







修改index、columns
1. 导入模块
import numpy as np
import pandas as pd 2. 修改index、columns, 通过把原来的数据覆盖掉进行修改
# 修改index、columns, 通过把原来的数据覆盖掉进行修改
df1 = pd.DataFrame(np.arange(9).reshape(3,3), index=['sh','cs','bj'],columns=['a','b','c'])
print(df1)
print("*"*20)
# 获取索引
print(df1.index)
print("*"*20)
# 获取索引数据['sh', 'cs', 'bj']
print(df1.index.tolist())
print("*"*20)
# 修改索引
df1.index = ['shanghai','changsha','beijing']
print(df1)
print("*"*20)
# 修改列名
df1.columns = ['A','B','C']
print(df1)运行结果
a b c
sh 0 1 2
cs 3 4 5
bj 6 7 8
********************
Index(['sh', 'cs', 'bj'], dtype='object')
********************
['sh', 'cs', 'bj']
********************a b c
shanghai 0 1 2
changsha 3 4 5
beijing 6 7 8
********************A B C
shanghai 0 1 2
changsha 3 4 5
beijing 6 7 8
3. 批量进行重命名
# 批量进行重命名
def func(x):
return x+'_ABC'
# rename
df1.rename(index=func, columns=func) # 注意:没有使用inplace=True时,不会修改df1的数据,而是返回一个新的数据运行结果
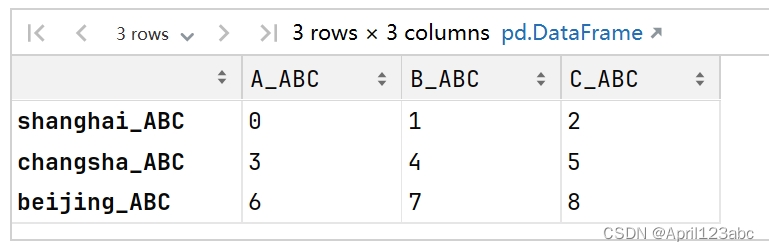
4. 个性化更改行索引或者列索引 优先考虑字典的方式
df2 = df1.rename(index={'shanghai':'SHANGHAI'}, columns={'C': 'c'})
print(df2)运行结果
A B c
SHANGHAI 0 1 2
changsha 3 4 5
beijing 6 7 8
常见操作
添加列
data = {
'Date':['2023-09-01','2023-09-02','2023-09-03'],
'Step 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 701
701











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









