







机器学习之朴素贝叶斯
一、朴素贝叶斯
朴素贝叶斯(Naive Bayes)是一种基于概率理论的分类算法,以贝叶斯理论为理论基础,通过计算样本归属于不同类别的概率来进行分类,是一种经典的分类算法。朴素贝叶斯是贝叶斯分类器里的一种方法,之所以称它朴素,原因在于它采用了特征条件全部独立的假设
二、贝叶斯决策理论
朴素贝叶斯
优点:在数据较少的情况下仍然有效,可以处理多类别问题。
缺点:对于输入数据的准备方式较为敏感。
适用数据类型:标称型数据。
朴素贝叶斯是贝叶斯决策理论的一部分,所以讲述朴素贝叶斯之前有必要快速了解一下贝叶斯决策理论。
假设现在有一个数据集,它由两类数据组成(红色和蓝色),数据分布如下图所示
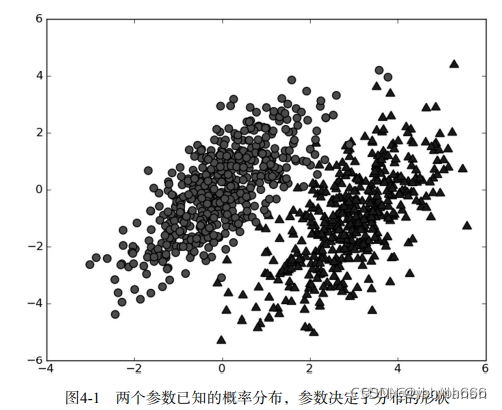
现在用p 1 ( x , y ) p1(x,y)p1(x,y)表示数据点( x , y ) (x,y)(x,y)属于类别1(图中圆点表示的类别)的概率,用p 2 ( x , y ) p2(x,y)p2(x,y)表示数据点( x , y ) (x,y)(x,y)属于类别2(图中三角形表示的类别)的概率,那么对于一个新的数据的( x , y ) (x,y)(x,y),可以用下面的规则来判断它的类别:
如果p 1 ( x , y ) > p 2 ( x , y ) p1(x,y) > p2(x,y)p1(x,y)>p2(x,y),那么类别为1
如果p 1 ( x , y ) < p 2 ( x , y ) p1(x,y) < p2(x,y)p1(x,y)<p2(x,y),那么类别为2
也就是说,会 选择高概率所对应的类别。这就是贝叶斯决策理论的核心思想,即选择具有最高概率的决策
三、相应的数学知识
1、贝叶斯准则
贝叶斯准则告诉我们如何交换条件概率中的条件与结果,即如果已知P(x|c),要求P(c|x),那么可以使用下面的计算方法
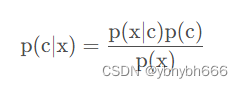
2、全概率公式
除了条件概率以外,在计算p 1 p1p1和p 2 p2p2的时候,还要用到全概率公式
设事件A1,A2,A3…An两两互斥,又事件B满足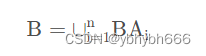
全概率公式可以写为
3、贝叶斯推断
对条件概率公式进行变形,可以得到如下形式:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-CGyupzH0-1660187309782)(C:\Users\HP\AppData\Roaming\Typora\typora-user-images\1660186658286.png)]
P(A)称为"先验概率"(Prior probability),即在B事件发生之前,对A事件概率的一个判断。
P(A|B)称为"后验概率"(Posterior probability),即在B事件发生之后,对A事件概率的重新评估
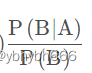
称为"可能性函数"(Likelyhood),这是一个调整因子,使得预估概率更接近真实概率
所以,条件概率可以理解成下面的式子:后验概率 = 先验概率 x 调整因子
四、使用条件概率来分类
贝叶斯决策理论要求计算两个概率 p1(x,y)和p2(x,y)
如果p1(x,y)>p2(x,y),那么类别为1
如果p1(x,y)<p2(x,y),那么类别为2
具体地,应用贝叶斯准则得到:

这些符号所代表的具体意义是:给定某个由x、y表示的数据点,那么该数据点来自类别c1和来自类别c2的概率是多少?
使用贝叶斯准则,可以通过已知的三个概率值来计算未知的概率值
五、文本分类举例
要从文本中获取特征,需要先拆分文本。这里的特征是来自文本的词条(token),一个词条是字符的任意组合。可以把词条想象为单词,也可以使用非单词词条,如URL、IP地址或者任意其他字符串。然后将每一个文本片段表示为一个词条向量,其中值为1表示词条出现在文档中,0表示词条未出现。
以在线社区的留言板为例。为了不影响社区的发展,我们要屏蔽侮辱性的言论,所以要构建一个快速过滤器,如果某条留言使用了负面或者侮辱性的语言,那么就将该留言标识为内容不当。过滤这类内容是一个很常见的需求。对此问题建立两个类别:侮辱类和非侮辱类,使用1和0分别表示
1、构建词向量
把文本看成 单词向量 或者 词条向量,也就是说将句子转换为向量。考虑出现在所有文档中的所有单词,再决定将哪些词纳入词汇表或者说所要的词汇集合,然后必须要将每一篇文档转换为词汇表上的向量。简单起见,先假设已经将本文切分完毕,存放到列表中,并对词汇向量进行分类标注
def loadDataSet():
postingList=[['my', 'do 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









