







1、inline 函数说明:

翻译:将结构数组分解为多行。返回一个包含N列的行集(N=结构中顶级元素的数目),数组中每个结构一行。
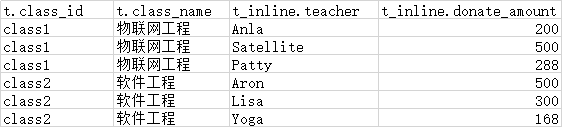
场景:源表粒度为 班级,目标表粒度为 班级+老师。

with t as (
select 'class1' as class_id, '物联网工程' as class_name,'Anla' as chinese_teacher,200 as chinese_teacher_donate_amount
,'Satellite' as math_teacher,500 as math_teacher_donate_amount,'Patty' as english_teacher,288 as english_teacher_donate_amount
union all
select 'class2' as class_id, '软件工程' as class_name,'Aron' as chinese_teacher,500 as chinese_teacher_donate_amount
,'Lisa' as math_teacher,300 as math_teacher_donate_amount,'Yoga' as english_teacher,168 as english_teacher_donate_amount
)
select
t.class_id
,t.class_name
,t_inline.teacher
,t_inline.donate_amount
from t
lateral view inline(array(struct(chinese_teacher,chinese_teacher_donate_amount),
struct(math_teacher,math_teacher_donate_amount),
struct(english_teacher,english_teacher_donate_amount)
)) t_inline as teacher,donate_amount;
2、动态分区如何实现:
set hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partition.mode=nonstrict;
set hive.exec.max.dynamic.partitions=100000; --可选
set hive.exec.max.dynamic.partitions.pernode=100000; --可选
insert overwrite table table_name partition(rand_num)
select field1,...,fieldn,cast(cast(rand() * 10 as int) as string) as rand_num
from t
这样就实现动态分区了。
注意:
1、distribute by解决的是小文件的问题,而不是实现动态分区,这点很容易混淆。
2、如果分区数超过限定值,会报错:Fatal error occured when node tried to create too many dynamic partitions.
报错则考虑是否设置参数: hive.exec.max.dynamic.partitions、hive.exec.max.dynamic.partitions.pernode
3、小文件如何处理:
3.1、distribute by
insert overwrite table table_name partition(statdate)
distribute by cast(rand() * 10 as int);
这种方法会在分区文件夹statdate=‘xxxx’ 下生成至多10个文件夹。
3.2、repartition,常使用在给一个分区插入数据上
select /*+ repartition(1) */
4、杂记
4.1、sqoop导出新经验:指定分区导出,分区字段得是 string 类型,不然会报错。
4.2、查询字段小数位长度: length(substring_index(cast(field as string),'.',-1))
效果:1.614->3; 12.8292->4














 655
655











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









