







多用户模式也称远程服务模式,用户非java客户端访问元数据库,在服务端启动MetaStoreServer,客户端利用Thrift协议通过MetaStoreServer访问元数据库。
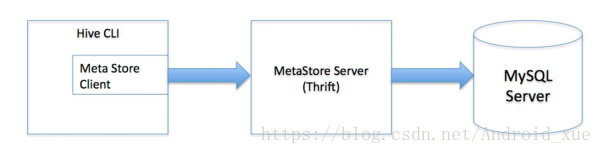
使用hive多用户模式前提:
(1)启动hadoop集群
(2)启动mysql服务
节点规划:
hadoop01作为mysql服务,用来存放元数据信息
hadoop03作为hive服务端
hadoop04作为hive客户端
搭建步骤:
1. 把hive的jar包通过远程发送给hadoop03、hadoop04
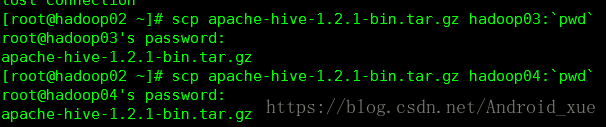
解压后配置环境变量(步骤和之前一样)
2. 配置服务端hadoop03中的hive-site.xml文件
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hadoop01:3306/hive?createDatabaseIfNotExist=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123</value>
</property>
</configuration>
3. hadoop03作为服务端需要连接mysql所以也要mysql的驱动jar包

4. 启动服务端
hive --service metastore

发现阻塞在这里了
因为客户端正在监听它,那么监听它的端口是多少呢?9083
ss -nal命令查看
5. 配置客户端hadoop04中的hive-site.xml文件:
客户端:
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
<property>
<name>hive.metastore.local</name>
<value>false</value>
</property>
<property>
<name>hive.metastore.uris</name>
<value>thrift://hadoop03:9083</value>
</property>
6. 由于客户端需要执行hive操作(换句话说谁需要请求server谁就需要把jline进行替换),所以需要把hive中jline的jar包拷贝到hadoop的
(/opt/software/hadoop-2.6.5/share/hadoop/yarn/lib/)目录的下,并把其中低版本的删掉,不然会报错。

7.在客户端hadoop04上执行hive操作:
hive> create table test02(id int,age int);
OK
Time taken: 2.84 seconds
hive> insert into test02 values(2,24);
Query ID = root_20180429235125_dd6de207-0551-4cf3-9e43-c366b4cbdbd1
Total jobs = 3
Launching Job 1 out of 3
Number of reduce tasks is set to 0 since there's no reduce operator
Starting Job = job_1525003393708_0002, Tracking URL = http://hadoop03:8088/proxy/application_1525003393708_0002/
Kill Command = /opt/software/hadoop-2.6.5/bin/hadoop job -kill job_1525003393708_0002
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 0
2018-04-29 23:51:53,973 Stage-1 map = 0%, reduce = 0%
2018-04-29 23:52:10,357 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 2.33 sec
MapReduce Total cumulative CPU time: 2 seconds 330 msec
Ended Job = job_1525003393708_0002
Stage-4 is selected by condition resolver.
Stage-3 is filtered out by condition resolver.
Stage-5 is filtered out by condition resolver.
Moving data to: hdfs://mycluster/user/hive/warehouse/test02/.hive-staging_hive_2018-04-29_23-51-25_850_3672183876211142123-1/-ext-10000
Loading data to table default.test02
Table default.test02 stats: [numFiles=1, numRows=1, totalSize=5, rawDataSize=4]
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Cumulative CPU: 2.33 sec HDFS Read: 3527 HDFS Write: 75 SUCCESS
Total MapReduce CPU Time Spent: 2 seconds 330 msec
OK
Time taken: 47.009 seconds
hive>
在webui中查看:


使用命令查看hdfs文件:

数据库查看元数据的方式和之前一样















 433
433











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











