







本文内容基于《算法笔记》和官方配套练题网站“晴问算法”,是我作为小白的学习记录,如有错误还请体谅,可以留下您的宝贵意见,不胜感激
一、最小生成树及其性质
最小生成树是在一个给定的无向图G(V,E)中求一棵树T,使得这棵树拥有图G的所有顶点,且所有边都是来自图G的边,并且满足整棵树的边权之和最小。
从定义来看,就是要求一个连通方案,使其可以从任一点出发到达连通图的任一点,且这个方案的边权之和需要最小,即求最小连通子图。
最小生成树的性质:
①最小生成树是树,因此其边数等于顶点数减1,且树内一定不会有环。
②对给定的图G(V,E),其最小生成树可以不唯一,但其边权之和一定是唯一的。
③由于最小生成树是在无向图上生成的,因此其根结点可以是这棵树上的任意一个结点。
二、prim算法
prim算法的基本思想:对图G(V,E)设置集合S(即巨型防护罩)来存放已被访问的顶点(即已攻占的城市),然后执行n次下面的两个步骤(n为顶点个数):
①每次从集合V-S(即未攻占的城市)中选择与集合S(巨型防护罩)最近的一个顶点(记为u),访问(即攻占)u并将其加入集合S(加入巨型防护罩),同时把这条离集合S最近的边加入最小生成树中。
②令顶点u作为集合S与集合V-S连接的接口(即把当前攻占的城市作为巨型防护罩与外界的接口),优化从u能到达的未访问顶点ⅴ(未攻占城市)与集合S(巨型防护罩)的最短距离。
prim算法的具体实现:pim算法需要实现两个关键的概念,即集合S的实现、顶点Vi(0≤i≤n-I)与集合S(巨型防护罩)的最短距离。
①集合S的实现方法和Dijkstra中相同,即使用一个bool型数组vis[]表示顶点是否已核访问。其中vis[i]==tnue表示顶点Vi已被访问,vis[i]==false则表示顶点Vi未被访问。
②不妨令int型数组d[]来存放顶点Vi(0≤i≤n-1)与集合S(巨型防护罩)的最短距离。切始时除了起点s的d[s]赋为0,其余顶点都赋为一个很大的数来表示INF,即不可达。
prim算法生成的一定是树结构的证明:
①首先,亚历山大一定是每次从已攻占城市出发去攻打未攻占城市,这说明最后生成的结构一定连通。
②其次,亚历山大在把起点攻占以后,总是沿着一条新的道路去攻击一个新的城市,这说明最后生成的结构的边数一定比顶点数少1。
基于上面两点,最后生成的结构定是一棵树(是满足了连通、边数等于顶点数减1)。
至于为什么是最小生成树(贪心证明),可以参考算法导论。
prim算法模板:
//G为图,一般设为全局变量,数组d为顶点与集合S的最短距离
prim(G , d[]){
初始化;
for(循环n次){
u = 使d[u]最小的还未被访问的顶点的标号;
记u已被访问;
for(从u出发能到达的所有顶点v){
if(v未被访问&&以u为中介点使得v与集合S的最短距离d[v]更优)
将G[u][v]赋值给v与集合S的最短距离的d[v];
}
}
}
prim算法和Dijkstra算法的贪心策略是相同的思路,只是在数组d[]上的含义不同;这种写法时间复杂度为O(V^2),其中V是顶点数,所以prim算法适合顶点数目少而边多的连通图(稠密图)。
实例:
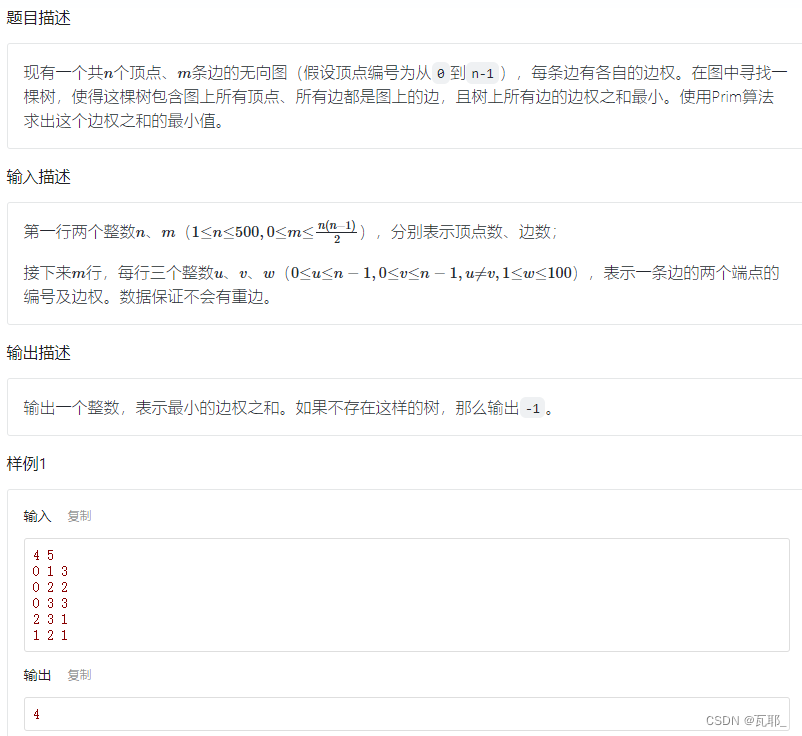
完整代码如下:
#include<cstdio>
#include<vector>
#include<queue>
#include<algorithm>
using namespace std;
const int MAXN = 500;
const int INF = 1e9;
struct Node{
int v , w;
};
vector <Node> Adj[MAXN];
int d[MAXN]; //散列顶点到集合(最小生成树)的最短距离 , 下标为顶点
bool hashTable[MAXN] = {};
int n , m;
int prim(int s){
fill(d , d + MAXN , INF);
d[s] = 0;
int ans = 0;
for(int i = 0; i < n; i++){
int u = -1 , MIN = INF;
for(int j = 0; j < n; j++)
if(hashTable[j] == false && d[j] < MIN){
u = j;
MIN = d[j];
}
if(u == -1) return -1;
hashTable[u] = true;
ans += d[u];
for(int j = 0; j < Adj[u].size(); j++){
int v = Adj[u][j].v;
if(hashTable[v] == false && Adj[u][j].w < d[v])
d[v] = Adj[u][j].w;
}
}
return ans;
}
int main(){
scanf("%d%d", &n , &m);
for(int i = 0; i < m; i++){
int u , v , w;
scanf("%d%d%d", &u , &v , &w);
Node uv = {v , w};
Node vu = {u , w};
Adj[u].push_back(uv);
Adj[v].push_back(vu);
}
int ans = prim(0);
printf("%d", ans);
}
三、prim算法堆优化
在prim算法中,通过全遍历找d[]数组中未被访问且距离集合S最短的顶点,这种动态更新数据流中最值的方法可以采用堆来实现,于是prim算法时间复杂度可以降为O(nlogn)。具体实现方法是开一个优先级队列作为辅助空间,将更新的最短距离以及对应的顶点放入优先级队列中,这样每次循环便可以直接取出堆顶的元素;而这种对应关系可以采用结构体或者pair模板实现,我选择结构体实现,于是优先级队列的定义为:
struct Hash{ //用于优先级队列的散列
int u , du; //最短距离以及对应的顶点
};
struct cmp{
bool operator ()(Hash a , Hash b){
return a.du > b.du;
}
};
priority_queue <Hash , vector<Hash> , cmp> pq;
1.需要注意的是,由于堆无法实现随机访问,所以这种更新实际上是反复加入顶点V到集合S的最短距离,所以可能存在相同顶点由于反复更新最短距离而重复加入的情况,所以需要在循环中进行判断。2.另外,如果图可能不连通,则还需要加一个计数器来记录处理结点的数量,如果计数小于输入数量,则说明有顶点未被访问(距离太远走不到,即顶点V不存在与集合S的连通边),图就是不连通的。
实例:
1.最小造路成本
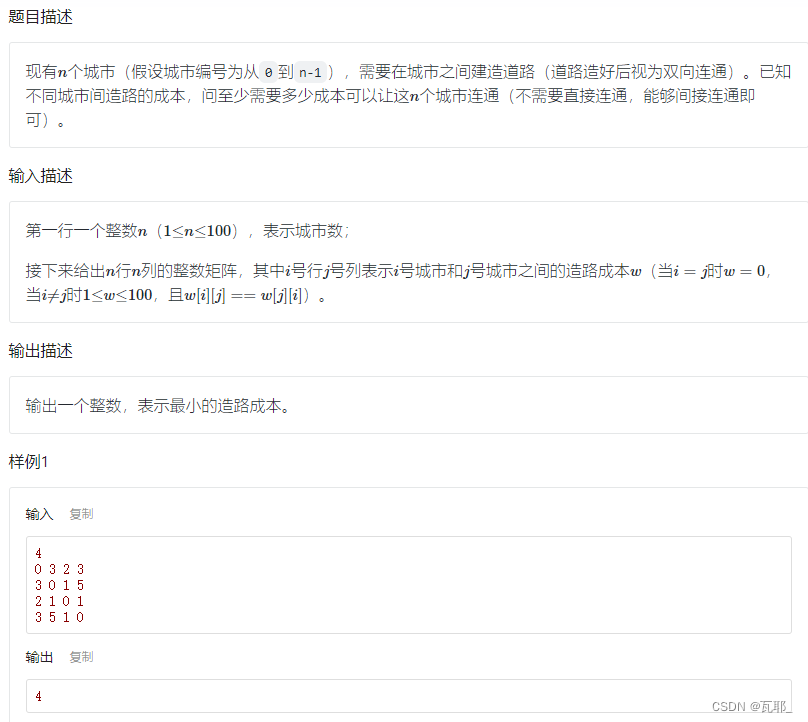
这道题内我采用了两个结构体实现,主要是为了防止误解,但其实两个结构体内的变量数量和类型一模一样,完整代码如下:
//堆优化:用堆作为辅助空间以log的复杂度取最值
//这道题有一个隐藏前提,即图是连通的
#include<cstdio>
#include<algorithm>
#include<vector>
#include<queue>
using namespace std;
const int MAXN = 100;
const int INF = 1e9;
struct Node{ //用于领接表
int v , w;
};
struct Hash{ //用于优先级队列的散列
int u , du;
};
struct cmp{
bool operator ()(Hash a , Hash b){
return a.du > b.du;
}
};
priority_queue <Hash , vector<Hash> , cmp> pq;
vector <Node> Adj[MAXN];
int d[MAXN];
bool hashTable[MAXN] = {};
int n;
int prim(int s){
fill(d , d + MAXN , INF);
d[s] = 0;
Hash S = {s , 0};
pq.push(S);
int ans = 0;
while(!pq.empty()){
int u = pq.top().u , du = pq.top().du;
pq.pop();
if(hashTable[u]) continue;//注意这里,如果满足以u为中介点可以更新距离,会重复将某个结点加入堆,并不是更新堆内的数据
ans += du;
hashTable[u] = true;
for(int j = 0; j < Adj[u].size(); j++){
int v = Adj[u][j].v;
if(hashTable[v] == false && Adj[u][j].w < d[v]){
d[v] = Adj[u][j].w;
Hash temp = {v , d[v]}; //优先级队列只能查看堆顶元素,不能随机访问
pq.push(temp);
}
}
}
return ans;
}
int main(){
scanf("%d", &n);
for(int i = 0; i < n; i++)
for(int j = 0; j < n; j++){
if(i != j) {
int tempw;
scanf("%d", &tempw);
Node ij = {j , tempw};
Adj[i].push_back(ij);
}
else {
int null;
scanf("%d", &null);
}
}
printf("%d", prim(0));
}
2.最大删边权值
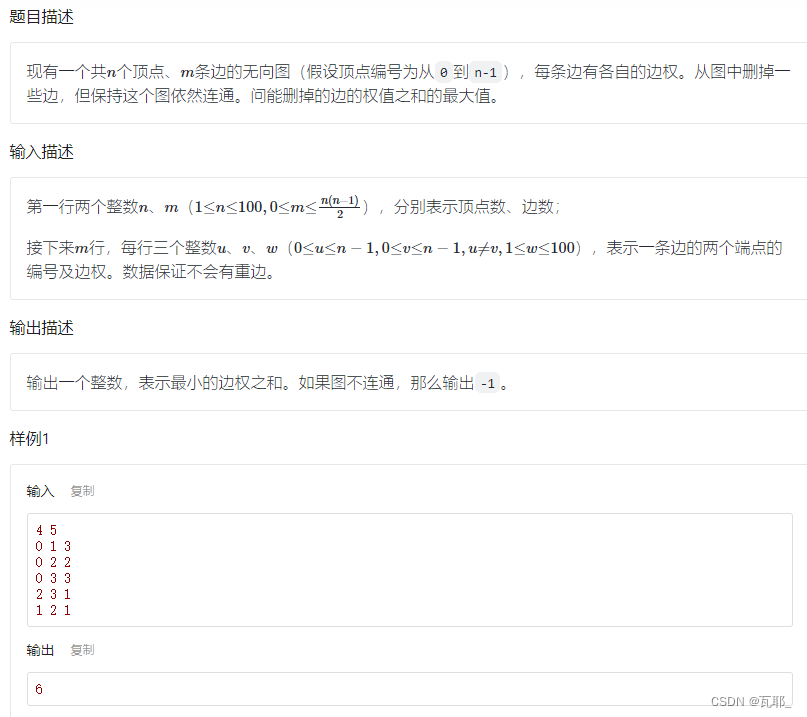
完整代码如下:
//逻辑题:最小生成树之外的边就可以被删掉,求出最小生成树的权值,剩下的权值就是删边权值
#include<cstdio>
#include<algorithm>
#include<vector>
#include<queue>
using namespace std;
const int MAXN = 100;
const int INF = 1e9;
struct Node{//这里将vector和priority_ququq内的两种结构体简化成一个来实现,请注意在不同容器内的含义
int v , w; //vector内放的是图的顶点和边权,优先级队列内放的是散列的顶点以及到集合S的最短距离
};
struct cmp{
bool operator ()(Node a , Node b){
return a.w > b.w;
}
};
vector <Node> Adj[MAXN];
priority_queue <Node , vector<Node> , cmp> pq;
int d[MAXN];
bool hashTable[MAXN] = {};
int n , m;
int prim(int s){
fill(d , d + MAXN , INF);
d[s] = 0;
Node S = {s , 0};
pq.push(S);
int ans = 0 , index = 0; //index记录处理的顶点数量
while(!pq.empty()){ //注意堆优化如何判断连通
int u = pq.top().v , du = pq.top().w;
pq.pop();
if(hashTable[u]) continue;
ans += du;
hashTable[u] = true;
for(int j = 0; j < Adj[u].size(); j++){
int v = Adj[u][j].v;
if(!hashTable[v] && Adj[u][j].w < d[v]){
d[v] = Adj[u][j].w;
Node temp = {v , d[v]};
pq.push(temp);
}
}
index++; //处理一个顶点
}
if(index == n) return ans; //如果所有顶点都处理完了
else return -1;
}
int main(){
scanf("%d%d", &n , &m);
int sum = 0;
for(int i = 0; i < m; i++){
int u , v , w;
scanf("%d%d%d", &u , &v , &w);
Node uv = {v , w};
Node vu = {u , w};
Adj[u].push_back(uv);
Adj[v].push_back(vu);
sum += w;
}
int ans = prim(0);
if(ans != -1) printf("%d", sum - ans);
else printf("-1");
}
四、kruskal算法
kruskal算法采用边贪心策略;
kruskal算法的基本思想:在初始状态时隐去图中的所有边,这样图中每个顶点都自成一个连通块。之后执行下面的步骤:
①对所有边按边权从小到大进行排序。
②按边权从小到大测试所有边,如果当前测试边所连接的两个顶点不在同一个连通块中,则把这条测试边加入当前最小生成树中:否则,将边舍弃。
③执行步骤②,直到最小生成树中的边数等于总项点数减1或是测试完所有边时结束。而当结束时如果最小生成树的边数小于总顶点数减1,说明该图不连通。
简述:每次选择最小边权的边,如果边两端的顶点在不同的连通块中,就把这条边加入最小生成树中。
kruskal算法需要一个特殊的结构体来保存边的信息,同时还需要在访问到边的同时访问边的两个顶点,所以结构体定义如下:
struct Node{
int u , v , w;
}node[MAXN];
kruskal算法模板:
int kruskal() {
令最小生成树的边权之和为ans、最小生成树的当前边数Num_Edge;
将所有边按边权从小到大排序;
for (从小到大枚举所有边) {
if (当前测试边的两个端点在不同的连通块中) {
将该测试边加入最小生成树中;
ans += 测试边的边权;
最小生成树的当前边数Num_Edge加1;
当边数Num_Edge等于顶点数减1时结束循环;
}
}
return ans;
}
其中判断两点是否连通可以采用并查集的查找实现,(并查集传送门)将测试边加入最小生成树的操作实际就是将边的两个端点加入最小生成树,可以采用并查集的合并实现。
时间复杂度为O(ElogE)其中E为边数,所以kruskal适合顶点多而边少的图(稀疏图)。
kruskal算法生成的一定是树结构的证明:
①由于图本身连通,因此每个顶点都会有边连接。而一开始每个结点都视为一个连通块,因此在枚举过程中一定可以把每个顶点都访问到,且只要是第一次访问某个顶点, 对应的边一定会被加入最小生成树中,故图中的所有顶点最后都会被加入最小生成树中。
②由于只有当测试边连接的两个顶点在不同的连通块中时才将其加入最小生成树,因此一定不会产生环。而如果有两个连通块未被连接,要么它们本身就无法被连接(也就是非连通图),要么它们之间一定有边。由于所有边都会被测试,因此两个连通块最终一定会被连接在一起。故最后一定会生成一个连通的结构。
③由于算法要求当最小生成树中的边数等于总顶点数减1时结束,因此由连通、边数等于项点数减1这两点可以确定,最后一定能生成一棵树。
至于为什么是最小生成树(贪心证明),可以参考算法导论。
实例:
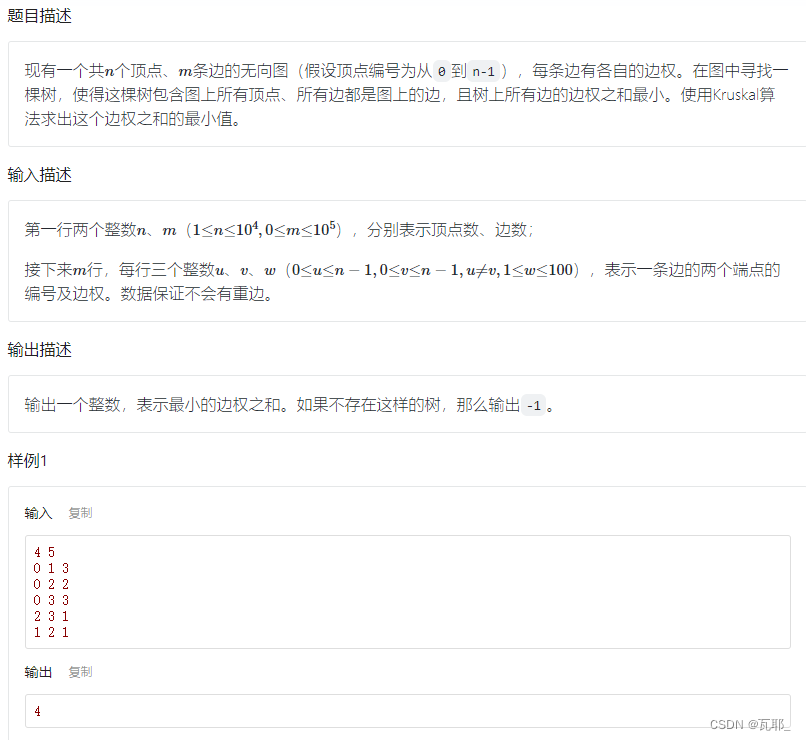
完整代码如下:
#include<cstdio>
#include<algorithm>
using namespace std;
const int MAXN = 1e5;
struct Node{
int u , v , w;
}node[MAXN];
int father[MAXN];
int n , m;
bool cmp(Node a , Node b){
return a.w < b.w;
}
int findFather(int x){
int r = x;
while(father[r] != r) r = father[r];
while(x != father[x]){
int fatherx = father[x];
father[x] = r;
x = fatherx;
}
return r;
}
bool Union(int u , int v){
int fu = findFather(u);
int fv = findFather(v);
if(fu != fv){
father[fu] = fv;
return false; //不在同一个集合
}
return true;
}
void init(){
for(int i = 0; i < n; i++) father[i] = i;
}
int kruskal(){
init();
int ans = 0 , num = 0;
sort(node , node + m , cmp);
for(int i = 0; i < m; i++){
if(Union(node[i].u , node[i].v) == false) {
ans += node[i].w;
num++;
}
if(num == n - 1) break; //满足边数等于顶点数减一的树形结构后,就不再放入边了
}
if(num != n - 1) return -1;//若图不连通,最后得到的边数会比顶点数减一还要小,因为存在没有合并在一起的边
else return ans;
}
int main(){
scanf("%d%d", &n , &m);
for(int i = 0; i < m; i++) scanf("%d%d%d", &node[i].u , &node[i].v , &node[i].w);
printf("%d", kruskal());
}
五、其余小题练习
1.最小连通成本
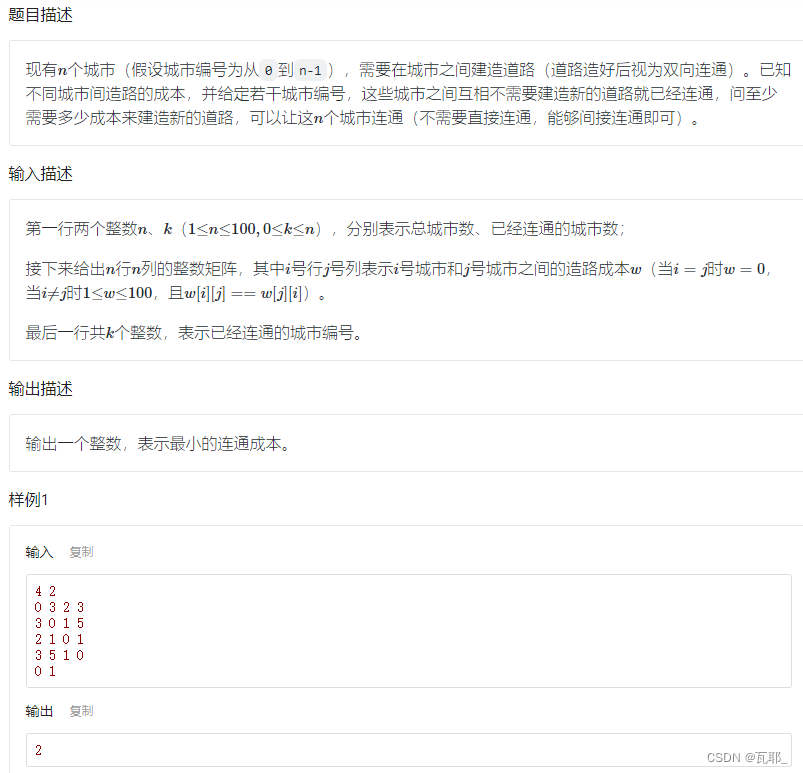
思路:已经建好的道路就不再花费成本,故可以将已经建好的道路边权设置为0,这样不论在prim还是kruskal算法中,贪心策略都可以将这些边选择上(因为0就是最小边权)。
但是在kruskal算法中,很难实现对边的散列访问,如果采用暴力枚举,那时间复杂度将是O(k^2+ElogE),可以看出还是很大的。由于kruskal采用的是边贪心策略,所以可以把已经建好的道路合并在一个并查集中,这样在算法实现过程中就不会再加入这些边权,并且可以保证贪心策略会在已经建成的道路基础上进行。
prim实现代码如下:
#include <cstdio>
#include <cstring>
#include <vector>
#include <algorithm>
using namespace std;
const int MAXN = 100;
const int INF = 1e9;
int G[MAXN][MAXN];
int d[MAXN], linked[MAXN];
bool vis[MAXN];
int prim(int n) {
fill(d, d + MAXN, INF);
memset(vis, false, sizeof(vis));
d[0] = 0;
int weightSum = 0;
for (int i = 0; i < n; i++) {
int u = -1, minDis = INF;
for (int j = 0; j < n; j++) {
if (!vis[j] && d[j] < minDis) {
u = j;
minDis = d[j];
}
}
if (u == -1) {
return -1;
}
vis[u] = true;
weightSum += d[u];
for (int v = 0; v < n; v++) {
if (!vis[v] && G[u][v] < d[v]) {
d[v] = G[u][v];
}
}
}
return weightSum;
}
int main() {
int n, k;
scanf("%d%d", &n, &k);
for (int i = 0; i < n; i++) {
for (int j = 0; j < n; j++) {
scanf("%d", &G[i][j]);
}
}
for (int i = 0; i < k; i++) {
scanf("%d", &linked[i]);
}
for (int i = 0; i < k; i++) {
for (int j = 0; j < i; j++) {
G[linked[i]][linked[j]] = 0;
G[linked[j]][linked[i]] = 0;
}
}
int weightSum = prim(n);
printf("%d", weightSum);
return 0;
}
备注
1.kruskal算法很难实现散列访问边信息及顶点信息;
2.常见考点会考在贪心策略中进行操作,这点和Dijkstra算法类似。
















 1111
1111











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











