






一、Azkaban安装
三个压缩包放在/opt/install目录下

tar -zxf ./azkaban-db-3.84.4.tar.gz 将该压缩包解压到当前目录

目录下sql到mysql数据库中执行 
在数据库虚拟机上

vim ./my.cnf
调整参数
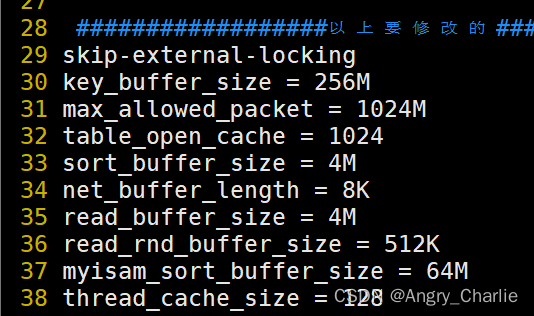
max_allowed_packet = 1024M
修改完成后重启mysql服务
回到/opt/install
加压剩余两个文件到soft
tar -zxf ./azkaban-exec-server-3.84.4.tar.gz -C ../soft/
tar -zxf ./azkaban-web-server-3.84.4.tar.gz -C ../soft/
cd /opt/soft/
更改目录名
mv azkaban-exec-server-0.1.0-SNAPSHOT/ azkaban-exec
mv azkaban-web-server-0.1.0-SNAPSHOT/ azkaban-web
配置azkaban-exec
cd /opt/soft/azkaban-exec/conf
配置azkaban.properties文件
vim ./azkaban.properties
7 default.timezone.id=Asia/Shanghai
21 azkaban.webserver.url=http://kb141:8081
//可以配置发送邮件
23 mail.sender=
24 mail.host=
42 database.type=mysql
43 mysql.port=3306
44 mysql.host=192.168.153.149
45 mysql.database=kb22azkaban
46 mysql.user=root
47 mysql.password=root
//在末尾行添加 给一个不被占用的端口
53 executor.port=12321
azkaban-exec启动命令
/opt/soft/azkaban-exec 执行目录
./bin/start-exec.sh 启动命令
./bin/shutdown-exec.sh关闭命令

select * from kb22azkaban.executors;此时active应该还是0
注!!!!第一次select并没有查询到数据发现是lib目录下jar包版本问题
从hive jar包中拷贝并删除原有的jar包 azkaban-web 打开web发现也有同样问题 执行同样操作更换jar包版本
cp /opt/soft/hive312/lib/mysql-connector-j-8.0.33.jar /opt/soft/azkaba
rm -rf ./mysql-connector-java-5.1.28.jar
注意!!出现错误调试时先把运行日志文件清空方便之后查看
cd /opt/soft/azkaban-exec/logs
rm -rf ./logs/*
未使用命令前active为0 使用后
cd /opt/soft/azkaban-exec/
curl -G "kb141:12321/executor?action=activate" && echo

配置azkaban-web
cd /opt/soft/azkaban-web/conf
vim ./azkaban-users.xml
<user password="123456" roles="admin" username="kb22"/>//加一行自己的用户信息

进入目录
cd /opt/soft/azkaban-exec/plugins/jobtypes
vim ./commonprivate.properties
添加一行内容
azkaban.native.lib=false
需要重启azkaban-exec服务
cd /opt/soft/azkaban-exec/logs 目录下查看日志文件报错等
vim ./azkaban-execserver.log
azkaban-web
打开WEB UI地址 :http://192.168.153.141:8081/
创建一个txt修改后缀project
每次打包都必须添加

内容
azkaban-flow-version: 2.0
创建一个.flow
调成Unix(LF)
语言选择YAML

创建one.flow(注意YAML格式是否正确)
nodes:
- name: jobOne
type: command
config:
command: echo “Hello World”


注意!!!!打包上传上传压缩包格式必须为.zip

左边进行定时执行设置 右边进行执行

使用该方法开启关闭Hadoop
jobB.sh
#!/bin/bash
echo "do jobB"
echo "azkaban shell sh , start hadoop server"
start-all.sh
hdfs dfsadmin -safemode leave
echo "over"
.flow文件
- name: jobB
type: command
config:
command: sh jobB.sh
出现错误重试间隔
nodes:
- name: joberror
type: command
config:
command: sh job.sh
retries: 3 //执行重复3次
retry.backoff: 5000 //每隔五秒
前一个任务的输出不满足第二个任务的执行前提
//flow
nodes:
- name: jobA
type: command
config:
command: sh jobA.sh
- name: jobB
type: command
dependsOn:
- jobA
config:
command: sh jobB.sh
condition: ${jobA:wk} == 3
jobA
#!/bin/bash
echo "do jobA.sh"
wk=`date +%w`
echo "{\"wk\":$wk}" > JOB_OUTPUT_PROP_FILE
//{"wk":3} 输出的json字符串
//相当于把这个字符串输入到一个容器里然后下一个任务再在这个容器中读取
jobB
#!/bin/bash
echo "do jobB"
stop-all.sh
echo "jobB over"
(1)all_success: 表示父 Job 全部成功才执行(默认)
(2)all_done:表示父 Job 全部完成才执行
(3)all_failed:表示父 Job 全部失败才执行
(4)one_success:表示父 Job 至少一个成功才执行
(5)one_failed:表示父 Job 至少一个失败才执行
nodes:
- name: jobA
type: command
config:
command: sh jobA.sh
- name: jobB
type: command
config:
command: sh jobB.sh
- name: jobC
type: command
dependsOn:
- jobA
- jobB
config:
command: sh jobC.sh
condition: all_success
使用该方法进行hbase的操作
flow
nodes:
- name: jobhbase
type: command
config:
command: hbase shell hbasedemo.sh
hbasedemo.sh
#!/bin/bash
create_namespace 'kb22azkaban'
create 'kb22azkaban:tb1','family'
list_namespace
list_namespace_tables 'kb22azkaban'
exit















 1363
1363











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









