







前言
博主来发文章了 再不发这个月笔记数要做0了><
今天的内容比较少~之前的笔记等我五一补上@_@
数组
一、 一维数组
数组的存储和访问
- 基本语法
T A[L];- 元素数据类型为T ,长度为L
- 内存中连续分配 L * sizeof(T) 个字节
内存都是连续存储的 如图
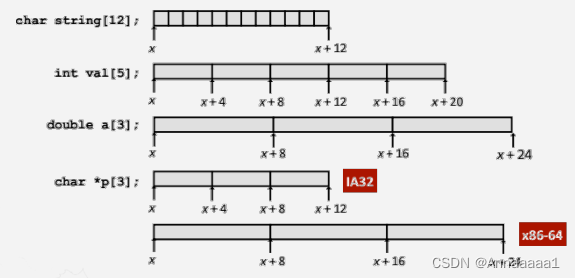
基本的编址单元是字节,一个指针变量与处理器(32位还是64位)有关,与数据类型无关
下面是例子
typedef就是给数据类型起个别名 这里 zip_dig就是int的别名


对应的内存分配如图 方格下面对应的是地址 地址的差值与数据类型有关
数组的访问
- 基本语法
T A[L]; - A可以被看做是第0个元素的指针,类型为 T *
如图 指针的内容是地址 地址之间的差值取决于数据类型
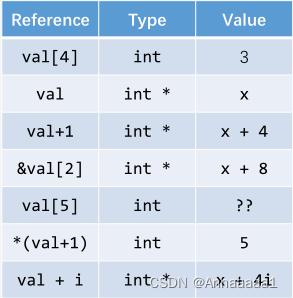
其中数据类型判断要在内存中取几个字节的数据(也就是步长是多少),x代表起始地址
下面是例子
这是c代码 实现了数组的访问

下面是他的汇编代码

注意 最后一行才是真正的代码
这行代码实现了将目标数据地址存储在了32位的%eax存储器里(也是32位中的目标存储器)
目标数据存储器为 %rdi + 4%rsi
其中4为步长
%rdi存储了起始地址
%rsi存储了数组索引
数组的循环遍历
原理就是上面的组合
我们直接上图
黄色的是实现数组循环的c代码


绿色的是汇编代码
在L4循环中第一行实现了数组元素加1
(%rdi,%rax,4)表示一个数组元素
其中%rdi为首地址 %rax表示数组索引
L4循环的第二行实现了索引的加1
L3循环的第一行实现了索引与4的比较 以确保索引符合循环条件
L3循环的第二行实现了跳转(符合条件时进入循环)
rep为空操作指令 确保跳转指令不相连
二、多维数组(嵌套)
1.数组的分配
-
基本语法
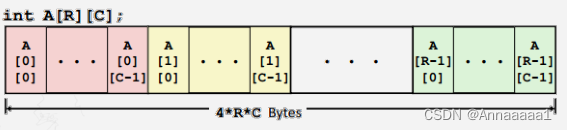
T A[R][C];- R 行,C 列
- T类型的元素需要 K 个字节
-
数组大小:R * C * K bytes
-
排列方式:行优先(就是一行的数据是连在一起的,故循环先写行的代码速度更快^^)
-
数据分配的形象表示如图
下面是例子


不同颜色表示不同行
2.访问嵌套数组的行
- A[i]是一个包含C个元素的数组
- 元素类型为T,需要K个字节
- 起始地址为 A + i*(C*K)
(首地址+(每行个数(列数) * 步长 *行数索引))
下面是例子
黄色为实现访问嵌套数组的行的c代码
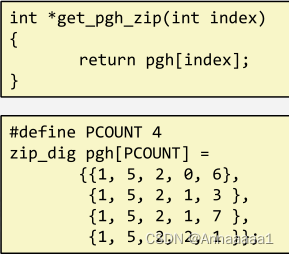
汇编代码如下
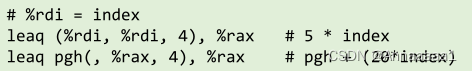
访问实现:pgh(起始地址) + (20*index)(索引乘以步长乘以列数)
- question:直接乘以五的话调用乘法 乘以4的话调用移位 两个的调用速度不同
故优先实现如下计算
pgh + 4*(index + 4*index)
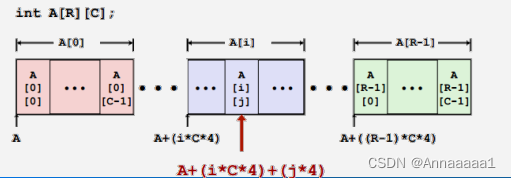
3.嵌套数组元素的访问
- A[i][j]数据类型为 T 的数组元素,需要 K 个字节
- 地址:A + i(CK) + jK = A + (i*C + j)*K
- 也就是首地址先索引到目标行(如上条) 再右移到目标列
下面是形象的示例
下面是例子
黄色是实现了嵌套数组元素访问的C代码


这是汇编代码 第一二行实现了
行数索引列数(每行元素个数)+列数索引
第三行实现了首地址 加 步长 * (行数索引列数(每行元素个数)+列数索引)
地址计算方法如下: pgh + 4*((index+4*index)+dig)
三、多层数组
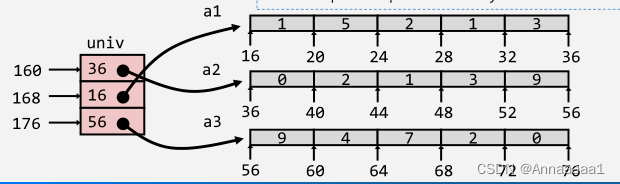
1.多层数组的存储
- 每个元素是一个指针:8字节
- 每个指针指向一个int型数组

如图二 左边表示了指针元素的地址 右边表示了其表示的数组的地址和存储的元素
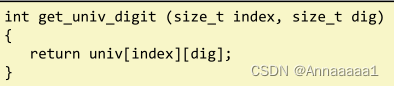
2.多层数组的元素访问
- Mem[Mem[univ+8index]+4digit]
- 需要进行两次存储器访问
- 首先获得行数组的地址
- 然后访问(行)数组中的元素

- 多维数组和多层数组的比较: 从C语法上看相似,但是寻址方式不同(因为存储方式不同)
四、数组长度
1.固定维度
- 在编译时N的大小已经确定
-

所以这里直接使用立即数寻址就可以了
2.可变维度,显示索引
传统的实现动态数组的方法
下面是n*n矩阵的示例


这里必须使用乘法 因为索引不固定
3.优化定长矩阵的访问

在汇编代码中 我们避免直接访问单个元素的地址 而是采用了每次增加 4N
这是初始地址 ajp = a + 4j
ajp += 4*N
结构体
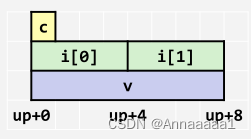
一、结构体的存储
- 结构体被看做是一块连续的内存区域
- 成员在内存中组织的顺序和声明的顺序一致
- 编译器决定了结构体的大小和每个成员在内存中的位置

下面是rec结构体的存储示意图
二、获得结构体的指针
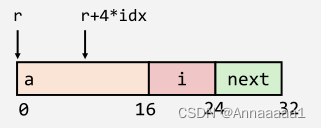
- 计算数组成员的指针 r->a[idx](黄色图)
- 每个结构体成员的偏移量在编译期决定
- 汇编代码(绿色图)计算的结果为r + 4*idx


三、链表遍历
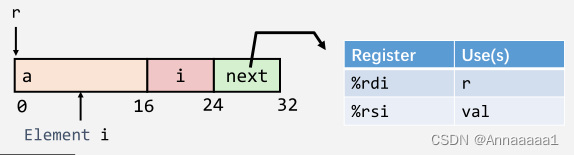
函数代码如图
其实就是循环,给数组中的每个元素赋值val 大家看看就行


主要是在存储的时候会按下图存储(结构体类型的话是 8个字节)前面是数组int类型元素 后面是两个结构体元素
汇编指令用的跳转

四、结构体对齐(重点)
1.结构体对齐举例
这是一个结构体

-
数据未对齐时如图

-
数据对齐规则
- 若基本数据类型需要K个字节 则地址必须是K的整数倍(即首地址 + K * i ,i为整数)
如图
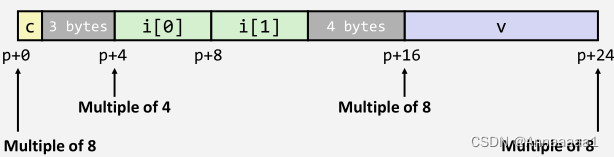
- 若基本数据类型需要K个字节 则地址必须是K的整数倍(即首地址 + K * i ,i为整数)
第一块黄色是char类型 只需要一个字节
第一个灰色部分是补充的字节 为了使地址满足int类型(4个字节)的要求(使 地址 = p + 4*1)
绿色部分是int类型的数据 数组含两个元素 故占8个字节
第二个灰色部分继续补充 使得地址满足double类型(8个字节)的要求
2.使用结构体对齐的原因
主要是物理原因
- 物理上,内存是以连续4或8字节
块的方式进行访问(依赖于系统) - 如果数据跨过四字的边界,数据
的访问效率低 - 当数据横跨2个内存页,虚拟内
存在处理上十分复杂
3.结构体对齐规则
- 结构体内每个成员都需要对齐
- K 为结构体中所有元素中的最大对齐需求(就是所有类型中需要的最大的字节数)
- 结构体的初始地址和大小必须为K的整数倍
下面是例子
- 例子1:

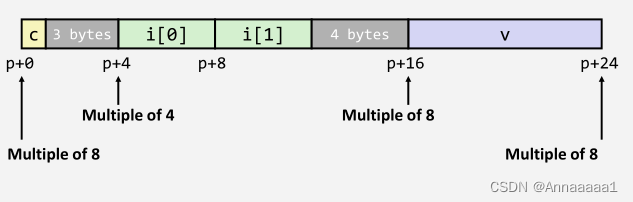
这里跟上面给过的例子相似,可以自己分析一下~ - 例子2

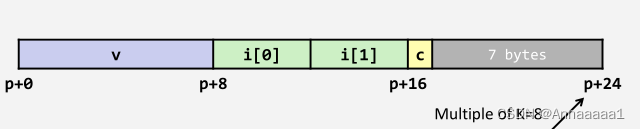
这里地址都是满足的,灰色部分的作用是补齐总字节数 使其满足最大对齐要求(8个字节的倍数)
所以这里的总字节数为24
4.具体对齐案例(32位)
- 1字节:char
- 2字节:short
- 地址的最低位必须为0 (二进制数)
- 4字节::int, float, long, char *, …
- 地址的最低2位必须为00 (二进制数)
- 8字节:double
- 地址的最低3位必须为000(二进制数)
5.访问结构体数组中的元素
- 计算结构体元素的偏移量
- 本例中成员 j 在结构体中的偏移量(相对于首地址)为8
先移到结构体的数组元素,再在该结构体中根据对齐规则进行移动
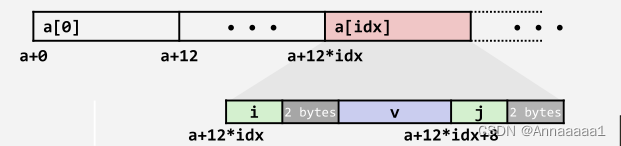


下面是汇编代码

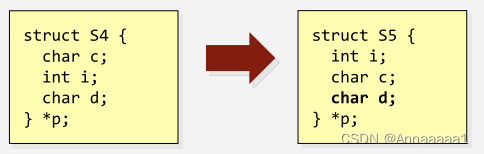
小技巧
为了节省空间 我们通常把尺寸大的成员放在结构体的前面 如图
联合体
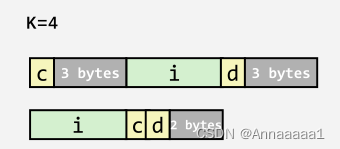
一、联合体的空间分配
联合体大家应该知道 就是各种类型的成员共享一个空间
如图

- 基于最大的成员分配空间
- 一次只能使用其中的一个成员
二、字节序
-
大端
- 最高字节在最低地址
如图
如图 从右往左为从高地址到低地址 f0是小 f3是大
- 最高字节在最低地址
-
小端
- 最低字节在最低地址
如图 从右往左为从低地址到高地址 f0是小 f3是大

- 最低字节在最低地址
-
双端(ARM)
- 可以通过某种方式进行配置
一个小问题^^
联合体中

-
与 (float) u 相同吗?
-

-
与(unsigned) f 相同吗?
这个问题的解答等我二编的时候放上来吧^^
PS:作者最近有点忙 之前写了一篇浮点数的草稿还没发,等我五一冲刺一下@_@















 1240
1240











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









