







前言
在上篇文章HDFS多rack分布的block placement policy设计实现里,笔者探讨了HDFS数据副本跨多rack分布的新placement方案,以此来提高数据的可用性。因为在日常集群运行过程中,是可能存在因为集群的操作维护导致短时间内一整个rack处于停服务状态的。按照HDFS三副本的存放策略,一整个rack离线意味着2/3的拷贝丢失了,这将极大增加数据不可访问的概率。本文我们来继续深入探讨这一话题,既然数据副本已经能够做到rack粒度的分开存储,那么是否我们还能够再进一步做到分区域的存储呢?这里的区域概念指的是一个集群内的各个区域。各个区域里之间具有一定隔离性,但是它们还是属于一个data center。在一个data center内,如果我们还能将数据均匀分配到这些独立区域内,这样就不仅能够做到rack的分离,还能做到区域的隔离了。这样的话,我们的数据还能够容忍一个区域机器的crash。这样毫无疑问,能够再次提高集群数据的可用性。本文我们就来聊聊数据的跨区域存储。
跨区域存储和跨rack存储的区别
首先我们来具体解释下跨区域和跨rack存储的差别:
一个data center里,区域数量是比较少的,一个区域里包含一组rack,它是rack的集合。一个集群可以包含有几个区域,我们可以理解这里的区域是一个zone的概念。不同区域可以互为灾备。用更简单的话来解释,区域是rack上面更高一级的概念。我们假设rack不会出现同时包含在2个区域分布的情况下,那么跨区域的数据存储也一定是跨rack的数据存储。
下面分别是数据跨rack以及跨区域的分布效果图:
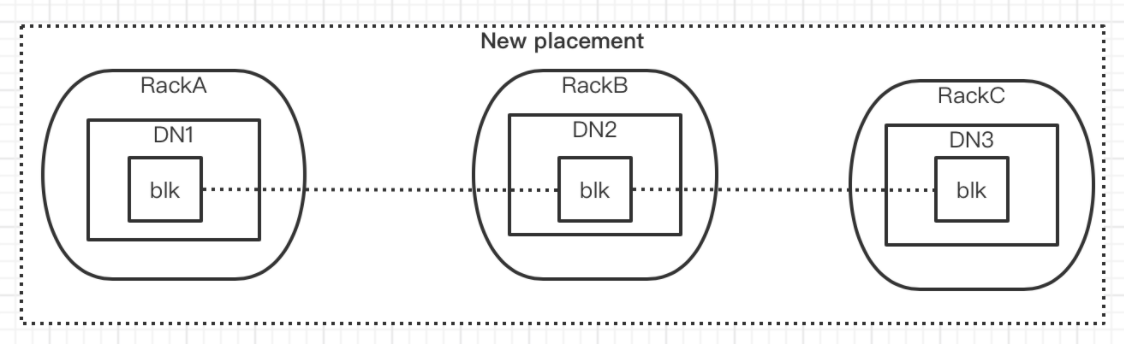
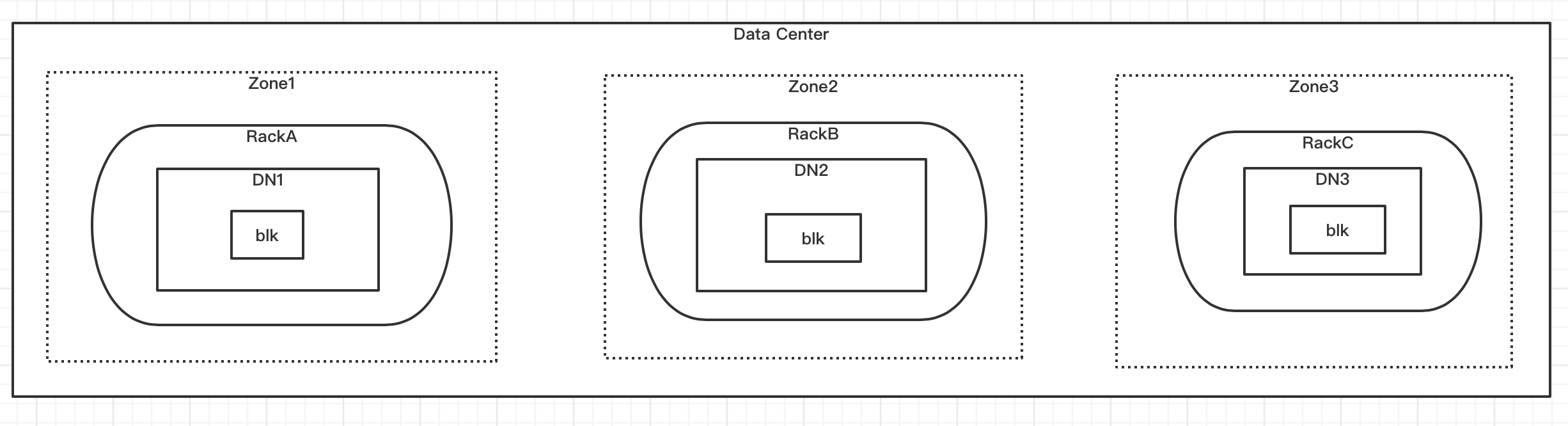
HDFS跨区域存储代码逻辑修改
上篇文章笔者详细分析了如何改动原有的choose target逻辑来支持3个rack location选择,主要的操作是覆盖了其中chooseLocalRack的方法,将其转成类似choose remote rack的逻辑。choose remote rack采用的是随机rack选择的方法,并没有同时传入之前选中的2个rack信息,其中会存在一定小概率的rack被重复选中的可能,因此在location检查的方法中多做了rack的判断。
但是在数据跨区域存储中,由于可选区域数远比集群rack数少,因此倘若依然采用随机选择的办法,将会导致一个比较高的区域重复选择率。因此如何做到精准,高效的区域选择,是一个需要重点解决的问题。
透过现象看本质,上面问题发生的原因实质上是所选location位置没有作为exclude的位置信息传入,导致了后续location选择的不精准。所以如果我们能把之前选过的location信息传入到后续的location选择方法内,那么是否就能完美解决这个问题了呢?
这里我们要把HDFS choose target的逻辑搬出来,看看它是怎么跑的。在默认的block placement实现类中,我们能够看到下面这样的方法:
/**
* Choose a datanode from the given <i>scope</i>.
* @return the chosen node, if there is any.
*/
protected DatanodeDescriptor chooseDataNode(final String scope,
final Collection<Node> excludedNodes) {
return (DatanodeDescriptor) clusterMap.chooseRandom(scope, excludedNodes);
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 5608
5608











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









