







 本文介绍了HDFS的Truncate功能,用于截断文件,类似于Linux的truncate命令。Truncate主要针对HDFS文件的block进行操作,支持在特定场景下回滚文件到先前状态。该功能在Hadoop 2.7.0及以上版本中可用,适用于移除意外写入的数据、回滚失败的写事务等场景。文章详细阐述了Truncate的实现原理和源码分析,并提到了特殊情况下的‘copy-on-truncate’操作。
本文介绍了HDFS的Truncate功能,用于截断文件,类似于Linux的truncate命令。Truncate主要针对HDFS文件的block进行操作,支持在特定场景下回滚文件到先前状态。该功能在Hadoop 2.7.0及以上版本中可用,适用于移除意外写入的数据、回滚失败的写事务等场景。文章详细阐述了Truncate的实现原理和源码分析,并提到了特殊情况下的‘copy-on-truncate’操作。
前言
在linux操作系统的使用中,有的时候我们可能想对某个现有的文件做尾部的截取(比如为了保留头部关键信息),但同时又不想重新写一个新的文件出来,这个时候我们其实可以采用系统提供的truncate命令。单词truncate的本意是“截断”,在这里由于操作的对象是文件,所以此命令的作用就是文件的截断。那么同样作为一套成熟的文件系统,HDFS是否也能支持这样的API方法呢?可能它与linux文件系统的一个巨大差别在于它是分布式的,但是这不会影响到HDFS Truncate功能的实现,正如标题所显示的,HDFS同样支持了truncate的操作。
HDFS Truncate功能概述
首先第一点要让大家有一个大概的认识,HDFS Truncate不会是一个很大,很复杂的改动,它实质上是对现有HDFS读写文件操作方法的一个补充和完善。简单地说,就是在HDFS的客户端和服务端增加一个truncate(…)方法。个人认为其中唯一一点比较难的是truncate截断操作如何落实到HDFS的block文件块的操作中,这一点也是大家所要着重去理解的。
Truncate文件截断在HDFS上的表现其实是block的截断。传入目标文件,与目标保留的长度(此长度应小于文件原大小),如下图所示:
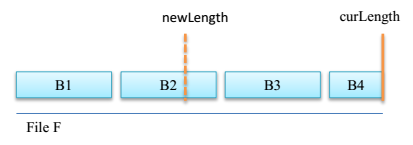
图 1-1 HDFS文件截断原理
上图表示的意思是说,一个文件有拥有4个block块,然后需要截取的长度刚好处在第二block快上,当真正截断操作发生后,B2的后半部,B3和B4就会被移除。
与原生的linux上的truncate命令略有不同的是,HDFS的truncate命令不支持截断超过当前文件大小的情况,如果是这种情况会抛出异常。而在linux中,这种情况下会在超出实际长度的部分返回空字节数据。
HDFS Truncate使用场景
这节我们聚焦的话题是HDFS Truncate到底有哪些适用场景呢?在其设计文档中,列举了如下几项:
- 第一点,允许用户移除意外写入的数据。
- 第二点,当写事务发生失败的时候,可以进行回滚,回到之前写入成功的事务状态。
- 第三点,有能力移除一次失败的写操作而写入的不完整的数据。
- 第四点,提升HDFS对于其它文件系统的支持度。
这里很有意思的一点是,truncate方法与append方法刚好是互逆的方法,在许多意外情况下我们append的出错数据可以通过truncate进行还原。
HDFS Truncate的实现原理
在本小节中,我们来看看HDFS的具体的实现原理,步骤不会太复杂,下面会同时给出具体的操作图帮助大家进行理解。
首先是一个初始的文件块,当前长度与目标截取的长度如下所示:
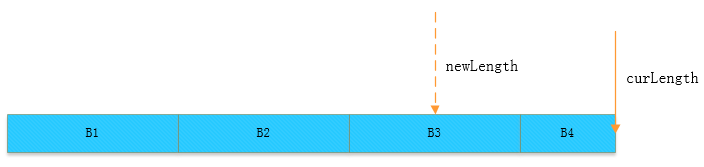
图 1-2 原始文件
要截取到newLength所指示的地方,我们需要做下面2个过程,
第一步,定位到新的截取长度所对应的块,然后把后面多余的块(这里就是B4)从此文件中进行移除,如下图所示:
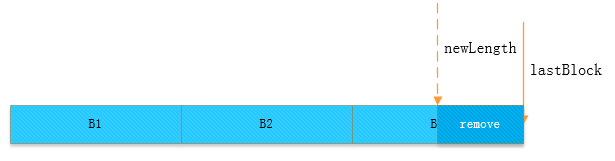
图 1-3 定位截取长度所在的block
第二步,找到新长度所对应的block块之后,计算此块内部需要移除的偏移量,然后进行删除,如下图:

图 1-4 截取最终效果图
上图就是最后的截取效果图,当然了,这里有一种特殊情况如果截取的位置恰好在block的分界处,比如刚好在B3的末尾处,则上面第二步block内部偏移量的截取操作则可以不用执行。
以上是对普通文件截取的操作,我们可以看到,它是直接在原文件上做的修改,我们可以称之为“in-place-truncate”,但是在有些情况下,我们为了保留原始的数据,需要重新拷贝一份出来做截取的动作,我们称这样的情况为“copy-on-truncate”,主要有以下2类情况:
- 当我们操作的文件为快照中的文件,需要保留当时快照维护的数据。
- 当前DataNode正处于升级过程。
上述2类情况是我们需要特殊对待的时候。
HDFS Truncate的实现
前面原理部分的内容大家如果理解了之后,将会非常有助于此小节的学习。本节我们将从源码层面去分析HDFS Truncate的实现。
首先我们从truncate方法的发起入口开始,就是DFSClient端的客户端方法,
// 文件截断方法
public boolean truncate(String src, long newLength) throws IOException {
checkOpen();
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









