







这里拿CFAR10数据集举例
CIFAR-10数据集包含60000张32x32彩色图像,分为10个类,每类6000张。有50000张训练图片和10000张测试图片。
先简单介绍一下(来自官方文档的介绍)
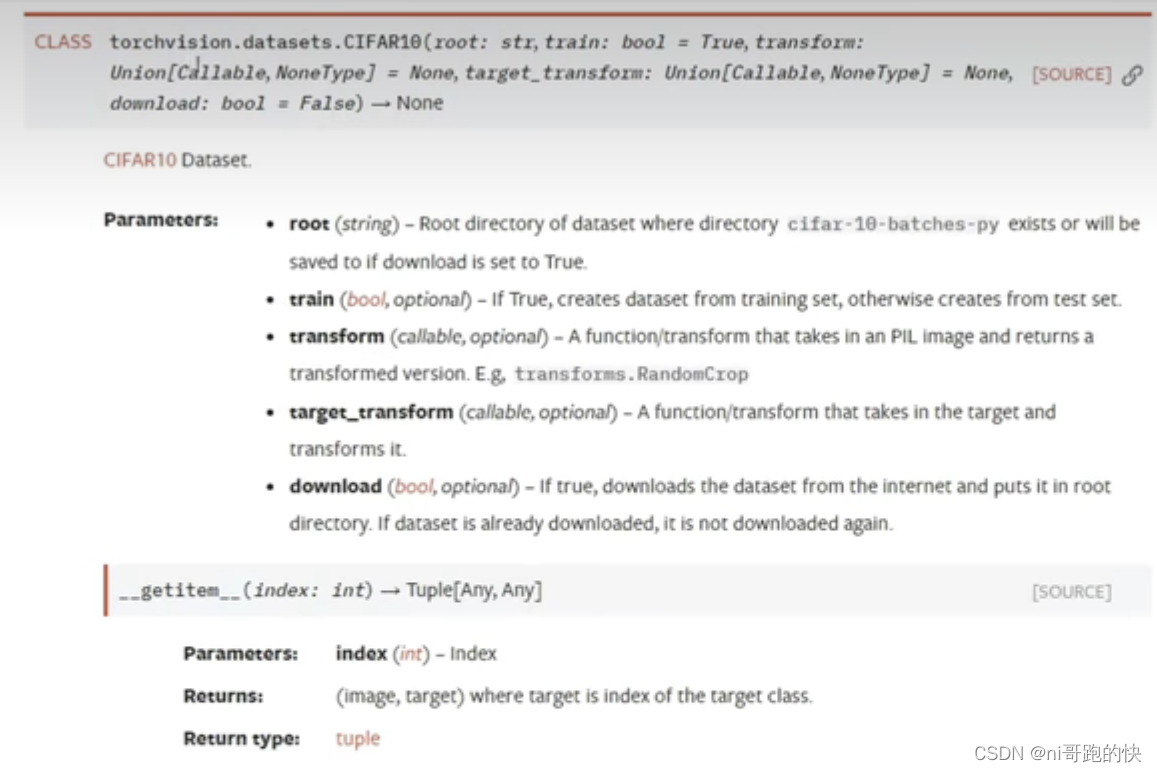
root:数据集的位置
tran:true-训练集;false-测试集
download:true-自动从网上下载数据集
下面讲一下常用操作:
先导入包,然后输入
import torchvision
test_data = torchvision.datasets.CIFAR10("learn_torch/dataset2",train=True, download=True)
#注意所有的True/False首字母要大写,不然识别不出来
download这个方法比较智能,如果你没有它会自动给你下载到这个地址上,如果你之前在这个地址中下载过,他会直接辨别并验证,不会重复下载,所以可以使用让它为True
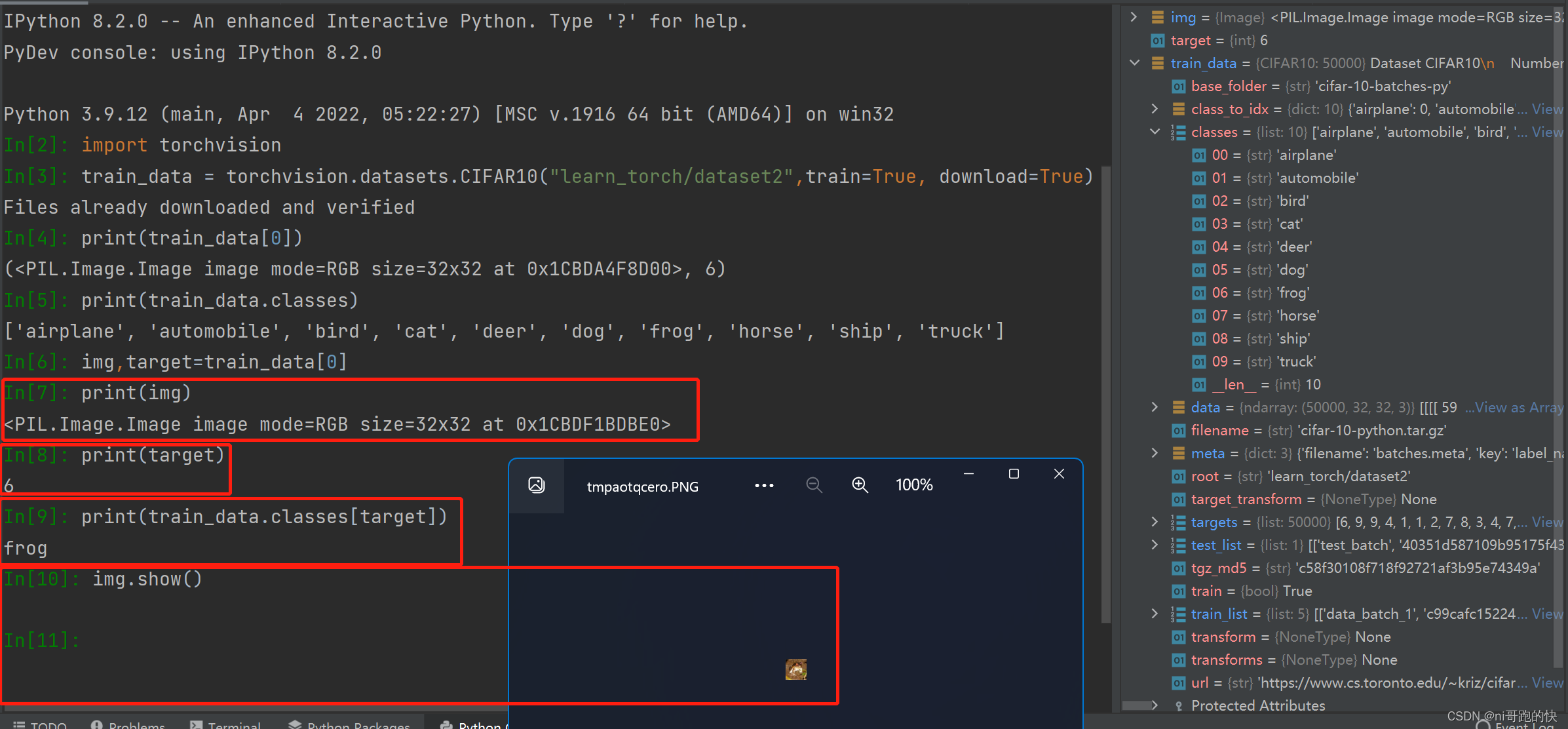
下面这是使用print打印数据集里的一张图我们能看到的形式,最后面的那个6是对应的class,在CIFAR10中我们有10个class,在右边红框里可以看到。
Dataloader
官方文档的说明

batch_size:每一次取数据的数量(步长)
shuffle:true-每次取数据都进行变换(改组),默认情况为false,一般设置为true
num_works:运行时进程数量(一般越多越快),通常是0(主进程运行);土堆说:如果在windows下报错,可以改成0再试试
drop_last:true-在取数据有余数的时候(100个数据每次取30张,剩10个)舍去剩下的
代码举例:
import torchvision.datasets
from torch.utils.data import DataLoader
#准备的测试数据集
from torch.utils.tensorboard import SummaryWriter
#下载并加载数据
test_data = torchvision.datasets.CIFAR10("./dataset2",train=False, transform=torchvision.transforms.ToTensor())
#将数据处理打包,处理成随机的64个一组,最后剩下的留着
test_loader = DataLoader(dataset=test_data, batch_size=64, shuffle=True, num_workers=0, drop_last=True)
img,target = test_data[0]
print(img.shape)
print(target)
writer = SummaryWriter("P12_dataloader")
step = 0
for data in test_loader:
imgs, targets = data
# print(imgs.shape)
# print(targets)
writer.add_images("test_data_drop_last",imgs, step)
step = step + 1
writer.close()













 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









