






目录
第一部分:前言与基础知识
-
人工智能与自然语言处理概述
-
人工智能的定义与发展
-
自然语言处理的历史与现状
-
NLP的主要应用领域(如语音识别、机器翻译、情感分析等)
-
自然语言处理的核心挑战与技术瓶颈
-
NLP 的技术栈与工具链(Python、Jupyter Notebook、NLTK、spaCy 等)
-
NLP 与前端开发的结合点
-
-
NLP 的基本概念与术语
-
语言模型、词嵌入、文本表示
-
语法、语义、语用学概念
-
常见数据结构:词袋模型(Bag of Words)、TF-IDF
-
语言理解与生成
-
语料库与数据集(GLUE、SQuAD、CoNLL 等)
-
语言模型的发展脉络(从 N-gram 到 Transformer)
-
-
NLP 的工程背景与应用场景
-
文本分类、情感分析与舆情分析
-
信息抽取与命名实体识别(NER)
-
机器翻译与跨语言处理
-
聊天机器人与对话系统
-
搜索引擎与智能推荐系统
-
第二部分:自然语言处理基础与核心技术
-
文本预处理与数据清洗
-
文本数据的采集与清洗
-
分词、去除停用词与词形还原
-
拼写纠正与规范化
-
特征工程:提取词汇特征与文本向量化
-
多语言处理(中文分词、日文分词等)
-
数据增强技术(同义词替换、随机插入等)
-
-
词嵌入与文本表示技术
-
传统词表示:词袋模型(BoW)、TF-IDF
-
词向量与词嵌入:Word2Vec、GloVe
-
基于上下文的词表示:ELMo、BERT、GPT
-
如何选择合适的文本表示方法
-
可视化工具(t-SNE、UMAP)
-
动态词嵌入(FastText)
-
-
经典的 NLP 算法与模型
-
朴素贝叶斯分类器
-
支持向量机(SVM)与逻辑回归
-
决策树与随机森林
-
条件随机场(CRF)与隐马尔可夫模型(HMM)
-
模型评估与比较(准确率、召回率、F1 分数等)
-
模型优化技巧(超参数调优、交叉验证等)
-
第三部分:深度学习与 NLP 的结合
-
深度学习基础与 NLP 的结合
-
神经网络基础:感知机、前馈神经网络
-
卷积神经网络(CNN)在 NLP 中的应用
-
循环神经网络(RNN)与长短期记忆(LSTM)
-
注意力机制与 Transformer 架构
-
图神经网络(GNN)在 NLP 中的应用
-
自注意力机制
-
-
预训练模型与迁移学习
-
预训练模型概念:BERT、GPT、T5
-
迁移学习的原理与实践
-
基于预训练模型的 NLP 任务(如文本分类、问答系统)
-
轻量级预训练模型(DistilBERT、ALBERT)
-
领域自适应
-
-
NLP 中的序列标注与生成任务
-
序列标注任务:命名实体识别(NER)、词性标注
-
序列生成任务:文本生成、机器翻译
-
生成对抗网络(GAN)在文本生成中的应用
-
文本摘要(抽取式摘要、生成式摘要)
-
文本纠错
-
第四部分:NLP 的工程化与实践
-
文本分类与情感分析
-
文本分类的基本方法与模型
-
情感分析的工作原理与技术实现
-
多分类与情感倾向分析
-
深度学习在文本分类中的应用(如 CNN、RNN)
-
多标签分类
-
不平衡数据处理(过采样、欠采样等)
-
-
命名实体识别(NER)与信息抽取
-
命名实体识别的定义与常见方法
-
信息抽取:关系抽取与事件抽取
-
基于规则与基于模型的信息抽取技术
-
实体链接
-
事件抽取
-
-
机器翻译与跨语言理解
-
机器翻译的基本原理与模型
-
统计机器翻译(SMT)与神经机器翻译(NMT)
-
句法分析与语法树
-
多语言与低资源语言的处理技术
-
低资源语言翻译
-
实时翻译系统
-
第五部分:对话系统与聊天机器人
-
聊天机器人与对话系统概述
-
对话系统的基础架构与设计原则
-
开放域对话与闭环域对话
-
规则基与生成式对话系统
-
基于深度学习的对话系统
-
语音助手
-
多模态对话系统
-
-
对话系统中的自然语言理解(NLU)与生成(NLG)
-
自然语言理解:意图识别与槽位填充
-
自然语言生成:模板生成与神经生成
-
端到端的对话模型(如 Seq2Seq、Transformers)
-
情感对话生成
-
对话系统的评估方法(BLEU、ROUGE 等)
-
-
多轮对话与上下文管理
-
多轮对话的挑战与技术
-
上下文管理与对话状态追踪
-
增强学习在对话系统中的应用
-
知识图谱在对话系统中的应用
-
第六部分:NLP 的前沿与发展趋势
-
NLP 中的最新技术与研究趋势
-
自监督学习与强化学习
-
多模态学习与跨模态任务
-
增强型语言模型:GPT-3、ChatGPT 与大规模生成模型
-
跨语言模型与跨域模型的研究进展
-
零样本学习与少样本学习
-
可解释性 NLP(LIME、SHAP 等方法)
-
-
NLP 的伦理与社会问题
-
NLP 模型的偏见与公平性
-
数据隐私与保护
-
NLP 模型的可解释性与透明度
-
模型鲁棒性
-
NLP 的社会影响(假新闻检测、内容审核等)
-
第七部分:实战项目与案例分析
-
文本分类与情感分析实战
-
项目背景与需求分析
-
数据预处理与特征提取
-
模型训练与评估
-
性能优化与调参技巧
-
实时情感分析系统
-
-
命名实体识别(NER)实战
-
项目背景与需求分析
-
数据标注与准备
-
使用深度学习进行 NER 任务
-
系统优化与部署
-
领域特定 NER(医疗、法律等)
-
-
对话系统开发实战
-
聊天机器人设计与实现
-
多轮对话的实现与上下文管理
-
部署与优化
-
聊天机器人的用户体验优化
-
多语言对话系统
-
附录
-
常见 NLP 工具与库
-
NLTK、spaCy、Transformers 等
-
Hugging Face 与 OpenAI 的 API 使用
-
GPU 加速工具(CUDA、cuDNN)
-
NLP 开发环境配置(Docker 等)
-
-
NLP 评估标准与方法
-
准确率、召回率、F1 得分等
-
人类评估
-
-
NLP 技术学习资源与参考书单
-
深度学习与 NLP 的经典教材
-
在线学习平台与社区资源(Coursera、Kaggle 等)
-
第一部分:前言与基础知识
-
人工智能与自然语言处理概述
-
人工智能的定义与发展
-
自然语言处理的历史与现状
-
NLP的主要应用领域(如语音识别、机器翻译、情感分析等)
-
自然语言处理的核心挑战与技术瓶颈
-
NLP 的技术栈与工具链(Python、Jupyter Notebook、NLTK、spaCy 等)
-
NLP 与前端开发的结合点
-
1. 人工智能与自然语言处理概述
1.1 人工智能(AI)的定义与发展
我们生活在一个充满智能机器的时代,人工智能(AI)不再是科幻电影中的虚构故事,它已经成为现实。从你手机里的语音助手到自动驾驶汽车,AI已经悄无声息地进入了我们的日常生活。那么,什么是人工智能呢?
狭义与广义:
-
狭义 AI:专注于完成特定任务,比如下棋、翻译。
-
例子:AlphaGo 只会下围棋,不会做别的。
-
-
广义 AI:具备人类水平的智能,能完成各种任务。
-
例子:科幻电影中的机器人,比如《钢铁侠》里的贾维斯。
-
打个比方,如果狭义 AI 是一个专才,那广义 AI 就是一个全才,样样精通!
定义:
人工智能,顾名思义,就是让机器拥有类似人类的智能。这种智能可以是模仿、推理、学习,甚至是解决问题。例如,AI可以像我们一样识别物体,理解语言,甚至写文章!在计算机科学中,AI的核心目标是让机器通过数据学习,从而模仿人类的认知过程并做出决策。
总而言之,人工智能(AI)是让机器像人类一样思考、学习和行动的技术。简单来说,就是让机器变得“聪明”。
例子:
-
语音助手:比如 Siri 和小度,它们能听懂你的话并做出回应。
-
推荐系统:比如抖音会根据你的喜欢推荐你喜欢的❤️Vlog。
-
自动驾驶:比如特斯拉的汽车能自己开上路。
发展历程:
人工智能的历史其实是一段充满曲折与惊奇的“奋斗史”。从1956年达特茅斯会议上,AI这个名字被首次提出,到如今的深度学习与大数据革命,AI经历了“高峰-低谷-高峰”的过程。早期,AI研究过于理论化,缺乏实际应用,但随着计算能力的提升,尤其是GPU的应用,AI才迎来了爆发式发展。
具体历程:
第一阶段:规则-based AI(1950s-1980s)
-
特点:机器按照预设的规则运行,依赖人工编写的逻辑和规则。
-
核心技术:专家系统、符号逻辑、规则引擎。
-
例子:
-
早期象棋程序:比如 1950 年代的“西洋跳棋程序”,它只能按照固定的规则下棋。
-
医疗诊断系统:比如 MYCIN,它通过规则库诊断细菌感染并推荐抗生素。
-
-
如果规则-based AI 是一个机器人,那它一定是一个“死板”的机器人,只会按部就班!你让它往东,它绝不会往西,但如果你让它处理规则之外的情况,它可能会直接“死机”!
第二阶段:统计机器学习(1990s-2010s)
-
特点:机器从数据中学习规律,基于统计学方法进行预测和决策。
-
核心技术:朴素贝叶斯、隐马尔可夫模型(HMM)、条件随机场(CRF)。
-
例子:
-
垃圾邮件过滤器:通过学习大量邮件数据,判断哪些是垃圾邮件。
-
语音识别:比如早期的语音输入法,通过统计模型识别语音内容。
-
机器翻译:比如谷歌翻译的早期版本,基于统计模型进行翻译。
-
-
如果统计机器学习是一个学生,那它一定是一个“勤奋”的学生,通过大量练习来提高成绩!但它也有点“死脑筋”,如果遇到没见过的问题,可能会手足无措。
第三阶段:深度学习(2010s-现在)
-
特点:机器通过多层神经网络学习复杂的模式,能够处理非结构化数据(如图像、文本、语音)。
-
核心技术:卷积神经网络(CNN)、循环神经网络(RNN)、Transformer、自注意力机制。
-
例子:
-
AlphaGo:通过深度学习击败世界顶级围棋选手。
-
图像识别:比如人脸识别、自动驾驶中的物体检测。
-
-
如果深度学习是一个天才,那它一定是一个“天赋异禀”的天才,看一眼就能学会!但它也有点“娇气”,需要大量的数据和算力来“喂养”,否则可能会“罢工”。
第四阶段:强化学习(2010s-现在)
-
特点:机器通过试错学习最优策略,适合动态决策问题。
-
核心技术:奖励机制、策略优化、环境模拟、Q-learning、深度 Q 网络(DQN)。
-
例子:
-
游戏 AI:比如 AlphaStar(星际争霸 AI)、OpenAI Five(Dota 2 AI)。
-
机器人控制:比如让机器人学会走路或抓取物体。
-
自动驾驶:通过强化学习优化驾驶策略。
-
-
如果强化学习是一个运动员,那它一定是一个“不断尝试”的运动员,通过无数次失败最终取得成功!但它也有点“固执”,可能会在同一个地方跌倒很多次才学会避开。
第五阶段:生成模型(2010s-现在)
-
特点:机器生成新数据(如图像、文本、音乐),适合创造性任务。
-
核心技术:生成对抗网络(GAN)、变分自编码器(VAE)、扩散模型(Diffusion Models)。
-
例子:
-
图像生成:比如 DALL·E 生成逼真的图像。
-
文本生成:比如 ChatGPT 生成流畅的文本。
-
音乐生成:比如 AI 生成交响乐或流行歌曲。
-
-
如果生成模型是一个艺术家,那它一定是一个“创意无限”的艺术家,能创造出你从未见过的作品!但它也有点“任性”,生成的结果有时会让人哭笑不得。
第六阶段:多模态学习(2020s-现在)
-
特点:机器同时处理多种类型的数据(如文本、图像、语音),实现跨模态理解。
-
核心技术:多模态 Transformer、跨模态预训练模型。
-
例子:
-
图文生成:比如根据文字描述生成图像(DALL·E)。
-
视频理解:比如分析视频中的语音、文字和图像内容。
-
虚拟助手:比如同时理解语音指令和图像输入。
-
-
如果多模态学习是一个全能选手,那它一定是一个“多才多艺”的选手,既能画画又能唱歌,还能写文章!但它也有点“贪心”,总想同时做好所有事情。
思考:
想象一下,我们的大脑就像一台超级计算机,它通过神经元连接进行信号传递,类似于AI中的“神经网络”。你看,AI的发展其实跟我们人类大脑的结构有很多相似之处。所以,当你在学习AI时,别忘了用“人类大脑”的方式来理解它,这样可能会更容易哦!
1.2. 自然语言处理的历史与现状
自然语言处理(NLP)的定义
自然语言处理,简称NLP,是AI的一个分支,专注于让机器理解、生成和处理我们日常使用的语言。无论是中文、英文还是其他语言,NLP的目标就是让计算机像我们一样理解和使用语言。你有没有发现,越来越多的应用程序开始理解我们的指令?“嘿,Siri,今天天气怎么样?”“Hey Siri,帮我订一张电影票。”这些对话其实就是NLP技术在背后默默工作。
总之,NLP 是 AI 的一个分支,专注于让机器理解和生成人类的自然语言。简单来说,就是让机器“听懂人话”。
例子:
-
机器翻译:比如谷歌翻译能把英文翻译成中文。
-
情感分析:比如分析社交媒体上的评论是正面还是负面。
-
聊天机器人:比如淘宝客服机器人能回答你的问题。
比如说,如果 NLP 是一个翻译官,那它一定是世界上最忙的翻译官,每天要处理无数种语言!
NLP的核心问题:
语言,特别是人类的自然语言,充满了模糊性、歧义性和多样性。计算机理解人类语言有时就像我们试图理解一位外语老师说的方言——不那么容易!例如,词语“银行”可以指的是“金融机构”,也可以指“河岸”,在不同的语境下,它的意思完全不同。这就是NLP需要面对的挑战之一——语境理解。
NLP的历史:
自然语言处理的历史可以追溯到1950年代。当时,AI的奠基人艾伦·图灵提出了一个著名的问题——“机器能思考吗?”,他甚至设计了“图灵测试”,来衡量机器是否能像人类一样进行智能对话。然而,最初的NLP系统都是基于规则的,它们需要通过大量的人工规则来理解语言。这些系统像是程序员在给机器编写复杂的字典——效率低,且适应性差。
到了20世纪90年代,统计方法进入了NLP领域,带来了革命性的变化。基于大数据和概率统计的模型能够自动从大量的文本数据中学习规律,不再依赖手工编写的规则。这时,机器翻译系统的表现有了飞跃性的提升,语音识别、情感分析等技术也开始应用于实际。
NLP的发展历程:
NLP起源
-
1950s:图灵测试
-
图灵提出,如果机器能通过对话让人误以为是人类,那它就具备智能。
-
如果图灵测试是一个考试,那 NLP 就是考生的语言科目,必须得高分才能通过!
-
-
1960s:规则-based NLP
-
机器通过语法规则处理语言。
-
例子:早期的机器翻译系统。
-
如果规则-based NLP 是一个翻译官,那它一定是一个“死板”的翻译官,只会按字典翻译!
-
NLP黄金时代
-
1990s:统计 NLP
-
机器从大量文本数据中学习语言规律。
-
例子:垃圾邮件过滤器、搜索引擎。
-
如果统计 NLP 是一个学生,那它一定是一个“勤奋”的学生,通过大量阅读来提高语言能力!
-
-
2000s:机器学习 NLP
-
机器通过算法(如 SVM、决策树)处理语言。
-
例子:情感分析、文本分类。
-
如果机器学习 NLP 是一个厨师,那它一定是一个“创新”的厨师,用新方法(情感分享、文本分类等)做出美味佳肴!
-
NLP的现代发展
-
2010s:深度学习 NLP
-
机器通过神经网络(如 RNN、LSTM、Transformer)处理语言。
-
例子:BERT、GPT、ChatGPT。
-
如果深度学习 NLP 是一个天才,那它一定是一个“天赋异禀”的天才,看一眼就能学会!
-
-
2020s:大规模预训练模型
-
机器通过海量数据预训练,然后在特定任务上微调。
-
例子:GPT-3、ChatGPT。
-
如果预训练模型是一个学霸,那它一定是一个“全能”的学霸,什么科目都能考高分!
-
NLP的现状与挑战
-
现状:
-
NLP 已经广泛应用于语音助手、机器翻译、情感分析等领域。
-
预训练模型(如 BERT、GPT)成为主流。
-
-
挑战:
-
语言歧义:机器如何理解“银行Bank”是金融机构还是河岸?
-
数据稀缺:某些语言或领域的数据非常少。
-
伦理问题:如何避免 AI 的偏见和滥用?
-
注:Bank:银行,在英文语境中是多义词,指银行,库,一排,一系列,河岸,边坡等;
NLP的现代技术:
如今,深度学习技术成为了NLP领域的主流。通过神经网络,尤其是Transformer模型(例如BERT、GPT等),NLP取得了突破性的进展。机器已经能够理解语言的上下文,生成流畅的文本,甚至进行对话交流。例如,你可能听说过的ChatGPT,就是基于这种技术。它不仅能根据提示生成高质量的文本,还能进行多轮对话,跟人类交流得越来越像。
AI 和 NLP 的关系:
AI 是大脑,NLP 是语言能力:
-
AI 负责整体的智能,而 NLP 负责语言相关的任务。
-
比如,AI 可以识别图像、玩游戏,而 NLP 专门处理文本和语音。
打个比方,如果 AI 是一个全能运动员,那 NLP 就是它的语言教练,专门教它如何“说话”!
思考:
你有没有想过,NLP的进步其实就像我们理解世界的方式一样?小时候,我们通过记单词卡片、背语法规则来学语言,但随着时间的推移,我们通过与他人的对话、通过不断的实践,学会了如何灵活应对不同的语言环境。机器的语言学习也是类似的——从死记硬背的规则,到模仿和实践,再到最终的理解和生成。
问题引导:
- 为什么NLP的进展需要依赖大数据?你能举个例子,说明没有足够数据支持的模型会遇到哪些问题吗?
- 深度学习在NLP中的应用有哪些优势?你觉得未来NLP技术会如何改变我们的生活方式?
1.3. NLP的主要应用领域
日常应用:
- 语音助手(Siri、Alexa、Google Assistant):这些应用通过语音识别技术和NLP解析我们的指令,进行自然对话。
- 智能客服与聊天机器人:在网上购物、银行咨询等场合,很多客服已经由机器代替,它们可以理解并回应客户的需求。
- 情感分析:通过分析社交媒体上的评论,NLP可以帮助公司了解公众情绪,改进产品或服务。
企业应用:
- 文档处理与信息抽取:例如,通过NLP提取合同中的关键信息,帮助法律工作者快速审查。
- 机器翻译:像Google翻译、DeepL等,能实时将不同语言的文本进行翻译,促进全球交流。
- 搜索引擎优化:搜索引擎通过分析关键词与语义匹配,给出相关性更高的搜索结果。
有趣的故事:
记得小时候,我们都曾尝试过用字典查找单词,但当我们面对复杂的句子结构时,字典似乎帮不上什么忙。而现在的NLP技术,不仅能理解单词的含义,还能抓住句子中的隐含信息。例如,当你问“昨天下雨了么?”NLP不仅要识别“昨天下雨”这几个词,还要理解你是在询问天气情况。这种能力的提升,正是现代NLP技术带来的巨大进步。
1.4. 自然语言处理的核心挑战与技术瓶颈
核心挑战之一:语言的模糊性
自然语言的表达充满了模糊性和歧义性,这对于机器理解来说是一个巨大挑战。让我们从一个简单的例子开始:
例子:
“我去银行。”
这个句子看似简单,但如果机器要理解它,却有两个可能的解释:
- 你去的是一个金融机构(银行)。
- 你去的是河边的岸。
这就是语言的歧义性。机器需要通过上下文来推断正确的含义,才能做出正确的处理。
问题引导:
- 你觉得为什么人的语言理解能力如此强大,而计算机却很难理解这些歧义?是不是因为计算机缺乏像人类一样的生活经验与语境推理能力?
问题:为什么“银行”这个词会让机器困惑?
-
在句子“他去了银行”中,“银行”可以指金融机构,也可以指河岸。机器如何知道是哪个意思?
解答:
-
上下文理解:机器需要通过上下文来判断词义。例如,“他去了银行取钱”中的“银行”显然是金融机构。
-
词向量技术:通过词嵌入(如 Word2Vec、BERT),机器可以学习到“银行”在不同上下文中的不同含义。
-
如果机器把“银行要倒闭了”理解成“河岸要塌了”,那可就闹笑话了!
核心挑战之二:上下文理解
自然语言的真正含义通常依赖于上下文。举个简单的例子:
例子:
"他吃了一碗面,面非常好吃。"
这里,“面”指的是食物,但如果你只是看单个词汇,“面”也可以指脸,或者其他东西。上下文决定了词汇的真正含义。
对于机器来说,上下文理解是一个必须解决的问题。早期的NLP模型往往只关注单词的含义,但现在,深度学习模型已经逐渐能够理解上下文中的词汇之间的关系,从而更好地理解语言的含义。
故事:
有一个短视频上的段子,一个小朋友和妈妈一起吃面,小朋友用筷子夹起面条🍜,从面条中间开始吃。于是小孩的母亲就说:“宝贝,从头上吃!”。小孩一脸懵逼,犹豫了几秒后,还是把面夹起放在自己的小脑袋顶上,大人对此哭笑不得。你们看曾经的人工智能是不是很像人类的小时候,也对语言的上下文没有概念,只是单从字面上理解?
核心挑战之三:语言的多样性与变化
每种语言都有自己的规则、结构和习惯,而每种语言的方言、俚语、惯用语等又使得语言呈现出多样性。例如,“啥子”在四川话中表示“什么”,但其他地方的人可能完全听不懂。
机器如何处理不同语言、不同文化背景下的语言?语言的多样性与变化就是NLP面临的又一大挑战。
技术瓶颈:
尽管深度学习和大数据的出现大大推动了NLP技术的发展,但仍然存在一些技术瓶颈:
- 数据瓶颈:大规模的标注数据集仍然稀缺。尤其是对某些低资源语言,获取足够的训练数据非常困难。
- 计算资源瓶颈:训练大型深度学习模型需要巨大的计算资源和时间。这对于许多企业或开发者来说,可能是一个障碍。
- 模型泛化能力:即使我们拥有了庞大的数据和计算资源,如何确保模型在面对未知数据时仍然表现良好,也是一个难题。
思考:
你曾经试过“填词游戏”吗?比如:“我昨天____了一个苹果。” 看似简单,但如果你把“吃”换成“买”,意义就完全不同了。NLP技术要做的,不仅仅是填补空白,而是要理解这些变化,搞清楚真正的语境和用意。
问题引导:
- 为什么NLP在处理不同语言时会遇到更多困难?不同语言之间的差异,是否也影响机器的学习效果?
- 在多语种NLP任务中,你认为最难的部分是什么?如何通过技术手段解决这些问题?
问题:机器如何应对全球数千种语言和方言?
-
例如,中文的“你好”和法语的“Bonjour”都是问候语,但机器如何识别和处理?
解答:
-
跨语言模型:如 mBERT(多语言 BERT),可以同时处理多种语言。
-
低资源语言处理:通过迁移学习,将高资源语言(如英语)的知识迁移到低资源语言(如斯瓦希里语)。
-
比如机器把“Bonjour”翻译成“好日子”,那它可能需要多学几门外语!
1.5. NLP 的技术栈与工具链
技术栈概述:
在NLP的世界里,技术栈就像是一套完整的工具工具箱,它帮助我们从零开始一步步构建自然语言处理应用。NLP技术栈通常包括以下几个重要部分:
-
数据预处理:这一步是任何NLP任务的第一步,目的是对原始文本数据进行清洗、规范化和转化。常见的工具有:
- NLTK(Natural Language Toolkit):一个强大的Python库,提供了许多用于处理语言的工具,如分词、词性标注等。
- spaCy:一个高效且易用的NLP库,支持文本的处理、词性标注、命名实体识别等任务。
- TextBlob:适合入门的NLP库,支持简单的文本处理和情感分析等任务。
-
特征提取与向量化:机器学习需要将文本转化为数字格式,常用的向量化方法有:
- TF-IDF(Term Frequency-Inverse Document Frequency):一种衡量词语重要性的常见方法。
- Word2Vec、GloVe:通过训练大规模语料库生成的词嵌入模型,使得词语具有连续向量表示,能够捕捉词与词之间的语义关系。
-
模型训练与推理:NLP的核心任务是模型的训练和推理。常用的机器学习和深度学习框架包括:
- scikit-learn:经典机器学习库,适合处理文本分类、聚类等任务。
- TensorFlow / PyTorch:深度学习框架,支持搭建复杂的神经网络模型,如RNN、LSTM、Transformer等。
- Hugging Face Transformers:一个非常流行的库,专注于Transformer模型,支持BERT、GPT、T5等大规模预训练语言模型的应用。
-
评估与调优:模型评估与调优是NLP应用成功的关键。常见的评估指标包括:
- 准确率、召回率、F1分数:常用于文本分类任务的评估。
- BLEU(Bilingual Evaluation Understudy):常用于机器翻译任务的评估指标。
编程语言:Python
-
为什么选择 Python?
-
Python 简单易学,拥有丰富的 NLP 库和工具。
-
例如,NLTK、spaCy、Transformers 等库都是 Python 的“明星产品”。
-
-
如果 Python 是一个厨师,那它一定是米其林大厨,擅长烹饪各种 NLP 美食!
开发环境:Jupyter Notebook
-
为什么选择 Jupyter Notebook?
-
Jupyter Notebook 是一个交互式开发环境,支持边写代码边看结果。
-
特别适合数据分析和模型训练。
-
-
如果 Jupyter Notebook 是一个笔记本,那它一定是魔法笔记本,让你的代码瞬间变成结果!
常用库与工具
-
NLTK(Natural Language Toolkit)
-
功能:分词、词性标注、句法分析等。
-
适合初学者,但性能较慢。
-
-
spaCy
-
功能:高效的 NLP 处理,支持多语言。
-
适合工业级应用。
-
-
Transformers(Hugging Face)
-
功能:提供预训练模型(如 BERT、GPT),支持各种 NLP 任务。
-
适合高级用户。
-
-
如果 NLTK 是自行车,spaCy 是摩托车,那 Transformers 就是跑车,速度快但需要老司机!
思考:
有没有想过,NLP的工具和技术栈就像你在厨房里做菜的工具一样?比如你有了切菜刀(文本预处理工具),锅碗瓢盆(特征提取方法),以及火候掌握(模型调优),这些工具组合起来才能做出一道美味的“自然语言大餐”!
1.6. NLP 与前端开发的结合点
自然语言处理与前端开发的结合点,已经成为现代Web开发中的一个热点。随着NLP技术的普及,越来越多的前端应用加入了语音识别、智能客服、文本分析等功能,给用户带来了更加智能化的交互体验。
结合点一:智能搜索与推荐系统
在传统的Web搜索中,用户通常需要输入关键词来查找信息。而通过NLP,系统可以理解用户输入的自然语言查询,并根据语义进行智能推荐。例如,在电商网站中,用户可以直接输入“帮我找一双适合夏天穿的运动鞋”,而不仅仅是输入“运动鞋”。
前端开发者需要掌握如何与后端的NLP模型进行交互,处理用户的自然语言请求,并将结果呈现给用户。
结合点二:语音识别与语音助手
语音识别是NLP与前端的另一个结合点。用户通过语音输入,前端通过JavaScript与语音识别API(如Web Speech API)结合,将语音转化为文本,然后通过NLP处理语音文本,完成语义理解。
例如,智能家居控制系统,用户可以说“打开客厅灯”,前端将语音信号转换为文本后,NLP引擎解析出“打开”和“客厅灯”这两个关键动作和目标对象,然后通过API控制家居设备。
结合点三:文本生成与交互式聊天机器人
在前端开发中,聊天机器人或虚拟助手的集成是一个非常常见的需求。前端工程师需要使用NLP技术来处理用户输入的对话,并将机器生成的响应展现出来。
现代的聊天机器人已经不仅仅是基于简单规则的问答系统,它们能够基于上下文、情感分析等因素,给出更符合用户需求的回答。NLP帮助前端开发者提升这些聊天机器人或语音助手的智能化水平,提供更自然、更流畅的用户体验。
举例:
智能前端应用
-
问题:前端如何通过调用 NLP 服务进行文本分析?
-
例如,用户在输入框中输入一段文字,前端如何实时分析情感?
-
-
解答:
-
API 调用:前端通过 RESTful API 调用后端的 NLP 服务。
-
实时反馈:使用WebSocket或Ajax或长轮询技术,实现实时情感分析。
-
如果前端是一个翻译官,那 NLP 就是它的语言老师,教它如何理解用户的语言!
-
语音识别与语音助手
-
问题:如何在前端实现语音识别功能?
-
例如,用户通过语音输入命令,前端如何识别并执行?
-
-
解答:
-
Web Speech API:浏览器原生支持的语音识别接口。
-
NLP 服务:将语音转换为文本后,调用 NLP 服务进行语义理解。
-
如果语音识别是一个魔术师,那 NLP 就是它的助手,把语音变成文字,再把文字变成行动!
-
聊天机器人与对话系统
-
问题:如何在前端实现一个聊天机器人?
-
例如,用户在网页上与机器人聊天,机器人如何理解并回应?
-
-
解答:
-
前端界面:使用 React 或 Vue.js 构建聊天界面。
-
后端服务:调用 NLP 服务进行意图识别和对话管理。
-
如果聊天机器人是一个相声演员,那 NLP 就是它的剧本,教它如何逗乐用户!
-
数据可视化与 NLP 结合
-
问题:如何将 NLP 的结果可视化?
-
例如,将情感分析的结果用图表展示。
-
-
解答:
-
ECharts 或 D3.js:用于绘制图表。
-
NLP 结果处理:将情感分析的结果转换为可视化数据。
-
如果数据可视化是一个画家,那 NLP 就是它的颜料,帮它画出美丽的图表!
-
思考:
想象一下,如果你用“发条扭扭”的方式操作网站,这会不会有点“机械”?但是,借助NLP技术,你可以通过自然语言直接与网站交互,“就像和朋友聊天”一样流畅!这就是未来的智能交互。
总结
通过这一部分的学习,你不仅了解了 NLP 的定义、发展历程、应用领域及其核心挑战和技术瓶颈,还了解了NLP的技术栈与工具链,以及如何将 NLP 与前端开发结合。
2. NLP 的基本概念与术语
在进入更复杂的NLP任务之前,我们必须理解一些基本的概念和术语。这些是理解整个NLP领域的基石,了解它们,就像我们学编程时首先要理解变量、数据类型、循环结构一样。
2.1 语言模型、词嵌入、文本表示
语言模型:
首先,咱们得搞明白什么是“语言模型”。想象你正在和朋友聊天,你会根据之前的对话内容猜测他们接下来可能说什么,对吧?语言模型就像是一个“聊天助手”,它通过计算大量文本数据中的词语概率,来预测下一个词语的出现概率。最简单的模型可以用“n-gram”模型来解释——它基于前面“n”个词来预测下一个词。
例子:
假如我们有句子“我今天吃了一个__”,那么语言模型就会根据前面的词“我今天吃了一个”来猜测下一个最可能出现的词是“苹果”还是“香蕉”,甚至是“午餐”。问题引导:你觉得计算机如何通过大量文本数据来“学习”这个概率呢?是不是也像我们通过经验来猜测对话内容一样?
词嵌入(Word Embeddings):
接下来是“词嵌入”,这是NLP中非常重要的一部分。简单来说,词嵌入就是将一个个词转化为向量(数字数组),从而使计算机能够“理解”它们的语义。这种转化方式能够让计算机不仅能看到词的表面,而是能“感知”这些词之间的关系。
有趣的事实:
词嵌入有时候能“暴露”语言的奇妙之处。比如,在Word2Vec模型中,“王”减去“男人”加上“女人”得到的结果竟然是“女王”!这可不是魔法,是数学的神奇。
常见的词嵌入算法包括:
- Word2Vec:由Google提出,通过捕捉上下文中词语的关系来生成词向量。
- GloVe:与Word2Vec类似,不过它通过统计词语之间的共现关系来生成词向量。
文本表示:
文本表示是指将文本(如一段话、一篇文章等)转化为机器可以处理的数字形式。除了词嵌入,我们还有一些其他常见的文本表示方法:
- One-hot编码:每个词用一个非常大的向量表示,向量中的一个位置标记该词的出现。这个方法非常简单,但并不能捕捉词之间的关系。
- TF-IDF:这是一种非常经典的文本表示方法,它通过计算词频和逆文档频率来衡量词语的重要性,稍后会更详细讨论。
2.2 语法、语义、语用学概念
NLP中有三个非常重要的领域,分别是语法、语义和语用学。虽然它们听起来有点像“高大上的学科”,但它们其实是从不同角度来研究语言的结构与含义。
语法(Syntax):
语法主要研究的是词语如何组合成句子。它关心的是“结构”。比如,英语语法中我们有主语、谓语、宾语的基本结构,中文里也有类似的语法规则。语法分析的目标就是理解文本中词语的结构关系。
例子:
“猫抓老鼠”是一个有效的句子,而“抓猫老鼠”就不太符合语法规则,计算机需要能够识别这些差异。
语义(Semantics):
语义分析则关注句子的意义,而不仅仅是它的结构。它试图揭示词语和短语背后的深层次含义。例如,“我很喜欢苹果”中的“苹果”指的是一种水果,还是手机品牌?我们通过语境来判断。
有趣的小贴士:
语义学就像一个侦探,时刻准备揭示隐藏在语言背后的真相。
语用学(Pragmatics):
语用学更关注语言的实际使用,特别是语言背后的意图。它研究的是我们说话时,如何根据语境来理解词语的意思。例如,当一个人说:“你能关一下窗户吗?”实际上是在请求,而不是单纯的陈述。
有趣的思考:
你是否曾经在对话中用了一些隐晦的表达,想让对方自己理解你的意图?这种“隐晦”表达正是语用学研究的重点。
2.3 常见数据结构:词袋模型(Bag of Words)、TF-IDF
词袋模型(Bag of Words, BOW):
词袋模型是NLP中最简单的文本表示方式,它的基本思想是:将文本中的每个词看作一个“袋子”,只关心词的出现与否,而忽略它们在文本中的顺序。
例子:
对于句子“我喜欢苹果”,词袋模型将其表示为“我、喜欢、苹果”这三个词的集合,而不考虑它们的顺序。
这种模型虽然简单,但是非常有效,尤其是在文本分类等任务中。不过,词袋模型的一个主要缺点是它无法捕捉词语的上下文关系,也不能反映词语的语法和语义信息。
TF-IDF(Term Frequency-Inverse Document Frequency):
TF-IDF是一种改进的文本表示方法,它不仅关注单个词在文档中的出现频率(TF),还考虑该词在所有文档中的重要性。具体来说,TF表示一个词在文档中出现的频率,而IDF则是一个词在所有文档中出现的稀有度。通过这种方法,TF-IDF能够减少常见词(如“的”、“和”等)对模型的影响。
公式:
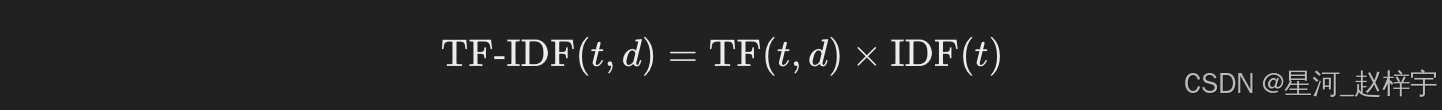
其中,TF(t,d) 是词 t 在文档 d 中出现的频率,IDF(t) 是词 t 的逆文档频率(逆文档频率指词频稀缺度)。
TF-IDF的优势是它能够有效地突出重要的词汇,特别是在信息检索、文档分类等任务中非常有效。
我们今天讲了很多基础的概念。虽然听起来有点“重口味”,但是这些都是NLP的基础知识,没有它们,我们就像是没有地图的探险者,怎么可能走得远呢?
思考题:
- 你能举出一个词袋模型不能正确理解的例子吗?例如,词袋模型如何无法识别“我喜欢苹果”和“苹果喜欢我”之间的差别?
- 你认为TF-IDF方法有哪些优缺点?为什么在某些任务中,它能帮助提升效果,而在其他任务中可能不太适用?
记住,NLP的目标不仅仅是让计算机“看懂”文本,更是让它能够理解文本的深层含义,并能进行有效的推理与应用。希望通过这部分内容的学习,大家已经对NLP的核心概念有了一个初步的了解,接下来我们会进入更具体的技术和方法,带领你们走向更高级的NLP世界!
2.4 语言理解与生成
在自然语言处理的世界里,语言理解(Language Understanding, LU)和语言生成(Language Generation, LG)是两个关键领域。理解和生成是NLP系统与我们人类交流的桥梁,它们就像是我们与计算机沟通时的“翻译官”和“作家”。
语言理解(LU / NLU):
语言理解指的是计算机能够理解和解释输入的自然语言文本。它不仅仅是“看懂”句子表面,而是深入到其中的含义。想象一下,当你问Siri或小度“明天的天气怎么样?”时,它并不只是直接给你“明天的天气”几个字,而是理解到你想要了解天气预报,并根据你的提问给予准确的答案。
语言理解的挑战:
- 歧义性:人类语言常常存在多义词或者模糊表达。比如,“银行”既可以指金融机构,也可以指河岸。
- 上下文依赖:理解某句话的意义,往往需要了解前后文。
- 隐含信息:有时候我们说的并不是表面意思,而是隐藏的意图,比如“这个房间有点冷”其实是在请求别人开暖气。
语言生成(LG / NLG):
语言生成则是指计算机根据某些输入生成自然语言文本的能力。就像我现在给你讲解这些内容,计算机生成的文本需要能在语法、语义和语境上都符合人类的表达方式。以GPT系列模型为例,它能根据你给出的提示生成流畅、合理的回答。
语言生成的挑战:
- 流畅性与连贯性:计算机生成的文本需要像人类一样流畅自然,避免出现“卡顿”或语无伦次的情况。
- 多样性与一致性:同一个问题可能有多个回答,计算机生成的内容要多样而不失一致性。
- 创造性:在某些任务中,语言生成不仅要合理,还需要富有创意,例如生成诗歌、故事或对话。
对比与联系:
理解和生成是NLP中的两个侧面,缺一不可。语言理解为生成提供了上下文和信息,而语言生成则是理解的输出和反映。它们是相辅相成的,就像是我们在与他人对话时,既要理解对方的意图,也要通过合适的语言表达自己的想法。
2.5 语料库与数据集(GLUE、SQuAD、CoNLL 等)
NLP是数据驱动的学科,语料库和数据集是其核心资源。它们像是训练NLP模型的“食物”,没有丰富的语料库和数据集,我们就无法训练出强大的模型。
什么是语料库与数据集?
语料库指的是大量的文本数据,通常包括各种类型的文章、对话、故事等。通过分析这些语料库,计算机能够学习到语言的结构、语法、词汇等特征。而数据集则是针对特定NLP任务(如情感分析、问答系统等)收集和整理的标注数据,提供了输入和期望输出的对应关系。
常见的NLP数据集:
- GLUE(General Language Understanding Evaluation):
GLUE是一个大型的NLP基准测试,它包含了多个任务(如文本分类、推理、问答等),用来评估模型在不同自然语言理解任务中的表现。GLUE的出现推动了NLP领域模型的快速发展,它成为了评估NLP模型的一项“标准”。
有趣的事实:
GLUE的目标并不仅仅是提供一个统一的测试,而是通过多个任务考察一个模型在不同语言理解场景下的能力。它是对模型的全面“体检”。
- SQuAD(Stanford Question Answering Dataset):
SQuAD是一个用于问答系统的经典数据集,包含了大量的文章和基于这些文章的问题。SQuAD的任务是让模型根据给定的段落回答特定的问题。它的挑战性在于,问题的答案可能不直接出现在原文中,而需要模型通过推理来生成答案。
思考题:
你认为SQuAD数据集如何帮助提升机器的推理能力?它是如何帮助模型从表面信息走向深层理解的?
- CoNLL(Conference on Natural Language Learning):
CoNLL数据集主要用于命名实体识别(NER)和句法分析等任务。它包含了大量的标注数据,能够帮助模型识别文本中的人名、地点、组织等实体,并理解它们之间的关系。
问题引导:
你能想到日常生活中哪些实际应用需要用到命名实体识别吗?比如,智能助手如何根据你的指令提取地点、人物等信息?
这些数据集不仅是学术研究的重要资源,也是工业界开发更高效、更智能NLP应用的基础。
2.6 语言模型的发展脉络(从 N-gram 到 Transformer)
N-gram模型:
在NLP的早期,N-gram模型成为了许多任务中的标准方法。N-gram模型非常简单,它通过统计文本中连续N个词的共现来预测下一个词语。例如,使用2-gram模型时,“我 爱 编程”会被拆分成“我 爱”和“爱 编程”这两个词对。
N-gram的局限性:
尽管N-gram模型非常简单,但它忽略了更长距离的上下文信息,无法有效捕捉词语之间的长程依赖。
神经网络模型:
随着深度学习的兴起,NLP领域开始逐渐转向神经网络模型。通过训练深度神经网络,模型能够自动学习文本中的复杂模式和语义关系。基于循环神经网络(RNN)和长短时记忆网络(LSTM)的模型开始被广泛应用。
问题引导:
为什么RNN和LSTM能在一定程度上解决N-gram模型中的“短期记忆”问题?它们如何通过记忆单元捕捉长距离依赖?
Transformer模型:
直到2017年,Google提出了Transformer模型,它彻底改变了NLP的格局。与RNN不同,Transformer采用了自注意力机制(Self-Attention),它能够在处理每个词时关注到文本中其他所有词的关系,不需要依赖传统的循环结构。这使得Transformer能够并行处理文本,并且在捕捉长程依赖和语境信息上表现得更加出色。
有趣的事实:
Transformer的出现就像是给NLP领域加了一颗火箭引擎,它大大提高了模型训练和推理的速度,同时提升了模型的精确度。BERT、GPT等模型都是基于Transformer架构的。
BERT与GPT的出现:
- BERT(Bidirectional Encoder Representations from Transformers):BERT是一种预训练的双向语言模型,通过大量文本数据预先训练,然后应用于具体任务,如情感分析、问答等。
- GPT(Generative Pre-trained Transformer):GPT则侧重于生成任务,像聊天机器人、文本生成等,GPT系列的强大表现让它成为了当前NLP的标杆。
思考题:
你觉得Transformer的自注意力机制是如何在文本中“找到”最相关的信息的?为什么它能在NLP任务中取得如此大的成功?
总结
通过这一章节的学习,我们了解了NLP的基本概念,如:语言模型、词嵌入、文本表示、语法、语义和语用学等,学习NLU、NLG等概念,认识了语料库和数据集在NLP中的重要性,并且回顾了语言模型从N-gram到Transformer的发展历程。每一次技术的突破都为我们打开了新的大门,让我们能够更深入地理解和生成自然语言,推动了NLP的快速发展。
思考题:
- 你认为未来NLP的发展会朝着哪些方向前进?会有哪些新的技术出现?
- 如果你要为一个特定的任务(比如自动摘要)设计一个NLP模型,你会选择哪些数据集和模型架构呢?
3. NLP 的工程背景与应用场景
-
文本分类、情感分析与舆情分析
-
信息抽取与命名实体识别(NER)
-
机器翻译与跨语言处理
-
聊天机器人与对话系统
-
搜索引擎与智能推荐系统
随着人工智能技术的进步,NLP已成为智能化应用中的重要组成部分。它不仅为计算机带来了理解人类语言的能力,更为我们日常生活中的许多应用提供了巨大的帮助。想象一下,现代的智能助手、推荐系统、甚至翻译工具,都是基于NLP技术来构建的。其核心任务不仅仅是对文本数据进行简单的解析,而是理解文本中的复杂语义、情感、意图,从而作出合适的反应。
从情感分析到机器翻译,再到对话系统,NLP已经渗透到几乎每个互联网产品中。而要实现这些功能,背后涉及的技术不仅仅是复杂的算法,更是人类语言的深刻理解与计算机技术的结合。正因如此,NLP的应用场景也在不断扩展,涉及的领域也越来越广泛。从社交网络到金融分析,从客户服务到多语种跨境电商,NLP为这些领域提供了巨大的技术支持。
在接下来的几个小节中,我们将分别探讨NLP在不同应用中的具体实现。每一个应用场景都蕴含着不同的挑战和技术难题,而这些技术的不断优化与创新,也正推动着NLP技术不断向前发展。
3.1 文本分类、情感分析与舆情分析
文本分类:
文本分类是将文本数据分配到预定义类别的任务,简单来说,就是给定一个文本,NLP模型要判断它属于哪一类。文本分类的应用场景非常广泛,包括垃圾邮件过滤、新闻分类、文章标签生成等。
实例:
假设你在一个新闻网站上浏览新闻,系统会根据新闻内容自动将其分类为“体育”、“娱乐”、“科技”等栏目。这背后就是一个典型的文本分类问题。
情感分析:
情感分析是文本分类中的一种特殊类型,目标是判断文本中所表达的情感倾向,通常是“积极”或“消极”。情感分析在市场营销、品牌管理等领域有着重要的应用。举个例子,当你在社交媒体上发布一条关于某个新产品的评论,系统可以分析评论的情感,帮助企业了解消费者的反馈。
思考:
如果你是企业的产品经理,通过情感分析,你能从客户的反馈中得出什么结论?这对你的产品改进有哪些帮助?
舆情分析:
舆情分析是情感分析的延伸,它不仅仅关注单个文本的情感,还要考虑文本在更大范围内的传播趋势。它分析公众对某个事件、品牌或话题的整体情绪。比如,假设一家公司因发生丑闻而成为舆论焦点,舆情分析可以帮助它实时了解社会舆论的变化,进而调整公关策略。
现实中的应用:
政府机构、企业或媒体公司都非常依赖舆情分析来实时监测公众情绪,尤其是在重大事件发生时,舆情分析能为决策提供重要参考。
文本分类、情感分析与舆情分析的技术挑战:
这些任务虽然在许多实际应用中非常有用,但也面临着一些挑战。比如,文本分类需要模型能够理解上下文,情感分析不仅要识别情绪词汇,还要处理双关语、讽刺等语言现象。舆情分析则要求在大量信息中找出情绪的变化趋势,这需要复杂的时序分析和数据聚合技术。
3.2 信息抽取与命名实体识别(NER)
信息抽取(IE):
信息抽取是指从非结构化文本中提取有价值的信息。这个过程需要识别出文本中的关键信息,如人名、地点、时间、事件等,并将它们组织成结构化数据。信息抽取在新闻报道、法律文件分析、金融数据处理等领域非常重要。
示例:
假设我们有一篇新闻文章,里面提到:“2023年10月1日,特斯拉公司在上海举行了新车发布会。”
通过信息抽取,我们能够从这段话中提取出:
- 日期:2023年10月1日
- 公司:特斯拉
- 地点:上海
- 事件:新车发布会
命名实体识别(NER):
命名实体识别是信息抽取中的一个重要任务,它的目标是识别文本中的命名实体,并将其归类。命名实体通常包括人名、地名、组织名、日期、时间等信息。例如,在一篇新闻报道中,NER可以识别出“阿里巴巴”是一个公司名称,“上海”是一个城市名,“2023年”是一个年份。
NER的应用:
在搜索引擎优化、信息检索、舆情监测等领域,NER都能帮助提高信息的检索精度。例如,用户输入一个问题,“2023年奥运会在哪里举办?”NER可以帮助提取出“2023年”和“奥运会”两个关键信息,进而帮助搜索引擎给出准确的答案。
技术挑战:
尽管NER已经取得了显著进展,但它仍然面临一些挑战。比如,命名实体可能存在多种表示方式,如“微软”可能出现为“Microsoft”或“MS”。此外,新的实体不断涌现,模型需要不断更新来适应新的命名实体。
3.3 机器翻译与跨语言处理
机器翻译(MT):
机器翻译是将一种语言的文本自动翻译成另一种语言的任务。它是NLP领域最具挑战性的问题之一。随着技术的进步,机器翻译已经取得了显著的进展,尤其是基于深度学习的神经机器翻译(NMT)方法,大大提升了翻译的质量。
例子:
你在阅读一篇外文文章时,如果能够使用机器翻译工具直接翻译成你熟悉的语言,那你就能轻松理解文章内容。像Google翻译、百度翻译等工具都利用了NMT技术。
跨语言处理:
跨语言处理不仅仅是翻译,它还包括在不同语言之间的语义理解、文本相似度计算、情感分析等任务。例如,跨语言搜索引擎能够在一个语言环境中检索到用另一种语言发布的信息。
跨语言的应用场景:
假设你需要翻译和分析来自不同国家和语言背景的用户评论,那么跨语言情感分析就可以帮助你分析这些评论的情感倾向,而不管评论的语言是什么。
机器翻译与跨语言处理的技术挑战:
尽管神经机器翻译技术取得了显著的进展,但翻译质量仍然受限于一些挑战。首先是文化差异和习惯表达,这些都影响着翻译的准确性。其次,某些语言的结构差异巨大,这使得直接的机器翻译变得更加困难。
引导思考:
你认为机器翻译和跨语言处理在未来会如何改变我们的沟通方式?在全球化日益加深的今天,NLP技术的这些应用将带来哪些社会变化?
通过本小节的学习,我们了解了文本分类、情感分析、舆情分析、信息抽取、命名实体识别和机器翻译的基本概念和应用场景。这些任务不仅展示了NLP技术在各种领域的实际应用,还揭示了它们在实际工程中面临的技术挑战。无论是在商业领域、政府管理,还是日常生活中,NLP的应用都在不断扩展,带来了巨大的便利和创新机会。
思考题:
- 在文本分类与情感分析的任务中,如何设计一个模型来提高分类准确度?你会如何处理数据中的不平衡问题?
- 机器翻译技术如何能够在未来突破语言和文化的壁垒,达到更高的翻译质量?
希望这部分内容能够帮助大家深入理解NLP技术在实际应用中的复杂性和潜力,也为你今后进行NLP工程实践奠定坚实的基础。
3.4 聊天机器人与对话系统
聊天机器人:
聊天机器人,或者叫“对话机器人”,是基于自然语言处理技术构建的自动化系统,它们能够与用户进行对话,理解用户的意图,并生成相应的回复。你可能已经在许多网站、社交媒体平台或移动应用中遇到过聊天机器人,它们能帮助你快速找到问题的答案,或者引导你完成某个操作。
示例:
当你在某个电商网站上询问客服“今天的优惠是什么?”,一个智能客服可能会立即给你提供一个优惠活动的链接和详细说明,而这就是聊天机器人的一个典型应用。
聊天机器人的工作原理:
聊天机器人的核心技术包括:
- 意图识别: 通过分析用户输入的文本,理解用户想要表达的目的。例如,你在向机器人询问“如何申请退款?”时,机器人的任务是识别出你在询问“退款”这一主题。
- 对话管理: 对话系统需要根据上下文保持对话的连贯性。例如,如果你继续询问“退款的条件是什么?”机器人必须根据前一个问题的背景来回答你,而不是从头开始理解你的问题。
- 自然语言生成: 当机器人确定了用户的意图后,它需要生成自然、流畅的语言来回答用户,确保用户能够清晰地理解。
技术挑战:
- 上下文理解: 对话的上下文对于理解问题至关重要。很多时候,用户并不会一次性说明所有问题,而是通过多轮对话来逐步展开。这就要求聊天机器人能够追踪对话历史,理解上下文。
- 多轮对话: 与单轮问题回答不同,聊天机器人需要处理多轮对话的复杂性,保持对话的一致性和连贯性。
- 情感识别: 现代的聊天机器人不仅要理解用户的问题,还需要识别出用户的情感。例如,用户可能会用不同的语气表达同样的问题:“我该如何申请退款?”和“我现在需要退款,怎么做?”这两者的语气差异就需要机器人做出不同的回应。
引导思考:
你认为现有的聊天机器人能完全替代人工客服吗?它们在“情感理解”和“非标准问题”的处理上可能存在什么局限性?
3.5 搜索引擎与智能推荐系统
搜索引擎:
搜索引擎通过解析用户输入的查询,帮助用户在大量的信息中快速找到所需的内容。虽然大家都知道Google、Bing和百度是常见的搜索引擎,但你是否想过,搜索引擎背后是如何利用NLP技术来解析用户的搜索意图,并迅速返回结果的?
示例:
当你在Google搜索“世界上最高的山是什么?”时,搜索引擎背后会运用NLP技术分析“世界上最高的山”这句话,理解它是一个事实类问题,并在数据库中找到“珠穆朗玛峰”这个答案。
搜索引擎的核心技术:
- 查询理解: 搜索引擎需要理解用户的查询,分析其中的关键字和语法,识别出用户的意图。例如,“纽约的天气”与“天气在纽约”虽然字面不同,但搜索引擎能理解它们的实际含义是一样的。
- 信息检索: 搜索引擎根据查询意图,从大量的网页中检索出最相关的内容。这里涉及到如何评估网页的相关性、重要性以及可信度。
- 排序算法: 搜索引擎通过复杂的排序算法来决定哪些结果应该排在前面,哪些排在后面。这通常涉及到网页的内容质量、外部链接、页面的SEO优化等因素。
智能推荐系统:
智能推荐系统利用用户的行为数据(如点击、浏览、购买历史等)来推测用户的兴趣,进而向用户推荐他们可能感兴趣的内容。如今,Netflix的电影推荐、淘宝的商品推荐、Spotify的音乐推荐都依赖于推荐系统来提高用户体验和满意度。
示例:
当你在Netflix上观看了一部科幻电影,Netflix的推荐系统就会根据你的观看历史推荐一些类似的科幻电影。而这些推荐系统背后的核心技术就是基于自然语言处理和机器学习算法对用户数据的分析。
推荐系统的工作原理:
- 协同过滤: 基于用户历史行为,推荐系统会找出与你兴趣相似的其他用户,并根据这些用户的行为推荐你可能喜欢的内容。比如,你和另一位用户都经常看科幻电影,那么系统就会推荐另一位用户看过的科幻电影。
- 内容推荐: 基于内容的推荐系统通过分析产品、电影、文章等的内容(比如关键词、标签、描述等)来进行推荐。这种方法不依赖于其他用户的行为,而是直接分析内容本身。
技术挑战:
- 个性化推荐的精度: 推荐系统面临的挑战之一是如何提高个性化推荐的精度。过于频繁的推荐可能让用户感到烦恼,过于少的推荐又会让用户错过感兴趣的内容。
- 冷启动问题: 推荐系统需要一定的数据才能为新用户或新项目进行推荐。对于没有历史数据的新用户或新物品,系统如何保证推荐的准确性就是一个难题。
思考:
你如何评价目前的搜索引擎和推荐系统?它们是否能准确捕捉到你的真实需求?你认为在这些系统中,NLP技术能发挥怎样的作用?
到这里,我们已经讨论了NLP在几个关键应用场景中的应用:聊天机器人与对话系统、搜索引擎与智能推荐系统。这些应用场景不仅在日常生活中触手可及,而且它们背后运用了大量复杂而高效的NLP技术。
技术挑战与思考:
这些场景的实现并非易事,涉及到复杂的语义理解、多轮对话、情感分析、个性化推荐等技术。这要求我们在实践中不断创新和优化模型、算法,提升其对上下文的理解能力,减少误差,并适应不断变化的用户需求。
引导思考:
你认为在未来,NLP技术会如何进一步改变我们和计算机的交互方式?你是否能够想象一个完全由AI驱动的客服系统,它能够理解和解决任何问题?
在下一部分,我们将继续深入探讨如何在实际工程中实现这些技术,分析其中的挑战和应对策略。
总结:
在这一节中,我们深入探讨了自然语言处理(NLP)在实际工程中的应用场景。从文本分类到情感分析,再到信息抽取、机器翻译、对话系统和推荐引擎,每一项应用都展示了NLP强大的功能和广泛的应用前景。随着NLP技术的不断进步,我们可以清晰地看到这一领域在多个方向上的发展与创新。让我们结合各个小节的内容,总结出未来的发展趋势。
文本分类、情感分析与舆情分析
在文本分类与情感分析的领域,我们看到了如何通过NLP技术提取文本中的关键信息,帮助企业、政府和其他组织做出更精准的决策。情感分析和舆情分析正在不断提高它们在公共安全、市场研究以及品牌监控中的应用价值。未来,随着情感分析模型的进一步精细化,我们将看到它们能够更加准确地捕捉到复杂的情感色彩,特别是在多语种、多文化的背景下,情感分析的智能化程度将大大提升。
信息抽取与命名实体识别(NER)
NER技术的应用为信息的结构化与智能提取提供了极大的便利,从法律文书的自动分析到医疗记录中的关键信息提取,都离不开这一技术。未来,NER将不仅仅局限于传统的实体识别,随着跨领域知识的融合,它将朝着更精细化的方向发展,能够识别更为复杂的实体关系和背景信息。例如,在医学、法律等高精度领域,NER将变得更加智能、精确。
机器翻译与跨语言处理
机器翻译技术已经经历了从规则翻译到统计翻译,再到神经网络翻译的飞跃。如今,基于深度学习的神经网络机器翻译(NMT)正在引领着翻译的新时代。从Google翻译到实时语音翻译,我们可以看到这一技术的广泛应用。而未来,机器翻译不仅会在语言转换上更加精确,尤其是在长文本、专业术语、跨文化理解等方面,还会融合更多的上下文信息,提供更自然的翻译结果。跨语言处理将不再局限于语言的转换,甚至可能涵盖文化差异、语境理解等方面,极大地提升全球化交流的效率。
聊天机器人与对话系统
随着对话系统和聊天机器人的不断发展,人工智能在客服、智能家居、医疗健康等多个领域的应用变得愈加普遍。从简单的FAQ机器人到复杂的多轮对话系统,NLP技术正在打破人与机器之间的沟通壁垒。未来,聊天机器人将不仅仅在客服领域发挥作用,还将通过集成更多的个性化推荐和情感分析技术,提供更细致、全面的服务。智能对话系统将进一步发展为全能型助手,在处理复杂问题时,不仅能够理解用户的语句,还能从用户的历史行为和情感中提取更多的信息,以做出更加智能、精准的回应。
搜索引擎与智能推荐系统
搜索引擎和推荐系统作为我们日常使用的最重要工具之一,已经深刻地改变了信息的获取方式。通过NLP技术,搜索引擎能够理解复杂的查询,并根据用户的需求提供最相关的答案。同时,推荐系统基于用户的兴趣和行为,不断优化推荐结果。未来,搜索引擎和推荐系统将更加智能化,能够理解用户的隐含需求与个性化偏好。随着多模态学习和深度神经网络的不断进步,搜索引擎和推荐系统将不仅局限于文本数据的处理,还会进一步整合图片、视频、语音等多种数据形式,为用户提供更为丰富和精准的体验。
整体来看,NLP技术在各个应用领域的渗透和拓展正在改变着我们的世界。从文本分类到情感分析,从机器翻译到智能对话系统,每一项技术都在为日常生活、商业决策、社会治理等方面提供创新的解决方案。随着技术的不断进步,我们能够预见未来的NLP应用将更加智能、精准,并能够适应更加复杂的实际场景。
随着深度学习与大数据技术的发展,未来NLP的技术能力将更加趋向于全局智能,不仅仅是“理解”语言,而是能根据复杂的上下文环境来进行动态决策与推理。未来的NLP将不再只是静态的文字处理工具,而是能真正理解、生成、推理、并且在实时对话中与人类进行高度互动的智能系统。
在未来的岁月里,NLP的技术边界将不断突破,应用场景将变得越来越丰富,AI与人类语言的互动将变得更加自然流畅。无论是在企业中帮助做出决策,还是在家庭中提升用户体验,NLP无疑将成为智能时代最具潜力的核心技术之一。
第二部分:自然语言处理基础与核心技术
1. 文本预处理与数据清洗
-
文本数据的采集与清洗
-
分词、去除停用词与词形还原
-
拼写纠正与规范化
-
特征工程:提取词汇特征与文本向量化
-
多语言处理(中文分词、日文分词等)
-
数据增强技术(同义词替换、随机插入等)
在进入深度学习模型、情感分析、机器翻译等复杂的应用之前,我们需要先处理输入的文本数据。你可以把文本预处理看作是烹饪中的“食材准备”环节,只有准备好食材,才能做出美味的佳肴。没有这一步,直接跳入复杂模型,效果可能会大打折扣。
文本数据预处理包括了多个环节,每一个环节都对模型的效果至关重要。让我们来逐一探讨。
1.1 文本数据的采集与清洗
在数据科学中,有一个经典的原则:“垃圾进,垃圾出”(Garbage In, Garbage Out)。这意味着,如果你的数据本身就有问题,那么即使使用最先进的算法和技术,得到的结果也不会令人满意。
文本数据的采集是NLP的第一步。你可以通过多种方式获得文本数据,比如从网站爬取、从社交媒体抓取、从公开数据集获取等。然而,采集到的数据往往是“脏的”,有很多噪音和不规范的部分,比如乱码、重复的内容、格式不统一的字段等。这时候,数据清洗就显得尤为重要。
文本清洗的步骤通常包括:
- 去除无关字符:如HTML标签、网址、特殊符号、非文本字符等。
- 去除重复文本:例如,当多个页面或不同平台发布相同的新闻时,去除重复的文本内容。
- 去除噪音数据:比如广告、营销语句、无关的留言等,这些内容不包含有价值的文本信息。
通过这些清洗步骤,我们确保处理后的文本数据更加干净,避免干扰分析的“垃圾数据”。
1.1.1 数据采集:爬取网页数据
爬取网页数据是获取文本数据的一种常见方式。在 Python 中,我们可以使用 requests 库来请求网页内容,结合 BeautifulSoup 库来解析 HTML 页面,从中提取出我们需要的文本信息。
安装依赖库:
pip install requests beautifulsoup4代码示例:
import requests
from bs4 import BeautifulSoup
# 请求网页
url = 'https://example.com' # 这里替换成目标网址
response = requests.get(url)
# 解析网页
soup = BeautifulSoup(response.text, 'html.parser')
# 提取网页中的文本内容
text = soup.get_text()
# 打印清洗后的文本内容
print(text)
上面代码通过 requests.get() 请求网页,获取 HTML 内容。然后用 BeautifulSoup 对 HTML 内容进行解析,提取出其中的文本部分。这是非常基础的网页爬取,当然,实际爬取过程中还需要处理反爬虫、页面加载异步内容等复杂问题。
1.1.2 数据清洗:去除无关字符、去重
数据清洗的目标是将文本数据转化为可供进一步处理的格式,去除噪声。常见的清洗步骤包括去除特殊符号、HTML 标签、数字、重复内容等。
代码示例:
import re
def clean_text(text):
# 去除HTML标签
text = re.sub(r'<[^>]+>', '', text)
# 去除特殊符号和数字,只保留字母和空格
text = re.sub(r'[^a-zA-Z\s]', '', text)
# 去除多余的空格
text = re.sub(r'\s+', ' ', text).strip()
return text
cleaned_text = clean_text(text)
print(cleaned_text)
这个清洗函数将 HTML 标签、特殊符号、数字都移除掉,并保留字母和空格。你也可以根据具体需求调整正则表达式,去除更多不需要的字符。
1.2 分词、去除停用词与词形还原
在中文和其他语言(如英语)中,句子的结构是由单词和字符组成的。而计算机要理解这段文本,首先需要将这些句子拆解成可以处理的单元,这就是所谓的“分词”。对中文来说,分词是一个复杂的任务,因为中文没有明确的单词边界(不像英语有空格隔开每个单词)。而对于英语,分词则相对简单,但也有需要注意的情况(如“don’t”会被分为“do”和“n’t”)。
分词的目标是将句子或文本分解为“单元”,可以是单词、字符或子词。分词之后,文本会变成一个一个的单词或词组,而计算机可以基于这些单元进行进一步的处理。
在分词之后,我们还需要做两件事情:
-
去除停用词:停用词是那些在语义上贡献不大的词语,例如“的”、“是”、 “and”、“the”等。虽然它们在语法上可能有作用,但对机器学习模型的训练影响较小,因此我们常常将这些停用词去除,减少计算复杂度。
-
词形还原(Lemmatization):有些词语会有多种形式,比如“run”可以是“running”或“ran”。这时,我们可以通过词形还原把所有变形的词还原成基础形式。这一步骤有助于提高模型的泛化能力,使得相同的词语在不同形式下得到统一处理。
1.2.1 分词:使用 jieba(中文)或 nltk(英文)
对于中文,我们常用 jieba 库进行分词。对于英文,我们可以使用 nltk 或 spaCy 进行分词。
安装依赖库:
pip install jieba nltk代码示例:
import jieba # 中文分词
import nltk # 英文分词
# 中文分词
text_zh = '我爱自然语言处理'
words_zh = jieba.cut(text_zh)
print("中文分词结果:", "/ ".join(words_zh))
# 英文分词
text_en = 'I love natural language processing'
words_en = nltk.word_tokenize(text_en)
print("英文分词结果:", words_en)
jieba.cut() 用于中文分词,nltk.word_tokenize() 用于英文分词。通过这两种方法,我们可以将文本拆解为单词或词组。
1.2.2 去除停用词:使用 nltk
停用词是指在文本中频繁出现但没有太大语义贡献的词,常见的如 “的”、“了”、 “and”、“the”等。我们可以使用 nltk 提供的停用词库来去除它们。
代码示例:
from nltk.corpus import stopwords
# 下载停用词库
nltk.download('stopwords')
# 获取英文停用词
stop_words = set(stopwords.words('english'))
# 去除停用词
words_no_stopwords = [word for word in words_en if word.lower() not in stop_words]
print("去除停用词后的结果:", words_no_stopwords)
这里我们使用了 nltk 中的停用词库,去掉了文本中的英文停用词。如果是中文的停用词,你可以使用相应的中文停用词库,或自定义一个。
1.2.3 词形还原:使用 nltk 或 spaCy
词形还原是将词语变为其基本形式。例如,“running” 和 “ran” 都应该被还原成 “run”。nltk 和 spaCy 都提供了词形还原的功能。
代码示例:
from nltk.stem import WordNetLemmatizer
# 初始化词形还原工具
lemmatizer = WordNetLemmatizer()
# 词形还原
word = 'running'
lemmatized_word = lemmatizer.lemmatize(word, pos='v') # 'v' 表示动词
print("词形还原结果:", lemmatized_word)
在这里,我们使用 WordNetLemmatizer 来对英文文本进行词形还原。你可以根据上下文选择不同的词性(如名词 n,动词 v)来进行准确还原。
小贴士:
你知道吗?有些“智能”分词工具,在处理中文时,不仅能识别标准的词汇,还能结合上下文推测新词!比如“马云”作为人名,它是一个单一的词汇,而不是两个单独的字。这也体现了NLP技术在自然语言中处理复杂问题的能力。
1.3 拼写纠正与规范化
拼写错误是我们日常交流中经常遇到的问题,在英文中尤其明显,比如“teh”应该是“the”,而在中文中也有类似的拼音错误,尤其是在手写输入时,出现“李明”被打成“理名”的情况。在NLP中,拼写纠正与规范化就是为了纠正这种由于打字、拼写或输入错误导致的问题。
拼写纠正的目的是通过算法(如编辑距离算法、字符级的语言模型等),识别出文本中的拼写错误并进行纠正。对于简体中文,可以利用拼音输入法自动纠错,或者使用训练好的纠错模型来进行修正。
文本规范化则包括了将不同的表达方式转换为统一的标准形式。例如,有时我们会看到“USA”和“美国”代表的是同一个事物,这时候,我们就需要将“USA”统一为“美国”这一标准化的表达方式。规范化不仅仅限于拼写,还包括数字、单位的统一。
拼写纠正与规范化是一个非常重要的步骤,它能确保我们的文本数据更加一致,减少因为拼写错误或不一致形式带来的噪声。
1.3.1 拼写纠正:使用 pyspellchecker
拼写错误是 NLP 中的常见问题。pyspellchecker 是一个简单且高效的拼写纠错工具,它通过字典匹配来修正拼写错误。
安装依赖库:
pip install pyspellchecker代码示例:
from spellchecker import SpellChecker
spell = SpellChecker()
# 输入有拼写错误的文本
text_with_errors = "I love programing and data scienc."
# 找到文本中的拼写错误单词
misspelled = spell.unknown(text_with_errors.split())
# 对拼写错误进行纠正
for word in misspelled:
print(f"纠正前:{word} -> 纠正后:{spell.correction(word)}")
pyspellchecker 会识别出文本中的拼写错误,并给出一个建议的修正词。
1.3.2 规范化:处理同义词
文本规范化的一个典型应用是将同义词统一。比如,“USA” 和 “America” 可以统一为 “美国”。这种操作可以通过自定义同义词词典来实现。
代码示例:
# 自定义同义词词典
synonym_dict = {
"USA": "美国",
"America": "美国",
"programming": "编程"
}
# 替换同义词
text = "I love programming and USA"
for word, synonym in synonym_dict.items():
text = text.replace(word, synonym)
print("规范化后的文本:", text)
在这个示例中,我们通过替换文本中的同义词来进行规范化操作。
通过这些代码示例,我们展示了如何使用 Python 库来实现文本数据的采集与清洗、分词、去除停用词与词形还原、拼写纠正与规范化等操作。这些步骤不仅是 NLP 的基础,而且是确保后续模型训练和应用效果的关键环节。
1.4 特征工程:提取词汇特征与文本向量化
特征工程是自然语言处理中至关重要的步骤,它帮助将文本数据转化为机器学习模型能够理解和处理的格式。简单来说,就是我们要把文本从人类语言转化为数字向量,才能让计算机开始“理解”这些文本。
1.4.1 词汇特征提取
词汇特征提取是指从文本中提取出单词及其特征。在自然语言处理中,最常见的特征是单词频率、单词的上下文等。我们可以通过以下方式来提取词汇特征:
- 词频 (Term Frequency, TF):某个单词在文档中出现的频率。
- 逆文档频率 (Inverse Document Frequency, IDF):用来衡量某个单词在语料库中出现的稀有度。
- TF-IDF:结合 TF 和 IDF,衡量一个词对文档的重要性。
代码实现:
from sklearn.feature_extraction.text import TfidfVectorizer
# 语料库(示例文本)
documents = [
"I love programming and natural language processing.",
"Natural language processing is fun.",
"Machine learning is a part of artificial intelligence."
]
# 创建TF-IDF向量化器
vectorizer = TfidfVectorizer()
# 转换文档为TF-IDF矩阵
tfidf_matrix = vectorizer.fit_transform(documents)
# 查看词汇表
print("词汇表:", vectorizer.get_feature_names_out())
# 查看TF-IDF矩阵
print("TF-IDF矩阵:\n", tfidf_matrix.toarray())
这个例子展示了如何用 TfidfVectorizer 提取文本的 TF-IDF 特征,将文本转换为数字化的形式。我们不仅能够获得每个单词在不同文档中的重要性,还能进一步利用这些数字向量做机器学习。
1.4.2 文本向量化:Word2Vec、GloVe、BERT 等
除了基本的 TF-IDF 特征,现代 NLP 中还常常使用更复杂的向量化技术,比如 Word2Vec、GloVe 和 BERT 等预训练语言模型。
- Word2Vec:通过上下文学习词语的分布式表示,每个词被映射为一个固定维度的向量,类似词与词之间的“语义距离”。
- GloVe:是另一种基于词频的分布式词向量表示方法。
- BERT:通过预训练的深度学习模型为每个词生成上下文相关的动态表示,能够捕捉到更多语法和语义信息。
Word2Vec 使用示例:
from gensim.models import Word2Vec
# 示例语料
sentences = [
["I", "love", "programming"],
["Natural", "language", "processing", "is", "fun"],
["Machine", "learning", "is", "part", "of", "AI"]
]
# 训练 Word2Vec 模型
model = Word2Vec(sentences, vector_size=50, window=3, min_count=1, workers=4)
# 查看“language”词的词向量
vector = model.wv['language']
print("‘language’词的词向量:", vector)
这段代码展示了如何利用 gensim 库训练一个简单的 Word2Vec 模型,并且查看词汇“language”的词向量。
1.5 多语言处理(中文分词、日文分词等)
NLP 处理不仅限于英语,中文、日文等其他语言的处理同样重要,尤其是在多语言环境中,处理多种语言的数据成为了一个挑战。
1.5.1 中文分词:jieba
中文分词是中文 NLP 中最基础的任务之一。由于中文没有明显的单词分隔符(如空格),所以分词变得尤为重要。jieba 是一个非常常用的中文分词库。
代码示例:
import jieba
# 中文文本
text = "我爱自然语言处理"
# 使用jieba进行分词
words = jieba.cut(text)
# 输出分词结果
print("分词结果:", "/ ".join(words))
jieba.cut() 方法可以将中文文本分解成词语,这对后续的文本分析、特征提取等任务非常重要。
1.5.2 日文分词:Janome
日文分词的难度与中文类似,因为日文也没有明确的词间分隔符。Janome 是 Python 中常用的日文分词库。
代码示例:
pip install janomefrom janome.tokenizer import Tokenizer
# 日文文本
text_jp = "自然言語処理は面白いです"
# 使用Janome进行分词
tokenizer = Tokenizer()
tokens = tokenizer.tokenize(text_jp)
# 输出分词结果
for token in tokens:
print(token.surface)
Janome 的分词效果能够将日文文本中的词汇拆解出来,可以用于后续的分析。
1.6 数据增强技术(同义词替换、随机插入等)
数据增强是指通过对现有数据进行变换,生成新的训练样本,从而增加模型的泛化能力。这在 NLP 中尤其重要,因为很多 NLP 模型对数据的多样性要求较高。常见的数据增强方法包括:
- 同义词替换:通过替换文本中的某些单词为它们的同义词。
- 随机插入:随机选择一个单词,并将其插入文本中的随机位置。
- 随机删除:随机删除文本中的某些单词。
1.6.1 同义词替换
代码示例:
from nltk.corpus import wordnet
# 获取单词的同义词
synonyms = wordnet.synsets("happy")
synonym_words = [lemma.name() for syn in synonyms for lemma in syn.lemmas()]
# 替换原文本中的“happy”为同义词
text = "I feel happy today."
new_text = text.replace("happy", synonym_words[0]) # 替换为第一个同义词
print("增强后的文本:", new_text)
这个示例展示了如何通过 nltk 获取单词“happy”的同义词并进行替换,从而增强文本的数据多样性。
1.6.2 随机插入
代码示例:
import random
def random_insert(text, num_insertions=1):
words = text.split()
for _ in range(num_insertions):
# 随机选择一个单词并插入
word = random.choice(words)
position = random.randint(0, len(words))
words.insert(position, word)
return " ".join(words)
text = "I love programming"
augmented_text = random_insert(text)
print("增强后的文本:", augmented_text)
通过随机插入,我们可以在文本中增加一些变化,增加模型对不同文本模式的学习能力。
通过这些代码示例,我们展示了如何使用 Python 库来实现文本数据的采集与清洗、分词、去除停用词与词形还原、拼写纠正与规范化等操作。这些步骤不仅是 NLP 的基础,而且是确保后续模型训练和应用效果的关键环节。同时,我们也学习了如何进行 特征工程,将文本数据转化为可以被机器学习模型处理的数字向量。我们使用了 TF-IDF、Word2Vec、GloVe、BERT 等方法来进行文本向量化;并且探索了如何处理不同语言的文本,如中文分词、日文分词等。此外,我们还了解了 数据增强技术,如同义词替换、随机插入等方法,以提高模型的泛化能力。
2. 词嵌入与文本表示技术
-
传统词表示:词袋模型(BoW)、TF-IDF
-
词向量与词嵌入:Word2Vec、GloVe
-
基于上下文的词表示:ELMo、BERT、GPT
-
如何选择合适的文本表示方法
-
可视化工具(t-SNE、UMAP)
-
动态词嵌入(FastText)
在自然语言处理中,如何将文本转化为计算机可以理解的数字形式是一个至关重要的问题。毕竟,计算机并不像人类一样能够直接“理解”语言,它们需要通过一系列的技术手段将语言中的信息转化为可以处理的形式。词嵌入和文本表示技术正是其中的核心技术之一,它们通过将词语或句子转化为向量,使得计算机能够理解和处理语言。
在本章节中,我们将深入探讨“词嵌入与文本表示技术”,从最基本的词袋模型到最先进的上下文感知词表示方法,涵盖了文本表示的多个维度和技术。无论是经典的词袋模型(BoW)和TF-IDF,还是当前广泛使用的词向量(Word2Vec、GloVe)和上下文感知的表示方法(如BERT和GPT),本章节都将逐一介绍并进行详细的分析。通过这些技术,我们能够把复杂的语言数据转化为可以由机器学习模型理解的数字格式,为各种自然语言处理任务奠定基础。
2.1 传统词表示:词袋模型(BoW)、TF-IDF
在处理自然语言时,我们要让计算机“理解”文本。无论是文章、新闻,还是用户评论,它们都包含着丰富的语义信息。我们如何将这些语义转换成计算机能够处理的数字表示呢?答案是:词表示方法!
在 NLP 的最早阶段,人们普遍使用了两种经典的词表示方法——词袋模型(BoW)和TF-IDF。它们简单、易懂,虽然很古老,但在一些场景下依然发挥着很大的作用。
2.1.1 词袋模型(BoW)
词袋模型(Bag of Words,简称 BoW)听起来就像是个袋子,把文档中的所有单词“装进来”,而不考虑它们的顺序和语法结构。这种方法的核心思想就是,统计文档中每个单词的出现次数。
- 比如,假如你有以下两篇文档:
- 文档 A:"苹果 香蕉 苹果"
- 文档 B:"香蕉 苹果 苹果"
通过词袋模型,我们可以将这两篇文档转换成如下的向量表示:
-
文档 A:
[2, 1]
这里的 "苹果" 出现了 2 次,"香蕉" 出现了 1 次。 -
文档 B:
[1, 2]
"苹果" 出现了 1 次,"香蕉" 出现了 2 次。
每个维度都代表一个单词在文档中的出现次数。简单来说,BoW 就是通过词频统计每个单词在文档中的重要性。
优点:
- 简单易用。
- 直观的表示文档中的单词频次。
缺点:
- 忽略了词语之间的顺序和语法关系。
- 无法很好地捕捉语义。
2.1.2 TF-IDF(Term Frequency-Inverse Document Frequency)
虽然词袋模型很简单,但有时候我们需要考虑某个单词在整个语料库中的稀有性,因为频繁出现的词汇未必有语义价值,比如"the"、"is"等。为了弥补这一点,TF-IDF(Term Frequency-Inverse Document Frequency)应运而生。
-
TF(Term Frequency,词频)衡量了某个词在文档中的出现次数。
-
IDF(Inverse Document Frequency,逆文档频率)衡量了某个词在整个语料库中的稀有性。
公式:

TF(Term Frequency)表示某个单词在文档中的出现次数:

IDF(Inverse Document Frequency)衡量某个词在整个语料库中的稀有性:
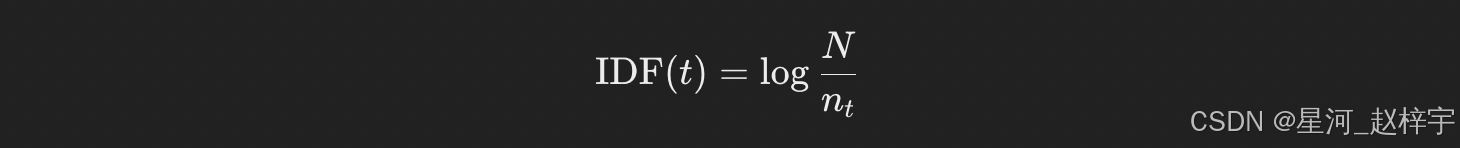
其中,N 是语料库中的文档总数,nt是包含词 t 的文档数。
示例:
- 假如有 3 篇文档:
- "苹果 香蕉 苹果"
- "香蕉 苹果 苹果"
- "苹果 香蕉"
我们可以计算文档中每个单词的词频(TF),以及整个语料库中每个单词的逆文档频率(IDF)。
- 文档 1:
- 苹果:2/3 = 0.66
- 香蕉:1/3 = 0.33
- 文档 2:
- 苹果:2/3 = 0.66
- 香蕉:1/3 = 0.33
- 文档 3:
- 苹果:1/2 = 0.5
- 香蕉:1/2 = 0.5
接着,我们计算 IDF:
- 苹果:log(3/3)
- 香蕉:log(3/3)
最终的 TF-IDF:
- 苹果 文档 1: 0.5 × log(3/3)
- 香蕉 文档 1: 0.25 × log(3/3)
优点:
- 考虑了单词在文档中的重要性和稀有性。
- 能够消除一些常见词的影响。
缺点:
- 计算复杂度较高,尤其当语料库非常庞大时。
- 无法很好地捕捉单词之间的语义关系。
在这一部分,我们学习了两种基本的词表示方法:词袋模型(BoW)和TF-IDF。
- 词袋模型简单地统计了单词的频次,但忽略了单词之间的顺序和语法关系。
- TF-IDF 在词频的基础上加入了单词在整个语料库中的稀有性,增强了文本表示的权重。
虽然这些方法简单易用,但它们无法很好地捕捉语义上的复杂关系,因此逐渐被更高级的词嵌入技术所取代。但正是从这基础上开始,我们才能更深入地学习现代 NLP 技术。
在接下来的章节,我们将讨论词向量与词嵌入,进一步探索如何用计算机“理解”语言的深层语义。
2.2 词向量与词嵌入:Word2Vec、GloVe
首先,我们得明白,词嵌入和词向量不是单纯的“字面上的字”或“简单的数字表示”,而是通过某种方式将每个词转换成一个低维度的连续向量,以便计算机能够处理和理解这些词之间的语义关系。这种表示方式比起“硬邦邦”的词袋模型,能够更好地反映出词与词之间的相似性、关联性和上下文信息。
简单来说,词向量就是通过一些算法把一个个单词转换成数字列表,让计算机在理解语言时不再“呆板”地看待每个词,而是通过词与词之间的“关系”来理解它们。
2.2.1 Word2Vec:让词语“变聪明”
Word2Vec(Word to Vector)是由Google的研究人员在2013年提出的一种词嵌入模型。它的目标是通过一个神经网络模型,将每个词表示为一个向量,使得“相似”或者“语义相关”的词在向量空间中彼此靠近。可以通过Word2Vec得到每个单词的词向量,使得不同单词之间的语义关系可以通过它们的向量距离来衡量。
Word2Vec有两个主要的模型:连续词袋模型(CBOW)和跳字模型(Skip-gram)。
- CBOW(Continuous Bag of Words):它试图通过上下文词来预测中心词。例如,给定句子:“我喜欢吃苹果”,它的上下文是“我、喜欢、吃、苹果”,CBOW会通过上下文来预测中间的词“吃”。
- Skip-gram:这个方法则是反过来,通过一个词来预测它的上下文。比如给定词“苹果”,Skip-gram模型会试图预测词“苹果”周围的上下文词,比如“我、喜欢、吃”。
这两个模型的本质区别是:CBOW通过上下文来预测目标词,而Skip-gram通过目标词来预测上下文。
Word2Vec示例:
假设有如下句子:
- "我 爱 编程"
- "我 喜欢 看书"
我们希望通过Word2Vec模型将词“我”转换成一个向量。经过训练后,模型会学到“我”和“爱”,“我”和“喜欢”在语义上比较相似,因此它们的词向量会在高维空间中靠得比较近,而像“编程”和“看书”的词向量则会远离“我”。
Word2Vec的优点:
- 计算效率高,可以在大规模语料库上快速训练。
- 训练出来的词向量能够捕捉到大量的语义信息和词语之间的相似度。例如,“国王”和“皇后”的词向量会非常接近,而“国王”和“苹果”的词向量则距离较远。
Word2Vec 实践
我们将使用Python的gensim库来实现Word2Vec模型。gensim是一个强大的自然语言处理库,专门用于文本向量化和词嵌入。首先,需要安装gensim库:
pip install gensim接下来,假设我们有一个简单的文本数据集,可以是一个由句子组成的列表。我们将训练一个Skip-gram模型。
import gensim
from gensim.models import Word2Vec
import logging
# 启用日志
logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO)
# 示例数据:简单的句子
sentences = [
["我", "喜欢", "编程"],
["我", "喜欢", "看书"],
["编程", "很", "有趣"],
["看书", "让我", "开心"]
]
# 训练Word2Vec模型
model = Word2Vec(sentences, vector_size=100, window=3, min_count=1, sg=1)
# 获取“编程”的词向量
vector = model.wv['编程']
print("词 '编程' 的词向量:", vector)
# 计算词之间的相似度
similarity = model.wv.similarity('编程', '喜欢')
print("词 '编程' 和 '喜欢' 的相似度:", similarity)
解释:
sentences:是我们用来训练Word2Vec模型的文本数据,每个句子是一个由单词组成的列表。vector_size:指定词向量的维度大小,通常为100-300维。window:窗口大小,决定了上下文的范围。比如,窗口大小为3,表示当前词前后各三个词为上下文。min_count:词频的最小值,表示只有出现次数超过该值的词才会被考虑。sg:决定使用的模型类型,sg=1代表Skip-gram模型,sg=0代表CBOW模型。
输出结果会告诉我们词“编程”的词向量是什么样的,并计算“编程”和“喜欢”之间的相似度。
2.2.2 GloVe:从全局语境提取知识
与Word2Vec不同,GloVe(Global Vectors for Word Representation)是另一种基于矩阵分解的词嵌入方法,由斯坦福大学的研究人员提出。GloVe的核心思想是,词的语义信息不仅来自于局部上下文(如Word2Vec中的窗口大小),还需要考虑到全局语境——即,单词在整个语料库中的统计信息。
GloVe的训练过程是通过构建一个共现矩阵,即记录语料库中每对词出现的频次,然后对这个矩阵进行因式分解,得到每个单词的向量表示。通过这种方式,GloVe能够捕捉到词之间的全局语义关系,尤其适用于处理大型语料库。
GloVe的核心思想:
- 假设两个词(如“编程”和“开发”)在语料库中经常一起出现,那么它们的向量在高维空间中应该是非常接近的。
- GloVe模型利用整个语料库中的词共现信息来训练词向量,使得词向量能够很好地反映出单词的语义和上下文信息。
GloVe示例:
假设我们有一个包含许多句子的语料库,词“编程”和“开发”在很多句子中同时出现,那么它们的词向量在GloVe的模型中将非常相似。通过训练,GloVe能够给出这样的语义关系:**“编程”和“开发”有相似的向量,而“编程”和“水果”**的向量则会差异很大。
GloVe的优点:
- 能够捕捉到更加全局的语义信息。
- 适用于大规模数据集,能够获得更为丰富的语义表示。
GloVe 实践
接下来,我们来看如何实现GloVe。GloVe的实现并不像Word2Vec那样可以通过现成的库(如gensim)直接调用,我们通常需要从GloVe的官方网站下载预训练的词向量模型,或者使用自己的数据进行训练。
首先,我们可以通过glove-python库来加载GloVe模型,或者直接使用gensim库加载GloVe的格式。
我们这里以使用gensim加载一个GloVe预训练模型为例:
-
下载预训练的GloVe模型: 你可以从GloVe官网(GloVe官网)下载一个适合的预训练模型。例如,可以下载
glove.6B.zip,这个模型包含了6B的词向量,维度有50D、100D、200D、300D四种。 -
加载 GloVe 模型:
pip install gensim然后,我们用gensim来加载GloVe模型并获取词向量:
import gensim
# 加载GloVe模型(假设下载并解压了 glove.6B.100d.txt)
glove_model = gensim.models.KeyedVectors.load_word2vec_format('glove.6B.100d.txt', binary=False, no_header=True)
# 获取词 '编程' 的词向量
vector_glove = glove_model['编程']
print("词 '编程' 的词向量(GloVe):", vector_glove)
# 计算词之间的相似度
similarity_glove = glove_model.similarity('编程', '喜欢')
print("词 '编程' 和 '喜欢' 的相似度(GloVe):", similarity_glove)
解释:
load_word2vec_format():gensim可以直接加载GloVe模型文件,binary=False表示我们的GloVe模型是文本格式,no_header=True表示文件没有头部信息。- 然后,我们可以像Word2Vec一样获取词向量,并计算词与词之间的相似度。
2.2.3 比较:Word2Vec vs GloVe
我们可以简单比较一下Word2Vec和GloVe的优缺点:
- Word2Vec:主要依靠局部上下文来训练词向量,更加关注单词之间的局部语义关系,训练速度较快。
- GloVe:更多关注整个语料库中单词之间的全局语义关系,可以捕捉到更深层的语义结构,但训练过程相对较为复杂。
这两者各有千秋,具体使用哪一个要根据实际任务来决定。
2.2.4 应用场景与实践
通过Word2Vec和GloVe等词嵌入技术,我们可以将复杂的语言信息转化为计算机易于处理的向量。这些技术广泛应用于各种自然语言处理任务:
- 文本分类:通过将文本转换为词向量,可以进行情感分析、主题分类等任务。
- 命名实体识别(NER):通过词向量对不同词进行表示,帮助识别文本中的人名、地名、时间等信息。
- 语义相似度计算:通过计算词向量之间的余弦相似度,判断两个词或句子的语义相似度。
- 机器翻译:将源语言和目标语言的词向量映射到同一个语义空间,从而实现跨语言的翻译。
总结
- Word2Vec:通过Skip-gram或CBOW模型从局部上下文中捕捉词的语义,通过训练数据学习词与词之间的关系。适用于较小的语料库,训练速度较快。
- GloVe:从全局共现矩阵中提取词之间的关系,适合大规模语料库,能够捕捉到更丰富的全局语义信息。
这两种技术各有优缺点,具体应用时可以根据数据量和任务需求选择合适的模型。在实际工作中,很多任务会结合使用这两种技术,或者使用更复杂的词嵌入技术(如BERT、GPT等)。
通过这些代码实践,大家不仅能理解词向量的概念,还能掌握如何在实际工作中运用这些技术,完成文本向量化、语义相似度计算等任务。
2.3 基于上下文的词表示:ELMo、BERT、GPT
读者朋友们,还记得之前我们学习的词袋模型(BoW)和词向量(Word2Vec、GloVe)吗?它们为我们提供了每个词的固定表示(词向量),但这些表示缺乏对上下文的理解。换句话说,词的意义是静态的,并不根据句子或段落的不同而发生变化。
然而,语言是有上下文的:同一个词在不同的句子中,其意义可能会有所不同。为了弥补这一不足,基于上下文的词表示应运而生,它们能够根据上下文动态调整词的表示,从而让计算机更加准确地理解语言。
接下来,我们将详细讨论三种基于上下文的词表示技术:ELMo、BERT 和 GPT。这三种技术都有其独特的优势和应用场景。
2.3.1 ELMo (Embeddings from Language Models)
ELMo 是一种基于语言模型的上下文词表示方法,它由斯坦福大学的研究人员提出。ELMo 的核心思想是:同一个词在不同上下文中的表示是不同的,因此,它利用双向语言模型(biLM)来为每个词生成不同的上下文表示。
ELMo 不同于传统的词向量(如Word2Vec或GloVe),它是基于句子的,每个词的表示会随着句子上下文的不同而不同。
ELMo 的工作原理
- 双向语言模型(biLM):ELMo 使用双向的 LSTM(长短期记忆网络)来训练语言模型,左到右和右到左的语言模型分别生成每个词的上下文表示。
- 层次化表示:ELMo 会将每个词的上下文表示通过多个层级进行整合,最后输出一个层次化的词表示,这些表示不仅反映了局部的语法信息,还包含了全局的语义信息。
ELMo 实践代码示例
ELMo 的实现较为复杂,通常我们会使用预训练模型进行操作。在实际应用中,我们通常使用 AllenNLP 这样的框架来调用预训练好的 ELMo 模型。
pip install allennlpimport allennlp
from allennlp.modules.elmo import Elmo, batch_to_ids
# 预训练的ELMo模型路径
options_file = 'https://allennlp.org/models/elmo-2x4096-2x512_2048_coverage.json'
weight_file = 'https://allennlp.org/models/elmo-2x4096-2x512_2048_coverage.hdf5'
# 加载ELMo模型
elmo = Elmo(options_file, weight_file, 2, dropout=0)
# 输入一个句子
sentences = [['我', '喜欢', '编程']]
# 将输入转化为Elmo所需的格式
character_ids = batch_to_ids(sentences)
# 计算词嵌入
embeddings = elmo(character_ids)
# 获取词嵌入
elmo_embeddings = embeddings['elmo_representations'][0]
print(elmo_embeddings)
2.3.2 BERT (Bidirectional Encoder Representations from Transformers)
BERT 是Google提出的一种深度学习模型,它改变了NLP领域的许多传统做法。BERT的出现使得模型能够以双向的方式理解上下文,而不仅仅是单向的。BERT 是基于 Transformer 架构的,因此它也充分利用了自注意力机制(self-attention),以捕捉文本中的复杂关系。
BERT 的工作原理
- 双向编码器:BERT 使用双向 Transformer 来理解上下文。在传统的语言模型中,文本通常是从左到右(或从右到左)逐字生成的,而BERT则可以从左到右和从右到左同时处理信息。
- 预训练任务:BERT 通过两种预训练任务来进行学习:Masked Language Model (MLM) 和 Next Sentence Prediction (NSP)。MLM 通过随机掩盖句子中的一些词来预测缺失的词,而NSP用于判断两个句子是否是连续的。
- 微调(Fine-tuning):BERT 是一个预训练的模型,使用预训练好的模型,我们可以通过微调来完成具体的NLP任务(如文本分类、命名实体识别等)。
BERT 实践代码示例
我们可以使用 transformers 库来加载预训练的 BERT 模型并进行推理:
pip install transformers使用 BERT 模型进行输出:
from transformers import BertTokenizer, BertModel
# 加载预训练的BERT模型和tokenizer
tokenizer = BertTokenizer.from_pretrained('bert-base-chinese')
model = BertModel.from_pretrained('bert-base-chinese')
# 输入一个句子
sentence = "我喜欢编程"
# 将句子转化为tokenizer需要的输入格式
inputs = tokenizer(sentence, return_tensors='pt')
# 获取BERT的输出
outputs = model(**inputs)
# 获取词嵌入(可以是最后一层的词向量)
last_hidden_states = outputs.last_hidden_state
print(last_hidden_states)
2.3.3 GPT (Generative Pretrained Transformer)
GPT 是OpenAI推出的基于Transformer的生成式预训练模型。与BERT不同,GPT的目标是生成文本,而不是理解文本。它只使用左到右的单向语言模型,主要应用于文本生成、对话系统等任务。
GPT 的工作原理
- 自回归生成模型:GPT 是一个自回归生成模型,也就是说,它通过已生成的词来预测下一个词。这种生成方式使得它非常适合进行文本生成任务。
- 预训练和微调:和BERT类似,GPT也采用了预训练+微调的方式。GPT的预训练任务是基于大量的无标签文本进行自回归语言建模,微调则是根据下游任务(如文本生成、翻译等)进行调整。
GPT实践
GPT的实现可以通过 transformers 库加载。
pip install transformers这里我们以GPT-2为例,展示如何进行文本生成:
from transformers import GPT2LMHeadModel, GPT2Tokenizer
# 加载预训练的GPT模型和tokenizer
tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
model = GPT2LMHeadModel.from_pretrained('gpt2')
# 输入一个提示语
prompt = "今天的天气很好,"
# 将输入转换为token
inputs = tokenizer.encode(prompt, return_tensors='pt')
# 生成文本
outputs = model.generate(inputs, max_length=50, num_return_sequences=1)
# 解码生成的文本
generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(generated_text)
总结
- ELMo 是基于语言模型的上下文词表示,适合处理复杂的上下文信息,但它并没有采用深度的Transformer架构,且处理速度较慢。
- BERT 利用双向Transformer架构,捕捉上下文的同时能够处理长范围的依赖,是当前NLP领域的标杆技术。BERT在文本分类、问答系统等任务中表现出色。
- GPT 则是自回归生成模型,更适合用于文本生成,具备生成有创意文本的强大能力,广泛应用于对话系统、创作等领域。
这些基于上下文的模型为我们提供了更强大的自然语言理解与生成能力,而通过以上的代码示例,孙儿你不仅学会了如何使用这些模型,还能在实践中应用它们解决各种NLP任务!
2.4 如何选择合适的文本表示方法
读者朋友们,相比您已经知道了不同的文本表示方法,例如词袋模型(BoW)、TF-IDF、词向量(Word2Vec、GloVe)以及基于上下文的表示(ELMo、BERT、GPT)。那么问题来了:在面对不同的任务时,我们该如何选择使用哪种表示方法呢?
选择合适的文本表示方法是自然语言处理(NLP)工作中至关重要的一个环节。正确的选择可以显著提高模型的性能,而不合适的选择则可能让你在项目中陷入困境。我们可以从以下几个方面来考虑:
1. 任务类型决定选择
不同的文本表示方法适合不同的任务。比如:
- 分类任务(如情感分析、垃圾邮件分类):如果任务的目标是分类,传统的TF-IDF和词袋模型(BoW)可能就能应对得很好,尤其是在数据集比较小、资源有限的情况下。它们简单、直观,效果也不差。
- 生成任务(如文本生成、机器翻译):如果你正在处理生成任务,比如文本生成或者机器翻译,那么像GPT这样的生成式模型是最佳选择。它利用语言的自回归特性生成流畅的文本。
- 上下文理解任务(如问答系统、命名实体识别NER、机器阅读理解):对于这些任务,BERT 或 ELMo 这样的上下文相关模型表现更为出色。它们能够根据上下文理解词汇的含义,因此在这些任务中往往能够获得更好的效果。
2. 计算资源与效率
有时,选择合适的文本表示方法不仅仅是看它能否解决问题,还要考虑它的计算成本。比如:
- 词袋模型(BoW):虽然非常简单且快速,但它也有缺点——高维稀疏矩阵。当你有大量的文本时,BoW 会变得非常庞大,占用大量内存,且处理速度慢。所以,如果计算资源有限,或者数据规模非常大,词向量(如Word2Vec、GloVe)会是更好的选择。
- TF-IDF:相较于BoW,TF-IDF更为高效,因为它考虑了词频和逆文档频率,生成的特征向量较为紧凑。不过,随着文本数量的增加,计算TF-IDF的开销还是会变得比较大。
- 上下文模型(BERT、GPT等):这些预训练模型虽然效果非常强大,但它们的计算开销也很高。BERT需要大量的显存和计算资源,对于大型数据集或实时应用,可能需要fine-tuning(微调)来实现最佳性能,而GPT系列则主要在生成任务中表现优异,但同样需要强大的计算资源。因此,如果计算资源有限,你可能要选择轻量级的模型(如DistilBERT)或传统的词向量表示方法。
3. 数据量的大小
文本表示方法的选择也受到数据量的影响:
- 小数据集:如果你的数据集非常小(比如几千条数据),传统的TF-IDF和**词袋模型(BoW)**可能就足够了。这些方法简单、计算量小,可以快速得到结果。
- 大数据集:如果你的数据集非常庞大,基于词向量的模型(如Word2Vec、GloVe)或基于上下文的模型(如BERT、ELMo)会更加有效。它们能够从大量数据中捕捉到更加丰富的语义信息。
4. 词语语义的处理方式
- 词袋模型(BoW)和TF-IDF:这些方法无法捕捉词语的语义联系。例如,**“苹果”和“水果”**会被看作两个完全不同的词,没有任何联系。但在许多实际应用中,词语之间的语义关系是非常重要的。
- 词向量(Word2Vec、GloVe):这些方法通过向量化表示,能够捕捉到词与词之间的关系。比如,Word2Vec可以通过邻近词汇来推测词语之间的语义关系,使得**“苹果”和“水果”**在向量空间中具有较高的相似度。
- 基于上下文的模型(BERT、GPT、ELMo):这些模型更进一步,不仅捕捉到词语的语义关系,还能够根据上下文变化动态调整词的表示。这对于多义词的处理(比如,“银行”可以是“金融机构”也可以是“河岸”)非常有效。
5. 可解释性与透明性
如果你的应用场景需要一定的可解释性,例如在一些医疗或法律领域中,我们希望能够解释模型为什么得出某个结论。传统的TF-IDF或BoW方法通常较为简单,容易解释。而基于深度学习的模型,如BERT和GPT,由于其复杂性,往往缺乏足够的可解释性。
6. 语言的多样性与复杂性
在处理多语言文本时,我们需要特别考虑所选模型的适应性:
- TF-IDF、BoW等方法在多语言环境中可能需要重新训练特征提取方法。
- 词向量(如Word2Vec、GloVe)可以通过多语言预训练模型(如 FastText)来处理不同语言的文本。
- BERT已经推出了多个多语言版本(例如Multilingual BERT),可以同时处理多种语言。因此,当我们需要处理多语言任务时,BERT模型常常是更好的选择。
总结
选择合适的文本表示方法并非一件简单的事情。它需要综合考虑任务需求、计算资源、数据规模、语义捕捉能力等多个因素。
- 如果你处理的任务是简单的分类或文本标注任务,且数据规模较小,TF-IDF和BoW可能就已经足够了。
- 如果你需要捕捉更丰富的语义信息,并且计算资源允许,Word2Vec或GloVe这样的词向量方法会更适合。
- 如果你要处理复杂的理解任务,尤其是在有丰富上下文的情况下,BERT或ELMo等上下文相关模型能为你提供更为精准的表示。
- 如果你的任务涉及生成文本或对话系统,GPT系列模型会为你提供非常强大的生成能力。
在选择时,最好的方法是试验不同的模型,看看哪一种方法在你的任务中表现最佳!每种方法都有其优势和不足,选择合适的模型就是最大化利用其优点,避免其局限。
2.5 可视化工具(t-SNE、UMAP)
这一次,我们要谈论的是如何通过可视化技术,帮助我们更好地理解和分析高维数据。你知道,高维数据就像是一个巨大的迷宫,里面藏着无数的细节和规律,而我们需要找到一种方法将这些规律呈现出来,让人一目了然。这时候,t-SNE和UMAP就能派上用场了。
在自然语言处理(NLP)中,词向量和文本表示常常是高维的,意味着每个词或文本都有很多维度的特征。这些高维数据可以包含丰富的语义信息,但要想理解它们,就需要对它们进行降维,也就是将这些高维数据转换为2D或3D的图形,这样我们就能更加直观地看到它们之间的关系和结构。
t-SNE:t-分布邻域嵌入(t-Distributed Stochastic Neighbor Embedding)
t-SNE是一个非常常用的降维方法,它主要用于将高维数据投影到二维或三维空间,以便可视化。t-SNE的工作原理可以用一个非常形象的比喻来解释:
- 想象你在玩一款魔法拼图游戏。你手中有一堆碎片(这些碎片代表高维数据的点),你需要将这些碎片拼凑成一个漂亮的拼图(2D或3D图像)。这些碎片之间有一种关系,有些碎片应该靠得很近,有些则应该远离。t-SNE就是帮你在拼图游戏中找到这些碎片之间的关系,并且尽量将关系相似的碎片放得更近,关系不同的碎片放得更远。
t-SNE的步骤:
- 计算高维空间中的相似度:t-SNE首先计算每个数据点与其他数据点的相似度,这个相似度是通过计算概率分布来表示的,意思是相似的数据点之间的距离较小。
- 降低维度:然后,t-SNE会将这些高维数据点通过迭代优化过程,调整它们在低维空间中的位置。最终,在低维空间中,相似的点会被紧密地放在一起,而不相似的点会被拉开,形成一个能够反映原始高维数据结构的可视化图。
t-SNE的优点:
- 直观的可视化:t-SNE非常擅长将复杂的高维数据结构通过二维或三维图像展现出来。特别是当我们有大量的文本或词向量时,它能够揭示不同类别之间的关系。
- 有助于探索数据结构:它帮助我们理解数据的内在结构和潜在模式,尤其是在分类、聚类和趋势分析中非常有用。
t-SNE的缺点:
- 计算开销大:t-SNE在处理大数据集时可能会非常慢,因为它涉及到大量的计算。
- 不适用于非常大的数据集:当数据集非常大时,t-SNE可能会面临性能瓶颈。
t-SNE的代码示例(以Python为例):
import numpy as np
import matplotlib.pyplot as plt
from sklearn.manifold import TSNE
from sklearn.datasets import load_iris
# 载入数据集(以Iris数据集为例)
data = load_iris()
X = data.data
y = data.target
# 使用t-SNE将高维数据降到2D
tsne = TSNE(n_components=2, random_state=42)
X_tsne = tsne.fit_transform(X)
# 可视化结果
plt.figure(figsize=(8, 6))
plt.scatter(X_tsne[:, 0], X_tsne[:, 1], c=y, cmap='viridis')
plt.colorbar()
plt.title('t-SNE visualization of Iris dataset')
plt.show()
在这个例子中,我们使用Iris数据集(一个经典的机器学习数据集),并使用t-SNE将其降到二维,最终通过散点图来展示数据点之间的关系。
UMAP:统一流形逼近与投影(Uniform Manifold Approximation and Projection)
虽然t-SNE是一个非常强大的降维工具,但它也有一些限制,尤其是在处理大规模数据集时。而UMAP作为一个较新的降维方法,它在保留数据结构的同时,在计算效率和准确度方面表现得更好。
UMAP的工作原理也与t-SNE类似,但它在数学理论上有一些创新,允许它在降维时更好地保持数据的全局结构。
UMAP的优点:
- 速度更快:相对于t-SNE,UMAP在处理大规模数据时更高效,尤其在计算速度和内存消耗上表现优秀。
- 保持全局结构:UMAP不仅能够保持局部结构,还能够尽量保留数据的全局结构,这使得它在许多应用中比t-SNE更具优势。
- 适用于大数据集:UMAP可以处理大量的数据集,适用于大规模文本、图像数据的降维。
UMAP的缺点:
- 较复杂的调参:UMAP的参数设置需要一定的经验,在一些特殊任务上可能需要微调。
UMAP的代码示例:
import umap
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
# 载入数据集(以Iris数据集为例)
data = load_iris()
X = data.data
y = data.target
# 使用UMAP将高维数据降到2D
umap_model = umap.UMAP(n_components=2, random_state=42)
X_umap = umap_model.fit_transform(X)
# 可视化结果
plt.figure(figsize=(8, 6))
plt.scatter(X_umap[:, 0], X_umap[:, 1], c=y, cmap='viridis')
plt.colorbar()
plt.title('UMAP visualization of Iris dataset')
plt.show()
在这个例子中,我们使用UMAP将Iris数据集降到二维,并可视化了降维结果。与t-SNE相比,UMAP可以在保持数据结构的同时,处理更大规模的数据集。
t-SNE vs UMAP:如何选择?
- t-SNE:适用于需要精确捕捉数据局部结构的情况。如果你关注的是数据点之间的局部相似性(比如词向量中的近邻关系),t-SNE会非常有效。
- UMAP:适用于更大规模的数据集,尤其是在处理全局结构和长期趋势时表现更好。如果你需要处理非常庞大的数据集,或者需要全局结构的保留,UMAP可能是更好的选择。
总结
- t-SNE和UMAP都是非常强大的可视化工具,能够帮助我们将高维数据转换为低维空间,从而更直观地展示数据的结构。
- t-SNE适合用于需要精准局部结构保留的任务,而UMAP则在大规模数据集和全局结构保留方面表现得更为出色。
- 选择哪种方法要根据任务需求、数据规模以及计算资源等因素来做决定。
通过这些可视化工具,你不仅能够更好地理解数据,还能在模型训练和调参的过程中,发现潜在的规律和模式。这也是NLP中非常重要的技能,能够帮助你做出更加聪明的决策,最终提高模型的性能!希望读者朋友们在玩转这些降维工具时,能像解开一张复杂的拼图一样,发现数据背后隐藏的精彩世界!
2.6 动态词嵌入(FastText)
FastText是Facebook的AI研究团队开发的一个模型,它不仅改进了传统的词嵌入方法,还能通过词的子词(subword)信息来生成词向量。这种方法的一个巨大优势就是它能够处理未见过的词,甚至是拼写错误的词,依然能够生成相对合理的词向量。
为什么需要FastText?
假设我们有一个词库,包含了大量的词向量。传统的词嵌入方法(例如Word2Vec)会将每个词作为一个独立的单位进行学习,因此如果遇到一个未曾见过的新词,系统根本无法给它生成一个有效的词向量。比如说,你可能在词典中看到“ChatGPT”,但模型没有接触过这个词,它就会无法生成该词的向量表示。
而FastText通过将词切分为n-gram(子词),即词的字母片段,来解决这个问题。即使是一个新词,FastText也可以利用这些子词信息来推测出一个合适的词向量。
举个例子:假设我们遇到了一个从未见过的词“chatgpt”,FastText可以将这个词分解为子词,如:
- “cha”
- “hat”
- “atg”
- “tgp”
- “gpt”
通过这些子词,FastText可以从已知的子词向量中组合出一个新的词向量。即使模型没有在训练数据中直接见过“chatgpt”这个词,它依然能够推测出一个较为合适的向量。
FastText的工作原理
FastText模型的工作原理可以分为几个步骤:
-
词的拆分: FastText首先将每个词拆分成多个子词(n-gram)。例如,词“chat”可能会被拆解为:
- 单个字母的子词:
c,h,a,t - 双字母子词:
ch,ha,at - 三字母子词:
cha,hat
- 单个字母的子词:
-
训练子词的词向量: FastText通过对每个子词进行训练,来学习这些子词的向量表示。通过这种方式,即便是一个全新词的子词,也可以找到相应的向量。
-
词的表示: 当我们需要表示整个词时,FastText并不会直接使用一个固定的词向量,而是将该词的所有子词向量进行求和或平均,然后得到一个表示整个词的向量。
-
处理未知词: 当遇到未见过的词时,FastText直接从它的子词向量中生成该词的向量。这样,即使是完全陌生的词,只要它的子词在训练过程中出现过,FastText就能够给出合理的表示。
FastText的优势
- 处理未见词(Out-of-Vocabulary, OOV): FastText可以处理那些在训练时未见过的词。它通过子词的组合来推测新词的向量,而不仅仅是通过整体词汇表来做匹配。
- 拼写纠错: 由于FastText对词的拆解基于字母的n-gram,它对拼写错误、词形变化等问题具有更强的适应性。例如,“runner”和“run”可能会有相似的n-gram,FastText可以将它们的向量表示得更为接近。
- 更细粒度的表示: 与传统的词嵌入模型(如Word2Vec)相比,FastText能够从子词中捕获更多细节信息,尤其是在处理一些复合词或稀有词时,效果更佳。
FastText的缺点
- 计算开销较大: 由于需要对每个词进行拆分并处理n-gram,FastText相对于一些其他的模型可能在训练时消耗更多的计算资源。
- 模型较复杂: 相比于传统的Word2Vec模型,FastText的模型稍微复杂一些,需要更多的内存和存储来存储这些子词向量。
FastText的实践代码
在Python中,我们可以通过Gensim库来使用FastText模型。下面是一个简单的示例代码,展示了如何训练一个FastText模型,并查看词向量。
import gensim
from gensim.models import FastText
# 假设我们有一个简单的文本数据集
sentences = [
["chat", "gpt", "is", "amazing"],
["language", "models", "are", "powerful"],
["fasttext", "is", "cool"]
]
# 训练FastText模型
model = FastText(sentences, vector_size=10, window=3, min_count=1, sg=1)
# 查看单词的词向量
word_vector = model.wv['chat']
print("Word vector for 'chat':", word_vector)
# 查看词向量的维度
print("Dimensions of word vector:", len(word_vector))
# 查看相似的词
similar_words = model.wv.most_similar('chat', topn=3)
print("Most similar words to 'chat':", similar_words)
代码解析:
vector_size=10表示每个词的向量维度为10(在实际应用中你可能会使用更大的维度)。window=3表示上下文窗口大小为3(即每个词周围的词被视为上下文)。min_count=1表示将所有出现至少1次的词都加入到词汇表。sg=1表示采用skip-gram模型进行训练(可以设置为0,使用CBOW模型)。
总结
- FastText通过利用子词的n-gram来生成词向量,特别适合处理未见过的新词和拼写错误的词,解决了传统词嵌入方法的一些局限。
- FastText在处理稀有词、拼写变种以及组合词时表现得非常强大。
- 在实践中,FastText比传统的词嵌入方法更加灵活,并且能为NLP任务提供更高质量的词表示。
通过使用FastText,你不仅能更好地处理文本数据,还能在遇到复杂、变化多端的语言情况时,保持较高的灵活性和准确性。希望你通过这些技术的学习,能够更好地解决实际问题,开发出更强大的NLP系统!
回顾:
传统词表示方法:词袋模型(BoW)与TF-IDF
词袋模型(BoW)和TF-IDF是自然语言处理中的两种经典文本表示方法,它们的基本思想是将文本表示为单词的频次或加权频次。在BoW中,每个词都是一个独立的特征,而在TF-IDF中,我们则对词的频次进行加权处理,给常见词和稀有词赋予不同的权重。尽管这两种方法在处理简单的文本任务时能够取得不错的效果,但它们的一个显著问题是忽略了词语之间的语义关系和上下文信息。
词向量与词嵌入:Word2Vec与GloVe
为了解决BoW和TF-IDF的局限,研究人员提出了词向量(Word Embeddings)的概念,最典型的技术包括Word2Vec和GloVe。通过这些技术,我们能够将每个词转化为一个稠密的向量,这些向量捕捉了词语之间的语义关系。Word2Vec采用Skip-Gram或CBOW模型,通过上下文窗口来学习词的向量,而GloVe则通过矩阵分解的方式来构建全局的词关系。这些方法较大程度地保留了词语之间的相似性,使得语义相似的词具有相近的向量表示。
基于上下文的词表示:ELMo、BERT与GPT
随着深度学习的发展,传统的词向量模型逐渐暴露出一些不足,特别是在处理多义词和上下文信息时。为了解决这一问题,基于上下文的词表示方法应运而生。ELMo、BERT和GPT等模型通过引入上下文信息,使得每个词的表示能够根据它在不同句子中的上下文进行动态调整。ELMo采用双向LSTM结构,BERT和GPT则基于Transformer架构,分别以编码器和解码器的方式处理上下文信息。通过这些方法,我们能够获得更加精准且灵活的词表示,极大地提升了NLP任务的性能。
动态词嵌入(FastText)
FastText作为一种动态词嵌入方法,通过将词拆分成多个子词(n-gram)来进行词表示。这使得FastText在处理未见过的词或拼写错误时表现得非常强大。即便是完全陌生的词,FastText也能通过组合子词的向量来生成合理的词向量。相比于Word2Vec,FastText更加灵活,并且能够处理一些特殊情况,如拼写变化和复合词。
可视化工具:t-SNE与UMAP
在处理和理解高维的词嵌入向量时,我们常常需要可视化这些向量,以便从中提取信息。t-SNE和UMAP是两种常用的降维技术,它们能够将高维数据映射到二维或三维空间中,并帮助我们理解词嵌入的结构。通过这些可视化工具,我们能够清晰地看到语义相似的词是如何聚集在一起的,以及词嵌入模型是如何捕捉到不同词之间的关系。
如何选择合适的文本表示方法
选择合适的文本表示方法取决于任务的具体需求。如果任务需要简单、快速的文本表示,传统的BoW或TF-IDF方法可能就足够了;如果任务要求更精确的语义理解,那么Word2Vec、GloVe等词向量模型会更合适;如果需要处理上下文依赖性强的复杂语言现象,那么基于上下文的BERT、GPT等模型将会发挥巨大的优势。而FastText则在处理未见词、拼写错误或特殊用法时尤为有效。
通过本章节的学习,你将全面掌握文本表示的各种技术,并能够根据不同的应用场景选择合适的方法。在实际的自然语言处理任务中,文本表示是基础中的基础,正确的选择和使用文本表示方法,能够显著提升模型的性能,为后续更高级的NLP任务打下坚实的基础。
3. 经典的 NLP 算法与模型
-
朴素贝叶斯分类器
-
支持向量机(SVM)与逻辑回归
-
决策树与随机森林
-
条件随机场(CRF)与隐马尔可夫模型(HMM)
-
模型评估与比较(准确率、召回率、F1 分数等)
-
模型优化技巧(超参数调优、交叉验证等)
3.1 朴素贝叶斯分类器
什么是朴素贝叶斯分类器?
朴素贝叶斯分类器(Naive Bayes Classifier,简称NBC)是一种基于贝叶斯定理的分类算法,它的基本思想是:根据已知的训练数据,计算出各类别的概率分布,然后通过最大化后验概率来判断新的数据属于哪个类别。
贝叶斯定理是条件概率的基本定理,它通过一个非常简单但强大的公式表达了如何根据观察到的证据更新信念结果。公式如下:
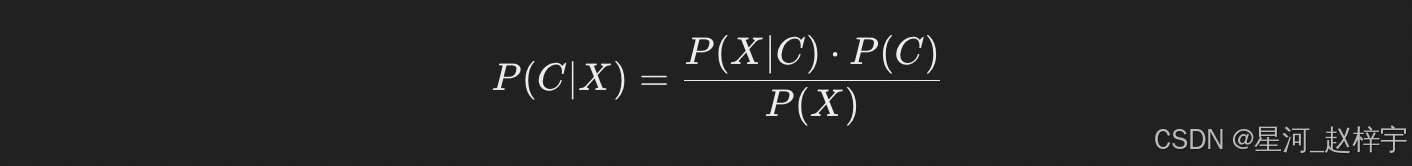
其中:
- P(C∣X) 是在给定观察到的特征 X 后,样本属于类别 C 的条件概率,即后验概率。
- P(X∣C) 是在类别 C 下观察到特征 XXX 的概率,即似然度。
- P(C) 是类别 C 的先验概率,即类别出现的概率。
- P(X) 是特征 X 的总概率,通常可以忽略,因为它对于比较不同类别的后验概率是一个常数。
朴素贝叶斯分类器的“朴素”之处在于,它假设每个特征(或词语)在给定类别的条件下是独立的。也就是说,它假设特征之间没有任何相互依赖性,尽管在实际情况中这种假设往往是不成立的。但即便如此,朴素贝叶斯算法仍然在许多实际应用中表现得非常好,尤其是在文本分类(例如垃圾邮件分类、情感分析等)中,效果往往超出预期。
朴素贝叶斯分类器的工作原理
朴素贝叶斯分类器的核心思想是通过计算不同类别的后验概率来预测样本所属的类别。具体来说,给定一个待分类的文本,我们的目标是计算该文本属于每个类别的概率,并选择概率最大的类别作为最终预测结果。
-
先验概率(Prior Probability):这是指每个类别出现的概率,通常是通过训练数据中的频率来估计的。例如,垃圾邮件分类问题中,垃圾邮件和正常邮件出现的概率就是先验概率。
-
似然概率(Likelihood Probability):这是指在特定类别下,特定词语出现的概率。例如,在垃圾邮件中,可能有词汇如“赢得大奖”“免费”之类,这些词汇在垃圾邮件中的出现频率较高。通过计算每个词在各类别中的出现概率,我们可以得到该类别下词的似然性。
-
后验概率(Posterior Probability):通过贝叶斯定理,我们可以计算给定一组特征(例如文本中的词语)后,每个类别的后验概率。最终,我们选择后验概率最大的类别作为预测结果。
公式推导
给定一个文档 D 和类别Ck,我们的目标是找到使得后验概率 P(Ck∣D)最大的类别。根据贝叶斯定理,我们有:
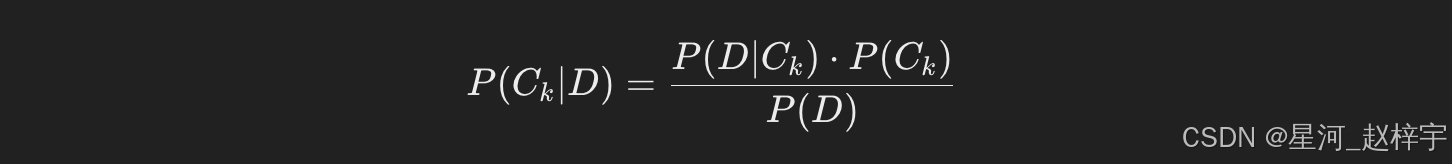
由于 P(D)对所有类别都是常数,因此我们只需要比较 P(D∣Ck)⋅P(Ck)即可。
为了进一步简化,我们假设所有词语在给定类别下是独立的,这就是“朴素”假设。于是,P(D∣Ck)可以被分解为每个词的条件概率的乘积:
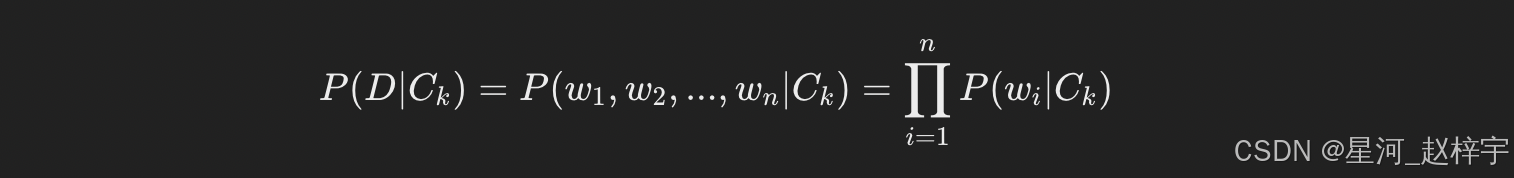
因此,我们的目标是最大化以下表达式:
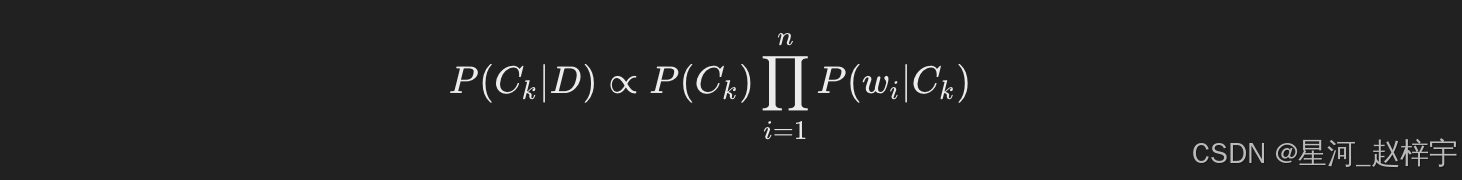
这个公式的含义是,对于每个类别 Ck,我们计算它的先验概率和在该类别下每个词的条件概率的乘积,最终选择后验概率最大的类别作为预测结果。
朴素贝叶斯分类器的优缺点
优点:
- 简单高效:朴素贝叶斯分类器的计算量较小,训练速度快,尤其适用于大规模数据。
- 性能良好:即使“朴素”假设(词语独立性假设)不完全成立,朴素贝叶斯也往往能给出相当不错的结果,特别是在文本分类中,效果十分显著。
- 对小数据集有很好的表现:与许多其他机器学习算法不同,朴素贝叶斯不容易出现过拟合,尤其是在样本较少时,它依然能保持较好的泛化能力。
缺点:
- 独立性假设不现实:朴素贝叶斯假设所有特征独立,实际上,许多实际问题中的特征是相互依赖的,这限制了它的应用范围。
- 对零概率敏感:如果某个词在某个类别中没有出现过(即该词的条件概率为零),则该类别的后验概率也会被打为零。为了解决这个问题,我们通常会使用拉普拉斯平滑来避免零概率问题。
Python 实践代码:朴素贝叶斯分类器
让我们通过一个简单的垃圾邮件分类实例来实现朴素贝叶斯分类器:
import pandas as pd
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import MultinomialNB
from sklearn.metrics import accuracy_score
# 示例数据:文本和标签(0表示正常邮件,1表示垃圾邮件)
data = {
'text': ["free money", "win lottery", "hello friend", "important information", "hello world", "free offer now"],
'label': [1, 1, 0, 0, 0, 1]
}
df = pd.DataFrame(data)
# 特征提取:将文本转化为词频矩阵
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(df['text'])
y = df['label']
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 训练朴素贝叶斯分类器
model = MultinomialNB()
model.fit(X_train, y_train)
# 预测
y_pred = model.predict(X_test)
# 评估模型
accuracy = accuracy_score(y_test, y_pred)
print(f'准确率: {accuracy:.2f}')
在这段代码中,我们使用了CountVectorizer将文本数据转化为词频矩阵,并通过MultinomialNB实现了朴素贝叶斯分类器。最终,我们用测试集对模型进行了评估,输出了分类准确率。
总结
朴素贝叶斯分类器是一种高效、简单且有广泛应用的算法,尤其在文本分类领域表现出色。它的核心在于贝叶斯定理和特征独立性的假设,尽管这个假设在实际应用中可能不完全成立,但它的简洁性和高效性使其在许多问题中表现良好。理解朴素贝叶斯的原理以及如何在实际应用中使用它,将为我们掌握其他更复杂的模型打下坚实的基础。
希望通过这节内容,大家能够掌握朴素贝叶斯分类器的工作原理、优缺点,并能在实际项目中熟练应用它!
3.2 支持向量机(SVM)与逻辑回归
支持向量机(SVM)
支持向量机(Support Vector Machine, SVM)是一种强大的监督学习算法,常用于分类任务,尤其是在处理高维数据时表现优异。在NLP中,SVM通常用于文本分类任务,比如垃圾邮件检测、情感分析、新闻分类等。
SVM的核心思想是通过找到一个超平面(Hyperplane)来将不同类别的样本区分开来。这个超平面是一个决策边界,它把不同类别的样本分开,使得每一类的样本都尽可能远离超平面。
SVM的工作原理
-
线性分类: 对于线性可分的样本(即可以通过一个直线或超平面来分开样本),SVM会选择一个超平面,使得两边类别的样本距离超平面最远。这个最远的距离就是间隔(Margin),SVM的目标是最大化这个间隔。
-
支持向量: 支持向量是那些最接近超平面的样本,它们决定了分类边界的位置。换句话说,支持向量就是最“关键”的样本。SVM的名字来源于它所使用的“支持向量”——即那些支持分类决策的样本。
-
非线性分类: 在很多实际应用中,数据并不是线性可分的。这时,SVM通过使用**核技巧(Kernel Trick)**将数据映射到一个更高维的空间,使得数据在这个新的空间中变得线性可分。常见的核函数有线性核、多项式核、径向基函数(RBF)核等。
SVM的数学公式
SVM的目标是找到一个最优的超平面。假设我们有一个二维数据集,目标是找到一个直线(超平面)来将样本分成两类。对于线性可分的情形,我们可以通过以下约束条件来寻找最优超平面:
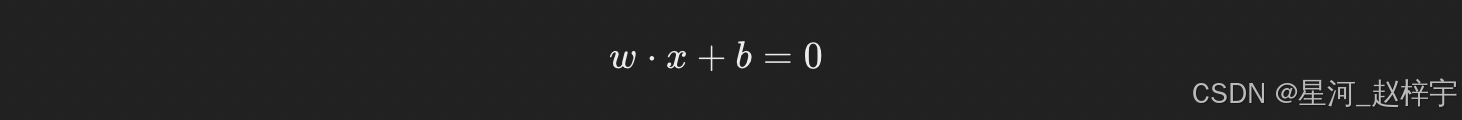
其中,w是超平面的法向量,b是偏置,x是样本点。
SVM通过最大化间隔来寻找最优超平面。最大化间隔相当于最小化一个目标函数,这个目标函数可以表示为:
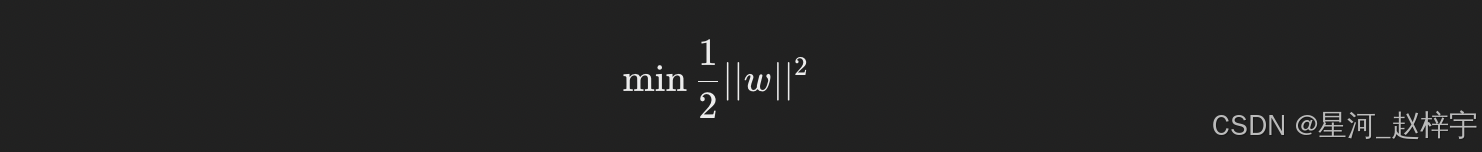
同时,要求所有样本满足以下约束条件:
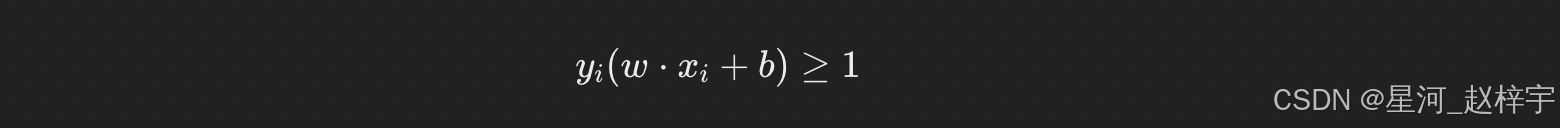
其中,yi是类别标签(1或-1),xi是样本点。
通过求解这个优化问题,SVM可以找到一个最优的超平面。
逻辑回归(Logistic Regression)
逻辑回归,尽管名字里有“回归”二字,但它其实是一种分类算法。它主要用于二分类问题,即通过一个输入特征来预测输出属于哪个类别(例如,垃圾邮件与正常邮件,患者是否患病)。逻辑回归非常适用于特征之间是线性关系的情况。
逻辑回归的工作原理
逻辑回归的核心思想是:根据输入特征,计算出属于某个类别的概率值。这个概率值通过一个Sigmoid函数(也叫逻辑函数)进行映射,使其保持在0和1之间。Sigmoid函数的公式如下:
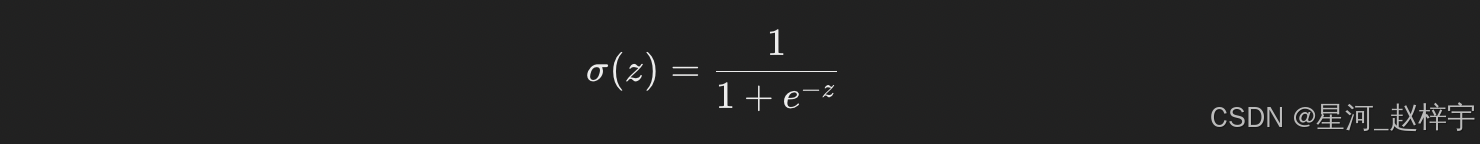
其中,z是输入特征与权重的线性组合,具体表示为:

然后,逻辑回归将通过最大化似然函数来优化模型参数。其目标是找到最佳的权重 www 和偏置 bbb,使得模型预测的概率最接近实际标签。
模型训练与优化
逻辑回归的训练过程通常采用梯度下降或牛顿法等优化算法来求解最优的模型参数。通过对训练数据进行反复训练,逻辑回归将逐步调整参数,使得模型的预测准确度逐渐提高。
SVM与逻辑回归的比较
虽然SVM和逻辑回归都是用于分类问题,但它们的工作原理、优缺点和应用场景有所不同。以下是两者的对比:
| 特点 | 支持向量机(SVM) | 逻辑回归(Logistic Regression) |
|---|---|---|
| 模型类型 | 线性分类器(也可通过核技巧处理非线性分类) | 线性分类器 |
| 优化目标 | 最大化间隔(margin) | 最大化对数似然函数(log-likelihood) |
| 处理非线性问题 | 通过核技巧(kernel trick)处理非线性问题 | 只能处理线性可分问题(通过多项式特征扩展可处理非线性) |
| 计算复杂度 | 对大规模数据集计算量较大 | 计算量较小,适合大规模数据集 |
| 模型可解释性 | 相对较低 | 相对较高 |
| 适用场景 | 适合复杂的分类问题,尤其是特征维度高、样本量小的场景 | 适合线性可分的问题,尤其是数据量大且噪音较小的场景 |
Python 实践代码:SVM与逻辑回归
现在,让我们通过一个文本分类的例子来实现这两个模型。
支持向量机(SVM)
import pandas as pd
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score
# 示例数据:文本和标签(0表示正常邮件,1表示垃圾邮件)
data = {
'text': ["free money", "win lottery", "hello friend", "important information", "hello world", "free offer now"],
'label': [1, 1, 0, 0, 0, 1]
}
df = pd.DataFrame(data)
# 特征提取:将文本转化为词频矩阵
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(df['text'])
y = df['label']
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 训练SVM分类器
model = SVC(kernel='linear') # 线性核
model.fit(X_train, y_train)
# 预测
y_pred = model.predict(X_test)
# 评估模型
accuracy = accuracy_score(y_test, y_pred)
print(f'SVM准确率: {accuracy:.2f}')
逻辑回归(Logistic Regression)
from sklearn.linear_model import LogisticRegression
# 训练逻辑回归分类器
model_logreg = LogisticRegression()
model_logreg.fit(X_train, y_train)
# 预测
y_pred_logreg = model_logreg.predict(X_test)
# 评估模型
accuracy_logreg = accuracy_score(y_test, y_pred_logreg)
print(f'逻辑回归准确率: {accuracy_logreg:.2f}')
总结
支持向量机(SVM)和逻辑回归(Logistic Regression)是两种非常重要且广泛应用的分类算法。在处理线性分类问题时,逻辑回归凭借其简单高效和可解释性强的特点,是非常不错的选择。而SVM则适用于更复杂的分类问题,尤其是在样本维度较高、样本较少的情况下,SVM的表现往往非常优异。理解这两种算法的基本原理、优缺点以及如何使用它们进行文本分类,将帮助你在实际应用中做出更加合适的选择。
3.3 决策树与随机森林
在我们了解了自然语言处理(NLP)中常见的算法之后,接下来我们要进入一个非常有趣的领域——决策树与随机森林。想象一下,你正在处理一个关于学生成绩的分类任务,需要根据学生的学习时间、作业提交情况、课堂参与度等特征来预测学生是否能通过考试。决策树就像是你在选择不同路径时的指南针,告诉你从哪个节点开始,走哪条路。随机森林则像是拥有多个智慧导师的团体合作,每个导师根据不同的数据子集作出决策,最后集思广益给出最终的判断。
虽然在NLP任务中,我们通常使用像BERT、GPT这样的深度学习模型,但决策树和随机森林在许多问题中依然扮演着重要角色,尤其是在结构化数据和需要高效处理的情况下。
3.3.1 决策树(Decision Tree)
决策树简介
决策树是一种树形结构的预测模型,通过一系列的决策节点(Decision Nodes)和叶子节点(Leaf Nodes)来做出决策。每个内部节点表示对某个特征的判断,分支代表判断结果,而每个叶子节点则表示最终的预测结果。通俗来说,决策树就像是你在做选择题时,每一道选择都让你一步步缩小范围,直到最终确定一个答案。
决策树的构建
构建决策树时,我们需要考虑如何选择一个最优的特征进行分割。最常见的选择标准是信息增益和基尼指数。
-
信息增益(Information Gain):衡量使用某个特征进行数据划分后,信息的不确定性减少的程度。信息增益越大,意味着用该特征划分后,数据的纯度提高得越多。
信息增益计算公式:
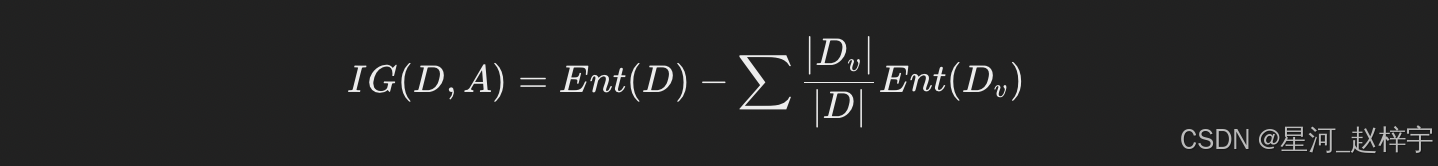
其中,D是数据集,A 是候选特征,Dv 是数据集在特征 A 的某个值上的子集,Ent 表示熵。
-
基尼指数(Gini Impurity):衡量数据集的不纯度,越小表示数据集越纯。决策树通过选择基尼指数最小的特征来进行划分。
基尼指数公式:
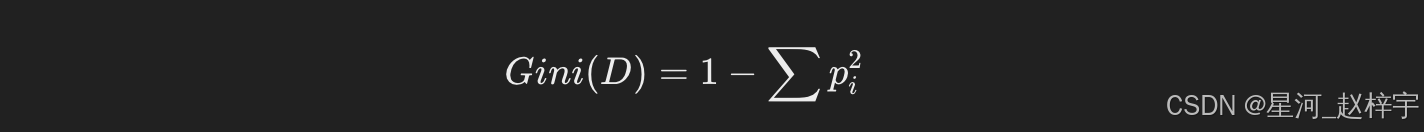
其中,pi 是每个类在数据集中的概率。
决策树的优缺点
-
优点:
- 直观易懂:可以通过树状图展示,非常适合可视化。
- 适用于非线性问题:可以处理特征之间复杂的关系。
- 可以处理缺失值:决策树具有较好的容错能力。
-
缺点:
- 容易过拟合:特别是在数据量小且特征复杂时,决策树容易完全拟合训练数据,导致泛化能力差。
- 不稳定:小的变化可能导致决策树结构发生较大变化。
决策树的应用
在NLP中,决策树常用于分类任务,比如情感分析、文本分类等。它能够通过将文本数据中的特征(例如词频、TF-IDF值等)输入决策树模型,进行分类预测。
3.3.2 随机森林(Random Forest)
随机森林简介
随机森林是集成学习(Ensemble Learning)的一种方法,它通过构建多棵决策树,并将这些树的预测结果进行集成(多数投票或平均)来提高预测的准确性和稳定性。简单来说,随机森林就像是一个拥有多个专家的委员会,每个专家(即每棵树)都有不同的见解,最终委员会根据多数意见做出决策。
随机森林的优势在于通过“投票”来减小单个决策树可能出现的过拟合问题,能够提高模型的泛化能力。
随机森林的构建
-
Bootstrap抽样:随机森林的每棵树都是在原始数据的一个随机子集上训练的。这个过程叫做Bootstrap抽样。通过对数据集进行有放回的抽样,可以得到多个不同的训练子集。
-
特征选择:每棵决策树在每个节点分裂时,都会从特征中随机选择一部分来决定最佳的分割特征。这种随机性有助于减小模型的方差。
随机森林的优缺点
-
优点:
- 高准确率:通过集成多棵树,随机森林通常能获得比单棵决策树更高的预测精度。
- 减少过拟合:通过引入随机性,减小了单棵决策树可能出现的过拟合问题。
- 处理大规模数据:随机森林可以处理大量的数据和高维度特征。
-
缺点:
- 模型复杂:相对于单棵决策树,随机森林需要更多的计算资源。
- 可解释性差:由于是集成了多棵树,模型的可解释性不如单棵决策树。
随机森林的应用
在NLP中,随机森林可用于文本分类、情感分析等任务。通过使用随机森林模型,可以在多个特征空间中训练决策树,最终通过集成的方式提高文本分类的准确性。
3.3.3 代码示例:使用决策树和随机森林进行文本分类
下面是一个简单的Python代码示例,演示如何使用决策树和随机森林进行文本分类。
# 导入必要的库
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 示例数据
documents = ["I love programming", "Python is amazing", "I love Python", "I enjoy coding in Python"]
labels = [1, 1, 1, 0] # 1: 正面,0: 负面
# 使用TF-IDF对文本进行向量化
vectorizer = TfidfVectorizer()
X = vectorizer.fit_transform(documents)
y = labels
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=42)
# 使用决策树进行训练和预测
dt_model = DecisionTreeClassifier(random_state=42)
dt_model.fit(X_train, y_train)
dt_pred = dt_model.predict(X_test)
print("决策树准确率:", accuracy_score(y_test, dt_pred))
# 使用随机森林进行训练和预测
rf_model = RandomForestClassifier(random_state=42)
rf_model.fit(X_train, y_train)
rf_pred = rf_model.predict(X_test)
print("随机森林准确率:", accuracy_score(y_test, rf_pred))
总结
- 决策树是一种直观、易于理解的分类算法,适用于许多NLP任务,尤其是当数据量较小或者特征比较简单时。
- 随机森林通过集成多棵决策树的预测结果,能提高模型的准确性和稳定性,尤其适用于大规模数据和复杂任务。
在NLP中,决策树和随机森林虽然不如深度学习模型那样强大,但它们依然是处理文本分类问题时非常有用的工具,特别是在特征较为简单和数据量不太庞大的情况下。通过合理选择和调优这些模型,你可以在很多任务中获得不错的效果。
3.4 条件随机场(CRF)与隐马尔可夫模型(HMM)
你有没有想过,如何理解一个句子中的每个词与其他词之间的关系呢?比如,“我喜欢自然语言处理”这句话,词与词之间的关系不仅仅是单纯的“喜欢”和“自然语言处理”这些词的组合,它们之间还有着复杂的顺序和依赖关系。这些关系的建模,不仅是自然语言处理(NLP)的关键,也是许多实际应用的基础,如命名实体识别(NER)、词性标注(POS tagging)等任务。
在这方面,有两个经典的模型特别重要:隐马尔可夫模型(HMM)和条件随机场(CRF)。它们被广泛应用于序列标注任务,这些任务中每个输入都对应一个序列,而输出也是一个序列。比如,对于一段文本中的每个词,HMM和CRF都可以帮助我们标注它们的词性、命名实体类型,甚至可以帮助理解词语之间的更深层次关系。
3.4.1 隐马尔可夫模型(HMM)
HMM简介
**隐马尔可夫模型(Hidden Markov Model, HMM)**是一个统计模型,用于描述一个由隐藏的状态序列生成观测序列的过程。通俗来说,HMM假设我们有一个不可直接观察的隐状态序列(例如,词性标签),这些隐状态序列会根据某种概率分布产生我们可以观察到的输出(例如,单词)。HMM通过学习观测序列与隐状态序列之间的依赖关系来进行预测。
HMM的基本要素包括:
- 状态集合(State Set):这些状态是我们想要预测的目标。比如在词性标注任务中,状态集合就是词性标签(例如,名词、动词、形容词等)。
- 观测集合(Observation Set):这些是我们可以观察到的输入。比如在词性标注任务中,观测集合就是输入文本中的词语。
- 转移概率(Transition Probabilities):表示从一个隐状态转移到另一个隐状态的概率。
- 发射概率(Emission Probabilities):表示从一个隐状态生成某个观测的概率。
- 初始状态概率(Initial State Probabilities):表示序列开始时处于某个隐状态的概率。
HMM的工作原理
HMM的目标是基于观测序列来推测隐状态序列,解决问题的常见方法包括:
- 前向算法(Forward Algorithm):用于计算给定观测序列的概率。
- 维特比算法(Viterbi Algorithm):用于寻找给定观测序列下最可能的隐状态序列。
HMM的优缺点
- 优点:
- 可以通过计算观测序列的概率来进行任务的评估。
- 适用于有明确顺序依赖的任务,例如词性标注、命名实体识别等。
- 缺点:
- HMM假设每个状态的输出仅依赖于当前状态,即每个状态的发射仅与当前状态有关,不考虑更长远的历史信息。这个假设对于一些复杂的自然语言任务来说是一个限制。
- HMM对于状态转移和观测分布的假设较强,这会导致模型的灵活性较差。
HMM在NLP中的应用
在NLP中,HMM主要应用于序列标注任务,例如:
- 词性标注:根据上下文推测每个词的词性。
- 命名实体识别:识别文本中的专有名词,如人名、地名、机构名等。
- 语音识别:通过语音信号的序列来推测语音对应的文字。
3.4.2 条件随机场(CRF)
CRF简介
**条件随机场(Conditional Random Field, CRF)**是一种判别式模型(与HMM的生成式模型相对),用于解决标注和分割问题,尤其适用于序列数据。与HMM不同,CRF通过直接建模给定输入序列条件下的输出序列的概率分布,而不假设输入和输出之间的生成过程。因此,CRF在建模时能够灵活地利用更多的特征,并能有效克服HMM的限制。
在CRF中,目标是根据输入序列生成一个标注序列。与HMM相比,CRF不需要显式建模生成过程,而是直接在条件下学习输入与输出之间的关系。
CRF的工作原理
CRF通过定义一个条件概率模型来计算给定输入序列 X=(x1,x2,...,xn)X = (x_1, x_2, ..., x_n)X=(x1,x2,...,xn) 和输出序列 Y=(y1,y2,...,yn)Y = (y_1, y_2, ..., y_n)Y=(y1,y2,...,yn) 的联合概率:
P(Y∣X)=1Z(X)exp(∑i,jλijfij(xi,yi,yi−1))P(Y|X) = \frac{1}{Z(X)} \exp\left(\sum_{i,j} \lambda_{ij} f_{ij}(x_i, y_i, y_{i-1})\right)P(Y∣X)=Z(X)1exp(i,j∑λijfij(xi,yi,yi−1))
其中:
- λij\lambda_{ij}λij 是模型的参数;
- fij(xi,yi,yi−1)f_{ij}(x_i, y_i, y_{i-1})fij(xi,yi,yi−1) 是特征函数,用于描述输入和输出之间的关系;
- Z(X)Z(X)Z(X) 是规范化常数,保证所有输出序列的概率和为1。
CRF通过最大化训练数据的对数似然函数来学习参数,通常使用梯度下降等方法来优化。
CRF的优缺点
- 优点:
- CRF能够考虑全局信息(即整个序列),比HMM更加灵活,能有效避免HMM的独立性假设。
- CRF能够使用丰富的特征,并且能够通过高维特征表示(如词性、上下文等)来提高模型性能。
- 缺点:
- 训练CRF需要较大的计算开销,特别是当特征空间非常大的时候。
- 模型的可解释性差,尤其是在处理复杂特征时。
CRF在NLP中的应用
CRF在NLP中主要用于序列标注任务,例如:
- 词性标注:通过CRF模型,根据上下文信息来标注每个词的词性。
- 命名实体识别:识别文本中的人名、地名、机构名等。
- 信息抽取:从文本中抽取结构化信息。
3.4.3 HMM与CRF的比较
| 特性 | 隐马尔可夫模型(HMM) | 条件随机场(CRF) |
|---|---|---|
| 模型类型 | 生成式模型(生成观测序列的概率) | 判别式模型(直接建模输出给定输入的概率) |
| 状态依赖 | 假设每个状态只依赖于前一个状态 | 通过条件概率建模所有依赖关系 |
| 特征利用 | 利用有限的特征(通常只依赖于当前状态和观测) | 能够使用丰富的特征(如上下文、词性等) |
| 训练复杂度 | 相对简单,易于实现 | 训练过程复杂,涉及到全局优化和特征选择 |
| 应用场景 | 适用于简单的序列标注任务,如语音识别、POS标注 | 适用于复杂的序列标注任务,如NER、信息抽取等 |
3.4.4 代码示例:使用HMM与CRF进行词性标注
HMM示例
import nltk
from nltk.corpus import treebank
from nltk.tag import hmm
from nltk.probability import LaplaceProbDist
# 下载treebank数据集并查看数据
nltk.download('treebank')
nltk.download('universal_tagset')
train_sents = treebank.tagged_sents()[:3000] # 使用前3000个句子作为训练数据
test_sents = treebank.tagged_sents()[3000:] # 剩下的数据作为测试数据
# 设置特征提取函数
def pos_features(sentence, index):
word = sentence[index][0]
features = {
'word': word,
'is_capitalized': word[0].upper() == word[0],
'is_stopword': word.lower() in nltk.corpus.stopwords.words('english'),
'word_length': len(word),
'prev_word': '' if index == 0 else sentence[index - 1][0],
'next_word': '' if index == len(sentence) - 1 else sentence[index + 1][0]
}
return features
# 将训练数据转换为特征向量
train_data = []
for sent in train_sents:
features = [pos_features(sent, i) for i in range(len(sent))]
labels = [label for word, label in sent]
train_data.append(list(zip(features, labels)))
# 使用HMM训练模型
trainer = hmm.HiddenMarkovModelTrainer()
hmm_model = trainer.train(train_data)
# 测试HMM模型
test_data = [pos_features(sent, i) for sent in test_sents for i in range(len(sent))]
hmm_predictions = hmm_model.tag_sents(test_data)
# 显示模型的部分预测结果
for sent, prediction in zip(test_sents[:5], hmm_predictions[:5]):
print("Sentence:", sent)
print("Predicted:", prediction)
print()
解释:
- 我们使用了
nltk的treebank语料库,它已经标注了每个词的词性。我们用这个语料库来训练和测试HMM模型。 pos_features函数用于提取每个词的特征,这些特征可以帮助HMM更好地做出预测。HiddenMarkovModelTrainer用于训练HMM模型,通过隐含状态(如词性)和观察数据(如词)之间的关系进行训练。- 然后,我们用训练好的HMM模型对测试数据进行词性标注。
CRF示例
我们使用条件随机场(CRF)来进行更复杂的词性标注。CRF允许我们使用更多的特征,并且可以在序列标注中捕捉到更复杂的上下文信息。
import nltk
from sklearn_crfsuite import CRF
from sklearn_crfsuite.metrics import flat_classification_report
# 使用Treebank语料库
nltk.download('treebank')
train_sents = treebank.tagged_sents()[:3000]
test_sents = treebank.tagged_sents()[3000:]
# 特征提取函数,生成更多的上下文特征
def word2features(sent, i):
word = sent[i][0]
features = {
'word': word,
'is_capitalized': word[0].upper() == word[0],
'is_stopword': word.lower() in nltk.corpus.stopwords.words('english'),
'word_length': len(word),
'prev_word': '' if i == 0 else sent[i - 1][0],
'next_word': '' if i == len(sent) - 1 else sent[i + 1][0],
'prev_tag': '' if i == 0 else sent[i - 1][1],
'next_tag': '' if i == len(sent) - 1 else sent[i + 1][1],
}
return features
# 提取训练和测试数据的特征
X_train = [[word2features(sent, i) for i in range(len(sent))] for sent in train_sents]
y_train = [[label for word, label in sent] for sent in train_sents]
X_test = [[word2features(sent, i) for i in range(len(sent))] for sent in test_sents]
y_test = [[label for word, label in sent] for sent in test_sents]
# 训练CRF模型
crf = CRF(algorithm='lbfgs', max_iterations=100)
crf.fit(X_train, y_train)
# 使用CRF进行预测
y_pred = crf.predict(X_test)
# 打印模型评估结果
print(flat_classification_report(y_test, y_pred))
解释:
word2features函数用于提取每个词的特征,这些特征不仅包含了当前词的信息,还包括了相邻词的信息,以及相邻词的标签(prev_tag和next_tag)。CRF模型是通过sklearn_crfsuite库来实现的,我们使用了lbfgs算法来训练CRF。flat_classification_report用来评估模型的性能,输出每个标签的精度、召回率和F1值。
CRF vs HMM的比较
-
HMM的优点:
- 计算上较为简单,特别是当状态空间比较小的时候,训练和推理效率较高。
- 模型的数学理论简单,可以很好地处理一阶依赖(即当前状态只依赖于前一个状态)。
-
CRF的优点:
- 能够捕捉到更复杂的依赖关系,可以根据更多的上下文特征来优化标签预测。
- 允许特征之间的相互依赖,因此在处理更复杂的任务时能取得更好的效果。
-
应用场景:
- HMM通常用于简单的序列标注任务,尤其是在数据有限的情况下,HMM往往能取得不错的效果。
- CRF则适用于那些依赖更复杂特征或上下文信息的任务,如命名实体识别、词性标注等。
总结
- HMM和CRF是经典的序列标注模型,在NLP中有着广泛的应用。HMM通过马尔可夫假设建模状态序列,计算相对简单;而CRF则能够捕捉更复杂的依赖关系,适合更加复杂的任务。
- 在处理任务时,选择哪种模型取决于数据的复杂性和任务的需求。CRF通常能通过更多的上下文信息和特征提高预测的准确性,而HMM则以其简单和高效的计算方式在许多场合中依然表现良好。
3.5 模型评估与比较(准确率、召回率、F1 分数等)
你可能曾经听过很多关于准确率、召回率和F1 分数的术语,它们是衡量分类模型性能的核心指标。实际上,模型的评估不仅仅是看准确率,还要根据实际需求选择合适的评估标准,尤其是在面对不平衡数据集时,准确率往往不能完全代表模型的好坏。那么,如何通过这些指标对模型进行全面评估呢?我们一起来深入探讨这些常见的评估指标,并通过具体的例子进行讲解。
3.5.1 准确率(Accuracy)
准确率是机器学习中最常见的评估指标,计算公式非常简单:

简单来说,就是模型预测正确的样本占总样本数的比例。
准确率的优点:
- 它是直观且容易理解的。
- 适用于类别平衡的情况。
准确率的缺点:
- 当数据类别不平衡时,准确率容易出现误导。例如,在二分类任务中,如果90%的样本属于负类(例如“没有疾病”),而模型始终预测为负类(“没有疾病”),那么准确率会达到90%,但模型显然没什么用。
例子:
假设我们有一个分类模型来判断是否是垃圾邮件,测试集有100封邮件,其中有90封是非垃圾邮件,10封是垃圾邮件。如果模型预测所有邮件都为非垃圾邮件,那么准确率就是:
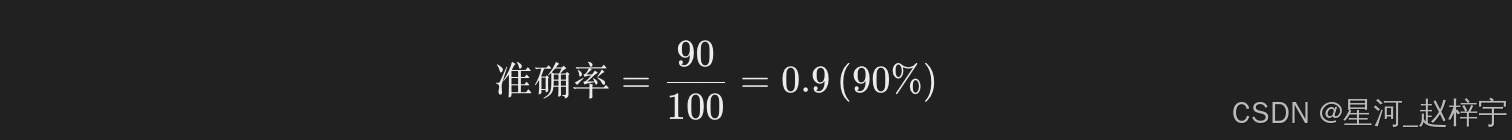
虽然准确率很高,但这个模型几乎没有做出有意义的预测,因为它把所有邮件都预测为非垃圾邮件。
3.5.2 召回率(Recall)
召回率,也叫灵敏度或查全率,衡量的是模型捕捉到的实际正类样本的比例。公式为:

在垃圾邮件的例子中,召回率衡量的是所有真正的垃圾邮件中,有多少被模型正确地预测为垃圾邮件。
召回率的优点:
- 适用于对“漏掉”正类样本非常敏感的任务。比如在疾病检测中,漏掉一个病人的诊断可能带来严重后果。
召回率的缺点:
- 当我们优化召回率时,可能会增加假阳性(即错误预测为正类的负类样本),导致模型的性能下降。
例子:
假设模型检测垃圾邮件时,预测出其中8封垃圾邮件为正类(即垃圾邮件),但实际上测试集中有10封垃圾邮件,那么召回率就是:
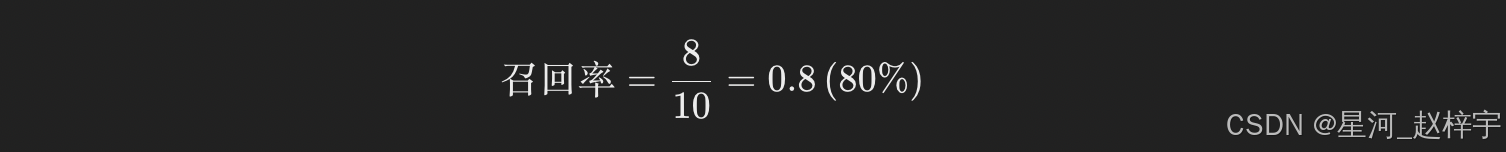
这意味着模型漏掉了2封垃圾邮件。
3.5.3 精确率(Precision)
精确率是与召回率互为补充的指标,它衡量的是模型预测为正类的样本中,有多少是实际的正类。公式为:

如果我们在垃圾邮件检测中,模型预测有12封邮件为垃圾邮件,其中8封是正确的垃圾邮件,4封是非垃圾邮件,那么精确率就是:
精确率 = 8/12 = 0.67
精确率的优点:
- 适用于对“错误警报”很敏感的任务。例如,在垃圾邮件过滤中,过多的误判可能会导致用户失去对系统的信任。
精确率的缺点:
- 精确率可能会忽略模型对实际正类的预测能力,只关注预测结果的准确性。
3.5.4 F1 分数(F1-Score)
F1 分数是精确率和召回率的调和平均数,尤其适用于类不平衡的数据集,因为它考虑了精确率和召回率的平衡。如果一个模型的召回率和精确率差距很大,那么F1 分数会较低。公式为:

F1 分数的优点:
- 它提供了一个平衡的评估,可以同时考虑精确率和召回率。
- 适用于类不平衡的任务,例如垃圾邮件分类、疾病诊断等。
例子:
继续以上的例子,假设精确率为0.67,召回率为0.8,那么F1 分数计算如下:
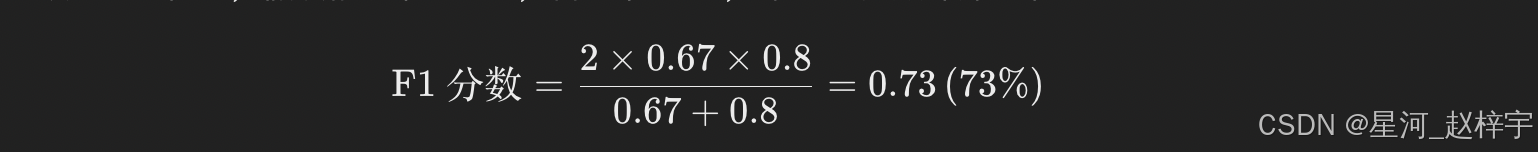
这个F1分数比单独的精确率和召回率更具综合性,是一个更为全面的性能评估指标。
3.5.5 ROC 曲线与 AUC(曲线下面积)
在处理二分类问题时,除了使用准确率、召回率和精确率等指标外,我们还可以利用ROC 曲线(Receiver Operating Characteristic Curve)和AUC(Area Under Curve)来评估模型的性能。
ROC曲线是一个以假阳性率(FPR)为横坐标,真正率(TPR,即召回率)为纵坐标的曲线图。AUC是ROC曲线下的面积,AUC值越接近1,表示模型的性能越好。
3.5.6 多类别分类的评估
在多类别分类任务中,常见的评估方式是使用宏平均(Macro Average)和加权平均(Weighted Average)。这两种方法分别是将每个类别的指标独立计算后再求平均,或者根据每个类别的样本数量加权平均。
3.5.7 模型评估总结
- 准确率:在数据平衡时,适用;但对不平衡数据集不合适。
- 精确率:强调预测为正类时的正确性,适用于不希望错报正类的场合。
- 召回率:强调正确识别正类,适用于需要捕捉所有正类样本的场景。
- F1 分数:精确率和召回率的折衷,适合于类不平衡任务。
- AUC 和 ROC:评估二分类模型,AUC越高越好。
总结
选择合适的评估指标非常重要,要根据具体的任务需求来做决策。对不同类型的任务,可能需要不同的衡量标准。了解这些指标的含义并在实际中进行灵活应用,能够帮助你在面对复杂的NLP任务时做出更加科学和合理的模型评估。
3.6 模型优化技巧(超参数调优、交叉验证等)
模型的训练过程就像是打磨一块石雕,数据就是原始石块,算法和技术就是雕刻工具,而优化过程则是最终让这块石雕展现出完美细节的关键。在这个过程中,超参数调优和交叉验证等技巧是你手中的利器,它们可以帮助你找到最优的模型配置,从而提升模型的精度、鲁棒性和泛化能力。
3.6.1 超参数调优(Hyperparameter Tuning)
在机器学习中,超参数是那些在训练开始前就需要手动设置的参数,与模型本身的结构、算法流程等不同。超参数对模型的表现有很大影响,常见的超参数包括:
- 学习率(Learning Rate):控制模型每次参数更新的步长。如果步长过大,可能会错过最优解;如果步长过小,训练可能会变得过慢,甚至陷入局部最优。
- 正则化参数(Regularization Parameter):控制模型的复杂度,防止过拟合。
- 树的深度(Tree Depth):对于决策树等模型,树的深度决定了模型的复杂度,太深可能会导致过拟合,太浅则可能无法捕捉数据的复杂性。
- 批大小(Batch Size):在神经网络训练中,批大小决定每次更新模型时使用的样本数量。
调优方法:网格搜索与随机搜索
-
网格搜索(Grid Search)
网格搜索是一种穷举法,遍历超参数空间的所有可能组合。假设你有两个超参数,每个超参数有三个候选值,那么网格搜索会尝试每一种组合,最终找到最佳配置。虽然简单,但当超参数空间较大时,计算量会非常庞大。例如:
- 学习率:[0.01, 0.1, 0.5]
- 批大小:[16, 32, 64] 网格搜索将尝试每个学习率和批大小的组合:
(0.01, 16), (0.01, 32), (0.01, 64), (0.1, 16), (0.1, 32), (0.1, 64), (0.5, 16), (0.5, 32), (0.5, 64)。
优点:简单直观,适合超参数空间较小的情况。
缺点:当超参数空间较大时,计算开销巨大。 -
随机搜索(Random Search)
随机搜索通过在超参数空间中随机选择一些组合进行尝试,相比网格搜索,它不遍历所有的组合,而是选择一定数量的随机组合进行试验。这样可以在较短的时间内找到不错的参数设置,尤其适合大规模的超参数空间。优点:计算效率更高,尤其是在参数空间很大的时候。
缺点:可能错过最优解,但通常可以找到一个“足够好”的解。
实际操作
假设我们用scikit-learn进行超参数调优,以下是一个简单的网格搜索示例:
from sklearn.model_selection import GridSearchCV
from sklearn.ensemble import RandomForestClassifier
# 设置要调优的超参数
param_grid = {
'n_estimators': [100, 200, 300],
'max_depth': [10, 20, 30],
'min_samples_split': [2, 5, 10]
}
# 创建模型
model = RandomForestClassifier()
# 使用网格搜索调优超参数
grid_search = GridSearchCV(estimator=model, param_grid=param_grid, cv=3, verbose=2, n_jobs=-1)
grid_search.fit(X_train, y_train)
# 输出最优超参数
print("Best parameters found: ", grid_search.best_params_)
通过这个例子,GridSearchCV 会在给定的参数网格中寻找最优的超参数组合。
3.6.2 交叉验证(Cross-Validation)
交叉验证是评估机器学习模型性能的一个非常有效的技术,尤其是在数据有限时。它通过将数据集分成多个小的子集(折叠),并在不同的训练集和验证集上多次训练和评估模型,从而获得更加稳定和可靠的评估结果。
K折交叉验证(K-Fold Cross-Validation)
K折交叉验证将数据集分为K个子集(折叠)。然后,模型会使用K-1个子集作为训练集,剩下的1个子集作为验证集。这个过程会重复K次,每次验证集不同,最终评估结果是所有验证集结果的平均。
例如,假设我们使用5折交叉验证(K=5),数据集被分为5个子集,我们将进行5次训练,每次训练使用4个子集作为训练数据,剩下1个子集作为验证数据,最终结果是5次验证结果的平均值。
优点:
- 充分利用数据集,避免了简单划分训练集和验证集可能带来的偏差。
- 相比单一的训练和测试集,交叉验证能更好地评估模型的稳定性和泛化能力。
缺点:
- 计算成本较高,尤其是在数据集较大时,因为需要多次训练模型。
实际操作
使用scikit-learn进行交叉验证,代码如下:
from sklearn.model_selection import cross_val_score
from sklearn.ensemble import RandomForestClassifier
# 创建模型
model = RandomForestClassifier()
# 使用K折交叉验证(这里设为5折)
scores = cross_val_score(model, X, y, cv=5)
# 输出交叉验证的得分
print(f'Cross-validation scores: {scores}')
print(f'Mean score: {scores.mean()}')
这个代码会自动在数据集上进行5折交叉验证,并输出每折的得分和最终的平均得分。
3.6.3 模型优化总结
- 超参数调优是提升模型性能的关键,可以通过网格搜索和随机搜索来寻找最优配置。
- 交叉验证提供了一种稳定可靠的评估方法,尤其适用于数据有限时,帮助我们更好地了解模型的泛化能力。
总结
在机器学习模型的训练过程中,调优超参数和使用交叉验证是非常重要的步骤。通过不断优化模型的超参数,并通过交叉验证来评估模型的稳定性和泛化能力,你可以有效提高模型的预测能力,让它在面对真实世界的数据时表现得更加出色。
希望通过这部分内容,你对模型优化有了更深的理解,也能在实际项目中灵活运用这些技巧!


















 1833
1833

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









