







训练代码(训练轮数提高到了70轮,学习速度降到了0.005)
完整代码如下:
import torch
import torchvision
from torch import nn
from torch import optim
from torch.nn import Conv2d,MaxPool2d,Flatten,Linear,Sequential
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
import time
#定义训练的设备
device = torch.device("cuda")
#准备数据集
train_data = torchvision.datasets.CIFAR10(root="./dataset2", train=True, transform=torchvision.transforms.ToTensor(),
download=True)
test_data = torchvision.datasets.CIFAR10(root = "./dataset2",train=False, transform=torchvision.transforms.ToTensor(),
download=True)
#length长度
train_data_size = len(train_data)
test_data_size = len(test_data)
print("训练数据集的长度为:{}".format(train_data_size))
print("测试数据集的长度为:{}".format(test_data_size))
#利用DataLoader来加载数据集
train_dataloader = DataLoader(train_data,batch_size=64)
test_dataloader = DataLoader(test_data,batch_size=64)
#准备训练模型
class qiqi(nn.Module):
def __init__(self):
super(qiqi, self).__init__()
self.model1 = Sequential(
Conv2d(3, 32, 5, padding=2), #注意有逗号
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self,x):
x=self.model1(x)
return x
#创建网络模型
qq=qiqi()
qq = qq.to(device)
#损失函数
loss_fn = nn.CrossEntropyLoss()
loss_fn = loss_fn.to(device)
#优化器
learning_rate = 5e-3
optimizer = torch.optim.SGD(qq.parameters(),lr=learning_rate)
#设置训练网络的一些参数
#记录训练的次数
total_train_step = 0
#记录测试的次数
total_test_step = 0
#训练的轮数
epoch = 70
#记录时间
start_time = time.time()
writer = SummaryWriter("train_gpu2")
for i in range(epoch):
print("--------第 {} 轮训练开始--------".format(i+1))
#训练步骤开始
qq.train() #对现在的网络层没影响,在含有bn层和dropout层的模型中有影响,因为这两个层在训练和测试是不一样的
for data in train_dataloader:
imgs,targets = data
imgs = imgs.to(device)
targets = targets.to(device)
outputs = qq(imgs)
loss = loss_fn(outputs,targets)
#优化器优化模型
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_train_step = total_train_step+1
if total_train_step % 100 == 0:
end_time = time.time()
print("本轮用时:{}".format(end_time-start_time) )
print("训练次数:{}, loss: {}".format(total_train_step,loss.item())) #这里item也可以不用
writer.add_scalar("train_loss",loss.item(),total_train_step)
#测试步骤开始
qq.eval() #对现在的网络层没影响,在含有bn层和dropout层的模型中有影响,因为这两个层在训练和测试是不一样的
total_test_loss = 0
total_accurancy = 0
with torch.no_grad():
for data in test_dataloader:
imgs, targets = data
imgs = imgs.to(device)
targets = targets.to(device)
outputs = qq(imgs)
loss = loss_fn(outputs, targets)
total_test_loss = total_test_loss + loss.item()
accurancy = (outputs.argmax(1) == targets).sum()
total_accurancy = total_accurancy + accurancy
print("整体测试集上的loss:{}".format(total_test_loss))
print("整体测试集上的正确率:{}".format(total_accurancy/test_data_size))
writer.add_scalar("test_loss",total_test_loss,total_test_step)
writer.add_scalar("test_accuracy",total_accurancy/test_data_size,total_test_step)
total_test_step = total_test_step + 1
torch.save(qq,"qq_model/qq_{}.pth".format(i))
print("模型已保存")
writer.close() 

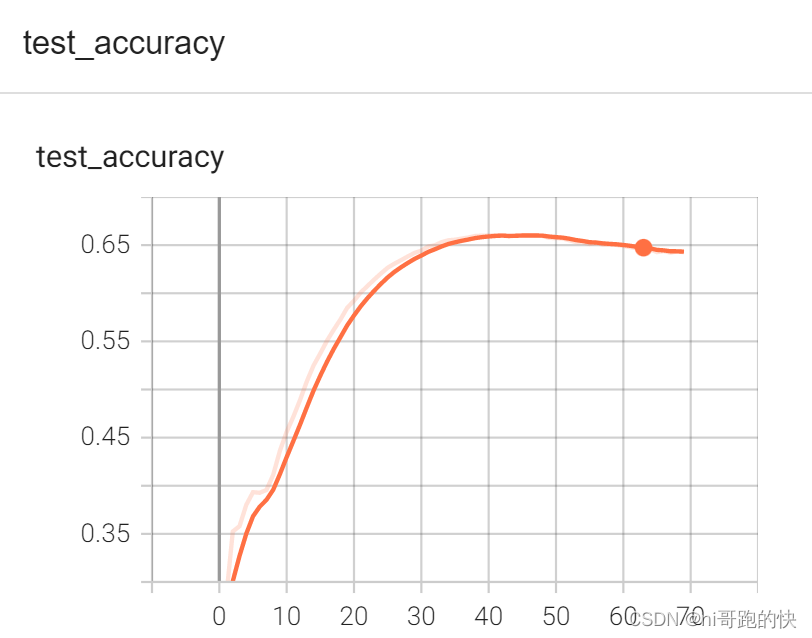
(这里显然是有些过拟合了)拿70轮训练的效果不大好了,下面就拿35轮的训练结果验证吧
训练完成之后我们拿其中训练好的“qq_35.pth”这个模型来进行验证(这个模型经过训练准确度已经达到了65%左右)
验证代码如下:
import torch
import torchvision
from PIL import Image
from torch import nn
from torch.nn import Conv2d,MaxPool2d,Flatten,Linear,Sequential
#导入图片
image_path = "learn_torch/imgs/dog4.png"
image = Image.open(image_path)
image = image.convert('RGB')#因为png格式是四个通道,除了RGB三通道之外,还有一个透明通道,所以,我们调用此行保留颜色通道
#加上这句话之后可以进一步适应不用格式,不同截图软件的图片
print(image)
#图片裁切、格式转化
transform = torchvision.transforms.Compose([torchvision.transforms.Resize((32,32)),
torchvision.transforms.ToTensor()])
image = transform(image)
print(image.shape)
class qiqi(nn.Module):
def __init__(self):
super(qiqi, self).__init__()
self.model1 = Sequential(
Conv2d(3, 32, 5, padding=2), #注意有逗号
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self,x):
x=self.model1(x)
return x
#加载模型
model = torch.load("learn_torch/qq_model/qq_35.pth",map_location=torch.device('cpu')) #因为这个模型是在gpu上训练的,因此需要进行映射
print(model)
image = torch.reshape(image,(1,3,32,32))
model.eval()
with torch.no_grad():
output = model(image)
print(output)
print(output.argmax(1))拿小狗的图像为例


结果对照一下,是正确的
















 1429
1429











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









