






Spark SQL 结构化数据
1、SparkSQL 简介
Spark SQL是Spark用来处理结构化数据的一个模块,它提供了一个编程抽象结构叫做DataFrame的数据模型(即带有Schema信息的RDD),Spark SQL作为分布式SQL查询引擎,让用户可以通过SQL、DataFrames API和Datasets API三种方式实现对结构化数据的处理。
Spark SQL的三个功能:
(1)Spark SQL可从各种结构化数据源中读取数据,进行数据分析。
(2)Spark SQL包含行业标准的JDBC和ODBC连接方式,因此它不局限于在Spark程序内使用SQL语句进行查询。
(3)Spark SQL可以无缝地将SQL查询与Spark程序进行结合,它能够将结构化数据作为Spark中的分布式数据集(RDD)进行查询。
2、Spark SQL 架构
Spark SQL架构与Hive架构相比,把底层的MapReduce执行引擎更改为Spark,还修改了Catalyst优化器,Spark SQL快速的计算效率得益于Catalyst优化器。从HiveQL被解析成语法抽象树起,执行计划生成和优化的工作全部交给Spark SQL的Catalyst优化器进行负责和管理。
1、SparkSQL 简介
Spark SQL是Spark用来处理结构化数据的一个模块,它提供了一个编程抽象结构叫做DataFrame的数据模型(即带有Schema信息的RDD),Spark SQL作为分布式SQL查询引擎,让用户可以通过SQL、DataFrames API和Datasets API三种方式实现对结构化数据的处理。
Spark SQL的三个功能:
(1)Spark SQL可从各种结构化数据源中读取数据,进行数据分析。
(2)Spark SQL包含行业标准的JDBC和ODBC连接方式,因此它不局限于在Spark程序内使用SQL语句进行查询。
(3)Spark SQL可以无缝地将SQL查询与Spark程序进行结合,它能够将结构化数据作为Spark中的分布式数据集(RDD)进行查询。
2、Spark SQL 架构Spark SQL架构与Hive架构相比,把底层的MapReduce执行引擎更改为Spark,还修改了Catalyst优化器,Spark SQL快速的计算效率得益于Catalyst优化器。从HiveQL被解析成语法抽象树起,执行计划生成和优化的工作全部交给Spark SQL的Catalyst优化器进行负责和管理。

Spark要想很好地支持SQL,需要完成解析(Parser)、优化(Optimizer)、执行(Execution)三大过程。

3、Spark SQL工作流程:
(1)下载解析SQL语句之前,会创建SparkSession,涉及到表名、字段名称和字段类型的元数据都将保存在SessionCatalog中;
(2)当调用SparkSession的sql()方法时就会使用SparkSqlParser进行解析SQL语句,解析过程中使用的ANTLR进行词法解析和语法解析;
(3)使用Analyzer分析器绑定逻辑计划,在该阶段,Analyzer会使用Analyzer Rules,并结合SessionCatalog,对未绑定的逻辑计划进行解析,生成已绑定的逻辑计划;
(4)使用Optimizer优化器优化逻辑计划,该优化器同样定义了一套规则(Rules),利用这些规则对逻辑计划和语句进行迭代处理;
(5)使用SparkPlanner对优化后的逻辑计划进行转换,生成可以执行的物理计划SparkPlan;
(6)使用QueryExecution执行物理计划,此时则调用SparkPlan的execute()方法,返回RDDs。
4、DataFrame简介
Spark SQL使用的数据抽象并非是RDD,而是DataFrame。
在Spark 1.3.0版本之前,DataFrame被称为SchemaRDD。
DataFrame使Spark具备处理大规模结构化数据的能力。
在Spark中,DataFrame是一种以RDD为基础的分布式数据集。
DataFrame的结构类似传统数据库的二维表格,可以从很多数据源中创建,如结构化文件、外部数据库、Hive表等数据源。
DataFrame可以看作是分布式的Row对象的集合,在二维表数据集的每一列都带有名称和类型,这就是Schema元信息,这使得Spark框架可获取更多数据结构信息,从而对在DataFrame背后的数据源以及作用于DataFrame之上数据变换进行针对性的优化,最终达到提升计算效率。
DataFrame的创建
创建DataFrame的两种基本方式:
(1)已存在的RDD调用toDF()方法转换得到DataFrame。
(2)通过Spark读取数据源直接创建DataFrame。
1.数据准备
在HDFS文件系统中的/spark目录中有一个person.txt文件,内容如下:
1 zhangsan 20
2 lisi 29
3 wangwu 25
4 zhaoliu 30
5 tianqi 35
6 jerry 40
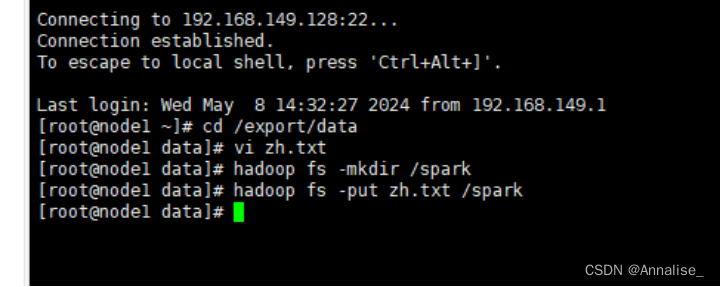
2.通过文件直接创建DataFrame

3.RDD直接转换为DataFrame

3.1 DataFrame的常用操作
DataFrame提供了两种语法风格,即DSL风格语法和SQL风格语法。二者在功能上并无区别,仅仅是根据用户习惯,自定义选择操作方式。
3.1.1 DSL风格操作DataFrame的常用方法,具体如下表如示

3.1.2 SQL风格操作DataFrame
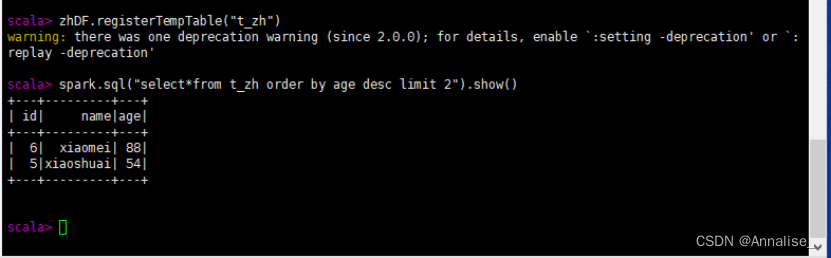
(1) 将DataFrame注册成一个临时表
scala > personDF.registerTempTable("t_person")
(2)查询年龄最大的前两名人的信息
(3)查询年龄大于25的人的信息

4、Dataset简介
Dataset是从Spark1.6 Alpha版本中引入的一个新的数据抽象结构,最终在Spark2.0版本被定义成Spark新特性。Dataset提供了
特定域对象中的强类型集合,也就是在RDD的每行数据中添加了类型约束条件,只有约束条件的数据类型才能正常运行。Dataset结合了RDD和DataFrame的优点,并且可以调用封装的方法以并
5、RDD、DataFrame及Dataset的区别
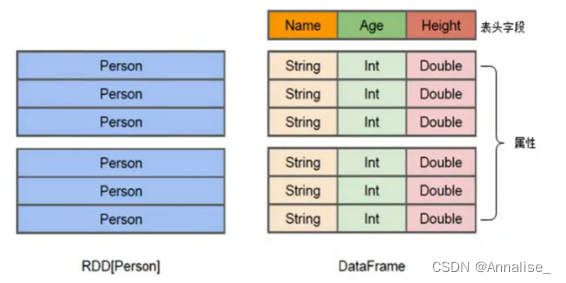
RDD数据的表现形式,即序号(1),此时RDD数据没有数据类型和元数据信息。
行方式进行转换等操作

DataFrame数据的表现形式,即序号(2),此时DataFrame数据中添加Schema元数据信息(列名和数据类型,如ID:String),DataFrame每行类型固定为Row类型,每列的值无法直接访问,只有通过解析才能获取各个字段的值

Dataset数据的表现形式,序号(3)和(4),其中序号(3)是在RDD每行数据的基础之上,添加一个数据类型(value:String)作为Schema元数据信息。而序号(4)每行数据添加People强数据类型,在Dataset[Person]中里存放了3个字段和属性,Dataset每行数据类型可自定义,一旦定义后,就具有错误检查机制

6、Dataset对象的创建
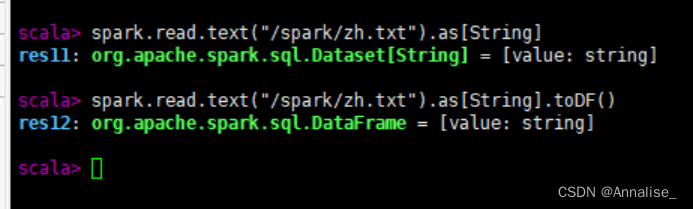
(1)通过SparkSession中的createDataset来创建Dataset

(2)DataFrame通过“as[ElementType]”方法转换得到Dataset
7、RDD转换DataFrame
Spark官方提供了两种方法实现从RDD转换得到DataFrame。
第一种方法是利用反射机制来推断包含特定类型对象的Schema,这种方式适用于对已知数据结构的RDD转换
第二种方法通过编程接口构造一个Schema,并将其应用在已知的RDD数据中。
8、Spark SQL操作MySQL
(1)读取MySQL数据库
(2)向MySQL数据库写入数据















 8018
8018











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









