







 超级会员免费看
超级会员免费看
 当Spark作业在YARN上运行时,由于内存不足可能导致container被杀。解决办法包括关闭`yarn.nodemanager.vmem-check-enabled`,增大`spark.yarn.executor.memoryOverhead`,降低并行度,处理数据倾斜,以及调整RDD缓存和内存比例。此外,理解YARN相关参数如`yarn.nodemanager.resource.memory-mb`对优化配置至关重要。
当Spark作业在YARN上运行时,由于内存不足可能导致container被杀。解决办法包括关闭`yarn.nodemanager.vmem-check-enabled`,增大`spark.yarn.executor.memoryOverhead`,降低并行度,处理数据倾斜,以及调整RDD缓存和内存比例。此外,理解YARN相关参数如`yarn.nodemanager.resource.memory-mb`对优化配置至关重要。
Bug信息
WARN TaskSetManager: Lost task 49.2 in stage 6.0 (TID xxx,
xxx.xxx.xxx.compute.internal): ExecutorLostFailure (executor 16 exited caused by one
of the running tasks) Reason: Container killed by YARN for exceeding memory limits.
18 GB of 18 GB physical memory used. Consider boosting
spark.yarn.executor.memoryOverhead or disabling yarn.nodemanager.vmem-check-enabled...
Bug本质原因
Yarn的nodemanager中某个container内存不够了,换句话说就是这个container中的数据太大了,超出它的内存上限了。
那么一个container中内存存了什么东西呢?是什么导致的超出内存限制呢?
下面这张图可以直观的看出几个内存的关系:
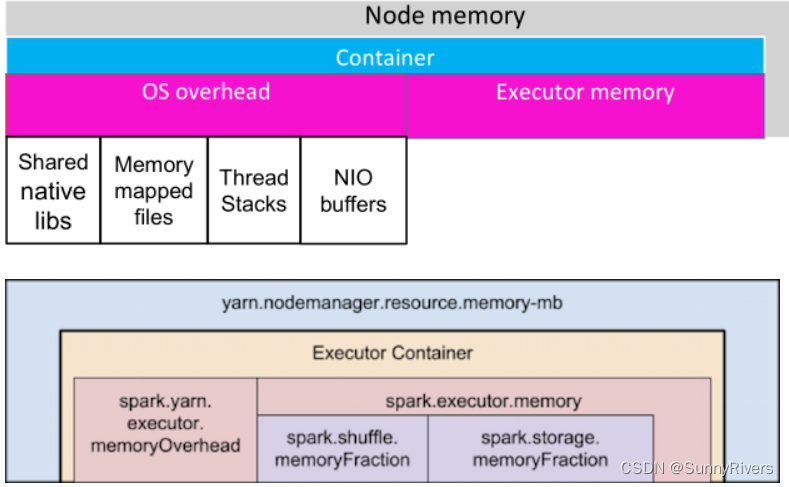
从上图可以看出一个container中有两部分内存组成&#x

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 5839
5839

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











