排)
public final class Singleton {
private Singleton() {}
private static Singleton INSTANCE = NULL;
public static Singleton getInstance() {
if(INSTANCE == null) {
// 首次访问INSTANCE为空才会同步,而之后的使用没有 synchronized
synchronized(Singleton.class) {
if(INSTANCE == null) {
INSTANCE = new Singleton();
}
}
}
return INSTANCE;
}
}
以上的实现特点是:
- 懒惰实例化
- 首次使用 getInstance() 才使用 synchronized 加锁,后续使用时无需加锁
- 有隐含的,但很关键的一点:第一个 if 使用了 INSTANCE 变量,是在同步块之外
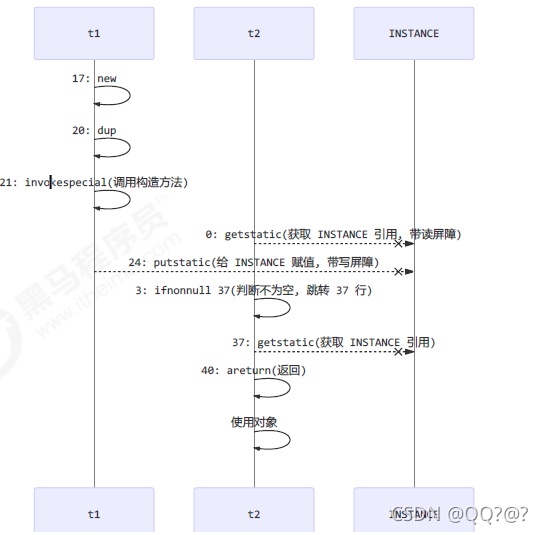
但在多线程环境下,上面的代码是有问题的,getInstance 方法对应的字节码为:
0: getstatic #2 // Field INSTANCE:Lcn/itcast/n5/Singleton;
3: ifnonnull 37
6: ldc #3 // class cn/itcast/n5/Singleton
8: dup
9: astore_0
10: monitorenter
11: getstatic #2 // Field INSTANCE:Lcn/itcast/n5/Singleton;
14: ifnonnull 27
17: new #3 // class cn/itcast/n5/Singleton 表示创建对象,将对象引用入栈
20: dup // 表示复制一份对象引用
21: invokespecial #4 // Method "<init>":()V 表示利用一个对象引用,调用构造方法
24: putstatic #2 // Field INSTANCE:Lcn/itcast/n5/Singleton; 表示利用一个对象引用,赋值给 static INSTANCE
27: aload_0
28: monitorexit
29: goto 37
32: astore_1
33: aload_0
34: monitorexit
35: aload_1
36: athrow
37: getstatic #2 // Field INSTANCE:Lcn/itcast/n5/Singleton;
40: areturn
也许 jvm 会优化为:先执行 24,再执行 21。
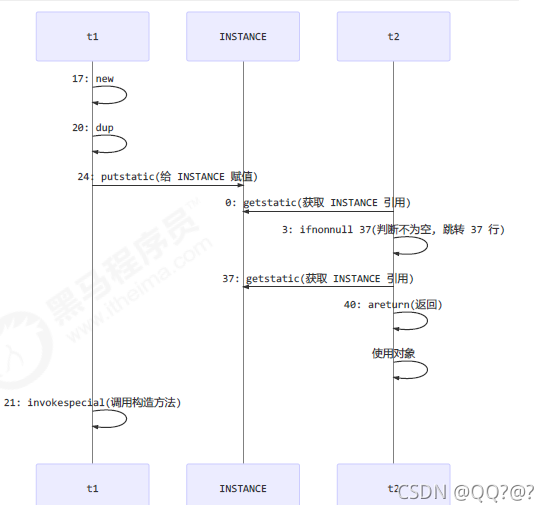
getstatic 这行代码(第一个看 INSTANCE 是否为空的判断)在 monitor 控制之外(synchronized代码块之外),它就像之前举例中不守规则的人,可以越过 monitor 读取 INSTANCE 变量的值
这时 t1 还未完全将构造方法执行完毕,如果在构造方法中要执行很多初始化操作,那么 t2 拿到的是将是一个未初始化完毕的单例
这里要重点注意的是: synchronized 可以保证 原子性、可见性和有序性,但是不能保证代码不会发生指令重排序
而这里的有序性指的是:当一段代码被 synchronized 包裹时,它可以保证这段代码在任意时刻都只有一个线程在使用,可以类似的看作是单线程的,这时即使内部做了指令重排序,也不会影响这段代码最终的结果,因为这段代码不会有其他线程进行干扰。
java中通过 synchronized 提供的锁机制,确保了在加锁和解锁过程中的逻辑执行是单线程的,也就满足了符合as-if-serial语义,从而实现了有序性。这里的有序性指的是符合单线程中的有序性as-if-serial语义
使用volatile解决此问题
对 INSTANCE 使用 volatile 修饰即可,可以禁用指令重排,但要注意在 JDK 5 以上的版本的 volatile 才会真正有效
public final class Singleton {
private Singleton() { }
private static volatile Singleton INSTANCE = null;
public static Singleton getInstance() {
// 实例没创建,才会进入内部的 synchronized代码块
if (INSTANCE == null) {
synchronized (Singleton.class) { // t2
// 也许有其它线程已经创建实例,所以再判断一次
if (INSTANCE == null) { // t1
INSTANCE = new Singleton();
}
}
}
return INSTANCE;
}
}
// -------------------------------------> 加入对 INSTANCE 变量的读屏障
0: getstatic #2 // Field INSTANCE:Lcn/itcast/n5/Singleton;
3: ifnonnull 37
6: ldc #3 // class cn/itcast/n5/Singleton
8: dup
9: astore_0
10: monitorenter // -----------------------> 保证原子性、可见性
11: getstatic #2 // Field INSTANCE:Lcn/itcast/n5/Singleton;
14: ifnonnull 27
17: new #3 // class cn/itcast/n5/Singleton
20: dup
21: invokespecial #4 // Method "<init>":()V
24: putstatic #2 // Field INSTANCE:Lcn/itcast/n5/Singleton;
// -------------------------------------> 加入对 INSTANCE 变量的写屏障
27: aload_0
28: monitorexit // ------------------------> 保证原子性、可见性
29: goto 37
32: astore_1
33: aload_0
34: monitorexit
35: aload_1
36: athrow
37: getstatic #2 // Field INSTANCE:Lcn/itcast/n5/Singleton;
40: areturn
如上面的注释内容所示,读写 volatile 变量时会加入内存屏障(Memory Barrier(Memory Fence)),保证下面两点:
- 可见性
写屏障(sfence)保证在该屏障之前的 t1 对共享变量的改动,都同步到主存当中
而读屏障(lfence)保证在该屏障之后 t2 对共享变量的读取,加载的是主存中最新数据 - 有序性
写屏障会确保指令重排序时,不会将写屏障之前的代码排在写屏障之后
读屏障会确保指令重排序时,不会将读屏障之后的代码排在读屏障之前
- 更底层是读写变量时使用 lock 指令来多核 CPU 之间的可见性与有序性
5. 为什么synchronized无法禁止指令重排,却能保证有序性
4. happens-before规则
happens-before 规定了对共享变量的写操作对其它线程的读操作可见,它是可见性与有序性的一套规则总结,抛开以下 happens-before 规则,JMM 并不能保证一个线程对共享变量的写,对于其它线程对该共享变量的读可见
- 线程解锁 m 之前对变量的写,对于接下来对 m 加锁的其它线程对该变量的读可见
static int x;
static Object m = new Object();
new Thread(()->{
synchronized(m) {
x = 10;
}
},"t1").start();
new Thread(()->{
synchronized(m) {
System.out.println(x);
}
},"t2").start();
- 线程对 volatile 变量的写,对接下来其它线程对该变量的读可见
volatile static int x;
new Thread(()->{
x = 10;
},"t1").start();
new Thread(()->{
System.out.println(x);
},"t2").start();
- 线程 start 前对变量的写,对该线程开始后对该变量的读可见
static int x;
x = 10;
new Thread(()->{
System.out.println(x);
},"t2").start();
- 线程结束前对变量的写,对其它线程得知它结束后的读可见(比如其它线程调用 t1.isAlive() 或 t1.join() 等待它结束)
static int x;
Thread t1 = new Thread(()->{
x = 10;
},"t1");
t1.start();
t1.join();
System.out.println(x);
- 线程 t1 打断 t2(interrupt)前对变量的写,对于其他线程得知 t2 被打断后对变量的读可见(通过
t2.interrupted 或 t2.isInterrupted)
static int x;
public static void main(String[] args) {
Thread t2 = new Thread(()->{
while(true) {
if(Thread.currentThread().isInterrupted()) {
System.out.println(x);
break;
}
}
},"t2");
t2.start();
new Thread(()->{
sleep(1);
x = 10;
t2.interrupt();
},"t1").start();
while(!t2.isInterrupted()) {
Thread.yield();
}
System.out.println(x);
}
- 对变量默认值(0,false,null)的写,对其它线程对该变量的读可见
- 具有传递性,如果 x happens-before y 并且 y happens-before z 那么有 x happens-before z ,配合 volatile 的防指令重排,有下面的例子
volatile static int x;
static int y;
new Thread(()->{
y = 10;
x = 20;
},"t1").start();
new Thread(()->{
// x=20 对 t2 可见, 同时 y=10 也对 t2 可见
System.out.println(x);
},"t2").start();
5. 线程安全–单例模式相关问题
1. 实现1
// 问题1:为什么加 final
// 问题2:如果实现了序列化接口, 还要做什么来防止反序列化破坏单例
public final class Singleton implements Serializable {
// 问题3:为什么设置为私有? 是否能防止反射创建新的实例?
private Singleton() {}
// 问题4:这样初始化是否能保证单例对象创建时的线程安全?
private static final Singleton INSTANCE = new Singleton();
// 问题5:为什么提供静态方法而不是直接将 INSTANCE 设置为 public, 说出你知道的理由
public static Singleton getInstance() {
return INSTANCE;
}
}
问题1:为什么加 final?
防止子类继承该类,并重写内部的一些方法或实现一些方法,来破坏单例的实现
问题2:如果实现了序列化接口, 还要做什么来防止反序列化破坏单例?// 实现readResolve方法,直接将对象返回。 // 因为如果已经实现了readResolve方法,反系列化后就会直接使用readResolve的返回值 public Object readResolve() { return INSTANCE; }问题3:为什么设置为私有? 是否能防止反射创建新的实例?
设置为私有就能防止直接调用构造器来new创建对象;但是不能防止反射创建新实例,因为反射中提供了暴力反射的方式来使用private的方法
问题4:这样初始化是否能保证单例对象创建时的线程安全?
可以。因为INSTANCE是静态类变量,类初始化时调用JVM的clinit方法来创建静态变量,由JVM保> 证线程安全(虚拟机必须保证一个类的clinit()方法在多线程下被同步加锁)
问题5:为什么提供静态方法而不是直接将 INSTANCE 设置为 public?说出你知道的理由
使用公共的静态方法,提供更好的封装性;为之后改进为懒汉式单例提供前提;方法支持泛型的使用
2. 实现2
// 问题1:枚举单例是如何限制实例个数的
// 问题2:枚举单例在创建时是否有并发问题
// 问题3:枚举单例能否被反射破坏单例
// 问题4:枚举单例能否被反序列化破坏单例
// 问题5:枚举单例属于懒汉式还是饿汉式
// 问题6:枚举单例如果希望加入一些单例创建时的初始化逻辑该如何做
enum Singleton {
INSTANCE;
}
问题1:枚举单例是如何限制实例个数的?
通过查看字节码可以知道,INSTANCE只是枚举类下的一个静态成员变量,由JVM保证单例(类型的初始化方法clinit只在该类型被加载时才执行,且只执行一次)
问题2:枚举单例在创建时是否有并发问题?
没有。由JVM保证线程安全
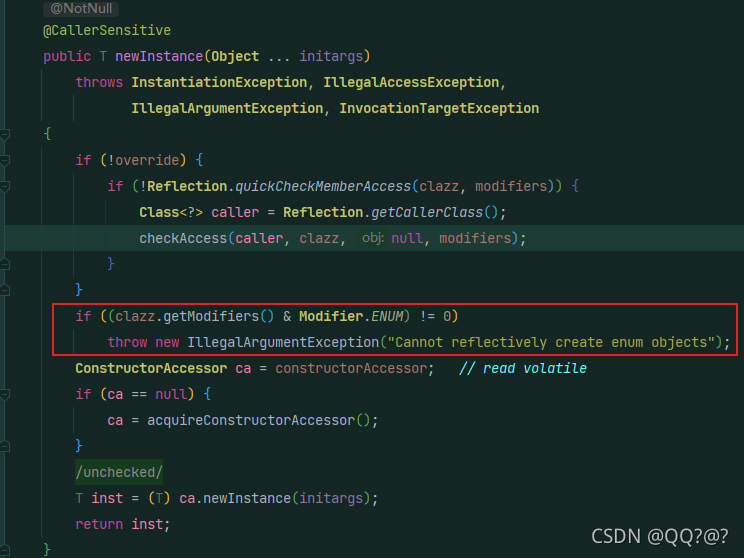
问题3:枚举单例能否被反射破坏单例?
不能,反射在通过newInstance创建对象时,会检查该类是否ENUM修饰,如果是则抛出异常,反射失败。
问题4:枚举单例能否被反序列化破坏单例?
不能;因为ENUM父类中的反序列化是通过valueOf实现的,不是通过反射
问题5:枚举单例属于懒汉式还是饿汉式?
饿汉式
问题6:枚举单例如果希望加入一些单例创建时的初始化逻辑该如何做?
加一个构造方法即可

3. 实现3(懒汉式)
public final class Singleton {
private Singleton() { }
private static Singleton INSTANCE = null;
// 分析这里的线程安全, 并说明有什么缺点
public static synchronized Singleton getInstance() {
if( INSTANCE != null ){
return INSTANCE;
}
INSTANCE = new Singleton();
return INSTANCE;
}
}
锁粒度太大,导致每次调用都要对整个方法加锁,影响性能
4. 实现4(DCL)
public final class Singleton {
private Singleton() { }
// 问题1:解释为什么要加 volatile ?
private static volatile Singleton INSTANCE = null;
// 问题2:对比实现3, 说出这样做的意义
public static Singleton getInstance() {
if (INSTANCE != null) {
return INSTANCE;
}
synchronized (Singleton.class) {
// 问题3:为什么还要在这里加为空判断, 之前不是判断过了吗
if (INSTANCE != null) { // t2
return INSTANCE;
}
INSTANCE = new Singleton();
return INSTANCE;
}
}
}
问题1:解释为什么要加 volatile ?
防止INSTANCE = new Singleton();指令重排序造成的空对象的创建,保证拿到的对象是完整调用构造方法的,具体可以看(十二、内存模型 – 3.volatile原理 – 4.单例模式 – 双重检查锁问题)
问题2:对比实现3, 说出这样做的意义
只有第一次调用创建对象的时候才会加锁,对象创建好之后在调用此方法,就会直接判断并返回实例,不会多次加锁,提高了性能
问题3:为什么还要在这里加为空判断, 之前不是判断过了吗
防止首次创建对象时,并发的问题。一个线程进入 synchronized 创建对象之时,如果另一个线程也调用了getInstance()方法,那么此时判断该对象为空,会阻塞在 synchronized 这里,当第一个线程创建完对象之后,第二个线程就会进入 synchronized 代码块,如果这时没有为空判断,就会在创建一个对象,破坏了单例。
5. 实现5
public final class Singleton {
private Singleton() { }
// 问题1:属于懒汉式还是饿汉式
private static class LazyHolder {
static final Singleton INSTANCE = new Singleton();
}
// 问题2:在创建时是否有并发问题
public static Singleton getInstance() {
return LazyHolder.INSTANCE;
}
}
问题1:属于懒汉式还是饿汉式
懒汉式;定义静态内部类,只有第一次被使用时(第一次通过Singleton类调用getInstance()方法时),才会触发类的加载操作,从而初始化创建INSTANCE实例
问题2:在创建时是否有并发问题
不存在并发问题,同样的,类的初始化操作会由JVM保证只执行一次,并且会加锁保证线程安全
无锁(非阻塞)-乐观锁
十三、CAS应用
1. CAS
定义:CAS操作需要输入两个值,一个旧值(期望操作之前的值)和一个新值,在操作期间先比较旧值有没有发生改变,如果没有发生改变,才交换成新值;发生了变化则不交换
public class Test20 {
private AtomicInteger balance;
public Test20(Integer balance) {
this.balance = new AtomicInteger(balance);
}
// 获取余额
public Integer getBalance() {
return balance.get();
}
// 取钱,每次余额减amount
public void withdraw(Integer amount) {
while (true) {
int prev = balance.get(); // 先获取修改前的值
int next = prev - amount; // 减去 amount
// 调用原子类中的CAS方法
// 内部判断修改前的值和原来的值是否相等,相等则设置值为next
if (balance.compareAndSet(prev, next)) {
break;
}
}
}
}
其中的关键是 compareAndSet,它的简称就是 CAS (也有 Compare And Swap 的说法),它必须是原子操作。
注意:
其实 CAS 的底层是 lock cmpxchg 指令(X86 架构),在单核 CPU 和多核 CPU 下都能够保证【比较-交换】的原子性。
在多核状态下,某个核执行到带 lock 的指令时,CPU 会让总线锁住,当这个核把此指令执行完毕,再开启总线。这个过程中不会被线程的调度机制所打断,保证了多个线程对内存操作的准确性,是原子的。
CAS必须配合volatile使用
因为CAS修改变量之后,需要保证它是可以被其他线程读取到修改后的最新值的;所以需要使用volatile保证变量的可见性。
它可以用来修饰成员变量和静态成员变量,他可以避免线程从自己的工作缓存中查找变量的值,必须到主存中获取它的值,线程操作 volatile 变量都是直接操作主存。即一个线程对 volatile 变量的修改,对另一个线程可见。
注意volatile 仅仅保证了共享变量的可见性,让其它线程能够看到最新值,但不能解决指令交错问题
(不能保证原子性)(可以禁止指令重排,注意区分指令交错和指令重排的区别)
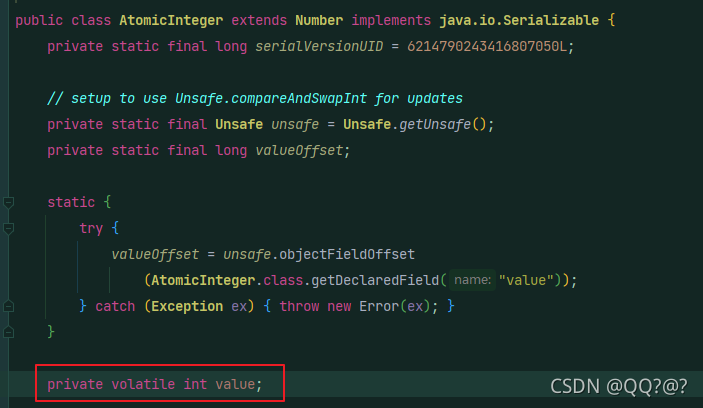
原子整数类底层源码,存储值的变量value就是用了volatile关键字来保证可见性:
CAS特点
结合 CAS 和 volatile 可以实现无锁并发,适用于线程数少、多核 CPU 的场景下。
- CAS 是基于乐观锁的思想:最乐观的估计,不怕别的线程来修改共享变量,就算改了也没关系,我吃亏点再重试呗。
- synchronized 是基于悲观锁的思想:最悲观的估计,得防着其它线程来修改共享变量,我上了锁你们都别想改,我改完了解开锁,你们才有机会。
- CAS 体现的是无锁并发、无阻塞并发,请仔细体会这两句话的意思
- 因为没有使用 synchronized,所以线程不会陷入阻塞,这是效率提升的因素之一
- 但如果竞争激烈,可以想到重试必然频繁发生,反而效率会受影响
2. 原子操作类
1. 原子整数
AtomicBoolean、AtomicInteger、AtomicLong
以AtomicInteger为例:
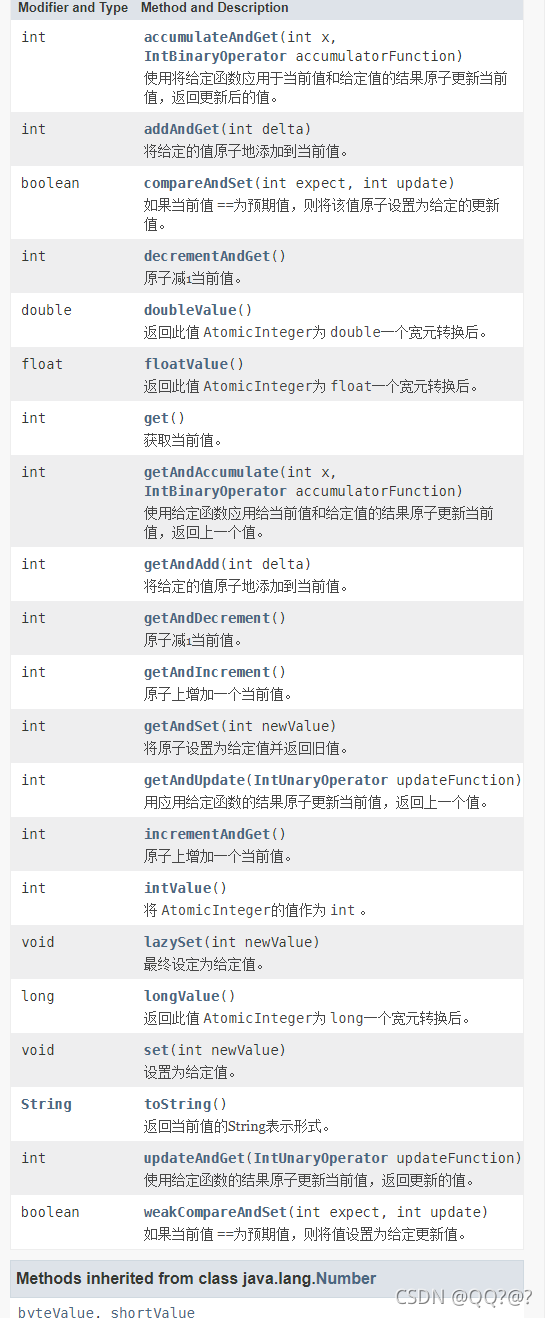
原理
1. 普通的自增操作:incrementAndGet()
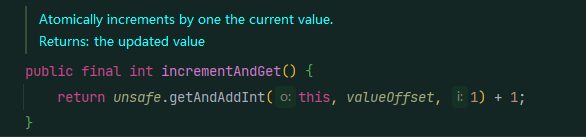
其底层还是使用了CAS操作(本地方法),从java角度可以类似看作是:
while (true) {
int prev = get(); // 先获取修改前的值
int next = prev - 1; // 减去 1
// 调用原子类中的CAS方法,内部判断修改前的值和原来的值是否相等,相等则设置值为next
if (balance.compareAndSet(prev, next)) {
break;
}
}
2. 可以进行复杂运算的方法:updateAndGet(IntUnaryOperator updateFunction)
其中IntUnaryOperator 是一个函数式接口,其中有一个抽象方法applyAsInt,这时我们可以使用lambda表达式对其进行具体实现。之后的执行逻辑就是,传入一个int类型的参数,然后根据我们实现的具体操作,对其进行修改,然后内部使用的还是CAS操作保证它的原子性,最后将修改成功之后的值作为返回值返回

源码
public final int updateAndGet(IntUnaryOperator updateFunction) {
int prev, next;
do {
prev = get();
next = updateFunction.applyAsInt(prev);
} while (!compareAndSet(prev, next));
return next;
}
2. 原子引用
AtomicReference
AtomicReference<BigDecimal> ref;
public DecimalAccountSafeCas(BigDecimal balance) {
ref = new AtomicReference<>(balance);
}
@Override
public BigDecimal getBalance() {
return ref.get();
}
@Override
public void withdraw(BigDecimal amount) {
// 依旧是使用CAS的原理
while (true) {
BigDecimal prev = ref.get();
BigDecimal next = prev.subtract(amount);
if (ref.compareAndSet(prev, next)) {
break;
}
}
}
ABA问题
因为CAS会比较共享变量的值和初始值是否相同,这时就会造成,如果刚好另外的线程将共享变量修改为与原值相同的值,这时原来的线程就没法感知到这个变化,还以为没有变化过,CAS依然成功
static AtomicReference<String> ref = new AtomicReference<>("A");
public static void main(String[] args) throws InterruptedException {
log.debug("main start...");
// 获取值 A
// 这个共享变量被它线程修改过?
String prev = ref.get();
other();
sleep(1);
// 尝试改为 C
log.debug("change A->C {}", ref.compareAndSet(prev, "C"));
}
private static void other() {
new Thread(() -> {
log.debug("change A->B {}", ref.compareAndSet(ref.get(), "B"));
}, "t1").start();
sleep(0.5);
new Thread(() -> {
log.debug("change B->A {}", ref.compareAndSet(ref.get(), "A"));
}, "t2").start();
}
主线程仅能判断出共享变量的值与最初值 A 是否相同,不能感知到这种从 A 改为 B 又 改回 A 的情况,如果主线程
希望:只要有其它线程【动过了】共享变量,那么自己的 cas 就算失败,这时,仅比较值是不够的,需要再加一个版本号
避免ABA问题
使用有版本号的原子类:AtomicStampedReference

AtomicMarkableReference

public static void main(String[] args) throws InterruptedException {
log.debug("main start...");
// 获取值 A
String prev = ref.getReference();
// 获取版本号
int stamp = ref.getStamp();
log.debug("版本 {}", stamp);
// 如果中间有其它线程干扰,发生了 ABA 现象
other();
sleep(1);
// 尝试改为 C
log.debug("change A->C {}", ref.compareAndSet(prev, "C", stamp, stamp + 1));
}
private static void other() {
new Thread(() -> {
log.debug("change A->B {}", ref.compareAndSet(ref.getReference(), "B",
ref.getStamp(), ref.getStamp() + 1));
log.debug("更新版本为 {}", ref.getStamp());
}, "t1").start();
sleep(0.5);
new Thread(() -> {
log.debug("change B->A {}", ref.compareAndSet(ref.getReference(), "A",
ref.getStamp(), ref.getStamp() + 1));
log.debug("更新版本为 {}", ref.getStamp());
}, "t2").start();
}
结果为:
15:41:34.891 c.Test36 [main] - main start...
15:41:34.894 c.Test36 [main] - 版本 0
15:41:34.956 c.Test36 [t1] - change A->B true
15:41:34.956 c.Test36 [t1] - 更新版本为 1
15:41:35.457 c.Test36 [t2] - change B->A true
15:41:35.457 c.Test36 [t2] - 更新版本为 2
15:41:36.457 c.Test36 [main] - change A->C false
AtomicStampedReference 可以给原子引用加上版本号,追踪原子引用整个的变化过程,如: A -> B -> A ->C ,通过AtomicStampedReference,我们可以知道,引用变量中途被更改了几次。
但是有时候,并不关心引用变量更改了几次,只是单纯的关心是否更改过,所以就有了AtomicMarkableReference
ref.compareAndSet(ref.getReference(), "A", true, false);
3. 原子数组
AtomicIntegerArray、AtomicLongArray、AtomicReferenceArray
/**
* 参数1,提供数组、可以是线程不安全数组或线程安全数组
* 参数2,获取数组长度的方法
* 参数3,自增方法,回传 array, index
* 参数4,打印数组的方法
*/
// supplier 提供者 无中生有 ()->结果
// function 函数 一个参数一个结果 (参数)->结果 , BiFunction (参数1,参数2)->结果
// consumer 消费者 一个参数没结果 (参数)->void, BiConsumer (参数1,参数2)->
// 此方法的目的是给一个长度为10的数组的各个索引位置自增到10000,看结果是否正确
private static <T> void demo(
Supplier<T> arraySupplier,
Function<T, Integer> lengthFun,
BiConsumer<T, Integer> putConsumer,
Consumer<T> printConsumer) {
List<Thread> ts = new ArrayList<>();
T array = arraySupplier.get();
int length = lengthFun.apply(array);
for (int i = 0; i < length; i++) {
// 每个线程对数组作 10000 次操作
ts.add(new Thread(() -> {
for (int j = 0; j < 10000; j++) {
putConsumer.accept(array, j % length);
}
}));
}
ts.forEach(t -> t.start()); // 启动所有线程
ts.forEach(t -> {
try {
t.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
}); // 等所有线程结束
printConsumer.accept(array);
}
1. 不安全数组(基础数组的创建,不能保证修改的原子性)
demo(
()->new int[10],
(array)->array.length,
(array, index) -> array[index]++,
array-> System.out.println(Arrays.toString(array))
);
结果
[9870, 9862, 9774, 9697, 9683, 9678, 9679, 9668, 9680, 9698]
2. 安全的数组(使用原子类中的数组类)
demo(
()-> new AtomicIntegerArray(10),
(array) -> array.length(),
(array, index) -> array.getAndIncrement(index),
array -> System.out.println(array)
);
结果
[10000, 10000, 10000, 10000, 10000, 10000, 10000, 10000, 10000, 10000]
4. 字段更新器
修改某个对象中的字段,保证原子操作
AtomicReferenceFieldUpdater (域 字段)、AtomicIntegerFieldUpdater、AtomicLongFieldUpdater
利用字段更新器,可以针对对象的某个域(Field)进行原子操作,只能配合 volatile 修饰的字段使用,否则会出现异常
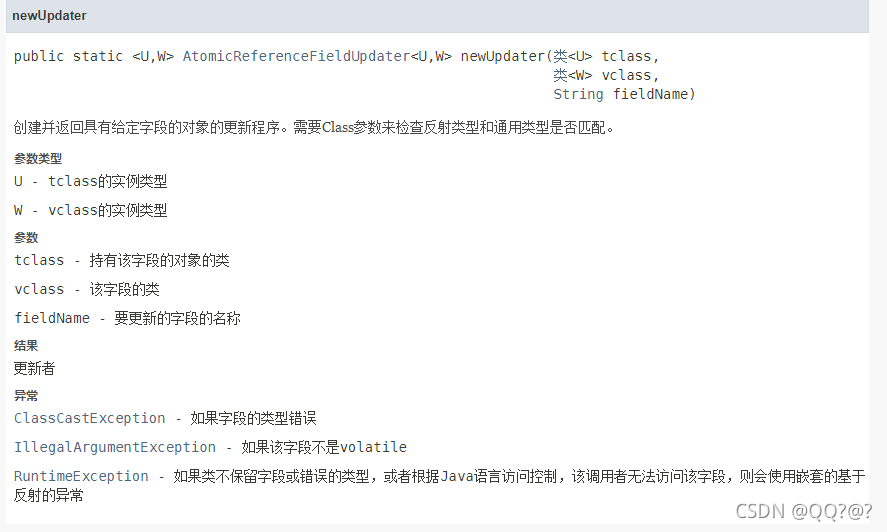
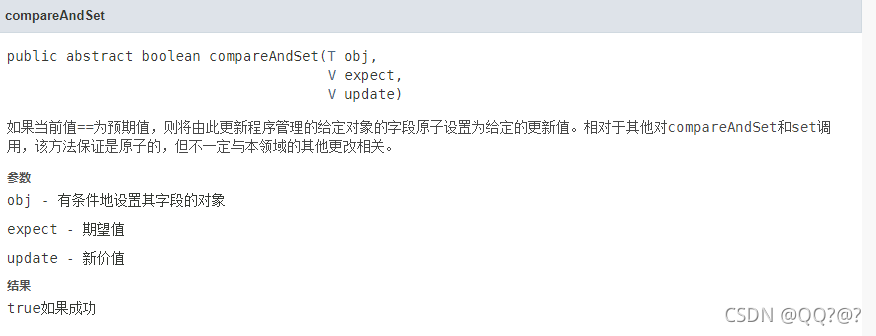
5. LongAdder原理 (源码)
LongAdder对比普通原子类的自增操作性能有很大提升;性能提升的原因很简单,就是在有竞争时,设置多个累加单元cells数组,Therad-0 累加 Cell[0],而 Thread-1 累加Cell[1]… 最后将结果汇总。这样它们在累加时操作的不同的 Cell 变量,因此减少了 CAS 重试失败,从而提高性能。
关键域:
// 累加单元数组, 懒惰初始化,**出现竞争时,会初始化创建**
transient volatile Cell[] cells;
// 基础值, 如果没有竞争, 则用 cas 累加这个域
transient volatile long base;
// 在 cells 创建或扩容时, 置为 1, 表示加锁
transient volatile int cellsBusy;
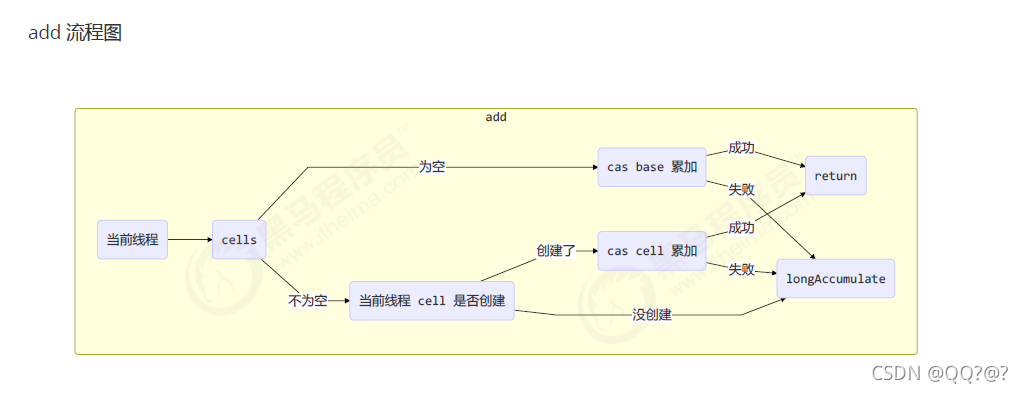
increment()方法 --> add方法(源码)
public void increment() {
add(1L);
}
public void add(long x) {
Cell[] as; long b, v; int m; Cell a;
// 判断cells数组是否为空,为空就使用casBase方法对base域累加,成功就直接返回
if ((as = cells) != null || !casBase(b = base, b + x)) {
// base累加失败,或者cells不为空,进入
boolean uncontended = true;
// as == null || (m = as.length - 1) < 0 || a = as[getProbe() & m]) == null 判断cell是否已经创建
// 如果没有创建,就直接进入调用longAccumulate()方法
// 如果创建了,就调用a.cas,对cells进行自增,成功直接返回,失败调用longAccumulate()方法
if (as == null || (m = as.length - 1) < 0 ||
(a = as[getProbe() & m]) == null ||
!(uncontended = a.cas(v = a.value, v + x)))
longAccumulate(x, null, uncontended);
}
}
longAccumulate()方法(源码)
final void longAccumulate(long x, LongBinaryOperator fn,
boolean wasUncontended) {
int h;
if ((h = getProbe()) == 0) {
ThreadLocalRandom.current(); // force initialization
h = getProbe();
wasUncontended = true;
}
boolean collide = false; // True if last slot nonempty
for (;;) {
Cell[] as; Cell a; int n; long v;
if ((as = cells) != null && (n = as.length) > 0) {
if ((a = as[(n - 1) & h]) == null) {
if (cellsBusy == 0) { // Try to attach new Cell // 看是否加锁
Cell r = new Cell(x); // Optimistically create 创建一个累加单元
if (cellsBusy == 0 && casCellsBusy()) { // 修改数组cells,加锁
// 加锁成功 进入
boolean created = false;
try { // Recheck under lock
Cell[] rs; int m, j;
// 查看cells中是否有别的已经创建了的累加单元
// 并判断cells中对应槽位是否为空
if ((rs = cells) != null &&
(m = rs.length) > 0 &&
rs[j = (m - 1) & h] == null) {
// 如果槽位为空,就讲自己创建的累加单元放入
rs[j] = r;
created = true;
}
} finally { // 解锁
cellsBusy = 0;
}
if (created)
break; // 创建成功
continue; // Slot is now non-empty
}
}
collide = false;
}
else if (!wasUncontended) // CAS already known to fail
wasUncontended = true; // Continue after rehash
else if (a.cas(v = a.value, ((fn == null) ? v + x :
fn.applyAsLong(v, x)))) // 直接cas累加原来累加单元的值
break; // 累加成功则返回
// 累加失败,走下面的逻辑
else if (n >= NCPU || cells != as) // 看CPU上线,看是否需要扩容累加单元数组
collide = false; // 超过了CPU上线,设置collide为false,下次循环就会走下面一个else if,就不会到else if (cellsBusy == 0 && casCellsBusy())扩容,而是直接改变线程对应的cell
else if (!collide)
collide = true;
// 没有超过CPU核数,累加单元数组扩容
else if (cellsBusy == 0 && casCellsBusy()) {
// 加锁成功,进入
try {
if (cells == as) { // Expand table unless stale
Cell[] rs = new Cell[n << 1]; // 累加数组扩容一倍
for (int i = 0; i < n; ++i)
rs[i] = as[i]; // 将原数组复制到新数组中
cells = rs; // 赋值给成员变量cells数组
}
} finally {
cellsBusy = 0; // 解锁
}
collide = false;
continue; // 然后就会再次循环,尝试对累加数组对应位置自增
}
h = advanceProbe(h);
}
// cellsBusy == 0 没有其他线程加锁; cells == as 没有其他线程创建cells数组
// 如果没有其他线程加锁 和 创建cells ,casCellsBusy()就把所标记位修改为1
// 加锁成功则 进入
else if (cellsBusy == 0 && cells == as && casCellsBusy()) {
boolean init = false;
try { // Initialize table
if (cells == as) { // 再次判断没有其他线程创建cells
Cell[] rs = new Cell[2]; // 初始化累加单元数组cells
rs[h & 1] = new Cell(x); // 初始化其中一个cell累加单元,并将值写入
cells = rs;
init = true;
}
} finally {
cellsBusy = 0;
}
if (init)
break;
}
// 如果加锁失败了,就cas累加vase,成功就结束了
else if (casBase(v = base, ((fn == null) ? v + x :
fn.applyAsLong(v, x))))
break; // Fall back on using base
}
}
最终获取结果sum()方法
public long sum() {
Cell[] as = cells; Cell a;
long sum = base; // 初始化为基础累加单元值
if (as != null) {
for (int i = 0; i < as.length; ++i) {
if ((a = as[i]) != null)
sum += a.value; // 循环累加,累加单元数组cells的各元素
}
}
return sum;
}
cells累加单元数组还没有创建好,else if (cellsBusy == 0 && cells == as && casCellsBusy())内部对应图:
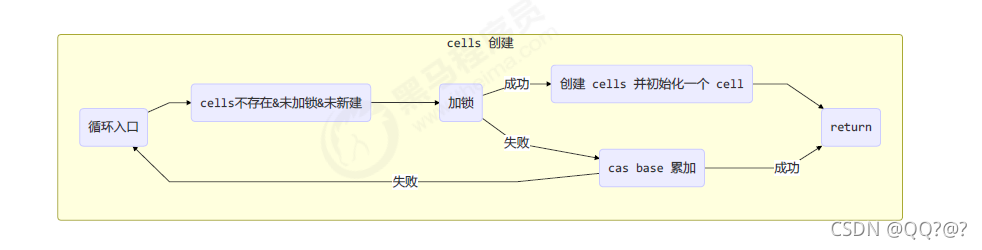
cells累加单元数组创建好了,但是累加单元还没有创建,if ((as = cells) != null && (n = as.length) > 0)内部对应图:
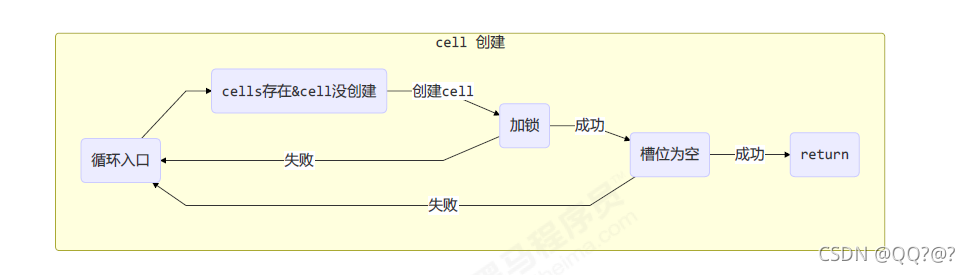
cells累加单元数组创建好了,累加单元也创建好了,else if (a.cas(v = a.value, ((fn == null) ? v + x : fn.applyAsLong(v, x))))内部对应图:
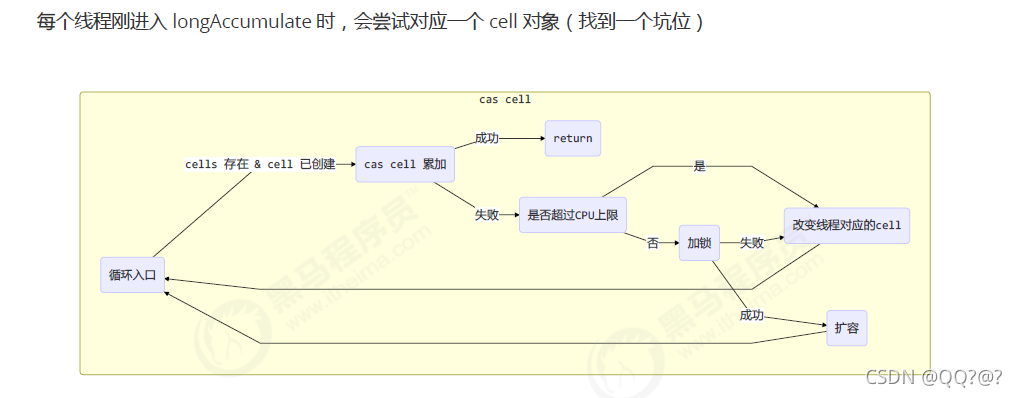
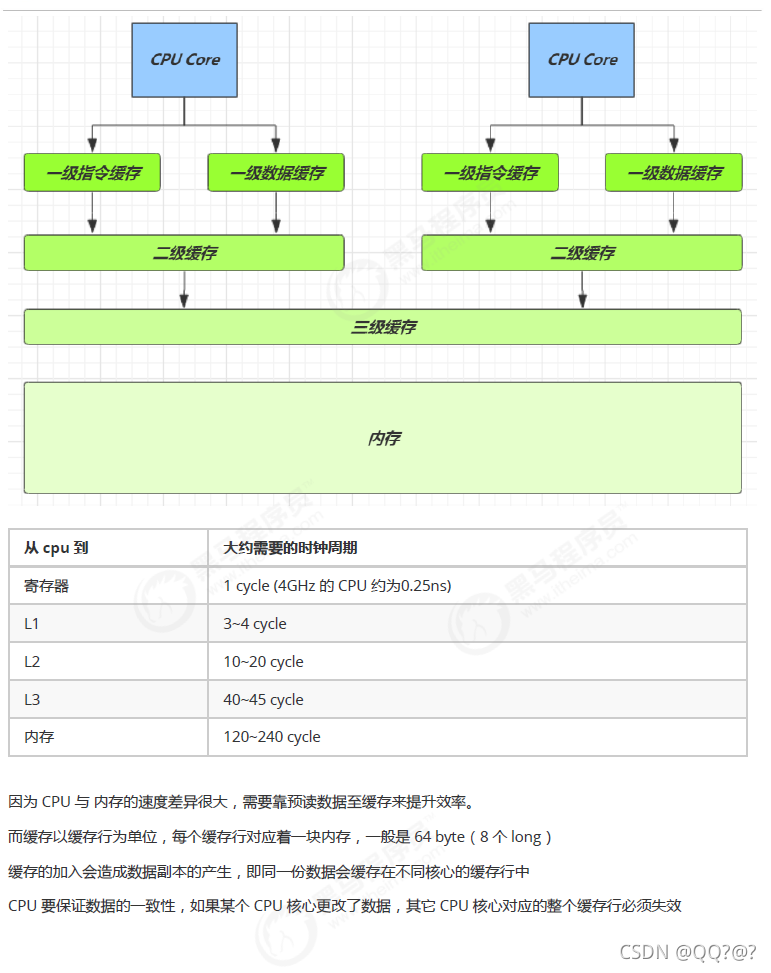
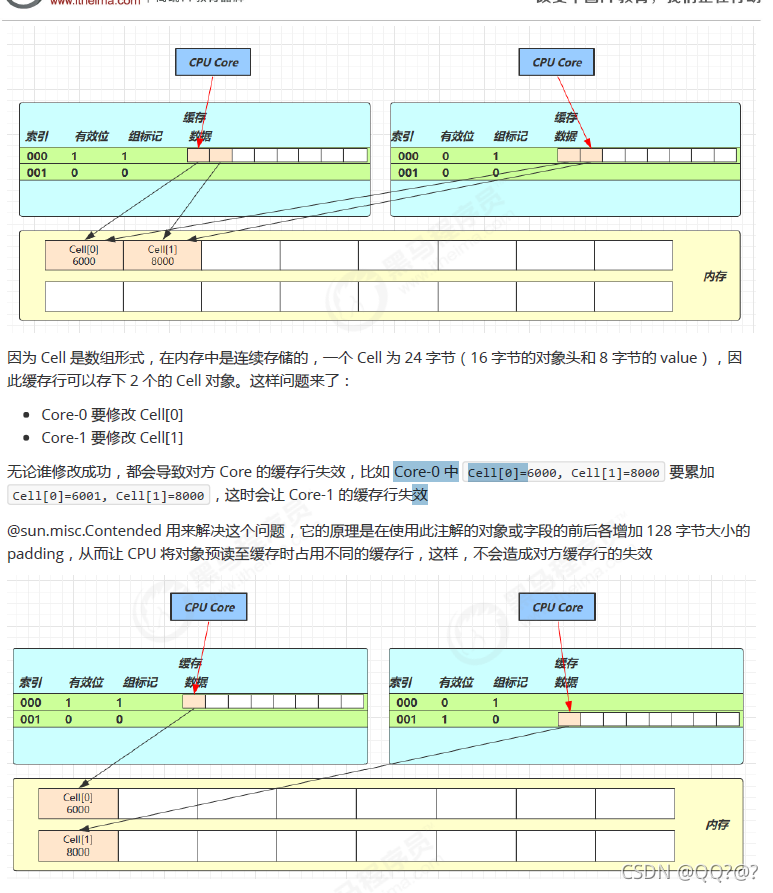
补充:缓存行填充 – 伪共享
// 此注解 防止缓存行伪共享
@sun.misc.Contended
static final class Cell {
volatile long value;
Cell(long x) { value = x; }
// 最重要的方法, 用来 cas 方式进行累加, prev 表示旧值, next 表示新值
final boolean cas(long prev, long next) {
return UNSAFE.compareAndSwapLong(this, valueOffset, prev, next);
}
// 省略不重要代码
}
3. Unsafe类
Unsafe 对象提供了非常底层的,操作内存、线程的方法,Unsafe 对象不能直接调用,只能通过反射获得
public class UnsafeAccessor {
static Unsafe unsafe;
static {
try {
Field theUnsafe = Unsafe.class.getDeclaredField("theUnsafe");
theUnsafe.setAccessible(true);
unsafe = (Unsafe) theUnsafe.get(null);
} catch (NoSuchFieldException | IllegalAccessException e) {
throw new Error(e);
}
}
static Unsafe getUnsafe() {
return unsafe;
}
}
使用Unsafe,自己手动实现一个原子类
class AtomicData {
private volatile int data;
static final Unsafe unsafe;
static final long DATA_OFFSET;
static {
unsafe = UnsafeAccessor.getUnsafe();
try {
// data 属性在 DataContainer 对象中的偏移量,用于 Unsafe 直接访问该属性
DATA_OFFSET = unsafe.objectFieldOffset(AtomicData.class.getDeclaredField("data"));
} catch (NoSuchFieldException e) {
throw new Error(e);
}
}
public AtomicData(int data) {
this.data = data;
}
public void decrease(int amount) {
int oldValue;
while(true) {
// 获取共享变量旧值,可以在这一行加入断点,修改 data 调试来加深理解
oldValue = this.data;
// cas 尝试修改 data 为 旧值 + amount,如果期间旧值被别的线程改了,返回 false
if (unsafe.compareAndSwapInt(this, DATA_OFFSET, oldValue, oldValue - amount)) {
return;
}
}
}
public int getData() {
return data;
}
}
十四、不可变类的并发
1. 最为常见的不可变类String

final的使用
发现该类、类中所有属性都是 final 的
- 属性用 final 修饰保证了该属性是只读的,不能修改
- 类用 final 修饰保证了该类中的方法不能被覆盖,防止子类无意间破坏不可变性
保护性拷贝
使用substring()方法举例
public String substring(int beginIndex) {
// 做边界正确性判断
if (beginIndex < 0) {
throw new StringIndexOutOfBoundsException(beginIndex);
}
int subLen = value.length - beginIndex;
if (subLen < 0) {
throw new StringIndexOutOfBoundsException(subLen);
}
// 如果从第0位开始切割,则不变返回原字符串
// 不是从第0位开始,则会调用有参构造创建新字符串
return (beginIndex == 0) ? this : new String(value, beginIndex, subLen);
}
public String(char value[], int offset, int count) {
if (offset < 0) {
throw new StringIndexOutOfBoundsException(offset);
}
if (count <= 0) {
if (count < 0) {
throw new StringIndexOutOfBoundsException(count);
}
if (offset <= value.length) {
this.value = "".value;
return;
}
}
// Note: offset or count might be near -1>>>1.
if (offset > value.length - count) {
throw new StringIndexOutOfBoundsException(offset + count);
}
// 底层中,使用copy方法,根据范围复制出一个新的数组,赋值给value
// 防止外部有数组和value使用相同的引用,导致内部value的改变
// 赋值一个新的数组,使用新的引用,不会产生此问题
this.value = Arrays.copyOfRange(value, offset, offset+count);
}
2. 享元模式
享元模式尝试重用现有的同类对象,如果未找到匹配的对象,则创建新对象。
1. 体现
1. 包装类
在JDK中 Boolean,Byte,Short,Integer,Long,Character 等包装类提供了 valueOf 方法,例如Long 的valueOf 会缓存 -128~127 之间的 Long 对象,在这个范围之间会重用对象,大于这个范围,才会新建 Long 对象。
// 内部类,会首先创建一个共享变量池,对于Long来说,是创建一个-128 ~ 127的池
// 当所取数字在此范围内,则不需要创建新的Long对象,而是从池中直接获取值
// 这就体现了享元模式,对同类值的重用
private static class LongCache {
private LongCache(){}
static final Long cache[] = new Long[-(-128) + 127 + 1];
static {
for(int i = 0; i < cache.length; i++)
cache[i] = new Long(i - 128);
}
}
public static Long valueOf(long l) {
final int offset = 128;
if (l >= -128 && l <= 127) { // will cache
return LongCache.cache[(int)l + offset];
}
return new Long(l);
}
注意:
- Byte, Short, Long 缓存的范围都是 -128~127
- Character 缓存的范围是 0~127
- Integer的默认范围是 -128~127
- 最小值不能变
- 但最大值可以通过调整虚拟机参数
-Djava.lang.Integer.IntegerCache.high来改变- Boolean 缓存了 TRUE 和 FALSE
2. BigDecimal BigInteger
3. String 字符串常量池(JVM)
2. 使用享元模式–自定义连接池
public class DIYThreadPool {
// 线程池数量
private final int poolSize;
// 连接数组对象
private Connection[] connections;
// 连接状态数组对象 0代表空闲, 1代表忙碌
private AtomicIntegerArray status;
public DIYThreadPool(int poolSize) {
this.poolSize = poolSize;
this.connections = new Connection[poolSize];
this.status = new AtomicIntegerArray(new int[poolSize]);
// 初始化连接池
for (int i = 0; i < poolSize; i++) {
connections[i] = new MockConnection("连接:" + i);
}
}
// 使用连接
public Connection borrow() {
// 尝试获取空闲连接
while (true) {
for (int i = 0; i < poolSize; i++) {
if (status.get(i) == 0) {
if (status.compareAndSet(i, 0, 1)) {
System.out.println("借出连接" + connections[i]);
return connections[i];
}
}
}
// 如果循环后没有空闲连接,就等待
synchronized (this) {
try {
System.out.println("没有连接,等待");
this.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
// 归还连接
public void free(Connection conn) {
// 判断连接是否存在于当前连接池
for (int i = 0; i < poolSize; i++) {
if (connections[i] == conn) {
status.set(i, 0);
System.out.println("归还连接:" + conn);
// 有空闲连接,唤醒等待的线程
synchronized (this) {
this.notifyAll();
}
break;
}
}
}
}
// 假的Connection连接类
class MockConnection implements Connection {
private String name;
public MockConnection(String name) {
this.name = name;
}
@Override
public String toString() {
return "MockConnection{" +
"name='" + name + '\'' +
'}';
}
// 其余都为默认,省略实现 ......
}
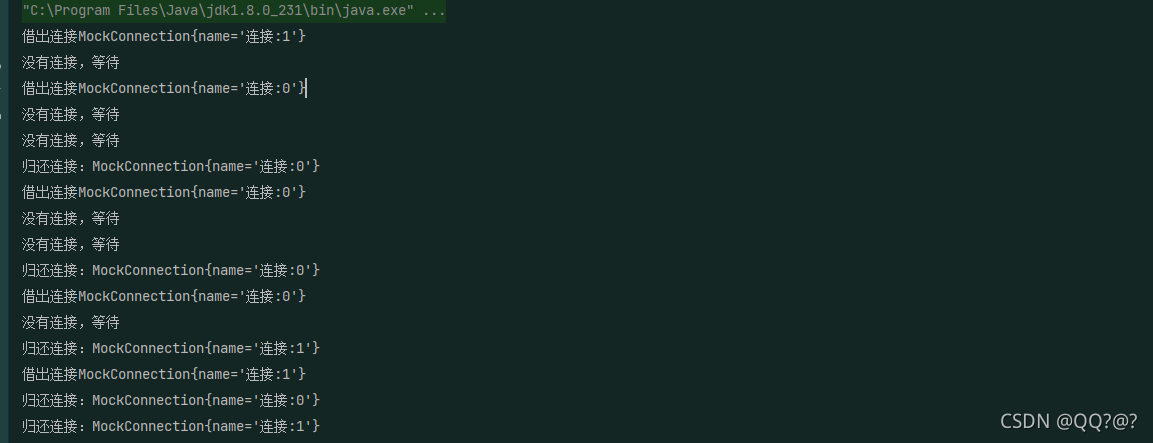
测试使用自定义连接池
public static void main(String[] args) {
DIYThreadPool pool = new DIYThreadPool(2);
for (int i = 0; i < 5; i++) {
new Thread(() -> {
Connection conn = pool.borrow();
try {
Thread.sleep(new Random().nextInt(1000));
} catch (InterruptedException e) {
e.printStackTrace();
}
pool.free(conn);
}).start();
}
}
结果:
3. final 原理
1. 设置 final 变量的原理
public class TestFinal {
final int a = 20;
}
字节码
0: aload_0
1: invokespecial #1 // Method java/lang/Object."<init>":()V
4: aload_0
5: bipush 20
7: putfield #2 // Field a:I
<-- 写屏障 -->
10: return
发现 final 变量的赋值也会通过 putfield 指令来完成,同样在这条指令之后也会加入写屏障,保证在其它线程读到它的值时不会出现为 0 的情况
2. 获取 final 变量的原理
使用final修饰的成员或类变量(共享变量),在获取时,根据字节码指令可知,就等同于一个常量,整个JVM实例生命周期中不会发送变化,可以直接引用使用。而不用再去堆中创建实例。















 98
98











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









