










近日,由亿欧、上海市人工智能行业协会(SAIA)主办的2024全球开发者大会“百模大战”商业发展讲坛成功举办。作为全球开发者大会的平行技术论坛之一,本场论坛聚焦大模型产业,分析大模型赛道的竞争格局,洞悉大模型技术的商业化挑战和机遇,探讨“百模大战”的未来趋势和走向。
本次大会通过汇聚行业专家、企业决策者和投资者的智慧,共同寻找推动大模型技术落地的策略,以期在商业化的道路上实现互利共赢。会上,澳鹏Appen市场拓展副总裁董成与各领域专家就“百模大战,未来是万紫千红还是一枝独秀”进行了深度探讨。

董成用“技、工、贸”三个字总结了对未来趋势的看法,分别是技术层的竞争会越来越难,大概率会形成几个寡头的局面;未来利用大模型和工业化融合来提升创新和生产力是一个很有潜力的方向;产业发展后期企业的商业化能力是大模型上下游厂商获得竞争优势和生存的关键因素。
《2024中国“百模大战”竞争格局分析报告》重磅发布
亿欧新科技事业部研究总监孙毅颂在会议上正式发布《2024中国“百模大战”竞争格局分析报告》(文末附下载链接)。这份报告从“百模大战”的关键进程切入,分析大战爆发原因及核心竞争力,评估通用大模型厂商的综合竞争力,洞察垂类大模型的行业发展前景,最后围绕通用大模型市场竞争格局、垂类大模型市场竞争格局、开源闭源发展路径、AI Agent和多模态生成等领域作出趋势判断。
自ChatGPT-3.5的发布引发了全球范围内对大模型的广泛关注以来,目前,国内公布的大模型数量已超过300个,行业呈现出“百模大战”的竞争格局。随着大模型技术的演进,其赋能千行百业的能力不断提升。
《2024中国“百模大战”竞争格局分析报告》构建了大模型基础层图谱、通用大模型图谱和垂类大模型图谱,全方位呈现大模型产业现状。作为产业链上的重要一环,澳鹏Appen凭借高质量的大模型数据能力成功入选大模型基础层图谱。
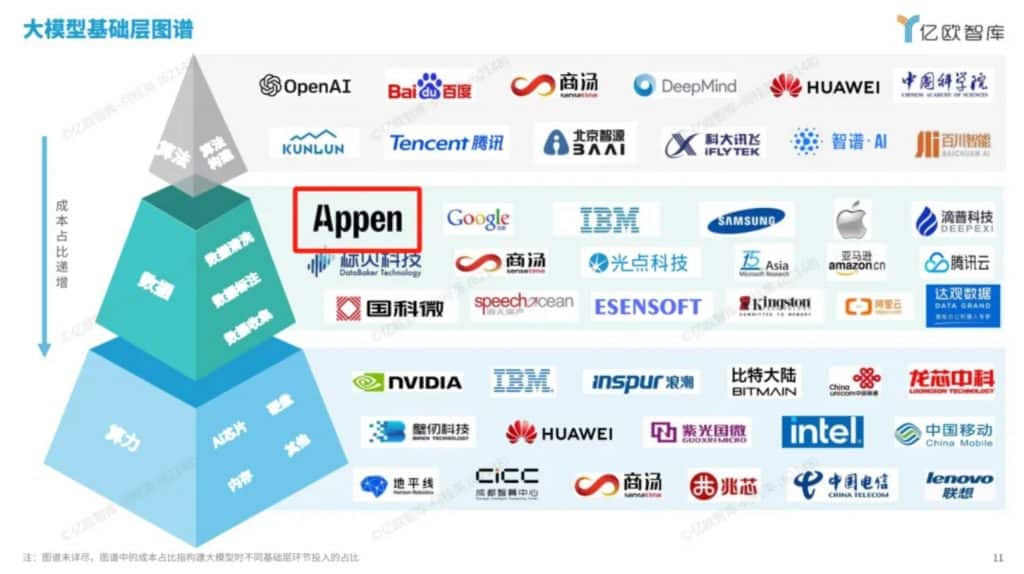
*图片来源于亿欧报告
在技术平台方面:澳鹏智能大模型开发平台提供数据集管理、数据标注、计算资源调度、模型评估、模型微调等全栈产品,助力企业轻松拥抱大模型。
在数据集方面:针对大模型的基础模型训练、模型微调、以及应用落地需求,澳鹏提供超过290种语言和方言的相关文本、语音数据库,并创建了一系列大模型专用的数据集,如:百科类人工泛化文本问答数据集,知识类百科文本语料对数据库,58亿图文对数据库,法律问答及医疗问答等。
澳鹏全栈式大模型智能开发平台 | 赋能AGI智能涌现
数据是人工智能发展的关键因素,高质量数据可有效地提高模型性能。《2024中国“百模大战”竞争格局分析报告》以澳鹏Appen为大模型数据领域的代表案例,分析了澳鹏Appen如何成功助力全球7,500+个AI项目的研发及商业化,赋能AGI智能涌现。
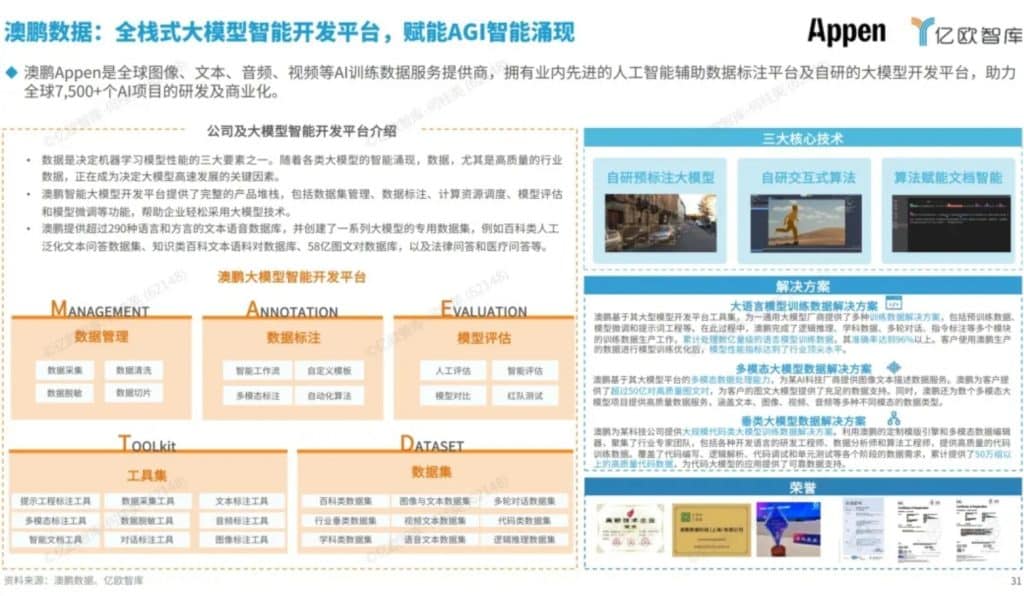
*图片来源于亿欧报告
澳鹏大模型智能开发平台为企业提供高质量训练数据解决方案,助力企业的数据采集、清洗、标注以及管理,快速地构建高质量数据集。澳鹏自研的算法模型和核心技术,如预标注大模型、交互式算法、文档智能产品等,在数据生产加工的过程中起到关键作用,极大地提升了项目交付的效率和质量。
平台三大核心技术:
自研预标注大模型
自研交互式算法
算法赋能文档智能
案例 | 澳鹏大模型数据解决方案
案例1:大语言模型训练数据解决方案
依托澳鹏大模型开发平台的工具集套件,澳鹏为某通用大模型厂商提供预训练数据、模型微调和提示词工程等训练数据解决方案,完成了逻辑推理,学科数据,多轮对话,指令标注等多个模块的训练数据生产工作,累计处理数亿量级的大语言模型训练数据,数据准确率达到96%以上。客户基于澳鹏所生产的数据优化模型训练,模型的性能指标达到行业顶尖水平。
案例2:多模态大模型数据解决方案
基于澳鹏的大模型平台多模态数据处理能力,澳鹏为某AI科技厂商提供图像文本描述数据服务工作,提供高质量图文对超过50亿对,为客户的图文大模型提供了丰富的数据养料。澳鹏同时也在为数个多模态大模型项目提供高质量数据服务,数据类型跨文本、图像、视频、音频等多种不同模态。
案例3:垂类大模型数据解决方案
澳鹏为某科技公司提供大规模代码类大模型训练数据解决方案,基于高度定制的澳鹏自定义模版引擎和多模态数据编辑器,汇聚了大量行业领域专家,包括覆盖各种不同开发语言的研发工程师,数据分析师和算法工程师,提供高质量的代码训练数据。从代码编写,逻辑解析,到代码调试和单元测试,涵盖代码垂类大模型所需数据的各个阶段,生产出高质量代码数据50万组以上。为代码大模型的落地应用提供了高质量的数据保障。
本次《2024中国“百模大战”竞争格局分析报告》的最后还重磅引述了三位行业大咖的观点。其中,澳鹏Appen全球高级副总裁、大中华区及北亚区总经理田小鹏博士分享道:“随着“数据二十条”等一系列政策措施相继出台,数据要素市场的探索与发展已步入高速增长阶段。据亿欧预计,2025年数据要素市场规模可达1990亿元,年复合增长率可达25%。尤其是在人工智能快速迭代、大模型与数据相得益彰的发展态势中,数据要素的战略地位进一步凸显。数据是决定机器学习模型性能的三大要素之一。随着各类大模型的智能涌现,数据,尤其是高质量的行业数据,正在成为决定大模型高速发展的关键因素。澳鹏自研的算法模型和核心技术,通过AI赋能数据全生命周期,更快更多地给予AI应用数据养料,为大规模的大模型场景落地提供支持。”

《2024中国“百模大战”竞争格局分析报告》
扫描上方二维码
限时免费下载

















 1251
1251

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









