








第三章:RDD
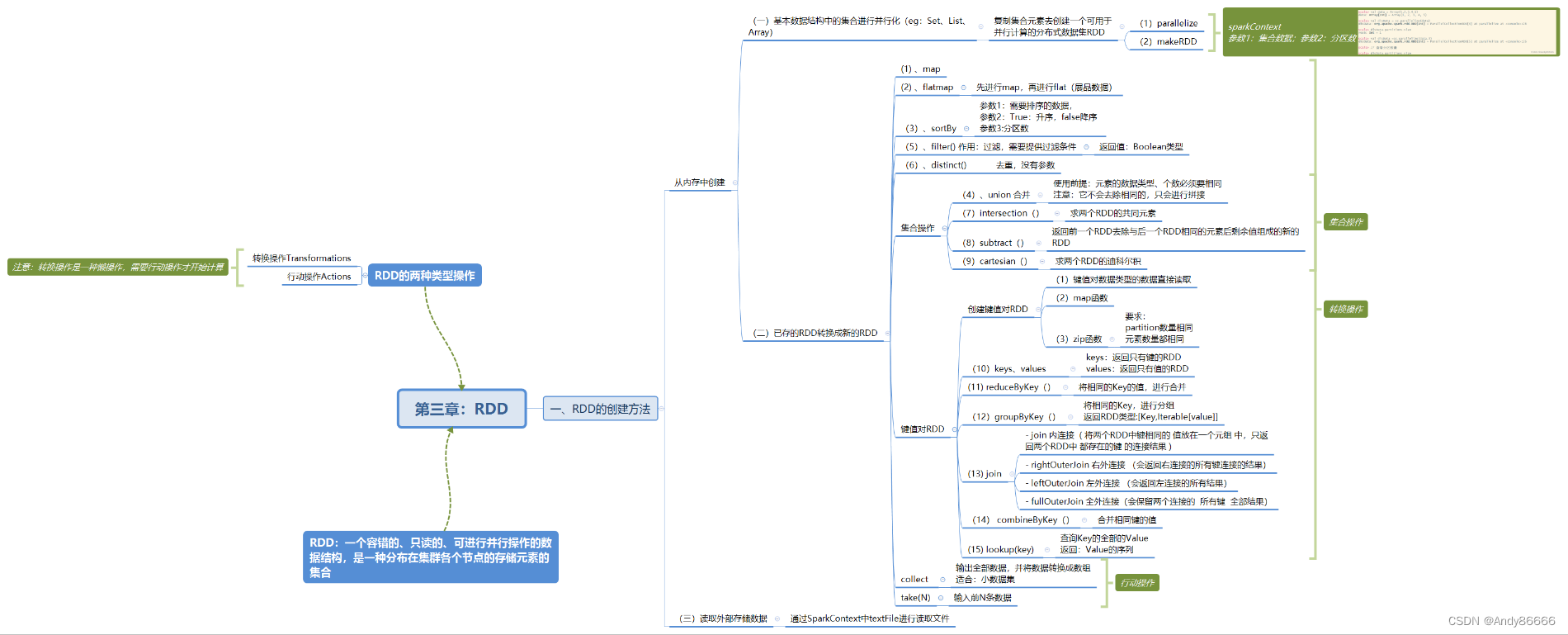
文章目录
- 第三章:RDD
- 一、从内存中已有的数据创建RDD
- (一)、基本数据结构中集合创建RDD
- (二)、将已存在RDD转换成新的RDD
- 1、map转换数据——转换操作
- 2、flatMap转换数据——转换操作
- 3、sortBy排序——转换操作
- 4、collect()查询——行动操作(返回类型:数组)
- 5、take() 查询某几个值——行动操作,返回类型:数值
- 6、union()合并多个RDD——转换操作
- 7、filter()进行过滤——转换操作,返回值:Boolean类型
- 8、使用distinct()去重
- 9、集合操作
- 键值对RDD
- 10、创建键值对的RDD
- 11、keys和values——转换操作
- 12、reduceByKey() ——转换操作
- 13、groupByKey()——转换操作
- 在这里插入图片描述 14、join()连接两个RDD
- 15、zip 组合两个RDD
- 16 、combineByKey 合并相同键的值
- 17、lookup (Key)查找指定键的值
- 二、从外部存储创建RDD
RDD:一个 容错的、只读的、可进行并行操作的 数据结构,是一种分布在集群各个节点的== 存储元素的集合==
RDD有3种方法创建
- 对程序中存在的基本数据结构中集合进行并行化
- 对已经存在的RDD转换成新的RDD
- 直接读取外部存储的数据集
一、从内存中已有的数据创建RDD
(一)、基本数据结构中集合创建RDD
1、parallelize
parallelize有两个参数
- Seq集合(指:可以迭代访问的对象数据)
- 分区数(默认:为该Application 分配到资源的CPU数)
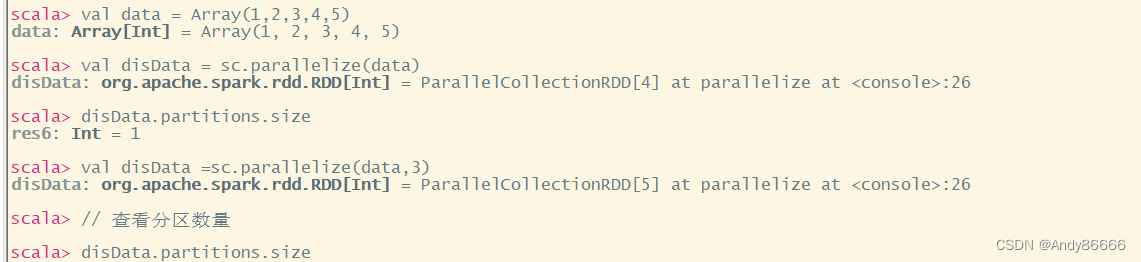
val data = Array(1,2,3,4,5)
val disData = sc.parallelize(data)
disData.partitions.size
val disData =sc.parallelize(data,3)
// 查看分区数量
disData.partitions.size
2、makeRDD
makeRDD的参数方法和parallelize一样
(二)、将已存在RDD转换成新的RDD

1、map转换数据——转换操作
属于:转换操作
map是一种基础的RDD转换操作,用于将RDD中每一个数据元素通过某种函数进行转换并会生成新RDD,但是不会立即计算。
由于RDD的特点是只读的、不可变的,因此进行修改后,必定会生成新RDD
eg:将5个数据进行平方
val data=sc.parallelize(List(1,2,4,6))
val now_data=data.map(x=>x*x)
now_data.collect

2、flatMap转换数据——转换操作
属于:转换操作
flatMap是进行map,再进行flat(展平)
eg:进行语句分割
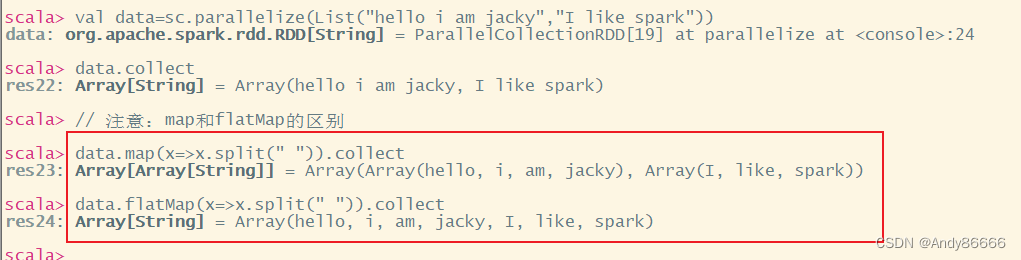
val data=sc.parallelize(List("hello i am jacky","I like spark"))
data.collect
// 注意:map和flatMap的区别
data.map(x=>x.split(" ")).collect
data.flatMap(x=>x.split(" ")).collect
3、sortBy排序——转换操作
属于:转换操作
sortBy() 有3个参数
- 第一个参数是一个函数f:(T)=>K,左边是要排序对象中的每一个元素,右边是返回的值是元素中要进行排序的值
- 第二个参数是ascending,默认为true代表的是升序,false为降序
- 第三个参数是numPartitions分区数,该参数决定排序后的RDD的分区个数。
- 注意:默认排序后的分区个数和排序之前的个数相同,即this.partitions.size
eg:对列表中第一个元素,按照升序进行排序
val data=sc.parallelize(List((1,3),(5,4),(2,6)))
val sortData=data.sortBy(x=>x._1,true,2).collect

4、collect()查询——行动操作(返回类型:数组)
属于:行动操作
返回:数组
collect()把RDD所有元素转换成数组 并返回到Driver端中,适合于小数据集
注意:如果用来查看数据集较大,Driver会将数据加载到内存中,会导致Driver端内存溢出。
方法一:
直接返回RDD中的所有元素,返回类型为数值
代码:
val data=sc.parallelize(List(1,23,4))
data.collect
结果:
scala> val data=sc.parallelize(List(1,23,4))
data: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[28] at parallelize at <console>:24
scala> data.collect
res25: Array[Int] = Array(1, 23, 4)
方法二:collect[U:ClassTag](f:PartialFunction[T,U]):RDD[U]
该用法较少,需要提供一个标准的偏函数
eg: 将性别F、M替换1,0
代码:
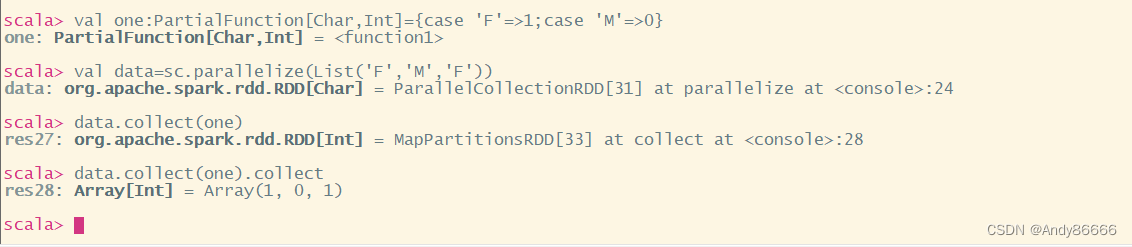
val one:PartialFunction[Char,Int]={case 'F'=>1;case 'M'=>0}
val data=sc.parallelize(List('F','M','F'))
data.collect(one)
注意:one:PartialFunction[Char,Int] ,输入数据类型是Char,输出数据类型为Int
结果:
scala> val one:PartialFunction[Char,Int]={case 'F'=>1;case 'M'=>0}
one: PartialFunction[Char,Int] = <function1>
scala> val data=sc.parallelize(List('F','M','F'))
data: org.apache.spark.rdd.RDD[Char] = ParallelCollectionRDD[31] at parallelize at <console>:24
scala> data.collect(one)
res27: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[33] at collect at <console>:28
scala> data.collect(one).collect
res28: Array[Int] = Array(1, 0, 1)
5、take() 查询某几个值——行动操作,返回类型:数值
属于:行动操作
返回值:数值类型
take(N)是获取RDD的前N个元素,返回类型为数组。
注意:collect和take(N) 区别:collect是输出全部数据集,take(N)是输出前N条数据
eg:
val data=sc.makeRDD(1 to 10)
data.take(5)
结果:
scala> val data=sc.makeRDD(1 to 10)
data: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[36] at makeRDD at <console>:24
scala> data.take(5)
res29: Array[Int] = Array(1, 2, 3, 4, 5)

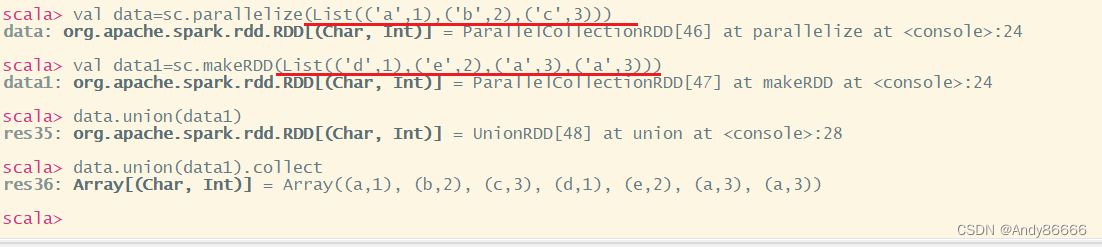
6、union()合并多个RDD——转换操作
属于:转换操作
用于将两个RDD的元素合并成一个,不进行去重操作,而且两个的RDD每一个元素中的值个数和元素类型要保存一致
注意:union不会将数据进行去重,而是直接拼接在一起
eg:
val data=sc.parallelize(List(('a',1),('b',2),('c',3)))
val data1=sc.makeRDD(List(('d',1),('e',2),('a',3),('a',3)))
data.union(data1)
data.union(data1).collect
结果:
scala> val data=sc.parallelize(List(('a',1),('b',2),('c',3)))
data: org.apache.spark.rdd.RDD[(Char, Int)] = ParallelCollectionRDD[42] at parallelize at <console>:24
scala> val data1=sc.makeRDD(List(('d',1),('e',2),('a',3),('a',3)))
data1: org.apache.spark.rdd.RDD[(Char, Int)] = ParallelCollectionRDD[43] at makeRDD at <console>:24
scala> data.union(data1)
res33: org.apache.spark.rdd.RDD[(Char, Int)] = UnionRDD[44] at union at <console>:28
scala> data.union(data1).collect
res34: Array[(Char, Int)] = Array((a,1), (b,2), (c,3), (d,1), (e,2), (a,3), (a,3))
7、filter()进行过滤——转换操作,返回值:Boolean类型
属性:转换操作
返回值:Boolean类型
filter需要一个参数,参数是一个用过滤的函数,该函数返回的是Boolean类型的
eg:筛选出大于2
val data=sc.parallelize(List(('a',1),('c',3),('d',2)))
data.filter(x=>x._2>2).collect
data.filter(_._2>2).collect
结果:
scala> val data=sc.parallelize(List(('a',1),('c',3),('d',2)))
data: org.apache.spark.rdd.RDD[(Char, Int)] = ParallelCollectionRDD[51] at parallelize at <console>:24
scala> data.filter(x=>x._2>2).collect
res38: Array[(Char, Int)] = Array((c,3))
scala> data.filter(_._2>2).collect
res39: Array[(Char, Int)] = Array((c,3))

8、使用distinct()去重
属于:转换操作
作用:去除完全相同的元素
eg:去除相同的元素
val data=sc.parallelize(List(('a',1),('c',3),('d',2),('a',1),('c',3),('d',2)))
data.distinct()
data.distinct().collect
结果:
scala> val data=sc.parallelize(List(('a',1),('c',3),('d',2),('a',1),('c',3),('d',2)))
data: org.apache.spark.rdd.RDD[(Char, Int)] = ParallelCollectionRDD[58] at parallelize at <console>:24
scala> data.distinct()
res43: org.apache.spark.rdd.RDD[(Char, Int)] = MapPartitionsRDD[61] at distinct at <console>:26
scala> data.distinct().collect
res44: Array[(Char, Int)] = Array((d,2), (c,3), (a,1))

9、集合操作
属于:转换操作
- intersection() :求出两个RDD的共同元素(交集)
- union:合并两个RDD(并集)
- subtract():去除RDD中相同的(补集)
- cartesian():求两个RDD的笛卡尔积
(1)intersection()
求交集
val data=sc.parallelize(List(('a',1),('w',3),('a',3)))
val data1=sc.parallelize(List(('a',1),('b',1)))
data.intersection(data1)
data.intersection(data1).collect
结果:
scala> val data=sc.parallelize(List(('a',1),('w',3),('a',3)))
data: org.apache.spark.rdd.RDD[(Char, Int)] = ParallelCollectionRDD[0] at parallelize at <console>:24
scala> val data1=sc.parallelize(List(('a',1),('b',1)))
data1: org.apache.spark.rdd.RDD[(Char, Int)] = ParallelCollectionRDD[1] at parallelize at <console>:24
scala> data.intersection(data1)
res0: org.apache.spark.rdd.RDD[(Char, Int)] = MapPartitionsRDD[7] at intersection at <console>:28
scala> data.intersection(data1).collect
res1: Array[(Char, Int)] = Array((a,1))

(2)subtract()
求补集
val data=sc.parallelize(List(('a',1),('b',2),('d',2)))
val data1=sc.parallelize(List(('b',2),('c',2)))
data.subtract(data1)
data.subtract(data1).collect
结果:
scala> val data=sc.parallelize(List(('a',1),('b',2),('d',2)))
data: org.apache.spark.rdd.RDD[(Char, Int)] = ParallelCollectionRDD[14] at parallelize at <console>:24
scala> val data1=sc.parallelize(List(('b',2),('c',2)))
data1: org.apache.spark.rdd.RDD[(Char, Int)] = ParallelCollectionRDD[15] at parallelize at <console>:24
scala> data.subtract(data1)
res2: org.apache.spark.rdd.RDD[(Char, Int)] = MapPartitionsRDD[19] at subtract at <console>:28
scala> data.subtract(data1).collect
res3: Array[(Char, Int)] = Array((a,1))

键值对RDD
10、创建键值对的RDD
方法一:键值对类型的数据读取时,直接返回键值对组成的PairRDD
方法二:使用map()函数进行操作
方法三:zip() 函数 ==》但是要分区数、元素个数相同
eg:将语句第一个单词作为Key,语句作为value
val data=sc.parallelize(List("this is test","play an import in","parallelize makeRDD map flatMap filter collect take(N) union sortBy(data,true,numPartitions) distinct()"))
val words=data.map(x=>(x.split(" ")(0),x))
words.collect
结果:
scala> val data=sc.parallelize(List("this is test","play an import in","parallelize makeRDD map flatMap filter collect take(N) union sortBy(data,true,numPartitions) distinct()"))
data: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[0] at parallelize at <console>:24
scala> val words=data.map(x=>(x.split(" ")(0),x))
words: org.apache.spark.rdd.RDD[(String, String)] = MapPartitionsRDD[1] at map at <console>:25
scala> words.collect
res0: Array[(String, String)] = Array((this,this is test), (play,play an import in), (parallelize,parallelize makeRDD map flatMap filter collect take(N) union sortBy(data,true,numPartitions) distinct()))

11、keys和values——转换操作
属于:转换操作
- keys 只返回包含键的RDD
- values只返回包含值的RDD
val data=sc.parallelize(List("this is test","play an import in","parallelize makeRDD map flatMap filter collect take(N) union sortBy(data,true,numPartitions) distinct()"))
val words=data.map(x=>(x.split(" ")(0),x))
val key=words.keys
key.collect
val value=words.values
value.collect
结果:
scala> val data=sc.parallelize(List("this is test","play an import in","parallelize makeRDD map flatMap filter collect take(N) union sortBy(data,true,numPartitions) distinct()"))
data: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[2] at parallelize at <console>:24
scala> val words=data.map(x=>(x.split(" ")(0),x))
words: org.apache.spark.rdd.RDD[(String, String)] = MapPartitionsRDD[3] at map at <console>:25
scala> val key=words.keys
key: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[4] at keys at <console>:25
scala> key.collect
res1: Array[String] = Array(this, play, parallelize)
scala> val value=words.values
value: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[5] at values at <console>:25
scala> value.collect
res2: Array[String] = Array(this is test, play an import in, parallelize makeRDD map flatMap filter collect take(N) union sortBy(data,true,numPartitions) distinct())
12、reduceByKey() ——转换操作
reduceByKey()的功能是==合并具有相同键的值==
注意:只对value进行处理
reduceByKey的处理流程: 将一个Key中的前两个Value传入函数中,处理后会产生新的value,这个value会和下一个相同k的value传入到函数中,一直到只有一个值为止。
eg:将相同k的值合并在一起
方法一:
val data=sc.parallelize(List(('a',1),('c',2),('e',2),('d',1),('a',2),('c',1)))
data.map(x=>(x._1,x._2))
val reduce=data.reduceByKey((a,b)=>a+b)
reduce.collect
结果:
scala> val data=sc.parallelize(List(('a',1),('c',2),('e',2),('d',1),('a',2),('c',1)))
data: org.apache.spark.rdd.RDD[(Char, Int)] = ParallelCollectionRDD[6] at parallelize at <console>:24
scala> data.map(x=>(x._1,x._2))
res3: org.apache.spark.rdd.RDD[(Char, Int)] = MapPartitionsRDD[7] at map at <console>:26
scala> val reduce=data.reduceByKey((a,b)=>a+b)
reduce: org.apache.spark.rdd.RDD[(Char, Int)] = ShuffledRDD[8] at reduceByKey at <console>:25
scala> reduce.collect
res4: Array[(Char, Int)] = Array((d,1), (e,2), (a,3), (c,3))
方法二:
val data=sc.parallelize(List(('a',1),('c',2),('e',2),('d',1),('a',2),('c',1)))
val reduce=data.reduceByKey((a,b)=>a+b)
reduce.collect
结果:
scala> val data=sc.parallelize(List(('a',1),('c',2),('e',2),('d',1),('a',2),('c',1)))
data: org.apache.spark.rdd.RDD[(Char, Int)] = ParallelCollectionRDD[9] at parallelize at <console>:24
scala> val reduce=data.reduceByKey((a,b)=>a+b)
reduce: org.apache.spark.rdd.RDD[(Char, Int)] = ShuffledRDD[10] at reduceByKey at <console>:25
scala> reduce.collect
res5: Array[(Char, Int)] = Array((d,1), (e,2), (a,3), (c,3))
13、groupByKey()——转换操作
属于:转换操作
groupByKey()将相同的Key的值进行分组
groupByKey()得到的RDD类型为[Key,Iterable[Value]]。
分组常用于为了同一组的数据计数、统计等
eg:对每组的个数进行统计
val data=sc.parallelize(List(('a',1),('c',2),('e',2),('d',1),('a',2),('c',1)))
val data1=data.groupByKey()
data1.collect
data1.map(x=>(x._1,x._2.size)).collect
结果:
scala> val data=sc.parallelize(List(('a',1),('c',2),('e',2),('d',1),('a',2),('c',1)))
data: org.apache.spark.rdd.RDD[(Char, Int)] = ParallelCollectionRDD[3] at parallelize at <console>:24
scala> val data1=data.groupByKey()
data1: org.apache.spark.rdd.RDD[(Char, Iterable[Int])] = ShuffledRDD[4] at groupByKey at <console>:25
scala> data1.collect
res2: Array[(Char, Iterable[Int])] = Array((d,CompactBuffer(1)), (e,CompactBuffer(2)), (a,CompactBuffer(1, 2)), (c,CompactBuffer(2, 1)))
scala> data1.map(x=>(x._1,x._2.size)).collect
res3: Array[(Char, Int)] = Array((d,1), (e,1), (a,2), (c,2))
 14、join()连接两个RDD
14、join()连接两个RDD
连接分为:右外连接、左外连接、全外连接、内连接
- join 内连接 (将两个RDD中键相同的值放在一个元组中,只返回两个RDD中都存在的键的连接结果)
- rightOuterJoin 右外连接 (会返回右连接的所有键连接的结果)
- leftOuterJoin 左外连接 (会返回左连接的所有结果)
- fullOuterJoin 全外连接(会保留两个连接的==所有键==全部结果)
(1)join——相同的Key
val rdd1=sc.parallelize(List(('a',1),('b',2)))
val rdd2=sc.parallelize(List(('d',1),('a',1)))
rdd1.join(rdd2)
结果:
scala> val rdd1=sc.parallelize(List(('a',1),('b',2)))
rdd1: org.apache.spark.rdd.RDD[(Char, Int)] = ParallelCollectionRDD[6] at parallelize at <console>:24
scala> val rdd2=sc.parallelize(List(('d',1),('a',1)))
rdd2: org.apache.spark.rdd.RDD[(Char, Int)] = ParallelCollectionRDD[7] at parallelize at <console>:24
scala> rdd1.join(rdd2)
res4: org.apache.spark.rdd.RDD[(Char, (Int, Int))] = MapPartitionsRDD[10] at join at <console>:28
scala> rdd1.join(rdd2).collect
res5: Array[(Char, (Int, Int))] = Array((a,(1,1)))

(2)leftOuterJoin
val rdd1=sc.parallelize(List(('a',1),('b',2)))
val rdd2=sc.parallelize(List(('d',1),('a',1)))
rdd1.leftOuterJoin(rdd2).collect
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-pTo2p2Ck-1655809429139)(C:/Users/%E6%80%9D%E9%9D%99/AppData/Roaming/Typora/typora-user-images/image-20220619215610815.png)]
如果存在相同的key,some类型,如果没有,则为None
(3)fullOuterJoin
val rdd1=sc.parallelize(List(('a',1),('b',2)))
val rdd2=sc.parallelize(List(('d',1),('a',1)))
rdd1.fullOuterJoin(rdd2).collect
结果:
scala> val rdd1=sc.parallelize(List(('a',1),('b',2)))
rdd1: org.apache.spark.rdd.RDD[(Char, Int)] = ParallelCollectionRDD[10] at parallelize at <console>:24
scala> val rdd2=sc.parallelize(List(('d',1),('a',1)))
rdd2: org.apache.spark.rdd.RDD[(Char, Int)] = ParallelCollectionRDD[11] at parallelize at <console>:24
scala> rdd1.fullOuterJoin(rdd2).collect
res2: Array[(Char, (Option[Int], Option[Int]))] = Array((d,(None,Some(1))), (a,(Some(1),Some(1))), (b,(Some(2),None)))
15、zip 组合两个RDD
要求:partitions分区数相同,元素数量相同
val rdd1=sc.parallelize(1 to 4,2)
val rdd2=sc.parallelize(List("a","b","c","d"),2)
rdd1.zip(rdd2)
rdd1.zip(rdd2).collect

16 、combineByKey 合并相同键的值
combinByKey是其他一些高阶键值对函数底层的基础,都是依赖它来实现 eg:reduceByKey 、groupByKey等
combinByKey用于将相同键的数据聚合,并且允许返回类型与输入数值类型不同的返回值。
combineByKey的定义:
combineByKey(createCombiner,mergeValue,mergeCombiners,numPartitions=None)
createCombiner:V=>C,V是键值对的值,将该值转换成另一种类型C,C会作为每一对键的累加器的初始值mergeValue:(C,V)=>C, 该函数把元素V合并到之前的元素C上(这个操作在每一个分区内进行)mergeCombiners:(C:C)=>C,该函数把两个元素C进行合并(这个操作在不同分区间进行)
补充知识:
由于聚合操作会遍历分区中所有的元素,因此每一个元素的键只有两种情况:以前没有出现过、以前出现过的
(1)如果没有出现过的,则执行createCombiner方法,否则执行mergeValue方法
(2)对于已经出现过的键,调用mergeValue进行合并,将原来的C类型和现在V类型进行合并
(3)注意:mergeValue是在不同的分区中进行的,因此同一个Key有多个累加器,需要通过mergeCombiners进行合并不同的分区数据
17、lookup (Key)查找指定键的值
lookup(key)作用于Key/Value类型的RDD上,返回指定Key的所有Value值
eg:
val data=sc.parallelize(Array(("a",1),("c",1),("a",2))
data.lookup("a")
结果:
scala> val data=sc.parallelize(Array(("a",1),("c",1),("a",2)))
data: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[25] at parallelize at <console>:24
scala> data.lookup("a")
res8: Seq[Int] = WrappedArray(1, 2)
二、从外部存储创建RDD
从外部存储创建RDD是指直接读取一个存放在文件系统的数据文件创建RDD。
通过SparkContext对象的textFile方法读取数据,并设置分区个数
(1)读取HDFS中的文件
val data =sc.textFile("hdfs://spark1:9000/word.txt")
// 统计行数
data.count
// 展示全部内容
data.collect

(2)读取Linux中的文件
注意:在读取linux文件时,需要在路径前面加上**file://**
val data=sc.textFile("file:///home/bigdata/test.txt")
data.count
















 1006
1006











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









