






安装Flink
解压Flink
tar -zxf ./flink-1.13.2-bin-scala_2.12.tgz -C ../soft/
到指定目录
/opt/soft/flink-1.13.2/conf
vim ./masters
192.168.153.141:8081
vim ./workers
192.168.153.141
vim ./zoo.cfg
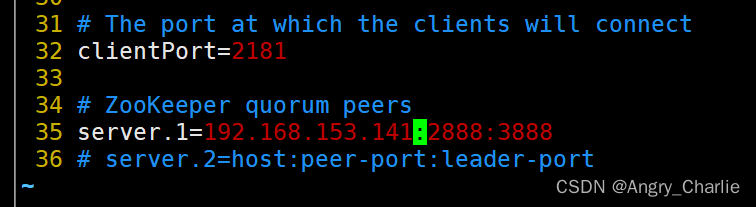
vim ./flink-conf.yaml

启动Flink
首先启动Zookeeper
zkServer.sh start
在当前目录下
/opt/soft/flink-1.13.2
./bin/start-cluster.sh
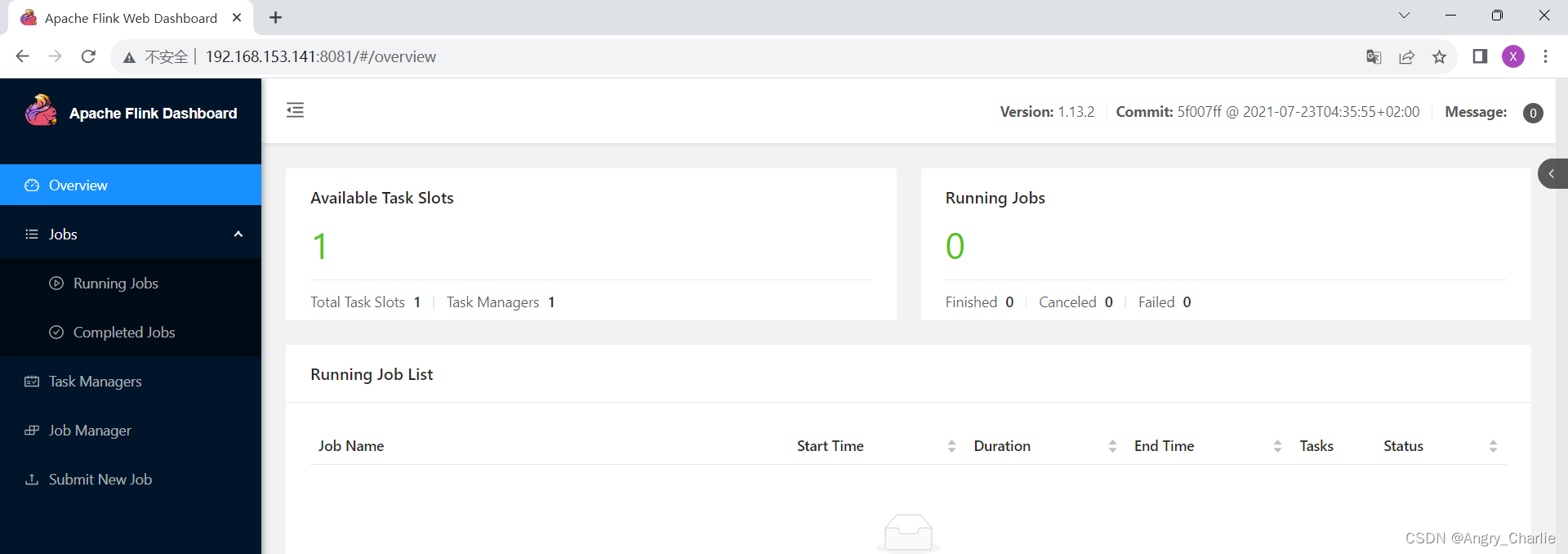
在Web UI
http://192.168.153.141:8081/
打开IDEA
添加pom.xml包
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<flink.version>1.13.2</flink.version>
</properties>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.12</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.12</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-compress</artifactId>
<version>1.21</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_2.12</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-statebackend-rocksdb_2.12</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner_2.12</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner-blink_2.12</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-csv</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.29</version>
</dependency>
<!-- scala -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-scala_2.12</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_2.12</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.1.3</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>3.1.3</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<!--<artifactId>flink-connector-kafka-0.11_2.11</artifactId>-->
<artifactId>flink-connector-kafka_2.12</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>2.3.5</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-server</artifactId>
<version>2.3.5</version>
</dependency>
<dependency>
<groupId>org.apache.bahir</groupId>
<artifactId>flink-connector-redis_2.12</artifactId>
<version>1.1.0</version>
</dependency>
添加Scala支持

创建Scala
import org.apache.flink.api.common.serialization.SimpleStringSchema
import org.apache.flink.streaming.api.functions.source.SourceFunction
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer
import org.apache.kafka.clients.consumer.{Consumer, ConsumerConfig}
import java.util.Properties
import scala.util.Random
//定义样例类
case class SensorReading(id:String, timestamp:Long, temperature: Double)
object SourceTest {
def main(args: Array[String]): Unit = {
//1.创建环境
val evn: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
evn.setParallelism(2)//设置当时参与执行并行的线程 如果没有就是全部线程都参与
//2.加载数据源吗
// val stream: DataStream[Any] = evn.fromElements(1, 2, 3, 4, 5, "hello", 3.14)
//
// //4.输出 sink
// stream.print()
//
// evn.execute("test")
//
/*val dataList = List(
SensorReading("sensor_1", 1691682857, 35.8),
SensorReading("sensor_2", 1691682857, 36.8),
SensorReading("sensor_3", 1691682857, 33.8),
SensorReading("sensor_4", 1691682857, 32.8)
)
val stream: DataStream[SensorReading] = evn.fromCollection(dataList)*/
//加载本地目录
// val stream = evn.readTextFile("D:\\IdeaProjects\\flinkstu1\\resources\\sensor.txt")
//加载地址端口数据
// val stream: DataStream[String] = evn.socketTextStream("192.168.153.141", 7777)
//4.输出 sink
//通过kafka
/* val prop = new Properties()
prop.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.153.141:9092")
prop.setProperty(ConsumerConfig.GROUP_ID_CONFIG,"sensorGroup1")
prop.setProperty(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization"+
".StringDeserializer")
prop.setProperty(ConsumerConfig.VALUE_DESERIALIZER_CLASS_DOC, "org.apache.kafka.common.serialization" +
".StringDeserializer")
prop.setProperty(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG,"latest")
val stream: DataStream[String] = evn.addSource(new FlinkKafkaConsumer[String]("sensor", new SimpleStringSchema(), prop))
//创建kafka生产者 生产消息
//kafka-topics.sh --zookeeper 192.168.153.141:2181 --create --topic sensor --partitions 1 --replication-factor 1
//kafka-console-producer.sh --topic sensor --broker-list 192.168.153.141:9092
*/
//自定义数据源
val stream = evn.addSource(new MySensorSource)
stream.print()
evn.execute("test")
}
}
class MySensorSource extends SourceFunction[SensorReading]{
override def run(ctx: SourceFunction.SourceContext[SensorReading]): Unit = {
val random = new Random()
while (true){
val i: Int = random.nextInt()
ctx.collect(SensorReading("随机数:"+i,System.currentTimeMillis(),1))
Thread.sleep(100)
}
}
override def cancel(): Unit = {
}
}
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









