







KMP算法
1. 暴力匹配算法
在讲KMP算法之前,我们先看看常规字符串匹配算法。
假设现在我们面临这样一个问题:有一个文本串S,和一个模式串P,现在要查找P在S中的位置,怎么查找呢?
如果用暴力匹配的思路,并假设现在文本串S匹配到 i 位置,模式串P匹配到 j 位置,则有:
- 如果当前字符匹配成功(即S[i] == P[j]),则i++,j++,继续匹配下一个字符;
- 如果失配(即S[i]! = P[j]),令i = i - (j - 1),j = 0。相当于每次匹配失败时,i 回溯,j 被置为0。
-
12345678910111213141516171819202122232425262728
intViolentMatch(char* s,char* p){intsLen =strlen(s);intpLen =strlen(p);inti = 0;intj = 0;while(i < sLen && j < pLen){if(s[i] == p[j]){//①如果当前字符匹配成功(即S[i] == P[j]),则i++,j++i++;j++;}else{//②如果失配(即S[i]! = P[j]),令i = i - (j - 1),j = 0i = i - j + 1;j = 0;}}//匹配成功,返回模式串p在文本串s中的位置,否则返回-1if(j == pLen)returni - j;elsereturn-1;}
2. KMP算法
2.1 KmpSearch函数
Knuth-Morris-Pratt 字符串查找算法,简称为 “KMP算法”,常用于在一个文本串S内查找一个模式串P 的出现位置,这个算法由Donald Knuth、Vaughan Pratt、James H. Morris三人于1977年联合发表,故取这3人的姓氏命名此算法。
- 假设现在文本串S匹配到 i 位置,模式串P匹配到 j 位置
- 如果j = -1,或者当前字符匹配成功(即S[i] == P[j]),都令i++,j++,继续匹配下一个字符;
- 如果j != -1,且当前字符匹配失败(即S[i] != P[j]),则令 i 不变,j = next[j]。此举意味着失配时,模式串P相对于文本串S向右移动了j - next [j] 位。
- 换言之,当匹配失败时,模式串向右移动的位数为:失配字符所在位置 - 失配字符对应的next 值(next 数组的求解会在下文的中详细阐述),即移动的实际位数为:j - next[j],且此值大于等于1。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
int KmpSearch(char* s, char* p)
{
int i = 0;
int j = 0;
int sLen = strlen(s);
int pLen = strlen(p);
while
(i < sLen && j < pLen)
{
//①如果j = -1,或者当前字符匹配成功(即S[i] == P[j]),都令i++,j++
if
(j == -1 || s[i] == p[j])
{
i++;
j++;
}
else
{
//②如果j != -1,且当前字符匹配失败(即S[i] != P[j]),则令 i 不变,j = next[j]
//next[j]即为j所对应的next值
j = next[j];
}
}
if
(j == pLen)
return
i - j;
else
return
-1;
}
|
向右移动4位后,S[10]跟P[2]继续匹配。为什么要向右移动4位呢,因为移动4位后,模式串中又有个“AB”可以继续跟S[8]S[9]对应着,从而不用让i 回溯。相当于在除去字符D的模式串子串中寻找相同的前缀和后缀,然后根据前缀后缀求出next 数组,最后基于next 数组进行匹配(不关心next 数组怎么求来的,只想看匹配过程是咋样的,可直接跳到下文)。

2.2 next数组求取
2.2.1 寻找最长前缀后缀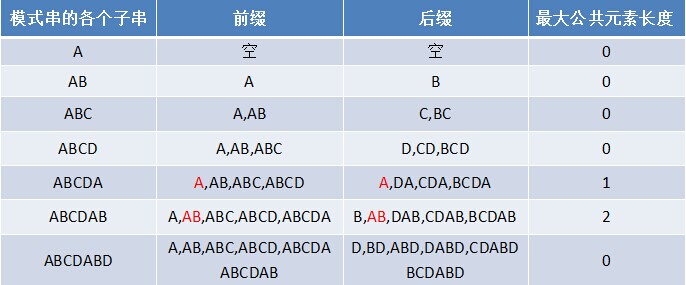

- 如下匹配,当模式串最后一个字符D跟文本串匹配时失配,显而易见,模式串需要向右移动。但向右移动多少位呢?因为此时已经匹配的字符数为6个(ABCDAB),然后根据《最大长度表》可得失配字符D的上一位字符B对应的长度值为2,所以根据之前的结论,可知需要向右移动6 - 2 = 4 位。

失配时,模式串向右移动的位数为:已匹配字符数 - 失配字符的上一位字符所对应的最大长度值
对于给定的模式串:ABCDABD,它的最大长度表及next 数组分别如下:

根据最大长度表求出了next 数组后,从而有
失配时,模式串向右移动的位数为:失配字符所在位置 - 失配字符对应的next 值
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
void
GetNext(
char
* p,
int
next[])
{
int
pLen =
strlen
(p);
next[0] = -1;
int
k = -1;
int
j = 0;
while
(j < pLen - 1)
{
//p[k]表示前缀,p[j]表示后缀
if
(k == -1 || p[j] == p[k])
{
++k;
++j;
next[j] = k;
}
else
{
k = next[k];
}
}
}
|
Next 数组的优化
行文至此,咱们全面了解了暴力匹配的思路、KMP算法的原理、流程、流程之间的内在逻辑联系,以及next 数组的简单求解(《最大长度表》整体右移一位,然后初值赋为-1)和代码求解,最后基于《next 数组》的匹配,看似洋洋洒洒,清晰透彻,但以上忽略了一个小问题。
比如,如果用之前的next 数组方法求模式串“abab”的next 数组,可得其next 数组为-1 0 0 1(0 0 1 2整体右移一位,初值赋为-1),当它跟下图中的文本串去匹配的时候,发现b跟c失配,于是模式串右移j - next[j] = 3 - 1 =2位。

右移2位后,b又跟c失配。事实上,因为在上一步的匹配中,已经得知p[3] = b,与s[3] = c失配,而右移两位之后,让p[ next[3] ] = p[1] = b 再跟s[3]匹配时,必然失配。问题出在哪呢?

问题出在不该出现p[j] = p[ next[j] ]。为什么呢?理由是:当p[j] != s[i] 时,下次匹配必然是p[ next [j]] 跟s[i]匹配,如果p[j] = p[ next[j] ],必然导致后一步匹配失败(因为p[j]已经跟s[i]失配,然后你还用跟p[j]等同的值p[next[j]]去跟s[i]匹配,很显然,必然失配),所以不能允许p[j] = p[ next[j ]]。如果出现了p[j] = p[ next[j] ]咋办呢?如果出现了,则需要再次递归,即令next[j] = next[ next[j] ]。
所以,咱们得修改下求next 数组的代码。|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
//优化过后的next 数组求法
void
GetNextval(
char
* p,
int
next[])
{
int
pLen =
strlen
(p);
next[0] = -1;
int
k = -1;
int
j = 0;
while
(j < pLen - 1)
{
//p[k]表示前缀,p[j]表示后缀
if
(k == -1 || p[j] == p[k])
{
++j;
++k;
//较之前next数组求法,改动在下面4行
if
(p[j] != p[k])
next[j] = k;
//之前只有这一行
else
//因为不能出现p[j] = p[ next[j ]],所以当出现时需要继续递归,k = next[k] = next[next[k]]
next[j] = next[k];
}
else
{
k = next[k];
}
}
}
|
参考文献
- 《算法导论》的第十二章:字符串匹配;
- 本文中模式串“ABCDABD”的部分图来自于此文:http://www.ruanyifeng.com/blog/2013/05/Knuth%E2%80%93Morris%E2%80%93Pratt_algorithm.html;
- 本文3.3.7节中有限状态自动机的图由微博网友@龚陆安 绘制:http://d.pr/i/NEiz;
- 北京7月暑假班邹博半小时KMP视频:http://v.youku.com/v_show/id_XNzQzMjQ1OTYw.html;
- 北京7月暑假班邹博第二次课的PPT:http://yun.baidu.com/s/1mgFmw7u;
- 理解KMP 的9张PPT:http://weibo.com/1580904460/BeCCYrKz3#_rnd1405957424876;
- 详解KMP算法(多图):http://www.cnblogs.com/yjiyjige/p/3263858.html;
- 本文第4部分的BM算法参考自此文:http://www.ruanyifeng.com/blog/2013/05/boyer-moore_string_search_algorithm.html;
- http://youlvconglin.blog.163.com/blog/static/5232042010530101020857;
- 《数据结构 第二版》,严蔚敏 & 吴伟民编著;
- http://blog.csdn.net/v_JULY_v/article/details/6545192;
- http://blog.csdn.net/v_JULY_v/article/details/6111565;
- Sunday算法的原理与实现:http://blog.chinaunix.net/uid-22237530-id-1781825.html;
- 模式匹配之Sunday算法:http://blog.csdn.net/sunnianzhong/article/details/8820123;
- 一篇KMP的英文介绍:http://www.inf.fh-flensburg.de/lang/algorithmen/pattern/kmpen.htm。
- http://blog.csdn.net/v_july_v/article/details/7041827















 7846
7846

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









