






一、概述:
朴素贝叶斯(Naive Bayes)是一种基于贝叶斯定理与特征条件独立假设的分类方法。它之所以被称为“朴素”,是因为它假设了输入特征之间的条件独立性,即一个特征的出现概率与其他特征无关。尽管这个假设在现实中很少成立,但朴素贝叶斯分类器在许多实际应用中仍然表现出了出色的性能。
1.1贝叶斯公式:
通常,事件A在事件B(发生)的条件下的概率,与事件B在事件A的条件下的概率是不一样的;然而,这两者是有确定的关系,贝叶斯法则就是这种关系的陈述。
贝叶斯法则是关于随机事件A和B的条件概率和边缘概率的:


其中P(A|B)是在B发生的情况下A发生的可能性。
在这里先讲两个概念:
先验概率(prior probability):是指根据以往经验和分析得到的概率。
后验概率(posterior probability):是指在得到“结果”的信息后重新修正的概率。
二、朴素贝叶斯定理:
给定一个类别  和一个从
和一个从  到
到  的相关的特征向量, 贝叶斯定理阐述了以下关系:
的相关的特征向量, 贝叶斯定理阐述了以下关系:
![]()
假设它们之间都是相互独立的:
![]()
对所有的i都成立,所以简化其公式:
![]()
在给定输入中![]() 是一个常量,所以 我们可以使用以下分类规则:
是一个常量,所以 我们可以使用以下分类规则:
我们可以使用最大后验概率(Maximum A Posteriori, MAP) 来估计 和 ; 前者是训练集中类别 的相对频率。
公式比较复杂,下面举一个具体的例子来具象化朴素贝叶斯算法:
小明是一个大学生,老师布置了一道作业给小明,小明觉得很难,小明打算向班里的三十位同学求助,同学们纷纷给小明回复了答案,小明发现这三十份回复里面既有作业答案,又有情书告白。
其中小明可以清晰分辨有16份答案以及13份情书,唯独班长的回答小明看的不是很懂,于是小明想可不可以按照消息中出现的关键词来给班长的消息进行分类。
小明根据收到的消息计算任何一则消息是作业还是情书的概率,然后从所有的消息中选中四个关键次作为分类依据:

然后分别计算出这四个词在作业与在情书中出现的概率:


假设班长的消息中出现红豆与喜欢两个关键词,分别计算它们在作业中出现的概率以及在情书中出现的概率,得出结果:

由于这个算法认为两个关键词是相互独立的,它们出现顺序并不能影响计算结果,由于这样简单粗暴,所以就叫做朴素贝叶斯算法,这就是朴素贝叶斯。
2.1拉普拉斯平滑:
拉普拉斯平滑(Laplace Smoothing)是一种常用的统计平滑技术,主要用于处理概率计算中的零概率问题。
拉普拉斯平滑,又称为加1平滑,是朴素贝叶斯分类器中一种常用的平滑方法。它通过为每个特征的计算增加一个正数值来避免出现概率为0的情况,从而提高了分类器的准确性和可靠性。
在计算事件的概率时,如果某个事件在观察样本库(训练集)中没有出现过,会导致该事件的概率结果是0。这是不合理的,因为不能因为一个事件没有观察到,就被认为该事件一定不可能发生。拉普拉斯平滑正是为了解决这种零概率问题而提出的。
朴素贝叶斯算法存在的另外一个问题:
假设有一则消息是这样的,通过计算可以得出,这则消息是作业的可能性为0.000177,而为情书的概率为零,这是由于辛苦这一关键词在情书之中没有出现过,所以在统计计算的时候情书中辛苦的概率为零,这是不对的,因为一个事物没有被观察到,并不代表着不会发生。

所以我们运用拉普拉斯平滑技巧,将关键词都加一,使得情书中辛苦的关键词不为零:
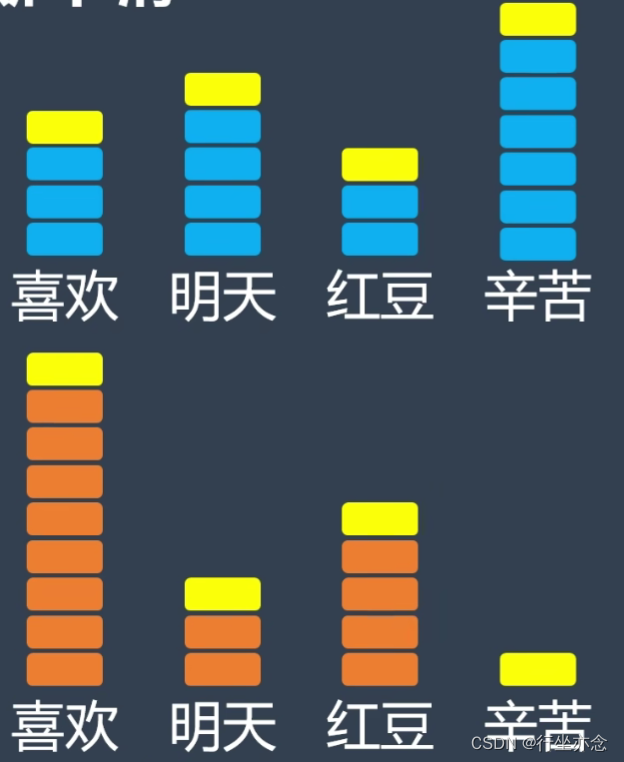
从而计算出正确的结果:

2.2朴素贝叶斯处理垃圾邮件:
如何判断一封邮件是否是垃圾邮件?也就是说我们需要求出 P(垃圾邮件|邮件内容),很显然这个概率明显不好求. 我们使用贝叶斯公式:
P(垃圾邮件|邮件内容) = P(垃圾邮件和邮件内容) / P(邮件内容) = P(邮件内容|垃圾邮件) * P(垃圾邮件) / P(邮件内容)
其中最后的 P(邮件内容) 对结果并没有影响,因为P(正常邮件|邮件内容)的分母也有此项,可以认为是一个常数,也就是说 P(垃圾邮件|邮件内容) 正相关于 P(邮件内容|垃圾邮件) * P(垃圾邮件)
所以现在我们将判断一封邮件是否是垃圾邮件这个问题的概率转化为 P(垃圾邮件) * P(邮件内容|垃圾邮件),那么怎么求求这两个的概率呢?
P(垃圾邮件)
这一部分的概率为先验概率,比如P(硬币正面朝上)=0.5,可以认为是根据大数定律,频率趋近于概率,也就是说我们找足够多的数据样本(10万封邮件或者更多),那么其中垃圾邮件出现的频率(6万次)就可以认为是P(垃圾邮件) = 6/10 = 0.6,这一部分的概率是根据一个巨大先验集(训练集)来确定的。
P(邮件内容|垃圾邮件)
另一部分就是垃圾邮件中邮件内容出现的概率了,显然不可能完整的计算整封邮件内容,考虑到一封邮件是由词 ABCD... 组成,这个概率可以被拆开,
正常情况下一封邮件的每一个词之间都是有前后文关联的,"我喜欢打篮球"和"喜欢打蓝我球"显然是不同的语义,这个概率应该被写作
P(邮件内容|垃圾邮件) = P(A|垃圾邮件) * P(B|A,垃圾邮件) * P(C|B,A,垃圾邮件) ....
也就是说每一个词出现的概率都需要计算前面的词已经出现的过的概率,这个计算量是巨大的.朴素贝叶斯的思想就是体现在这里,假设每个特征之间是相互独立的. "我喜欢打篮球"和"喜欢打蓝我球",只要是这五个字的排列组合我都认为是同一种情况没有区别,这大大减少了计算量
P(邮件内容|垃圾邮件) = P(A|垃圾邮件) * P(B|垃圾邮件) * P(C|垃圾邮件) ...
也就是我们只需要统计出先验集(训练集)的垃圾邮件中邮件内容的每个词出现的概率就可以了,这时会产生一个问题,如果这个词没有出现过那该怎么做呢?
对于一个从未见过的词,在训练集中没有对应的概率值, P(X|垃圾邮件) = 0 ? ,这显然是不合适的,因为我们计算概率 P(邮件内容|垃圾邮件)的时候需要把每个词的概率相乘.某一项为0显然是我们不希望看到的结果.
而这个错误的造成是由于训练量不足,会令分类器质量大大降低。为了解决这个问题,我们引入 拉普拉斯平滑,就可以完美解决以上问题了。
举个例子: 如果垃圾邮件中有 2个"售",3个"买",...,现在的词是"购",在原数据集中并没有出现,那么对于垃圾邮件中每个词数量加一,变为3个"售",4个"买",1个"购"....,这样每个类都加了一个当数据集足够大时基本没什么影响.
2.3伯努利与多项式朴素贝叶斯:
在查阅一些资料的时候总会看到伯努利朴素贝叶斯与多项式朴素贝叶斯这样的细分,它们是两种基于朴素贝叶斯算法的变体,它们各自在处理分类问题时具有不同的特点和适用场景。

(1)伯努利朴素贝叶斯
伯努利朴素贝叶斯适用于非0即1的情况,例如文本分类中,每个特征可能表示一个单词是否出现在文档中。它假设每个特征在给定类别下是二项分布的(即伯努利分布),这意味着特征只有两种可能的结果(例如,出现或未出现)。
示例:
假设我们有一个简单的垃圾邮件分类任务,邮件的内容由一些单词(特征)组成,我们关心这些单词是否出现在邮件中(用0表示未出现,1表示出现)。
| 邮件ID | 单词A | 单词B | 单词C | 类别(是否为垃圾邮件) |
|---|---|---|---|---|
| 1 | 1 | 0 | 1 | 是 |
| 2 | 0 | 1 | 0 | 否 |
| 3 | 1 | 1 | 0 | 是 |
| ... | ... | ... | ... | ... |
我们做以下应用:
- 计算每个单词在每个类别下的概率(出现和未出现)。
- 对于新邮件,计算其属于每个类别的概率,选择概率最大的类别作为预测结果。
(2)多项式朴素贝叶斯
多项式朴素贝叶斯则适用于特征值为非负整数的情况,例如文本分类中,每个特征可能表示一个单词在文档中出现的次数。它假设每个特征在给定类别下是多项式分布的,这意味着特征可以有多个不同的取值(例如,单词在文档中出现的次数)。
同样假设我们有一个文本分类任务,但是这次我们关心的是单词在文本中出现的次数。
| 文档ID | 单词A的计数 | 单词B的计数 | 单词C的计数 | 类别(例如:体育、科技) |
|---|---|---|---|---|
| 1 | 3 | 0 | 1 | 体育 |
| 2 | 0 | 4 | 0 | 科技 |
| 3 | 2 | 1 | 0 | 体育 |
| ... | ... | ... | ... | ... |
我们做以下应用:
- 计算每个单词在每个类别下的频率(即单词在文档中出现的次数除以文档的总词数)。
- 对于新文档,计算其属于每个类别的概率(使用多项式分布),选择概率最大的类别作为预测结果。
总结:
朴素贝叶斯分类在实际应用中具有一定的参考价值,它的算法逻辑简单,易于实现,分类过程中对时间空间的开销也较小。理论上,朴素贝叶斯模型与其他分类方法相比具有最小的误差率。但是实际上并非总是如此,这是因为朴素贝叶斯模型假设属性之间相互独立,这个假设在实际应用中往往是不成立的,在属性个数比较多或者属性之间相关性较大时,分类效果不好。
(以上为学习资料,侵删。)















 13万+
13万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









