







在大视觉语言模(Large Vision-Language Models, LVLMs)的应用中,幻觉问题,即生成内容与输入的视觉信息和指令不一致,备受关注。
近期,蚂蚁保联合浙江大学深入研究了视觉语言大模型幻觉产生的机制,提出了层级专家混合模型(Mixture of Layer Experts, MoLE)的幻觉问题解决方案。该技术已成功应用于智能理赔业务中,实现了“病历图像到理赔结论”的端到端审核,助力“安心赔”试点产品上线“秒赔”服务。
今天给大家介绍论文,详细探讨了其中的关键算法问题和解决方案。
论文标题
MoLE:Decoding by Mixture of Layer Experts Alleviates Hallucination in Large Vision-Language Models.
该论文已收录于AI顶会AAAI 2025,本届AAAI会议共收到12957份提交论文,其中3032篇论文被录用,接受率为23.4%。

LVLM 幻觉困境频现
LVLMs已成为解决视觉语言任务的主流范式,然而,幻觉问题的存在不仅损害了输出的准确性,还削弱了LVLMs在智能理赔等场景中的可靠性。
现有的幻觉缓解方法主要依赖对比解码技术,通过“业余模型”来过滤错误输出。通常,专家模型(即原始 LVLM)与较弱或更混乱的模型对比,以差异筛除幻觉。尽管此方法有所成效,但其局限在于对较弱模型的依赖,而这些模型未必总能提供准确指导。
认识到传统对比解码方法的局限性,蚂蚁保联合浙江大学深入研究了视觉语言大模型幻觉产生的机制,发现LVLMs的解码过程中,幻觉可能在推理和事实信息注入过程中产生,同时随着生成token数量的增加,对原始prompt的遗忘也可能导致幻觉的出现。
为此,研究团队从**混合专家模型(Mixture of Experts, MoE)**框架中汲取灵感,提出了一种无需训练的解码方法——层级专家混合模型(MoLE)。MoLE利用启发式门控机制动态选择LVLMs的多个层作为专家层,通过各专家的协同合作,增强了生成过程的鲁棒性和忠实性。实验结果表明,MoLE显著减少了幻觉现象,在三种主流LVLMs和两个已建立的幻觉基准测试中均优于当前最先进的解码技术,展示了LVLMs独立生成更可靠和准确输出的潜力。
MoLE 专家妙招破解
MoLE识别了三个关键专家:**最终专家层(Final Expert)**来自最后一层,负责优化最终输出;**第二意见专家层(Second Opinion Expert)**从最后几层中选取,提供可供参考的其他见解;**提示保持专家层(Prompt Retention Expert)**选择能最好保留原始输入的层,确保模型的输出保持遵循输入。
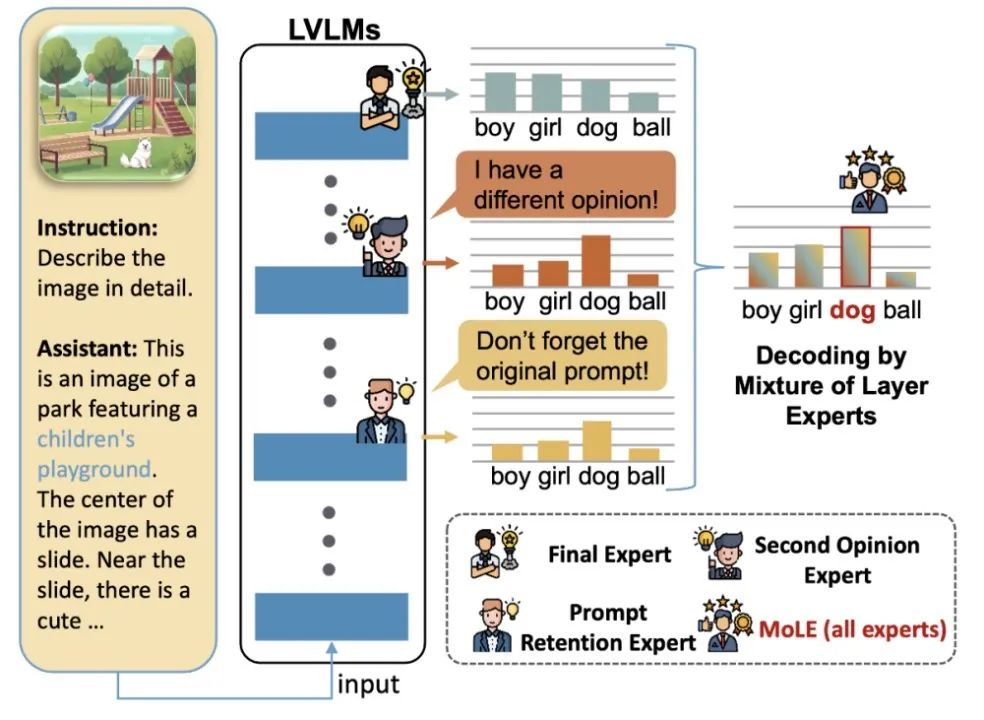
图1 MoLE解码算法示意图
MoLE生成答案的过程可分为四步:
第一步,选择最终专家层
通常选择最后一层作为最终专家层,以综合前面所有层的信息。
第二步,选择第二意见专家层
为提升解码准确性,引入一个视角不同的层。该层在关键 token 上与最终专家层存在分歧,但在其他 token 上保持一致。通过计算最终层与候选层 logits 差异,选出最优层。
第三步,选择提示保持专家层
生成过程中,模型可能削弱对原始提示的关注,导致幻觉。为此,选取对 prompt tokens 注意力分数最高的层作为提示保持专家层,以强化对提示的记忆。
第四步,层级专家混合解码
结合最终专家层、第二意见专家层和提示保持专家层的logits生成最终预测。不同于传统对比解码,MoLE直接累加专家logits,实现信息融合。
MoLE 通过单次前向传播协调多个专家层,最小化计算开销,同时减少幻觉。 此外,其启发式门控机制动态选择 LVLMs 的不同层作为专家层,增强生成的鲁棒性和忠实性。
为验证方法的普适性,实验采用三种先进的大视觉语言模型(LVLMs):MiniGPT-4、LLaVA-1.5和Shikra,均基于Vicuna-7B作为解码器。在这些模型上,对比所有基线方法与MoLE,以评估其在不同LVLMs体系中的稳健性。
实验结果表明,MoLE 在提升 LVLMs 输出准确性和减少幻觉方面达到SOTA水平。无论是在基于投票的对象探测评估(POPE)数据集,还是长文本生成任务的 CHAIR 评估中,MoLE 均显著优于其他解码策略。在所有测试模型和指标上,其稳健性得到充分验证。特别是在 MiniGPT-4 上,MoLE使CHAIR-S指标相比 DoLA下降 21%,进一步突显了MoLE在减少长文本生成任务中对象幻觉方面的有效性。
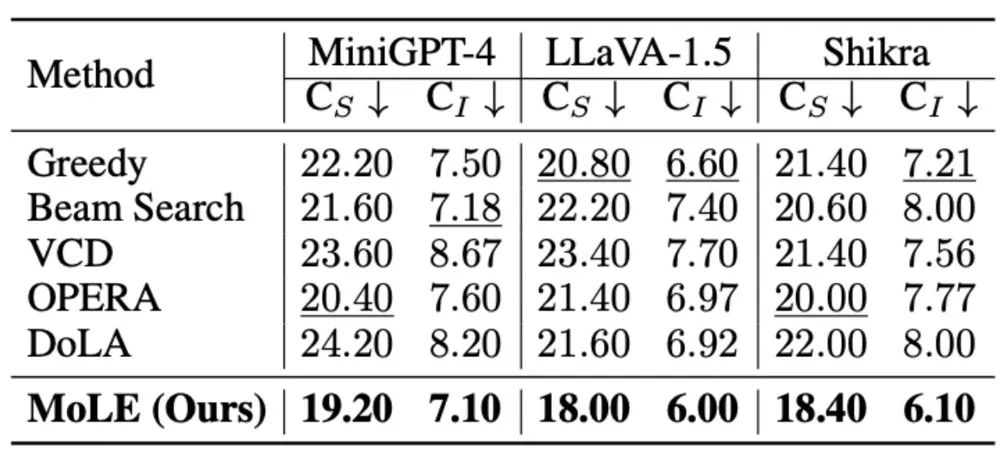
图2 CHAIR大模型幻觉评估结果
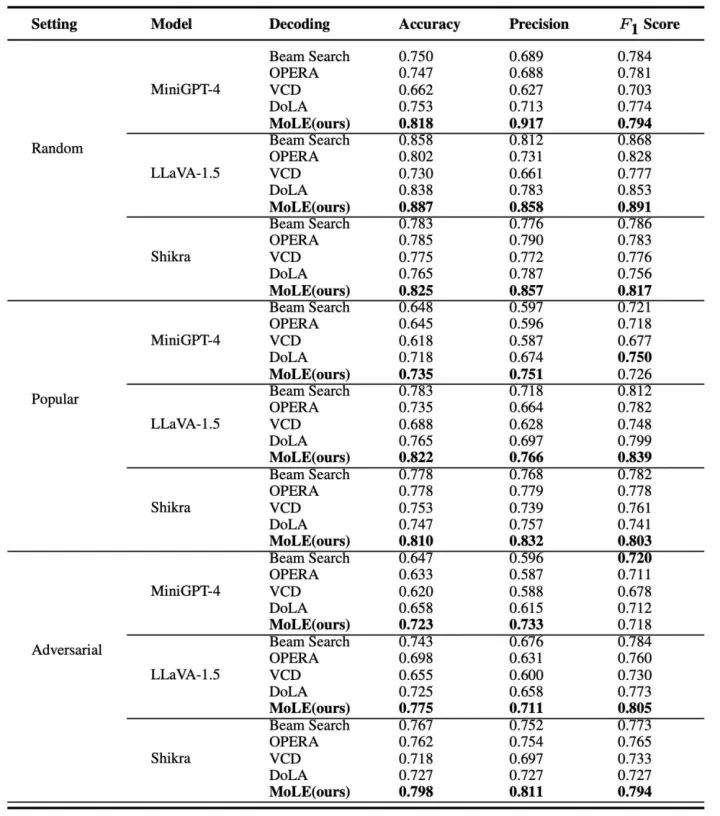
图3 POPE测试集结果
智能理赔进入多模态端到端时代
过去,智能理赔链路依赖ocr,信息提取,知识图谱,以及决策系统等复杂链路。基于视觉语言大模型实现“病历到理赔结论”的端到端理赔,可以显著降低长决策链路中的信息漏损和累积误差,是未来理赔智能化的发展方向。
然而,幻觉问题始终是视觉语言大模型应用的“痛点”:生成的理赔结论可能与实际病历或保单信息不符,导致误判和不准确的理赔结果。为了减少这些误判,提高审核的精度,蚂蚁保与浙江大学展开了深入的科研合作,提出了创新的解决方案——层级专家混合模型(MoLE),为解决视觉语言大模型中的幻觉问题提供了新的思路。
这一创新为智能理赔提供了端到端解决方案,帮助实现了安心赔试点产品的“秒赔”,推动了理赔服务标准化、智能化发展。未来,视觉语言大模型还将与智能体应用相结合,为用户打造更丰富,更智能的保险服务体验。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









