







 本文介绍了在Hadoop集群中,当节点下线操作被中止后,如何处理大量剩余复制块的问题。下线操作涉及数据的重新复制,确保数据安全。但误操作或临时变更可能会导致不必要的复制块残留,影响NameNode性能。通过分析源码,文章揭示了Dead Node恢复与下线恢复的区别,并提出了解决方案,包括在DecommissionManager中添加新方法以移除残余副本块。
本文介绍了在Hadoop集群中,当节点下线操作被中止后,如何处理大量剩余复制块的问题。下线操作涉及数据的重新复制,确保数据安全。但误操作或临时变更可能会导致不必要的复制块残留,影响NameNode性能。通过分析源码,文章揭示了Dead Node恢复与下线恢复的区别,并提出了解决方案,包括在DecommissionManager中添加新方法以移除残余副本块。
前言
如果说你是一名hadoop集群的日常维护者,那么你肯定经历过很多的节点上下线工作.例如,随着业务规模的高速扩张,集群的资源渐渐的不够使用的时候,一般正常的做法是通过增加机器来达到线性扩展的效果.当然,当这些机器在使用的过程中,出现了机器老化而引发的各自问题的时候,比如磁盘坏了,又比如某些机器网络偶尔连接不上了等,这个时候,就要把这些机器从集群中挪掉,切忌不能图一时的小利益,将这些机器留在集群中,往往像这样的异常机器会影响到集群整体的运行效率,因为不同机器上跑的任务会相互关联,你的没跑完,我的任务就必须等.今天本篇文章所要围绕的主题就是与机器的下线操作有关.
节点下线操作具体是什么意思
这里要解释一个略显的比较专业的名词:节点下线.对应的单词是Decommision,大意就是说将1个节点从集群中移除掉,并且不会对集群造成影响.所以很明显的可以看出,下线操作必然会导致集群失去大约1个节点资源的计算能力,但在hadoop中下线操作最重要的还是2个字:数据.如何保证下线节点中的数据能够完全转移到其他机器中,这才是最关键的.所以在DataNode的下线过程中,做的主要操作就是block块的重新复制,来达到HDFS默认的3副本的数据备份,当这些数据都拷贝完毕后,datanode的节点状态就是decommissioned,这个时候就可以stop datanode,彻底将机器关机移除掉.
节点下线中止后大量块复制残留
上一小节其实是一个铺垫,下线操作中出现的问题才是本文所重点强调的.当你在进行普通的机器下线中,当然过程会非常的顺利.但是当你执行完节点下线操作后,出现下面2种情形时:
1.你发现是1个误操作,误将nodeA节点加入到dfs.exclude文件中了
2.你受到上级指示,这个节点暂时不进行下线,重新调回正常服务状态
上述2种情况发生后,你的第一反应就是将节点从exclude文件中移掉,并重新dfsadmin -refreshNodes,当然你会很高兴的看到,节点的状态确实重新变为In Service的状态了.但是你如果再仔细一点的话,你会发现namenode主页面上的underReplicatedBlocks块的个数并没有减少,依然是中止下线操作前的数值.这些待复制的块基本就是原下线节点上存储的那些块.就是如下图所示的区域:
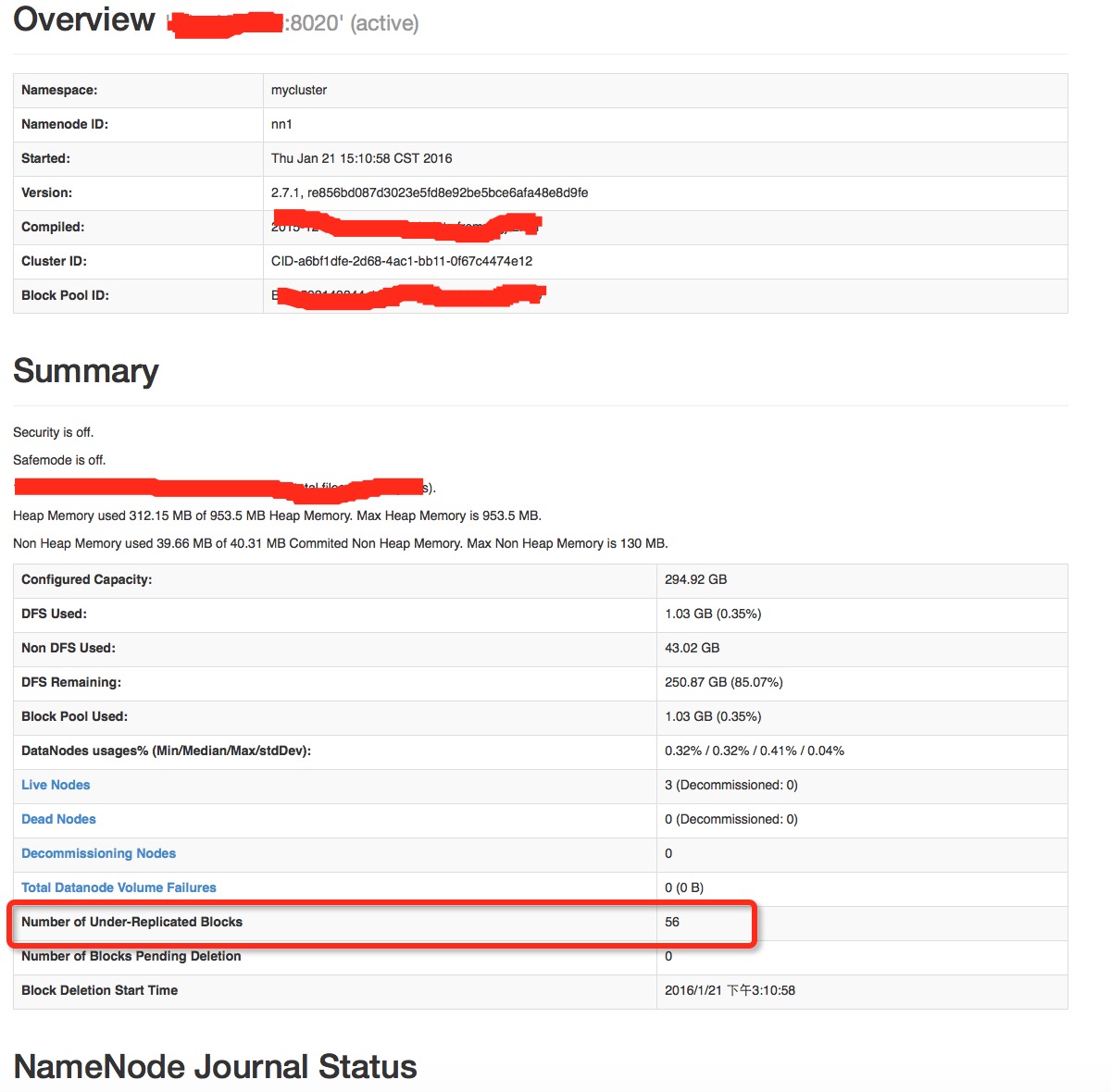
显然当下线节点恢复后,这些大量的复制块请求是不需要的,而且会持续占用namenode的时间去处理这些待复制block块,而且最后会频繁的发现,HDFS已经存在足够的块副本了,当有大量的待复制块时,那对namenode来说简直就是灾难,甚至会直接影响到namenode正常的请求处理.OK,从这里可以看出,这绝对不是一个小问题,在后面的篇幅中将会给出一套完整的解决方案,在这之前,为了帮助大家扩展一下视野,在介绍一种类似大量残余复制块的场景.
类似场景:Dead Node"复活"
出现大量复制块的另外一个场景就是出现Dead Node.当一个DataNode出现心跳长时间不汇报,超过心跳检测超时时间后,就会被任务是Dead Node.出现了Dead Node后,为了达到副本块的平衡,同样会进行大量块的拷贝,与Decommision下线操作极为类似.但是这里会有1个主要的不同点,当Dead Node,重启之后,这些残余复制块过一会就会减少到Dead Node之前的正常值.(不相信的同学可以执行这个操作进行验证).2种场景,相似的现象,不同的结果.Dead Node恢复的情况才是我们想看到的结果.那么为什么Dead Node的恢复会使得复制块的减少,而下线恢复操作则不会呢,解决这个问题的唯一办法还是从源码中寻找,光猜是永远解决不了问题的,一旦这个答案发现,一定有助于我们用相同的办法解决下线操作时大量复制块残留的问题.
Dead Node复活-"复制块消除"
本篇文章中的角色始终在围绕着"复制块",那么在HDFS的代码中,这个变量到底是被对象类所控制的呢,找到这个变量,方法很关键.答案在FSNamesystem类中,代码如下:
@Override // FSNamesystemMBean
@Metric
public long getUnderReplicatedBlocks() {
return blockManager.getUnderReplicatedBlocksCount();
}/** Used by metrics */
public long getUnderReplicatedBlocksCount() {
return underReplicatedBlocksCount;
}void updateState() {
pendingReplicationBlocksCount = pendingReplications.size();
underReplicatedBlocksCount = neededReplications.size();
corruptReplicaBlocksCount = corruptReplicas.size();
}/**
* Main loop for each BP thread. Run until shutdown,
* forever calling remote NameNode functions.
*/
private void offerService() throws Exception {
LOG.info("For namenode " + nnAddr + " using"
+ " DELETEREPORT_INTERVAL of " + dnConf.deleteReportInterval + " msec "
+ " BLOCKREPORT_INTERVAL of " + dnConf.blockReportInterval + "msec"
+ " CACHEREPORT_INTERVAL of " + dnConf.cacheReportInterval + "msec"
+ " Initial delay: " + dnConf.initialBlockReportDelay + "msec"
+ "; heartBeatInterval=" + dnConf.heartBeatInterval);
//
// Now loop for a long time....
//
while (shouldRun()) {
try {
final long startTime = scheduler.monotonicNow();
//
// Every so often, send heartbeat or block-report
//
final boolean sendHeartbeat = scheduler.isHeartbeatDue(startTime);
if (sendHeartbeat) {
...
}
if (sendImmediateIBR ||
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









