







# coding: utf-8
# In[1]:
##导入依赖的包,数据采用红酒数据集
from sklearn import tree
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
##数据探索
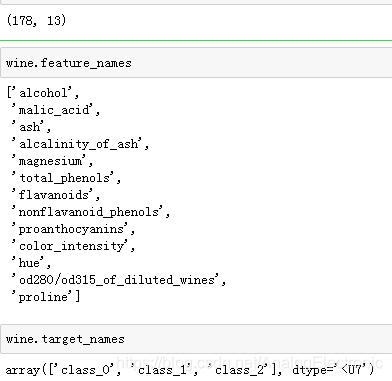
wine = load_wine()
wine.data.shape
#将数据转换为df格式:
import pandas as pd
pd.concat([pd.DataFrame(wine.data),pd.DataFrame(wine.target)],axis=1)
##生成训练集和测试集
Xtrain, Xtest, Ytrain, Ytest = train_test_split(wine.data,wine.target,test_size=0.2)
##构建决策树模型 gini
clf = tree.DecisionTreeClassifier()
clf = clf.fit(Xtrain, Ytrain)
score = clf.score(Xtest, Ytest) #返回预测的准确度
score
0.9444444444444444
##构建决策树模型 gini
clf = tree.DecisionTreeClassifier(criterion="entropy")
clf = clf.fit(Xtrain, Ytrain)
score = clf.score(Xtest, Ytest) #返回预测的准确度
score
0.9722222222222222
##打印决策树
feature_name = ['酒精','苹果酸','灰','灰的碱性','镁','总酚','类黄酮','非黄烷类酚类','花青素','颜色强度','色调','od280/od315稀释葡萄酒','脯氨酸']
import os
os.environ["PATH"] += os.pathsep + 'C:/Program Files (x86)/Graphviz2.38/bin/'
import graphviz
dot_data = tree.export_graphviz(clf
,out_file = None
,feature_names= feature_name
,class_names=["琴酒","雪莉","贝尔摩德"]
,filled=True
,rounded=True
)
graph = graphviz.Source(dot_data)
graph

##显示决策树各个特征重要性
clf.feature_importances_
[*zip(feature_name,clf.feature_importances_)]

##打印预测的准确度
clf = tree.DecisionTreeClassifier(criterion="entropy",random_state=30)
clf = clf.fit(Xtrain, Ytrain)
score = clf.score(Xtest, Ytest) #返回预测的准确度
score
1.0
###random_state和split参数优化
clf = tree.DecisionTreeClassifier(criterion="entropy",random_state=30,splitter="random")
clf = clf.fit(Xtrain, Ytrain)
score = clf.score(Xtest, Ytest)
score
1.0
###max_depth、min_samples_leaf & min_samples_split参数优化
clf = tree.DecisionTreeClassifier(criterion="entropy",
random_state=30,
splitter="random",
max_depth = 5,
min_samples_leaf = 1,
min_samples_split =2)
clf = clf.fit(Xtrain, Ytrain)
score = clf.score(Xtest, Ytest)
score
1.0
##学习曲线
import matplotlib.pyplot as plt
test = []
for i in range(10):
clf = tree.DecisionTreeClassifier(max_depth=i+1
,criterion="entropy"
,random_state=30
,splitter="random"
)
clf = clf.fit(Xtrain, Ytrain)
score = clf.score(Xtest, Ytest)
test.append(score)
plt.plot(range(1,11),test,color="red",label="max_depth")
plt.legend()
plt.show()

##交叉验证
from sklearn.datasets import load_boston
from sklearn.model_selection import cross_val_score
from sklearn.tree import DecisionTreeRegressor
score_1 = []
score_2 = []
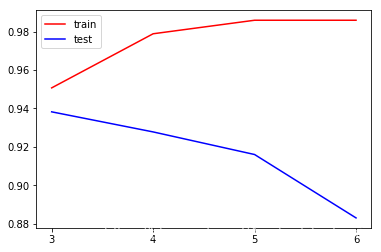
for depth in range(3,7):
clf = tree.DecisionTreeClassifier(criterion="entropy",
random_state=30,
splitter="random",
max_depth = depth,
min_samples_leaf = 1,
min_samples_split =2)
clf = clf.fit(Xtrain, Ytrain)
score1 = clf.score(Xtrain, Ytrain)
score2 = cross_val_score(clf, wine.data,wine.target, cv=10,scoring = "accuracy")
score_1.append(score1)
score_2.append(score2.mean())
print(max(score_2))
plt.plot(range(3,7),score_1,color="red",label="train")
plt.plot(range(3,7),score_2,color="blue",label="test")
plt.xticks(range(3,7))
plt.legend()
plt.show()
0.9382352941176471
##网格搜索
from sklearn.model_selection import GridSearchCV
parameters = {'splitter':('best','random')
,'criterion':("gini","entropy")
,"max_depth":[*range(1,10)]
,'min_samples_leaf':[*range(1,50,5)]
,'min_samples_split':[*range(1,50,5)]}
clf = tree.DecisionTreeClassifier(random_state=30)
#n_jobs=-1指定全部cpu的核跑,cv指定交叉验证
GS = GridSearchCV(clf, parameters, cv=10,n_jobs=-1)
grid_result = GS.fit(Xtrain, Ytrain) #运行网格搜索
grid_result.best_params_

##回归树练习,泰坦尼克号幸存者的预测
import pandas as pd
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.model_selection import GridSearchCV
from sklearn.model_selection import cross_val_score
import matplotlib.pyplot as plt
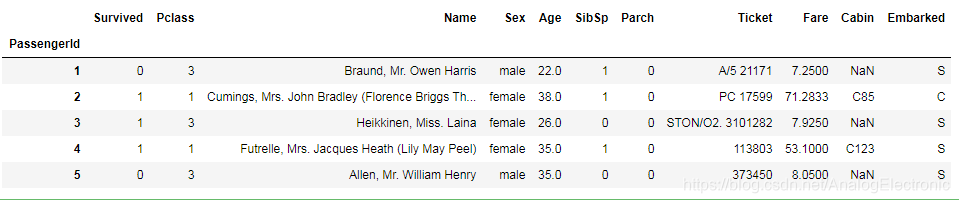
data = pd.read_csv(r"I:\hadoop note\titanic_train.csv",index_col= 0)
data.head()
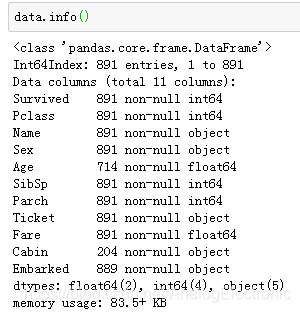
#删除缺失值过多的列,和观察判断来说和预测的y没有关系的列
data.drop(["Cabin","Name","Ticket"],inplace=True,axis=1)
#处理缺失值,对缺失值较多的列进行填补,有一些特征只确实一两个值,可以采取直接删除记录的方法
data["Age"] = data["Age"].fillna(data["Age"].mean())
data = data.dropna()
#将分类变量转换为数值型变量
#将二分类变量转换为数值型变量
#astype能够将一个pandas对象转换为某种类型,和apply(int(x))不同,astype可以将文本类转换为数字,用这个方式可以很便捷地将二分类特征转换为0~1
data["Sex"] = (data["Sex"]== "male").astype("int")
#将三分类变量转换为数值型变量
labels = data["Embarked"].unique().tolist()
data["Embarked"] = data["Embarked"].apply(lambda x: labels.index(x))
#查看处理后的数据集
data.head()
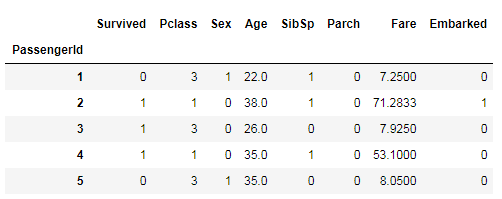
##提取X和Y,拆分训练集和测试集
X = data.iloc[:,data.columns != "Survived"]
y = data.iloc[:,data.columns == "Survived"]
from sklearn.model_selection import train_test_split
Xtrain, Xtest, Ytrain, Ytest = train_test_split(X,y,test_size=0.3)
#修正测试集和训练集的索引
for i in [Xtrain, Xtest, Ytrain, Ytest]:
i.index = range(i.shape[0])
#查看分好的训练集和测试集
Xtrain.head()
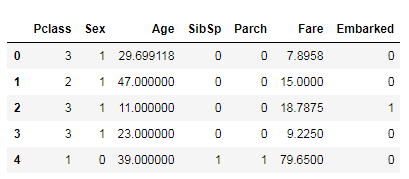
clf = DecisionTreeClassifier(random_state=25)
clf = clf.fit(Xtrain, Ytrain)
score_ = clf.score(Xtest, Ytest)
score_
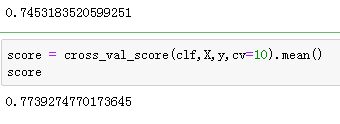
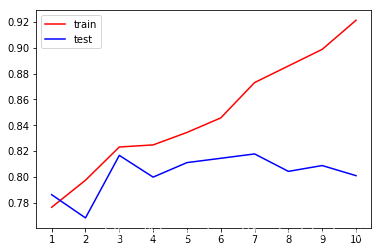
##循环获取适合的max_depth
tr = []
te = []
for i in range(10):
clf = DecisionTreeClassifier(random_state=25,max_depth=i+1 ,criterion="entropy" )
clf = clf.fit(Xtrain, Ytrain)
score_tr = clf.score(Xtrain,Ytrain)
score_te = cross_val_score(clf,X,y,cv=10).mean()
tr.append(score_tr)
te.append(score_te)
print(max(te))
plt.plot(range(1,11),tr,color="red",label="train")
plt.plot(range(1,11),te,color="blue",label="test")
plt.xticks(range(1,11))
plt.legend()
plt.show()
0.8177860061287026
##交叉验证和网格搜索
import numpy as np
gini_thresholds = np.linspace(0,0.5,20)
parameters = {'splitter':('best','random'),
'criterion':("gini","entropy"),
"max_depth":[*range(1,10)],
'min_samples_leaf':[*range(1,50,5)],
'min_impurity_decrease':[*np.linspace(0,0.5,20)]}
clf = DecisionTreeClassifier(random_state=25)
GS = GridSearchCV(clf, parameters, cv=10)
GS.fit(Xtrain,Ytrain)
GS.best_params_

GS.best_score_
0.819969278033794














 6915
6915











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









