






Redis五种基本数据类型底层实现
1、Redis是什么
Redis 是一个开源(BSD许可)的,内存中的数据结构存储系统,它可以用作数据库、缓存和消息中间件。 它支持多种类型的数据结构,如 **字符串(strings), 散列(hashes), 列表(lists), 集合(sets), 有序集合(sorted sets) **与范围查询, bitmaps, hyperloglogs 和 地理空间(geospatial) 索引半径查询。 Redis 内置了 复制(replication),LUA脚本(Lua scripting), LRU驱动事件(LRU eviction),事务(transactions) 和不同级别的 磁盘持久化(persistence), 并通过 Redis哨兵(Sentinel)和自动分区(Cluster)提供高可用性(high availability)。
2、RedisObject
Redis是一个k-v数据库,默认有16个数据库,每一个db 会有两个dict, 一个dict存储数据内容,一个dict 来记录失效时间。存储数据的dict,key是String,value就是RedisObject。RedisObject 有五种对象:字符串对象、列表对象、哈希对象、集合对象和有序集合对象。redisDb和ReidsObject的结构如下:
typedef struct dictEntry {
void *key;
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next;
} dictEntry;
typedef struct dictType {
uint64_t (*hashFunction)(const void *key);
void *(*keyDup)(void *privdata, const void *key);
void *(*valDup)(void *privdata, const void *obj);
int (*keyCompare)(void *privdata, const void *key1, const void *key2);
void (*keyDestructor)(void *privdata, void *key);
void (*valDestructor)(void *privdata, void *obj);
} dictType;
/* This is our hash table structure. Every dictionary has two of this as we
* implement incremental rehashing, for the old to the new table. */
typedef struct dictht {
dictEntry **table;
unsigned long size;
unsigned long sizemask;
unsigned long used;
} dictht;
typedef struct dict {
dictType *type;
void *privdata;
dictht ht[2];
long rehashidx; /* rehashing not in progress if rehashidx == -1 */
unsigned long iterators; /* number of iterators currently running */
} dict;
typedef struct redisDb {
dict *dict; /* The keyspace for this DB */
dict *expires; /* Timeout of keys with a timeout set */
dict *blocking_keys; /* Keys with clients waiting for data (BLPOP)*/
dict *ready_keys; /* Blocked keys that received a PUSH */
dict *watched_keys; /* WATCHED keys for MULTI/EXEC CAS */
int id; /* Database ID */
long long avg_ttl; /* Average TTL, just for stats */
unsigned long expires_cursor; /* Cursor of the active expire cycle. */
list *defrag_later; /* List of key names to attempt to defrag one by one, gradually. */
} redisDb;
typedef struct redisObject {
unsigned type:4;/* 类型 */
unsigned encoding:4;/* 编码 */
unsigned lru:LRU_BITS; /* LRU time (relative to global lru_clock) or
* LFU data (least significant 8 bits frequency
* and most significant 16 bits access time). 用于记录缓存对象最后被访问的时间*/
int refcount;/* 引用计数 */
void *ptr;/* 指向底层数据结构的指针 */
} robj;RedisDB结构如下图所示:

RedisObject各字端作用:
-
type: 对象类型 ,即五种基本类型:字符串(strings), 散列(hashes), 列表(lists), 集合(sets), 有序集合(sorted sets
/* Object types */ #define REDIS_STRING 0 #define REDIS_LIST 1 #define REDIS_SET 2 #define REDIS_ZSET 3 #define REDIS_HASH 4 -
encoding:编码方式,同一个类型的 type 会有不同的编码方式,
/* Objects encoding. Some kind of objects like Strings and Hashes can be * internally represented in multiple ways. The 'encoding' field of the object * is set to one of this fields for this object. */ #define OBJ_ENCODING_RAW 0 /* Raw representation */ #define OBJ_ENCODING_INT 1 /* Encoded as integer */ #define OBJ_ENCODING_HT 2 /* Encoded as hash table */ #define OBJ_ENCODING_ZIPMAP 3 /* Encoded as zipmap */ #define OBJ_ENCODING_LINKEDLIST 4 /* No longer used: old list encoding. */ #define OBJ_ENCODING_ZIPLIST 5 /* Encoded as ziplist */ #define OBJ_ENCODING_INTSET 6 /* Encoded as intset */ #define OBJ_ENCODING_SKIPLIST 7 /* Encoded as skiplist */ #define OBJ_ENCODING_EMBSTR 8 /* Embedded sds string encoding */ #define OBJ_ENCODING_QUICKLIST 9 /* Encoded as linked list of ziplists */ #define OBJ_ENCODING_STREAM 10 /* Encoded as a radix tree of listpacks */ #define LRU_BITS 24 #define LRU_CLOCK_MAX ((1<<LRU_BITS)-1) /* Max value of obj->lru */ #define LRU_CLOCK_RESOLUTION 1000 /* LRU clock resolution in ms */ #define OBJ_SHARED_REFCOUNT INT_MAX /* Global object never destroyed. */ #define OBJ_STATIC_REFCOUNT (INT_MAX-1) /* Object allocated in the stack. */ #define OBJ_FIRST_SPECIAL_REFCOUNT OBJ_STATIC_REFCOUNT -
lru:LRU_BITS: LRU 信息,用于记录缓存对象最后被访问的时间
-
refcount:引用计数,每个对象都有个引用计数 refcount,当引用计数为零时,对象就会被销毁,内存被回收。
-
ptr 指针:将指向对象内容 的具体存储位置。
-
type和encoding的对应关系如下图:

3、基本的数据结构
String
- String的底层是动态字符串SDS(Simple Dynamic String)

sds结构一共有五种Header定义,其目的是为了满足不同长度的字符串可以使用不同大小的Header,从而节省内存。 Header部分主要包含以下几个部分:
typedef char *sds;
/* Note: sdshdr5 is never used, we just access the flags byte directly.
* However is here to document the layout of type 5 SDS strings. */
struct __attribute__ ((__packed__)) sdshdr5 {
unsigned char flags; /* 3 lsb of type, and 5 msb of string length */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len; /* used */
uint8_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr16 {
uint16_t len; /* used */
uint16_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr32 {
uint32_t len; /* used */
uint32_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr64 {
uint64_t len; /* used */
uint64_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};-
len:表示字符串真正的长度,不包含空终止字符 字符串的长度(实际使用的长度)
-
alloc:表示字符串的最大容量,不包含Header和最后的空终止字符
-
flags:标志位,低三位表示类型,其余五位未使用
-
buf:字符数组
-
encoding可能是int、raw、embstr
查看内部编码格式:
127.0.0.1:6379> set name 1234567890123456789 #小于(2^63)-1 9223372036854775807 则是int OK 127.0.0.1:6379> debug object name Value at:0x7fccbec160b0 refcount:1 encoding:int serializedlength:20 lru:6679383 lru_seconds_idle:2 127.0.0.1:6379> set name 12345678901234567890 #大于(2^63)-1 是embstr OK 127.0.0.1:6379> debug object name Value at:0x7fccbec16060 refcount:1 encoding:embstr serializedlength:21 lru:6679391 lru_seconds_idle:3 127.0.0.1:6379> set name 123456789012345678w #19位是embstr OK 127.0.0.1:6379> debug object name Value at:0x7fccbec160b0 refcount:1 encoding:embstr serializedlength:20 lru:6680701 lru_seconds_idle:3 127.0.0.1:6379> set name 12345678901234567890123456789012345678901234 OK 127.0.0.1:6379> debug object name #44位是embstr Value at:0x7fccc0010f40 refcount:1 encoding:embstr serializedlength:21 lru:6669496 lru_seconds_idle:1 127.0.0.1:6379> set name 123456789012345678901234567890123456789012345 OK 127.0.0.1:6379> debug object name #45位是raw Value at:0x7fccc000f020 refcount:1 encoding:raw serializedlength:21 lru:6669503 lru_seconds_idle:3- int: 可以用long类型的整数表示 Redis会将键值转化为 long型来进行存储,此时即对应
OBJ_ENCODING_INT编码类型。
- raw:长度大于44字节的字符串,使用SDS(简单动态字符串)保存

- embstr:长度小于等于44字节的字符串,效率比较高,且数据都保存在一块内存区域

- int: 可以用long类型的整数表示 Redis会将键值转化为 long型来进行存储,此时即对应
-
常用命令
################################### String #######################################
AmydeMacBook-Pro:bin zhengamy$ redis-cli -h 127.0.0.1 -p 6379 #连接redis
127.0.0.1:6379> select 0 #切换数据库,默认有16个数据库
127.0.0.1:6379> keys * #查看数据库所有的key
127.0.0.1:6379> expire name 10 #设置过期时间单位是秒
127.0.0.1:6379> ttl name #查看剩余时间
127.0.0.1:6379> ttl name #查看剩余时间
127.0.0.1:6379> type name #查看类型
127.0.0.1:6379> exists name #是否存在key
127.0.0.1:6379> append name "hello" #追加字符串,如果当前key不存在,就相当于setkey
127.0.0.1:6379> strlen name #获取字符串的长度!
127.0.0.1:6379> incr count #自增1
127.0.0.1:6379> decr count #自减1
127.0.0.1:6379> incrby count 10 #可以设置步长,指定增量
127.0.0.1:6379> decrby count 5 #可以设置步长,指定减量
127.0.0.1:6379> getrange name 0 2 #截取字符串 [0,2]
127.0.0.1:6379> getrange name 0 -1 #获取全部字符串,相当于getkey
127.0.0.1:6379> set age 13 ex 10
127.0.0.1:6379> setex age 10 13 #设置过期时间,将age的值设置为13,10秒过期
127.0.0.1:6379> setnx name amy #不存在才会设置值,存在不会设置
127.0.0.1:6379> mset name saber age 22 sex 女 #同时设置多个值
127.0.0.1:6379> mget name age sex #同时获取多个值
127.0.0.1:6379> msetnx score 99 age 22 #msetnx 是一个原子性的操作,要么一起成功,要么一起失败
127.0.0.1:6379> getset name amy #先获取结果然后在修改值
127.0.0.1:6379> object encoding name #查看底层数据结构
"embstr"
127.0.0.1:6379> object encoding age #查看底层数据结构
"int"List
- List的底层是链表
typedef struct listNode {
struct listNode *prev;
struct listNode *next;
void *value;
} listNode;
typedef struct list {
listNode *head;
listNode *tail;
void *(*dup)(void *ptr);
void (*free)(void *ptr);
int (*match)(void *ptr, void *key);
unsigned long len;
} list;-
encoding早期使用ziplist或linkedlist,Redis 3.2版本后list使用quicklist
- ziplist:压缩列表,适用于长度较小的值,其是由连续空间组成(会保存每个值的长度信息,因此可依次找到各个值)

- 存取效率高,内存占用小,但是由于是连续内存,修改操作需要重新分配内存
- linkedlist:双向链表,修改效率高,但是由于需要保存前后指针,占内存比较多

- quicklist:3.2之后引入的,可以理解成是一种混合结构,quicklist 是 ziplist 和 linkedlist 的混合体,它将 linkedlist 按段切分,每一段使用 ziplist 来紧凑存储,多个 ziplist 之间使用双向指针串接起来。这样既满足了快速的插入删除性能,又不会出现太大的空间冗余**。
typedef struct quicklistNode { struct quicklistNode *prev; struct quicklistNode *next; unsigned char *zl; unsigned int sz; /* ziplist size in bytes */ unsigned int count : 16; /* count of items in ziplist */ unsigned int encoding : 2; /* RAW==1 or LZF==2 */ unsigned int container : 2; /* NONE==1 or ZIPLIST==2 */ unsigned int recompress : 1; /* was this node previous compressed? */ unsigned int attempted_compress : 1; /* node can't compress; too small */ unsigned int extra : 10; /* more bits to steal for future usage */ } quicklistNode; typedef struct quicklist { quicklistNode *head; quicklistNode *tail; unsigned long count; /* total count of all entries in all ziplists */ unsigned long len; /* number of quicklistNodes */ int fill : QL_FILL_BITS; /* fill factor for individual nodes */ unsigned int compress : QL_COMP_BITS; /* depth of end nodes not to compress;0=off */ unsigned int bookmark_count: QL_BM_BITS; quicklistBookmark bookmarks[]; } quicklist; - ziplist:压缩列表,适用于长度较小的值,其是由连续空间组成(会保存每个值的长度信息,因此可依次找到各个值)
-
常用命令
################################### list #######################################
127.0.0.1:6379> lpush list 3 #将一个值或者多个值,插入到列表头部(左)
127.0.0.1:6379> lrange list 0 -1 #获取list中值
127.0.0.1:6379> lpop list #从列表头部(左)获取值
127.0.0.1:6379> rpop list #从列表尾部(右)获取值
127.0.0.1:6379> lrange list 0 1 #指定区间获取list中值
127.0.0.1:6379> rpush list -1 #将一个值或者多个值,插入到列表尾部(右)
127.0.0.1:6379> lindex list 0 #获取指定下表的值
127.0.0.1:6379> lrem list 1 2 #移除1个list中的值为2的元素
127.0.0.1:6379> llen list #返回列表成都
127.0.0.1:6379> ltrim list 1 2 #按照下标截取list
127.0.0.1:6379> rpoplpush list otherlist #移除列表的最后一个元素,将他移动到新的列表中
127.0.0.1:6379> lset list 1 -1 #将列表中指定下标的值替换为另外一个值,更新操作,不存在会报错(将下标为1的元素设置为-1)
127.0.0.1:6379> linsert list before -1 0 # 将某个具体的value插入到列把你中某个元素的前面或者后面!(将下标为0插入到1的前面)
127.0.0.1:6379> object encoding list #查看底层数据结构
"quicklist"Hash
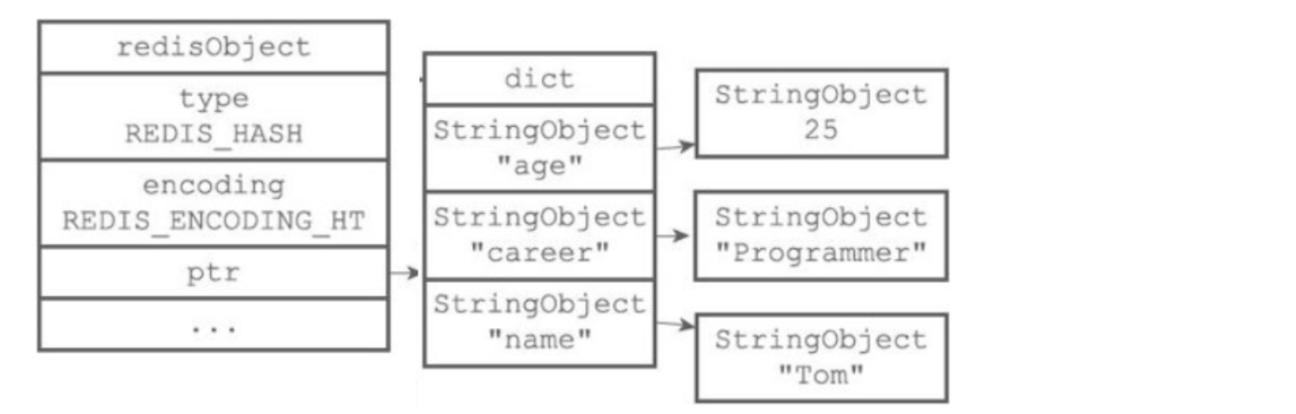
-
Hash的底层是dict
typedef struct dictEntry { void *key; union { void *val; uint64_t u64; int64_t s64; double d; } v; struct dictEntry *next; } dictEntry; /* This is our hash table structure. Every dictionary has two of this as we * implement incremental rehashing, for the old to the new table. */ typedef struct dictht { dictEntry **table; unsigned long size; unsigned long sizemask; unsigned long used; } dictht; typedef struct dict { dictType *type; void *privdata; dictht ht[2]; long rehashidx; /* rehashing not in progress if rehashidx == -1 */ unsigned long iterators; /* number of iterators currently running */ } dict;

-
encoding使用ziplist或者hashtable
- ziplist: 当键和值的长度和数量都比较少时(64B和512个),默认使用ziplist,hash过程是通过直接遍历得到的,由于数据量小,且都在内存中,效率仍然很高

- hashtable: 否则,则采用hash表提高效率
- 常用命令
################################### hash #######################################
127.0.0.1:6379> hset map field1 val1 #设置一个具体 [key, key-vlaue]
127.0.0.1:6379> hget map field1 #获取一个字段值
127.0.0.1:6379> hgetall map #获取全部的数据
127.0.0.1:6379> hexists map field4 #判断hash中指定字段是否存在
127.0.0.1:6379> hsetnx map field1 val1 #不存在才会设置值,存在不会设置
127.0.0.1:6379> hmset map field2 val2 field3 val3 #设置多个
127.0.0.1:6379> hkeys map #只获得所有field
127.0.0.1:6379> hvals map #只获得所有val
127.0.0.1:6379> hlen map #获取hash表的字段数量
127.0.0.1:6379> hdel map field3 #删除hash指定key字段,对应的value值也就消失了
127.0.0.1:6379> hincrby map field3 4 #可以设置步长,指定增量
127.0.0.1:6379> hset map 1234567890123456789012345678901234567890123456789012345678901234 1234567890123456789012345678901234567890123456789012345678901234
(integer) 1
127.0.0.1:6379> object encoding map #64位 ziplist
"ziplist"
127.0.0.1:6379> hset map 12345678901234567890123456789012345678901234567890123456789012345 12345678901234567890123456789012345678901234567890123456789012345
(integer) 1
127.0.0.1:6379> object encoding map #65位 hashtable
"hashtable"Set
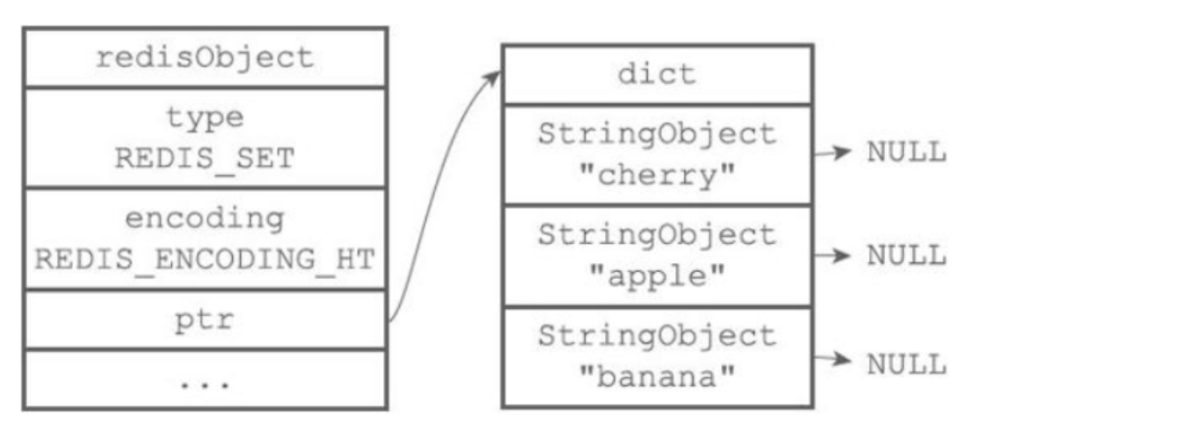
-
encoding使用intset或者hashtable
- intset: 集合中的数都是整数时,且数据量不超过512个,使用intset(有序不重复连续空间)
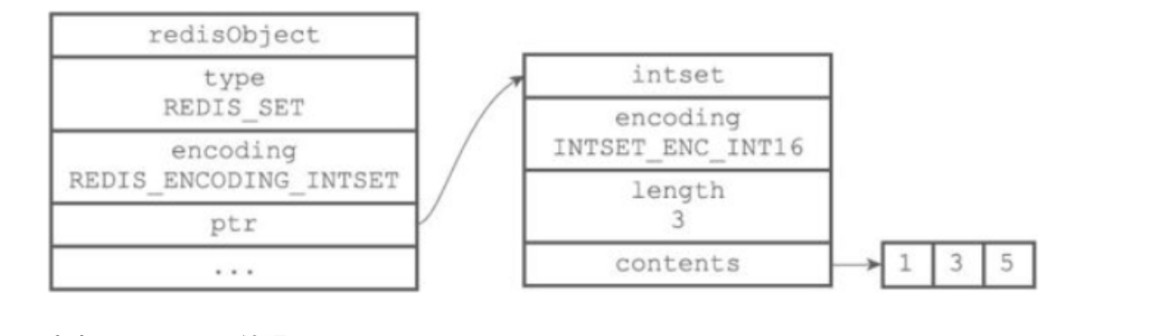
- 节约内存,但是由于是连续空间,修改效率不高
- 整数集合(intset)是集合键的底层实现之一: 当一个集合只包含整数值元素, 并且这个集合的元素数量不多时, Redis 就会使用整数集合作为集合键的底层实现。
- insert结构
```c++
typedef struct intset {
uint32_t encoding;
uint32_t length;
int8_t contents[];
} intset;++
```- hashtable:其中value使用NULL填充
- 常用命令
################################### set #######################################
127.0.0.1:6379> sadd set hi #添加元素
127.0.0.1:6379> scard #获取set集合中的内容元素个数
127.0.0.1:6379> sismember hello #判断是否存在值
127.0.0.1:6379> smembers set #查看所有元素
127.0.0.1:6379> srandmember set #随机获取一个元素
127.0.0.1:6379> srandmember set 2 #随机获取指定个素元素
127.0.0.1:6379> spop myset #随机删除set集合中的元素
127.0.0.1:6379> srem set hellow #移除指定元素
127.0.0.1:6379> smove set myset hello #将一个指定的值,移动到另外一个set集合
127.0.0.1:6379> sunion set myset #获取两个集合的并集
127.0.0.1:6379> sdiff set myset #获取两个集合的差集,移除set中和myset一样的元素
127.0.0.1:6379> sinter set myset #获取两个集合的交集
127.0.0.1:6379[1]> object encoding set #所有元素是数值 intset
"intset"
127.0.0.1:6379[1]> sadd set a
(integer) 1
127.0.0.1:6379[1]> object encoding set #包含非数字 hashtable
"hashtable"ZSet
-
encoding使用ziplist或者skiplist
-
ziplist:连续存放值以及score(排序的标准,double),当元素个数及长度都比较小时使用
-
skiplist:跳表(具有层次结构的链表),因此可支持范围查询
-
跳表结构
typedef struct zskiplistNode { sds ele;//成员对象 double score;//分值 struct zskiplistNode *backward;//后退指针 struct zskiplistLevel { struct zskiplistNode *forward;//前进指针 unsigned long span;//跨度 用来计算排位(rank)的 } level[]; } zskiplistNode; typedef struct zskiplist { struct zskiplistNode *header, *tail;//表头节点,表尾节点 unsigned long length;//跳跃表的长度 int level;//层数最大的那个节点的层数 } zskiplist; typedef struct zset { dict *dict; zskiplist *zsl; } zset; -
查找和插入的时间复杂度都是logn
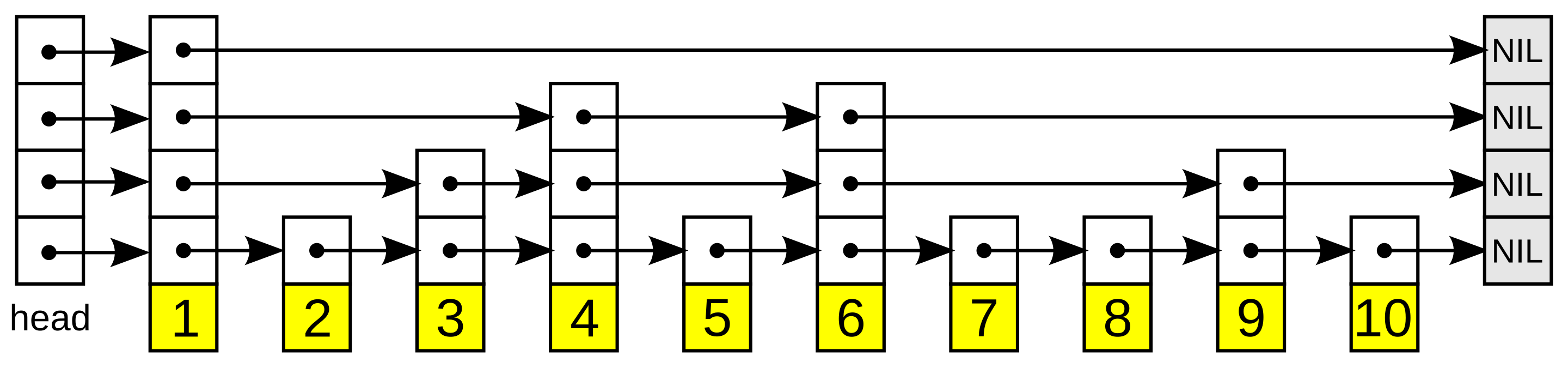
按照层次组织,上面层的step大,因此查找快,从上往下依次确定范围。
-
查找时,从最上面一层开始查找,直到找到大于或null,然后指向前一个节点的下一层
-
新增时,为了保证每层的数量能够满足要求(第i层的某个数出现的概率是P,则上一层该数的概率是1/(1 - p),一般取p=0.5),因此需要随机产生该数的层数,并保证概率。实现上需要找到所有前驱
-
redis实现上,每一层数的随机的实现:
randomLevel() level := 1 // random()返回一个[0...1)的随机数 p = 1/4 maxlevel=32 while random() < p and level < MaxLevel do level := level + 1 return level
-
-
删除时,需要考虑前驱的next节点改变,同时考虑最大level是否变化
-
-
同时使用一个dict保存每个值对应的score
-
为什么使用跳表:
- 其占用的内存开销可控(通过控制概率P)
- 支持范围查询,比如zrange
- 跳跃表优点是有序,但是查询分值复杂度为O(logn);字典查询分值复杂度为O(1) ,但是无序,所以结合连个结构的有点进行实现
- 虽然采用两个结构但是集合的元素成员和分值是共享的,两种结构通过指针指向同一地址,不会浪费内存。
-
-
-
常用命令
################################### sorted set #######################################
127.0.0.1:6379> zadd salary 2800 amy #添加一个值
127.0.0.1:6379> zrem salart saber #删除一个值
127.0.0.1:6379> zrangebyscore salary -inf +inf withscores #按照score升序排序,并附带score
127.0.0.1:6379> zrevrangebyscore salary +inf -inf withscores #按照score降序排序,并附带score
127.0.0.1:6379> zcard salary #获取有序集合的个数
127.0.0.1:6379> zcount salary 1000 3000 #获取指定区间的元素
127.0.0.1:6379> zadd zset 1234567890123456789012345678901234567890123456789012345678901234 1234567890123456789012345678901234567890123456789012345678901234
(integer) 1
127.0.0.1:6379> object encoding zset #64位 ziplist
"ziplist"
127.0.0.1:6379> zadd zset 12345678901234567890123456789012345678901234567890123456789012345 12345678901234567890123456789012345678901234567890123456789012345
(integer) 1
127.0.0.1:6379> object encoding zset #65位 skiplist
"skiplist"














 3181
3181

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}