







 本文探讨了Hadoop的压缩框架,重点介绍了Compressor和Decompressor的角色,以及CompressionInputStream和CompressionOutputStream的功能。Hadoop支持gzip、bzip、snappy等多种压缩算法,它们通过CompressionCodec接口实现。压缩过程包括设置输入数据、判断输入状态、压缩数据和结束标记。解压缩的流程与压缩类似。文章详细解析了压缩的关键步骤,包括setInput()、finish()和JNI调用的底层压缩处理。
本文探讨了Hadoop的压缩框架,重点介绍了Compressor和Decompressor的角色,以及CompressionInputStream和CompressionOutputStream的功能。Hadoop支持gzip、bzip、snappy等多种压缩算法,它们通过CompressionCodec接口实现。压缩过程包括设置输入数据、判断输入状态、压缩数据和结束标记。解压缩的流程与压缩类似。文章详细解析了压缩的关键步骤,包括setInput()、finish()和JNI调用的底层压缩处理。
Hadoop的Compressor解压缩模块是Hadoop Common IO模块中又一大的模块。虽然说在现实生活中,我们使用压缩工具等的使用场景并不是那么多。或许在我们潜在的意识里,压缩的概念就停留在一些压缩种类上,zip,gzip,bizp等等不同类型的压缩,分别具有不同的压缩比,效率比等等。也许当你看完本篇本人对于Hadoop的压缩框架的学习之后,你一定会有所收获。
压缩对于数据的传输室至关重要的,同样对于存储来说也大大的提高了效率,在Hadoop系统中目前支持的压缩算法包括1,gzip 2.bzip 3.snappy4.default系统默认算法。这些压缩工具的体现都是通过一个叫CompressionCodec的对象来体现的。先来看看这个类:
/**
* This class encapsulates a streaming compression/decompression pair.
*/
public interface CompressionCodec {
CompressionOutputStream createOutputStream(OutputStream out) throws IOException;
CompressionOutputStream createOutputStream(OutputStream out,
Compressor compressor) throws IOException;
Class<? extends Compressor> getCompressorType();
Compressor createCompressor();
CompressionInputStream createInputStream(InputStream in) throws IOException;
CompressionInputStream createInputStream(InputStream in,
Decompressor decompressor) throws IOException;
Class<? extends Decompressor> getDecompressorType();
Decompressor createDecompressor();
String getDefaultExtension();
}1个是Compressor和Decompressor解压缩的构造,
1个是CompressionInputStream,CompressionOutputStream压缩输入输出流。
其实2者很像,因为压缩输入输出流的很多操作也是基于上面的压缩器,解压器的操作实现的。具体压缩算法的表现都是继承与这个基类。看一下比较庞大的结构图:
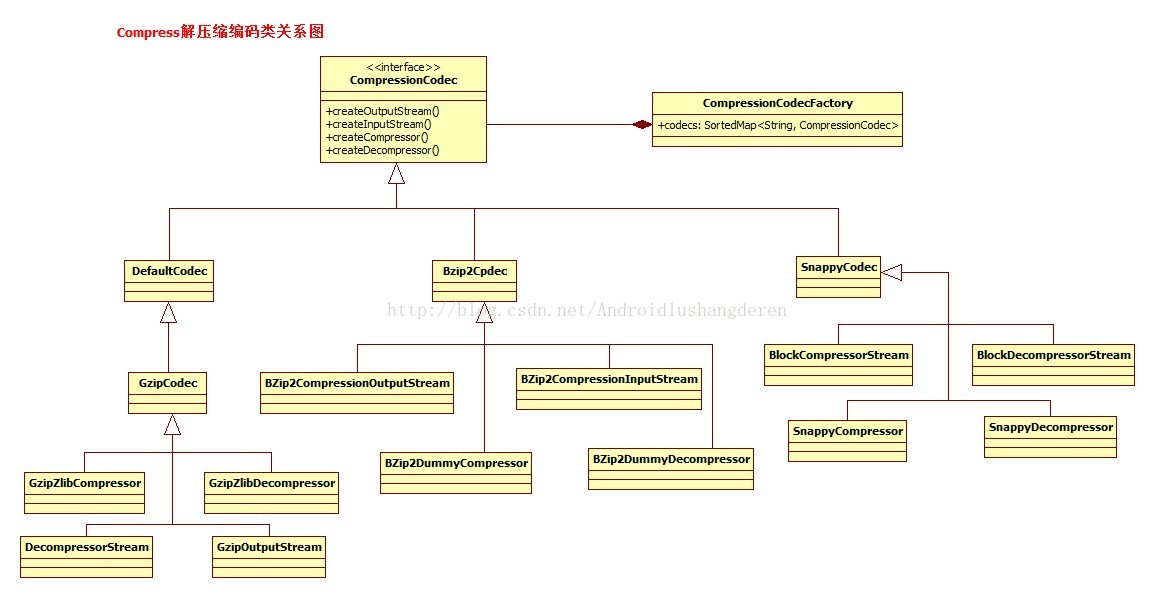
可以看到在每种Codec子类中,都会有解压缩器的实现和压缩输入输出流的构造。然后把这种压缩算法类保存在了一个Codec的工厂中,通过统一的接口调用。
public class CompressionCodecFactory {
public static final Log LOG =
LogFactory.getLog(CompressionCodecFactory.class.getName());
/**
* A map from the reversed filename suffixes to the codecs.
* This is probably overkill, because the maps should be small, but it
* automatically supports finding the longest matching suffix.
* 所有的解压缩编码类放入 codecs Map图中,CompressionCodec是一个基类,
* 允许添加上其所继承的子类
*/
private SortedMap<String, CompressionCodec> codecs = null;
/**
* Find the codecs specified in the config value io.compression.codecs
* and register them. Defaults to gzip and zip.
* 根据配置初始化压缩编码工厂,默认添加的是gzip和zip编码类
*/
public CompressionCodecFactory(Configuration conf) {
codecs = new TreeMap<String, CompressionCodec>();
List<Class<? extends CompressionCodec>> codecCl 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









