







 本文详细介绍了Ceph的分布式架构、特点,包括其可扩展性、高可用性、数据分布存储和一致性,以及各个组件如Mon、OSD、Mgr、CephFS和RGW的功能。此外,还探讨了存储资源划分,如存储池、PG和CRUSH映射,以及后端存储引擎BlueStore和FileStore的比较。
本文详细介绍了Ceph的分布式架构、特点,包括其可扩展性、高可用性、数据分布存储和一致性,以及各个组件如Mon、OSD、Mgr、CephFS和RGW的功能。此外,还探讨了存储资源划分,如存储池、PG和CRUSH映射,以及后端存储引擎BlueStore和FileStore的比较。
一、前言
Ceph 是一个完全分布式的系统,它将数据分布在整个集群中的多个节点上,以实现高可用性和容错性,ceph支持对象存储、块存储、文件存储所以被称为统一存储,ceph的架构由以下组件组成:mon、mgr、osd、mds、cephfs、rgw,以下就来详细的介绍ceph各个组件的功能和ceph集群的工作原理
二、特点
可扩展性:
Ceph 可以轻松地扩展到数千甚至数百万台服务器,并处理大规模的数据存储需求
它采用分布式架构,允许用户根据需要动态添加或移除存储节点,以满足不断增长的存储需求
高可用性:
Ceph 采用了数据冗余备份和自动修复机制,确保数据的可靠性和容错性
它支持多副本和纠删编码等技术,以防止数据丢失和数据损坏
数据分布式存储:
Ceph 将数据分布存储在集群中的多个节点上,并使用 CRUSH 算法确保数据的均衡分布和负载均衡
数据分布存储提高了系统的并发访问性能,同时降低了存储节点的压力和单点故障的风险
数据强一致性:
当客户端向 Ceph 写入数据时,Ceph 会等待所有副本都成功写入后才返回写入成功的响应。这确保了数据写入的原子性和一致性
如果任何一个副本写入失败,Ceph 会自动尝试重新写入数据,直到所有副本写入成功
统一存储接口:
Ceph 提供了统一的存储接口,包括对象存储(RADOS)、块存储(RBD)和文件系统(CephFS)等,使得用户可以使用相同的存储平台处理不同类型的数据和应用场景
二、组件介绍
Monitor(监视器):
监视器维护了集群的状态和拓扑信息
负责监控 OSD 的健康状态和群集的运行状况
提供了客户端和其他组件所需的集群元数据信息
在集群中动态添加或删除 OSD 时,负责维护和更新集群拓扑
Object Storage Daemon(OSD):
存储实际的数据对象,并提供数据访问的接口
负责数据的读取、写入、复制和恢复等操作
使用 CRUSH 算法确定数据的存储位置,并实现数据的均衡分布
具有自我修复功能,能够在节点故障或数据损坏时自动恢复数据
Manager(mgr):
管理器负责监控和管理集群的状态和性能。
提供了集群管理、性能调优和故障排除等功能。
支持插件机制,允许用户扩展和定制管理器的功能
CephFS(Ceph 文件系统):
提供了一个分布式文件系统,允许用户在整个集群中共享和访问文件
支持 POSIX 兼容的文件系统接口,使得 CephFS 可以集成到现有的应用程序和工具中
使用元数据服务器(MDS)来管理文件系统的元数据,并确保文件系统的一致性和可靠性
RADOS Gateway(RGW):
提供了一个面向对象的存储接口,允许用户通过 HTTP 或 S3/Swift API 访问 Ceph 存储
作为对象存储服务的门户,提供了对象存储、数据复制和访问控制等功能
支持多租户和多协议,能够同时处理不同类型的数据和请求
MDS:
MDS 负责管理文件系统的元数据,包括目录结构、文件属性和权限信息等
当客户端请求读取或写入文件时,MDS 负责将请求转发到正确的 OSD 上,并确保数据的一致性和完整性
三、ceph存储资源划分
Ceph 的资源划分主要涉及到存储池、PG(Placement Group)、CRUSH 映射等方面
存储池(Pool):
存储池是 Ceph 中用于管理数据的逻辑单元,用户可以在存储池中定义数据的副本数、CRUSH 规则、数据压缩等策略
存储池可以根据数据的不同需求划分,例如可以根据数据的访问模式、重要性和性能要求等进行划分
每个存储池都可以包含多个 PG
Placement Group(PG):
PG 是 Ceph 中数据的分布单元,用于实现数据的分布和复制
PG 根据 CRUSH 算法将数据均匀地分布在 OSD 上,并确保数据的复制和冗余
PG 的数量和大小对集群的性能和可靠性有重要影响,用户可以根据需要调整 PG 的数量和大小
pg的数量越多数据分布的越均衡
CRUSH 映射:
CRUSH 是 Ceph 集群中用于数据分布和故障域管理的算法
CRUSH 算法根据设定的规则将数据分布在不同的 OSD 上,并考虑了数据的复制和故障域的因素
CRUSH 映射将存储池中的 PG 映射到实际的 OSD 上,并负责数据的读取和写入操作
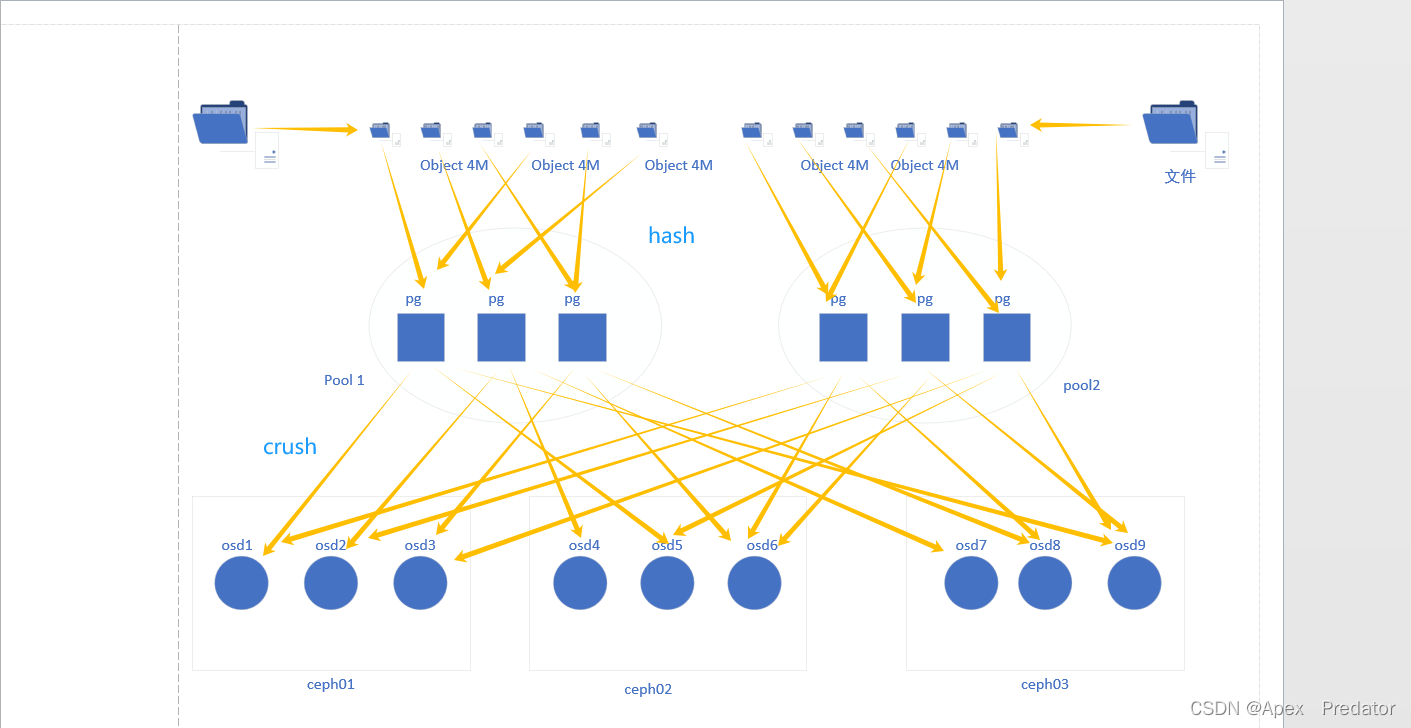
Ceph 存储过程
Ceph 将文件切分为大小相等的小块,默认为4M,并将这些小块通过hash算法分别存储到不同的 PG 中,再根据存储池配置的副本数,默认为3个,通过crush算法分配到不同的osd
四、后端存储引擎的介绍
新版本的ceph中默认使用bluestore,相对来说filestore还需要调用文件系统,性能没有bluestore好,bluesotre可以直接使用磁盘作为osd
FileStore:
FileStore 是 Ceph 最早引入的 OSD 后端存储引擎,它使用文件系统来管理 OSD 中的数据FileStore 将每个对象存储为一个文件,使用 XFS 或者 ext4 等文件系统来管理这些文件
FileStore 的优点包括成熟稳定、易于部署和管理,适用于旧版本的 Ceph 集群和传统的硬盘存储
BlueStore:
BlueStore 是 Ceph 新一代的 OSD 后端存储引擎,它直接管理 OSD 中的存储设备,不依赖于传统的文件系统
BlueStore 将数据以对象的形式直接存储到底层设备上,并使用 RocksDB 来管理元数据
BlueStore 的优点包括更高的性能、更低的存储开销、更好的数据完整性保障和更好的管理灵活性
BlueStore 适用于新版本的 Ceph 集群和要求更高性能和可靠性的应用场景,特别是在 SSD 和 NVMe 存储设备上的表现更加优越
















 2273
2273











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









