import re
import jieba
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# from keras.preprocessing.text import Tokenizer# from keras.preprocessing.sequence import pad_sequences# from keras.models import Sequential# from keras.layers import *# from keras.utils.np_utils import to_categorical# from keras.callbacks import EarlyStoppingfrom tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import*from tensorflow.python.keras.utils.np_utils import to_categorical
from tensorflow.keras.callbacks import EarlyStopping
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score,classification_report
import warnings
warnings.filterwarnings('ignore')
2023-08-16 09:28:02.684741: I tensorflow/core/util/port.cc:110] oneDNN custom operations are on. You may see slightly different numerical results due to floating-point round-off errors from different computation orders. To turn them off, set the environment variable `TF_ENABLE_ONEDNN_OPTS=0`.
2023-08-16 09:28:02.686545: I tensorflow/tsl/cuda/cudart_stub.cc:28] Could not find cuda drivers on your machine, GPU will not be used.
2023-08-16 09:28:02.724128: I tensorflow/tsl/cuda/cudart_stub.cc:28] Could not find cuda drivers on your machine, GPU will not be used.
2023-08-16 09:28:02.725814: I tensorflow/core/platform/cpu_feature_guard.cc:182] This TensorFlow binary is optimized to use available CPU instructions in performance-critical operations.
To enable the following instructions: AVX2 AVX512F AVX512_VNNI FMA, in other operations, rebuild TensorFlow with the appropriate compiler flags.
2023-08-16 09:28:03.400648: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Could not find TensorRT
2.数据读取
#读取数据
data = pd.read_csv('./data/dataset.csv')#数据预览
data.head()
#定义删除除字母,数字,汉字以外的所有符号的函数defremove_pun(line):
rule = re.compile(u"[^a-zA-Z0-9\u4E00-\u9FA5]")
line = rule.sub('',line)return line
#读取停用词表
stopwords =[line.strip()for line inopen('./data/中文停用词库.txt','r', encoding='utf-8').readlines()]
#字符清理
data['clean_text']= data['text'].map(lambda x:remove_pun(x))#结合停用词表进行分词
data['cut_text']= data['clean_text'].apply(lambda x:" ".join(w for w in jieba.lcut(x)if w notin stopwords))
Building prefix dict from the default dictionary ...
Dumping model to file cache /tmp/jieba.cache
Loading model cost 0.536 seconds.
Prefix dict has been built successfully.
data.head()
text
label
clean_text
cut_text
0
酒店设计有特色,房间很舒服亦很美,位置于南门很方便出入,而且又有得免费上网。前台服务员不错,...
0
酒店设计有特色房间很舒服亦很美位置于南门很方便出入而且又有得免费上网前台服务员不错唯退房时出...
酒店设计 特色 房间 舒服 美 位置 南门 出入 免费 上网 前台 服务员 不错 唯 退房 ...
1
地理位置不错,闹中取静。房间比较干净,布局合理。但是隔音效果太差了,有住简易客栈的感觉。临水...
0
地理位置不错闹中取静房间比较干净布局合理但是隔音效果太差了有住简易客栈的感觉临水的房间风景不...
地理位置 不错 闹中取静 房间 干净 布局合理 隔音 效果 太差 住 简易 客栈 感觉 临水...
2
不错,下次还考虑入住。交通也方便,在餐厅吃的也不错。
0
不错下次还考虑入住交通也方便在餐厅吃的也不错
不错 下次 入住 交通 餐厅 吃 不错
3
地理位置比较便捷,逛街、旅游、办事都比较方便。老的宾馆新装修改的,房间内的设施简洁、干净,但...
0
地理位置比较便捷逛街旅游办事都比较方便老的宾馆新装修改的房间内的设施简洁干净但宾馆整体建筑设...
地理位置 便捷 逛街 旅游 办事 宾馆 新装 修改 房间内 设施 简洁 干净 宾馆 整体 建...
4
因为只住了一晚,所以没什么感觉,差不多四星吧。大堂的地砖很漂亮。房间小了一点。
0
因为只住了一晚所以没什么感觉差不多四星吧大堂的地砖很漂亮房间小了一点
只住 一晚 没什么 感觉 四星 大堂 地砖 很漂亮 房间 一点
4.建模数据预处理
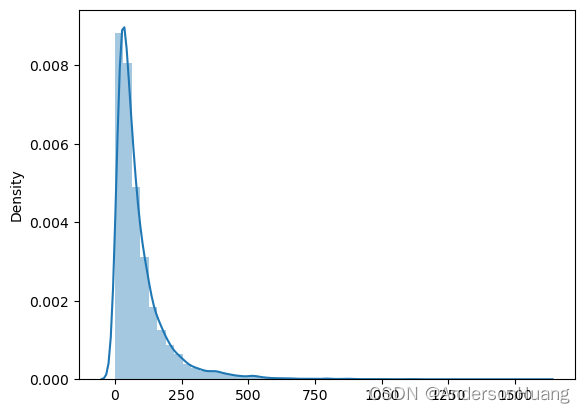
#查看cut_text的长度分布import seaborn as sns
len_list = data['cut_text'].map(lambda x:len(x)).tolist()
sns.distplot(len_list)
plt.show()


























 3021
3021











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









