







前言
前阵子,打磨已久的React18终于正式发布,其中最重要的一个更新就是并发(concurrency)。其他的新特性如Suspense、useTransition、useDeferredValue 的内部原理都是基于并发的,可想而知在这次更新中并发的重要性。
但是,并发究竟是什么?React团队引入并发又是为了解决哪些问题呢?它到底是如何去解决的呢?前面提到的React18新特性与并发之间又有什么关系呢?
相信大家在看官方文档或者看其他人描述React新特性时,或多或少可能会对以上几个问题产生疑问。因此,本文将通过分享并发更新的整体实现思路,来帮助大家更好地理解React18这次更新的内容。
什么是并发
首先我们来看一下并发的概念:
并发,在操作系统中,是指一个时间段中有几个程序都处于已启动运行到运行完毕之间,且这几个程序都是在同一个处理机上运行,但任一个时刻点上只有一个程序在处理机上运行。
举个通俗的例子来讲就是:
- 你吃饭吃到一半,电话来了,你一直到吃完了以后才去接,这就说明你不支持并发也不支持并行。
- 你吃饭吃到一半,电话来了,你停了下来接了电话,接完后继续吃饭,这说明你支持并发。
- 你吃饭吃到一半,电话来了,你一边打电话一边吃饭,这说明你支持并行。
并发的关键是具备处理多个任务的能力,但不是在同一时刻处理,而是交替处理多个任务。比如吃饭到一半,开始打电话,打电话到一半发现信号不好挂断了,继续吃饭,又来电话了…但是每次只会处理一个任务。
在了解了并发的概念后,我们现在思考下,在React中并发指的是什么,它有什么作用呢?
React 为什么需要并发
我们都知道,js是单线程语言,同一时间只能执行一件事情。这样就会导致一个问题,如果有一个耗时任务占据了线程,那么后续的执行内容都会被阻塞。比如下面这个例子:
<button id="btn" onclick="handle()">点击按钮</button>
<script> // 用户点击事件回调
function handle() {
console.log('click 事件触发 ')
}
// 耗时任务,一直占用线程,阻塞了后续的用户行为
function render() {
for (let i = 0; i < 10 ** 5; i++) {
console.log(i)
}
}
window.onload = function () {
render()
} </script>
当我们点击按钮时,由于render函数一直在执行,所以handle回调迟迟没有执行。对于用户来讲,界面是卡死且无法交互的。
如果我们把这个例子中的render函数类比成React的更新过程:即setState触发了一次更新,而这次更新耗时非常久,比如200ms。那么在这200ms的时间内界面是卡死的,用户无法进行交互,非常影响用户的使用体验。如下图所示,200ms内浏览器的渲染被阻塞,且用户的click事件回调也被阻塞。

那我们该如何解决这个问题呢?React18给出的答案就是:并发。
我们可以将react更新看作一个任务,click事件看作一个任务。在并发的情况下,react更新到一半的时候,进来了click任务,这个时候先去执行click任务。等click任务执行完成后,接着继续执行剩余的react更新。这样就保证了即使在耗时更新的情况下,用户依旧是可以进行交互的(interactive)。
虽然这个想法看上去非常不错,但是实现起来就有点困难了。比如更新到一半时怎么中断?更新中断了又怎么恢复呢?如果click又触发了react更新不就同时存在了两个更新了吗,它们的状态怎么区分?等等各种问题。
虽然很困难,但React18确实做到了这一点:
Concurrency is not a feature, per se. It’s a new behind-the-scenes mechanism that enables React to prepare multiple versions of your UI at the same time.
正如官网中描述的:并发是一种新的幕后机制,它允许在同一时间里,准备多个版本的UI,即多个版本的更新,也就是前面我们提到的并发。下面我们将逐步了解React是怎么实现并发的。
浏览器的一帧里做了什么?
首先,我们需要了解一个前置知识点——window.requestIdleCallback。它的功能如下:
window.requestIdleCallback() 方法插入一个函数,这个函数将在浏览器空闲时期被调用。
网上有许多文章在聊到React的调度(schedule)和时间切片(time slicing)的时候都提到了这个api。那么这个api究竟有什么作用呢?浏览器的空闲时间又是指的什么呢?
带着这个疑问,我们看看浏览器里的一帧发生了什么。我们知道,通常情况下,浏览器的一帧为16.7ms。由于js是单线程,那么它内部的一些事件,比如 click事件,宏任务,微任务,requestAnimatinFrame,requestIdleCallback等等都会在浏览器帧里按一定的顺序去执行。具体的执行顺序如下:
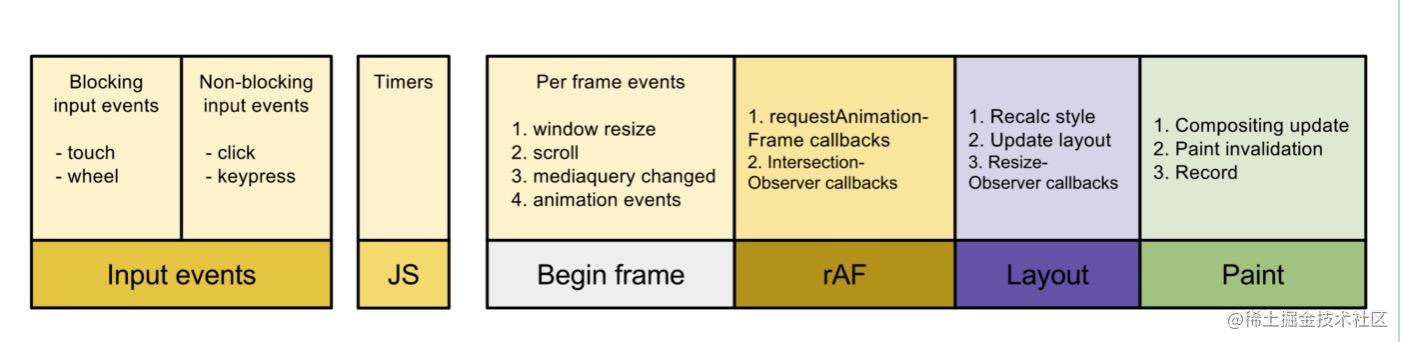
我们可以发现,浏览器一帧里回调的执行顺序为:
- 用户事件:最先执行,比如
click等事件。 js代码:宏任务和微任务,这段时间里可以执行多个宏任务,但是必须把微任务队列执行完成。宏任务会被浏览器自动调控。比如浏览器如果觉得宏任务执行时间太久,它会将下一个宏任务分配到下一帧中,避免掉帧。- 在渲染前执行
scroll/resize等事件回调。 - 在渲染前执行
requestAnimationFrame回调。 - 渲染界面:面试中经常提到的浏览器渲染时
html、css的计算布局绘制等都是在这里完成。 requestIdleCallback执行回调:如果前面的那些任务执行完成了,一帧还剩余时间,那么会调用该函数。
从上面可以知道,requestIdleCallback表示的是浏览器里每一帧里在确保其他任务完成时,还剩余时间,那么就会执行requestIdleCallback回调。比如其余任务执行了10ms,那么这一帧里就还剩6.7ms的时间,那么就会触发requestIdleCallback的回调。
了解了这个方法后,我们可以做一个假设:如果我们把React的更新(如200ms)拆分成一个个小的更新(如40 个 5ms 的更新),然后每个小更新放到requestIdleCallback中执行。那么就意味着这些小更新会在浏览器每一帧的空闲时间去执行。如果一帧里有多余时间就执行,没有多余时间就推到下一帧继续执行。这样的话,更新一直在继续,并且同时还能确保每一帧里的事件如click,宏任务,微任务,渲染等能够正常执行,也就可以达到用户可交互的目的。
但是,requestIdleCallback的兼容性太差了:

因此,React团队决定自己实现一个类似的功能:时间切片(time slicing)。接下来我们看看时间切片是如何实现的。
时间切片
假如React一个更新需要耗时200ms,我们可以将其拆分为40个5ms的更新(后续会讲到如何拆分),然后每一帧里只花5ms来执行更新。那么,每一帧里不就剩余16.7 - 5 = 11.7ms的时间可以进行用户事件,渲染等其他的js操作吗?如下所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-HSjIdy1Z-1652253577077)(https://p9-juejin.byteimg.com/tos-cn-i-k3u1fbpfcp/7fd7cda8979548899e753b7aa30127a9~tplv-k3u1fbpfcp-zoom-in-crop-mark:1956:0:0:0.image?)]
那么这里就有两个问题:
- 问题1:如何控制每一帧只执行
5ms的更新? - 问题2:如何控制
40
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1197
1197











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









