






本书全卷:
全书目录
第一部分:初识Python——从“Hello, World!”开始
第一章:Python的魅力与起源
- 为什么Python这么受欢迎?
- 从蛇到编程语言:Python的成长故事。
- Python和其他语言的对比(Python是如何一鸣惊人的)。
第二章:安装与开发环境配置
- 让Python住进你的电脑:安装与配置指南。
- 理想的开发环境:IDE vs. 代码编辑器的选择。
第三章:基础语法与数据类型
- 你最亲密的伙伴:变量、常量与数据类型。
- 列表、元组、字典:你身边的“智能集合”。
- 数据类型转换:Python是怎样“变魔术”的!
第四章:控制流——让程序像你一样思考
- 判断、循环:让代码在不同情况下做出决策。
- 理解“缩进”魔法:Python如何让你“看得见”代码的逻辑。
第二部分:数据处理与操作——Python与数据的亲密接触
第五章:函数与模块:让代码更有条理
- 函数的定义与调用:让代码更简洁易读。
- 模块与包:如何让你的代码变成一个大“宝藏”。
第六章:字符串与正则表达式:文本背后的艺术
- 字符串的魔法:切片、格式化、操作。
- 正则表达式:如何让Python帮你解锁“隐藏文本”。
第七章:文件操作:你的代码也能“存档”
- 打开、读取与写入文件:如何和文件“亲密接触”。
- CSV、JSON文件:如何让Python帮你整理数据。
第三部分:面向对象编程(OOP)——让代码更“优雅”
第八章:类与对象:用代码创建世界
- 类的定义:给对象们一个家。
- 面向对象的优势:让你的代码有条理、有结构。
第九章:继承与多态:让Python“继承”智慧
- 继承:如何让新类“继承”父类的能力。
- 多态:一个对象多个表现,Python怎么做到的?
第十章:封装与抽象:保护代码的隐私
- 封装:让数据和函数合二为一,保护你的代码隐私。
- 抽象:隐藏复杂性,展示简单易用的接口。
第四部分:高级特性与技巧——让你成为“Python大佬”
第十一章:装饰器与闭包:让Python更具“魔法感”
- 装饰器:如何为现有函数增加功能(不修改原函数!)。
- 闭包:Python是怎么“记住”你的函数的。
第十二章:生成器与迭代器:Python的懒人模式
- 生成器:如何用更少的内存做更多的事。
- 迭代器:一步一步走,获取无限数据。
第十三章:上下文管理器与异常处理:应对突发状况的“万能钥匙”
- 上下文管理器:如何确保资源被安全释放。
- 异常处理:Python如何优雅地应对错误。
第五部分:Python与外部世界的沟通——网络、数据库与Web开发
第十四章:Python与网络:让代码“畅游互联网”
- 网络请求与响应:如何让你的Python和服务器沟通。
- 基础网络协议:HTTP、FTP,Python怎么应对这些?
第十五章:Python与数据库:给数据存个“家”
- 连接数据库:如何让Python和数据库建立联系。
- SQL与ORM:Python如何与数据库高效互动。
第十六章:Web开发:如何用Python做一个简单的Web应用
- Flask与Django:Python的Web开发框架大比拼。
- 搭建一个小网站:用Flask做个“Hello, World!”。
第六部分:Python与数据采集、清洗、搜索——从零开始处理大数据
第十七章:数据采集:用Python做爬虫
- 爬虫入门:如何用Python抓取网页数据
- 动态网页爬取与Selenium
- 反爬虫技术与应对策略
第十八章:数据清洗:让脏数据变得有价值
- 数据预处理:如何清洗和准备数据
- 文本数据清洗:从噪音中提取有用信息
- 如何对数据进行标注与分类
第十九章:数据存储:如何存放和管理大数据
- 使用SQL数据库存储数据
- 向量数据库:如何存储高维数据
- 使用Elasticsearch进行全文搜索
第二十章:搜索引擎与数据索引
- 如何创建一个简易的搜索引擎
- 向量检索与相似度匹配
第七部分:Python在数据科学与人工智能中的应用——你也可以成为“数据科学家”
第二十一章:数据科学入门:Python如何处理大数据
- NumPy与Pandas:让你操作数据如虎添翼。
- 数据清洗与分析:Python如何帮你发现数据背后的“秘密”。
第二十二章:机器学习与人工智能:Python的智能进化
- 使用Scikit-learn做机器学习:让Python为你“预测未来”。
- TensorFlow与PyTorch:Python如何驾驭深度学习。
第八部分:Python人工智能实战——AI的挑战与机遇
第二十三章:深入AI实战:加载与微调预训练模型
- 从TensorFlow到HuggingFace:开源AI模型的加载与微调
- 数据准备与预处理:为微调做好准备
- 模型选择与评估策略
- 微调技巧与最佳实践
- 部署与优化:将模型投入生产环境
第二十四章:计算机视觉(CV)实战
- 如何用Python执行图像识别与处理任务
- 物体检测与语义分割:从YOLO到Mask R-CNN
- 图像增强与数据增广技术
- 实时视频分析与流媒体处理
- 深度学习架构优化与超参数调整
- 高级主题:生成对抗网络(GANs)与自监督学习
第二十五章:自然语言处理(NLP)实战
- 从BERT到GPT:如何处理文本并生成内容
- 文本分类与情感分析
- 命名实体识别(NER)与关系抽取
- 序列标注任务:POS Tagging与Dependency Parsing
- 对话系统与聊天机器人开发
- 机器翻译与跨语言处理
- 实战案例:NLP项目从数据准备到部署上线
第二十六章:多模态模型应用:跨越文本、图像与声音的界限
- 跨模态的AI应用:图像+文本=理解
- 多模态融合方法与策略
- 视觉语言预训练模型:CLIP及其应用
- 基于多模态数据的生成任务
- 音频与视觉信息的联合处理
- 实战案例:构建一个简单的多模态交互系统
第二十七章:AI模型的部署与上线
- 从训练到生产:如何将AI模型部署为Web服务
- 模型优化与加速:提高推理效率
- 容器化与微服务架构
- 监控与维护:确保服务的稳定性和可靠性
- 安全考量与隐私保护
- 实战案例:从训练到部署一个安全的AI服务
第二十八章:AI项目中的常见问题与挑战
- 模型过拟合、数据不均衡问题的解决
- 数据质量问题及其改进策略
- 特征工程的重要性与实践技巧
- 模型解释性与可解释AI(XAI)
- 性能瓶颈分析与优化
- 道德伦理与法律合规考量
第二十九章:实践项目:打造一个AI助手
- 从零到一:开发一个人工智能助手
- 对话管理系统的设计与实现
- 自然语言处理模块的集成与优化
- 用户界面与交互体验设计
- 部署与持续改进:让AI助手上线并不断进化
第九部分:Python的最佳实践——代码优化与项目管理
第三十章:编写高效代码:Python如何跑得更快
- 时间复杂度与空间复杂度:如何用Python写出“高效代码”。
- 性能调优与内存管理:如何让Python为你“省心”。
第三十一章:代码的可维护性:如何写出“别人看得懂”的代码
- 良好的代码风格:PEP8标准与代码重构。
- 单元测试与调试技巧:如何让你的代码无懈可击。
第三十二章:项目管理与部署:将代码推向“实战”
- 使用Git进行版本控制与团队协作。
- 部署Python应用:如何把代码变成实际可用的应用。
附录部分:Python开发的实用资源
-
常见Python库与框架
-
Python工具链与开发环境
-
开源预训练模型的资源库
-
AI与深度学习领域的重要论文与研究资源
-
Python开发者社区与学习资源
-
Python开发中的调试工具与技巧
第七部分:Python在数据科学与人工智能中的应用——你也可以成为“数据科学家”
第二十一章:数据科学入门:Python如何处理大数据
- NumPy与Pandas:让你操作数据如虎添翼。
- 数据清洗与分析:Python如何帮你发现数据背后的“秘密”。
21.1 NumPy与Pandas:让你操作数据如虎添翼
欢迎来到“数据科学”的魔法世界!在当今这个数据驱动的时代,数据科学就像是一位能够从海量数据中提取有价值信息的“数据魔法师”。Python作为数据科学领域中最受欢迎的编程语言,提供了强大的工具和库来帮助你处理和分析大数据。今天,我们将深入探讨Python中两个最重要的数据处理库——NumPy和Pandas,看看它们如何让你在数据处理的旅程中如虎添翼。
21.1.1 NumPy:Python中的数值计算基石
NumPy(Numerical Python)是Python中用于科学计算的基础库,提供了支持多维数组和矩阵运算的功能,以及大量的数学函数库。NumPy是许多其他数据科学库(如Pandas、SciPy、Matplotlib等)的基础。
21.1.1.1 NumPy的主要特点
1. 多维数组对象(ndarray):
NumPy的核心是ndarray对象,它是一个具有固定大小和相同数据类型的多维数组。
示例:
import numpy as np
# 创建一个一维数组
array_1d = np.array([1, 2, 3, 4, 5])
print(array_1d) # 输出: [1 2 3 4 5]
# 创建一个二维数组
array_2d = np.array([[1, 2, 3], [4, 5, 6]])
print(array_2d)
# 输出:
# [[1 2 3]
# [4 5 6]]
2. 广播机制:
NumPy支持广播机制,允许不同形状的数组进行算术运算。
示例:
a = np.array([1, 2, 3])
b = 2
c = a * b
print(c) # 输出: [2 4 6]
3. 丰富的数学函数:dddd
NumPy提供了大量的数学函数,如sin、cos、exp、log等。
示例:
a = np.array([0, np.pi/2, np.pi])
print(np.sin(a)) # 输出: [0.0000000e+00 1.0000000e+00 1.2246468e-16]
4. 线性代数运算:
NumPy支持矩阵运算,如矩阵乘法、矩阵转置、逆矩阵等。
示例:
A = np.array([[1, 2], [3, 4]])
B = np.array([[5, 6], [7, 8]])
C = np.dot(A, B)
print(C)
# 输出:
# [[19 22]
# [43 50]]
21.1.1.2 NumPy的优势
- 高性能:
- NumPy的底层实现是用C语言编写的,具有很高的计算性能。
- 内存效率:
- NumPy数组在内存中是连续存储的,节省内存空间。
- 丰富的功能:
- NumPy提供了大量的函数和工具,适用于各种科学计算任务。
21.1.2 Pandas:Python中的数据处理利器
Pandas是Python中用于数据分析和数据处理的强大库,提供了DataFrame和Series两种主要的数据结构。Pandas建立在NumPy之上,提供了更高级的数据操作功能。
21.1.2.1 Pandas的主要特点
1. DataFrame:
DataFrame是Pandas的核心数据结构,是一个类似于电子表格的二维表,具有行和列标签。
示例:
import pandas as pd
data = {
'姓名': ['张三', '李四', '王五'],
'年龄': [25, 30, 22],
'城市': ['北京', '上海', '广州']
}
df = pd.DataFrame(data)
print(df)
输出:
姓名 年龄 城市
0 张三 25 北京
1 李四 30 上海
2 王五 22 广州
2. Series:
Series是Pandas的一维数组结构,类似于列表,但具有标签。
示例:
s = pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd'])
print(s)
输出:
a 1
b 2
c 3
d 4
dtype: int64
3. 数据清洗与处理:
Pandas提供了丰富的数据清洗和处理功能,如缺失值处理、数据过滤、数据聚合等。
示例:
# 填充缺失值
df['年龄'].fillna(df['年龄'].mean(), inplace=True)
# 数据过滤
df_filtered = df[df['年龄'] > 23]
# 数据聚合
df_grouped = df.groupby('城市').agg({'年龄': 'mean'})
4. 数据导入与导出:
Pandas支持多种数据格式的导入和导出,如CSV、Excel、SQL数据库等。
示例:
# 导入CSV文件
df = pd.read_csv('data.csv')
# 导出到Excel
df.to_excel('output.xlsx', index=False)
21.1.2.2 Pandas的优势
- 易于使用:
- Pandas的API设计简洁,易于学习和使用。
- 强大的数据处理能力:
- Pandas提供了丰富的数据操作功能,适用于各种数据处理任务。
- 高效的数据分析:
- Pandas支持快速的数据分析和探索性数据分析(EDA)。
21.1.3 小结:数据科学的魔法工具
通过本节,你已经学习了NumPy和Pandas的基本概念和功能,就像掌握了“数据科学”的魔法工具。NumPy和Pandas是Python数据科学领域中最基础和最重要的库,它们提供了强大的数据处理和分析功能。希望你能灵活运用这些“魔法工具”,让你的数据处理和分析工作更加高效和高效,为编写更强大的数据科学程序打下坚实的基础。
21.2 数据清洗与分析:Python如何帮你发现数据背后的“秘密”
欢迎来到“数据洞察”的魔法实验室!在数据科学的世界中,数据清洗和数据分析就像是魔法师用来揭示数据背后隐藏信息的“魔法工具”。通过数据清洗,你可以去除数据中的噪音和错误,而数据分析则帮助你从数据中提取有价值的见解和模式。今天,我们将深入探讨如何使用Python进行数据清洗和分析,以及如何利用这些技术来发现数据背后的“秘密”。
21.2.1 数据清洗:去除噪音,净化数据
数据清洗是数据分析的第一步,旨在识别和纠正数据中的错误、不一致和缺失值。就像魔法师在施展魔法前需要净化魔法材料一样,数据清洗可以确保你的数据质量,从而提高分析结果的准确性。
21.2.1.1 处理缺失值
缺失值是数据集中常见的“噪音”,需要进行处理。
删除缺失值:
- 如果缺失值较少,可以选择删除包含缺失值的行或列。
示例:
import pandas as pd
df = pd.read_csv('data.csv')
df_cleaned = df.dropna()
填充缺失值:
- 使用均值、中位数、众数或插值法填充缺失值。
示例:
df['age'].fillna(df['age'].mean(), inplace=True)
21.2.1.2 处理重复数据
重复数据会干扰分析结果,需要进行去重处理。
示例:
df.drop_duplicates(inplace=True)
21.2.1.3 处理异常值
异常值是指数据集中与其他数据点显著不同的值,可能影响分析结果。
识别异常值:
- 使用统计方法(如IQR方法)或可视化方法(如箱形图)识别异常值。
示例:
Q1 = df['salary'].quantile(0.25)
Q3 = df['salary'].quantile(0.75)
IQR = Q3 - Q1
outliers = df[((df['salary'] < (Q1 - 1.5 * IQR)) | (df['salary'] > (Q3 + 1.5 * IQR)))]
处理异常值:
- 删除异常值或使用合理值进行替换。
示例:
df = df[~((df['salary'] < (Q1 - 1.5 * IQR)) | (df['salary'] > (Q3 + 1.5 * IQR)))]
21.2.1.4 数据转换
数据转换涉及将数据从一种格式转换为另一种格式,以满足分析需求。
标准化和归一化:
- 将数据缩放到特定范围(如0到1)或标准化为均值为0、标准差为1。
示例:
from sklearn.preprocessing import StandardScaler, MinMaxScaler
scaler = StandardScaler()
df['age_scaled'] = scaler.fit_transform(df[['age']])
scaler = MinMaxScaler()
df['salary_normalized'] = scaler.fit_transform(df[['salary']])
编码分类数据:
- 将分类变量转换为数值形式,如使用独热编码(One-Hot Encoding)或标签编码(Label Encoding)。
示例:
df = pd.get_dummies(df, columns=['gender', 'country'])
21.2.2 数据分析:揭示数据背后的“秘密”
数据分析是数据科学的核心,旨在从数据中提取有价值的见解和模式。通过数据分析,你可以发现数据中的趋势、关系和异常,从而为决策提供支持。
21.2.2.1 描述性统计分析
描述性统计分析用于总结和描述数据集的基本特征。
常用指标:
- 均值(Mean)、中位数(Median)、众数(Mode)。
- 标准差(Standard Deviation)、方差(Variance)。
- 范围(Range)、四分位数(Quartiles)。
示例:
import pandas as pd
df = pd.read_csv('data.csv')
print(df.describe())
21.2.2.2 可视化分析
可视化分析通过图表和图形来展示数据,帮助识别趋势和模式。
常用图表:
- 柱状图(Bar Chart)、折线图(Line Chart)、饼图(Pie Chart)。
- 散点图(Scatter Plot)、箱形图(Box Plot)、直方图(Histogram)。
示例:
import matplotlib.pyplot as plt
import seaborn as sns
sns.histplot(df['age'], kde=True)
plt.title('Age Distribution')
plt.xlabel('Age')
plt.ylabel('Frequency')
plt.show()
21.2.2.3 相关性分析
相关性分析用于衡量两个变量之间的线性关系。
相关系数:
- 皮尔逊相关系数(Pearson Correlation Coefficient)、斯皮尔曼相关系数(Spearman Correlation Coefficient)。
示例:
correlation_matrix = df.corr()
print(correlation_matrix)
21.2.2.4 回归分析
回归分析用于建模和分析变量之间的关系。
线性回归:
- 建模两个变量之间的线性关系。
示例:
from sklearn.linear_model import LinearRegression
X = df[['age']]
y = df['salary']
model = LinearRegression()
model.fit(X, y)
predictions = model.predict(X)
21.2.2.5 机器学习
机器学习算法可以用于更复杂的分析和预测任务。
示例:
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
X = df[['age', 'income']]
y = df['purchase']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
model = RandomForestClassifier()
model.fit(X_train, y_train)
predictions = model.predict(X_test)
21.2.3 小结:数据清洗与分析的魔法
通过本节,你已经学习了数据清洗和分析的基本概念和方法,就像掌握了“数据洞察”的魔法技巧。数据清洗和分析是数据科学中至关重要的一环,它们可以帮助你从数据中提取有价值的见解和模式。希望你能灵活运用这些“数据洞察魔法”,让你的数据分析工作更加高效和准确,为编写更强大的数据科学程序打下坚实的基础。
第二十二章:机器学习与人工智能:Python的智能进化
- 使用Scikit-learn做机器学习:让Python为你“预测未来”。
- TensorFlow与PyTorch:Python如何驾驭深度学习。
22.1 使用Scikit-learn做机器学习:让Python为你“预测未来”
欢迎来到“智能预测”的魔法课堂!在人工智能和机器学习的世界里,预测未来不再只是科幻小说中的情节。通过机器学习,我们可以让计算机从数据中学习模式,并利用这些模式进行预测和决策。而Scikit-learn是Python中最受欢迎的机器学习库之一,它提供了简单而强大的工具来实现各种机器学习任务。今天,我们将深入探讨如何使用Scikit-learn进行机器学习,让Python为你“预测未来”。
22.1.1 什么是机器学习?
机器学习是人工智能的一个分支,它通过算法和统计模型使计算机能够从数据中学习,并在没有明确编程指令的情况下进行预测和决策。机器学习可以分为以下几类:
1. 监督学习(Supervised Learning):
- 使用带标签的数据进行训练,目标是预测新数据的标签。
示例:分类(预测离散标签,如垃圾邮件检测)、回归(预测连续值,如房价预测)。
2. 无监督学习(Unsupervised Learning):
- 使用无标签的数据进行训练,目标是发现数据中的模式和结构。
示例:聚类(将数据分组,如客户细分)、降维(减少数据维度,如PCA)。
3. 半监督学习(Semi-supervised Learning):
- 结合少量带标签数据和大量无标签数据进行训练。
4. 强化学习(Reinforcement Learning):
- 通过与环境的交互进行学习,目标是最大化累积奖励。
示例:游戏AI、机器人控制。
22.1.2 Scikit-learn简介
Scikit-learn(也称为sklearn)是一个开源的Python机器学习库,提供了简单而高效的工具来实现数据挖掘和分析。它建立在NumPy、SciPy和Matplotlib之上,提供了广泛的机器学习算法和工具。
22.1.2.1 Scikit-learn的主要特点
1. 简洁的API:
Scikit-learn的API设计简洁,易于学习和使用。
示例:
from sklearn.linear_model import LogisticRegression
model = LogisticRegression()
model.fit(X_train, y_train)
predictions = model.predict(X_test)
2. 丰富的算法:
提供了多种监督学习和无监督学习算法,如线性回归、逻辑回归、决策树、支持向量机(SVM)、K近邻(KNN)、聚类算法等。
3. 数据预处理工具:
提供了丰富的数据预处理工具,如标准化、归一化、编码分类变量等。
4. 模型评估与选择:
提供了多种模型评估指标和交叉验证工具,帮助选择最佳模型。
5. 管道(Pipeline):
支持将多个步骤(如预处理、模型训练)组合成一个管道,简化工作流程。
22.1.3 使用Scikit-learn进行机器学习的基本步骤
22.1.3.1 数据准备
首先,需要准备用于训练和测试的数据集。
示例:
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
# 加载数据集
iris = load_iris()
X = iris.data
y = iris.target
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
22.1.3.2 数据预处理
对数据进行预处理,如标准化、归一化、编码分类变量等。
示例:
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
22.1.3.3 选择模型
选择合适的机器学习模型进行训练。
示例:
from sklearn.linear_model import LogisticRegression
model = LogisticRegression()
22.1.3.4 模型训练
使用训练数据对模型进行训练。
示例:
model.fit(X_train_scaled, y_train)
22.1.3.5 模型评估
使用测试数据评估模型的性能。
示例:
from sklearn.metrics import accuracy_score, classification_report
predictions = model.predict(X_test_scaled)
print(f"准确率: {accuracy_score(y_test, predictions)}")
print(f"分类报告:\n{classification_report(y_test, predictions)}")
22.1.3.6 模型预测
使用训练好的模型对新数据进行预测。
示例:
new_data = [[5.1, 3.5, 1.4, 0.2]]
new_data_scaled = scaler.transform(new_data)
prediction = model.predict(new_data_scaled)
print(f"预测结果: {prediction}")
22.1.4 示例:使用Scikit-learn进行鸢尾花分类
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, classification_report
# 加载数据集
iris = load_iris()
X = iris.data
y = iris.target
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 数据预处理
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# 选择模型并训练
model = LogisticRegression()
model.fit(X_train_scaled, y_train)
# 模型评估
predictions = model.predict(X_test_scaled)
print(f"准确率: {accuracy_score(y_test, predictions)}")
print(f"分类报告:\n{classification_report(y_test, predictions)}")
# 预测新数据
new_data = [[5.1, 3.5, 1.4, 0.2]]
new_data_scaled = scaler.transform(new_data)
prediction = model.predict(new_data_scaled)
print(f"预测结果: {prediction}")
22.1.5 小结:机器学习的魔法
通过本节,你已经学习了如何使用Scikit-learn进行机器学习,就像掌握了“智能预测”的魔法技巧。机器学习是人工智能的重要组成部分,它可以帮助我们从数据中提取有价值的信息,并进行预测和决策。希望你能灵活运用这些“机器学习魔法”,让你的Python程序能够智能地分析和预测,为编写更强大的数据科学和人工智能应用打下坚实的基础。
22.2 TensorFlow与PyTorch:Python如何驾驭深度学习
欢迎来到“深度学习”的魔法殿堂!在人工智能的快速发展中,深度学习已经成为推动技术进步的核心力量。深度学习通过模拟人脑的神经网络结构,能够处理复杂的任务,如图像识别、自然语言处理、语音识别等。而TensorFlow和PyTorch是Python中最受欢迎的深度学习框架,它们各自拥有独特的优势和广泛的应用场景。今天,我们将深入探讨这两个框架,看看它们如何帮助Python驾驭深度学习。
22.2.1 什么是深度学习?
深度学习是机器学习的一个子领域,它使用多层神经网络来模拟人脑的工作方式,从而实现对复杂数据的自动特征提取和模式识别。深度学习模型通常具有多个隐藏层,能够学习到数据中的高层次抽象特征。
比喻:如果机器学习是一个魔法师学习基础魔法咒语,那么深度学习就是学习更复杂、更强大的魔法组合。
22.2.2 TensorFlow:深度学习的“瑞士军刀”
TensorFlow是由Google开发的开源深度学习框架,广泛应用于研究和生产环境。它提供了丰富的工具和库,支持从构建模型到部署的整个流程。
22.2.2.1 TensorFlow的主要特点
1. 灵活性高:
- TensorFlow支持多种编程范式,如符号式编程和命令式编程。
- 比喻:就像一个多功能的魔法工具箱,可以根据需要选择不同的工具。
2. 强大的计算图:
- TensorFlow使用计算图(Computational Graph)来表示和执行计算,适合大规模分布式训练。
- 示例:
import tensorflow as tf # 定义计算图 a = tf.constant(2) b = tf.constant(3) c = a + b print(c) # 输出: Tensor("add:0", shape=(), dtype=int32) # 执行计算图 with tf.compat.v1.Session() as sess: print(sess.run(c)) # 输出: 5
3. 丰富的预训练模型:
- TensorFlow Hub提供了大量预训练的模型,如BERT、ResNet等,方便快速构建应用。
4. 生产环境支持:
- TensorFlow Extended(TFX)提供了从数据准备到模型部署的完整生产环境支持。
5. 广泛的社区和文档:
- TensorFlow拥有庞大的社区和丰富的文档资源,方便学习和解决问题。
22.2.2.2 TensorFlow的应用场景
-
大规模深度学习模型训练:
- TensorFlow适合训练复杂的深度学习模型,如卷积神经网络(CNN)、循环神经网络(RNN)等。
-
生产环境部署:
- TensorFlow提供了强大的部署工具,适合将模型部署到服务器、移动设备、嵌入式系统等。
-
研究与应用开发:
- TensorFlow广泛应用于学术研究和工业应用,如自动驾驶、医疗影像分析等。
22.2.3 PyTorch:深度学习的“动态魔法师”
PyTorch是由Facebook开发的开源深度学习框架,以其动态计算图和易用性而闻名。PyTorch在研究和快速原型开发中非常受欢迎。
22.2.3.1 PyTorch的主要特点
1. 动态计算图:
- PyTorch使用动态计算图(Dynamic Computational Graph),允许在运行时定义和修改计算图,适合快速迭代和调试。
- 比喻:就像一个可以随时调整的魔法卷轴,开发者可以灵活地修改和优化模型。
2. 易于调试:
- 由于其动态特性,PyTorch的调试体验更接近于传统的Python编程,易于使用Python调试工具。
3. 广泛的社区和库支持:
- PyTorch拥有庞大的社区和丰富的第三方库,如torchvision、torchtext等,方便快速构建应用。
4. 易用性高:
- PyTorch的API设计简洁,易于学习和使用,适合快速原型开发和研究。
22.2.3.2 PyTorch的应用场景
-
研究和快速原型开发:
- PyTorch适合进行深度学习研究、快速迭代和模型验证。
-
自然语言处理(NLP):
- PyTorch在NLP领域应用广泛,许多先进的模型(如BERT、GPT)都是基于PyTorch实现的。
-
计算机视觉:
- PyTorch也广泛应用于计算机视觉任务,如图像分类、目标检测、图像生成等。
22.2.4 TensorFlow vs. PyTorch:如何选择?
| 特性 | TensorFlow | PyTorch |
|---|---|---|
| 计算图 | 静态计算图(默认),支持动态图(TensorFlow 2.x) | 动态计算图 |
| 易用性 | 中,需要学习计算图的概念 | 高,接近传统Python编程 |
| 性能 | 高,适合大规模分布式训练 | 高,适合快速迭代和调试 |
| 生态系统 | 丰富,TensorFlow Hub、TFX等 | 丰富,torchvision、torchtext等 |
| 社区支持 | 庞大,Google支持 | 庞大,Facebook支持 |
| 应用场景 | 大规模模型训练、生产环境部署 | 研究、快速原型开发 |
22.2.5 小结:深度学习的魔法工具
通过本节,你已经了解了TensorFlow和PyTorch的特点和适用场景,就像掌握了“深度学习”的魔法工具。TensorFlow和PyTorch都是强大的深度学习框架,各有其独特的优势:
- TensorFlow适合大规模模型训练和生产环境部署,拥有丰富的工具和库。
- PyTorch适合研究和快速原型开发,以其动态计算图和易用性著称。
希望你能根据项目需求和个人偏好选择合适的框架,灵活运用这些“深度学习魔法”,让你的Python程序能够驾驭深度学习,为编写更强大的智能应用打下坚实的基础。
第八部分:Python人工智能实战——AI的挑战与机遇
第二十三章:深入AI实战:加载与微调预训练模型
- 从TensorFlow到HuggingFace:开源AI模型的加载与微调
- 数据准备与预处理:为微调做好准备
- 模型选择与评估策略
- 微调技巧与最佳实践
- 部署与优化:将模型投入生产环境
23.1 从TensorFlow到HuggingFace:开源AI模型的加载与微调
欢迎来到“AI实战”的魔法实验室!在人工智能领域,预训练模型就像是一位已经掌握了大量知识和技能的“魔法学徒”。通过加载和微调这些预训练模型,你可以利用它们已经学到的知识,快速构建和优化自己的AI应用。今天,我们将深入探讨如何从TensorFlow到Hugging Face,加载并微调开源的AI模型,让你的Python程序变得更加智能和强大。
23.1.1 什么是预训练模型?
预训练模型是指已经在大量数据上训练好的机器学习或深度学习模型。这些模型通常在大规模数据集(如ImageNet、Wikitext等)上训练,学习到了丰富的特征和模式。通过加载预训练模型,你可以节省大量的训练时间和计算资源,并利用其已经学到的知识来加速你的AI应用开发。
比喻:如果AI模型是一个学徒,那么预训练模型就是一个已经完成了基础训练的学徒,你可以直接让它学习更高级的技能。
注意:加载大模型,进行预训练和推理需要高级 GPU,在普通计算机上可能无法正常运行。可以适当选择蒸馏后的小参数模型继续开发测试验证。
23.1.2 TensorFlow Hub:TensorFlow的模型库
TensorFlow Hub是一个由Google维护的模型库,提供了大量预训练的TensorFlow模型,涵盖图像、文本、音频等多种数据类型。
23.1.2.1 加载预训练模型
使用TensorFlow Hub加载预训练模型非常简单。
示例:加载预训练的文本嵌入模型
import tensorflow as tf
import tensorflow_hub as hub
# 加载预训练的文本嵌入模型
embed = hub.load("https://tfhub.dev/google/universal-sentence-encoder/4")
# 使用模型进行文本嵌入
sentences = ["你好,世界!", "TensorFlow Hub is great."]
embeddings = embed(sentences)
print(embeddings)
23.1.2.2 微调预训练模型
微调是指在特定任务的数据集上对预训练模型进行进一步的训练,以适应特定的应用需求。
示例:微调预训练的图像分类模型
import tensorflow as tf
import tensorflow_hub as hub
# 加载预训练的图像分类模型
model = tf.keras.Sequential([
hub.KerasLayer("https://tfhub.dev/google/imagenet/mobilenet_v2_100_224/feature_vector/5",
trainable=True), # 设置trainable=True以微调模型
tf.keras.layers.Dense(10, activation='softmax')
])
# 编译模型
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# 假设train_data和test_data是已经准备好的数据集
model.fit(train_data, epochs=5)
model.evaluate(test_data)
23.1.3 Hugging Face Transformers:深度学习模型的宝库
Hugging Face Transformers是一个由Hugging Face维护的开源库,提供了大量预训练的深度学习模型,涵盖自然语言处理(NLP)、计算机视觉(CV)等领域。
23.1.3.1 加载预训练模型
Hugging Face Transformers提供了简单易用的API来加载和微调预训练模型。
示例:加载预训练的BERT模型进行文本分类
from transformers import BertTokenizer, TFBertForSequenceClassification
import tensorflow as tf
# 加载预训练的BERT tokenizer和模型
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = TFBertForSequenceClassification.from_pretrained('bert-base-uncased')
# 准备数据
sentences = ["Hello, world!", "TensorFlow is awesome."]
labels = [1, 0]
# 编码输入
encodings = tokenizer(sentences, truncation=True, padding=True, return_tensors='tf')
# 训练模型
train_dataset = tf.data.Dataset.from_tensor_slices((
dict(encodings),
labels
)).shuffle(100).batch(32)
model.compile(optimizer='adam',
loss=model.compute_loss, # 使用模型自带的损失函数
metrics=['accuracy'])
model.fit(train_dataset, epochs=3)
23.1.3.2 微调预训练模型
微调预训练模型可以显著提高特定任务的性能。
示例:微调BERT模型进行情感分析
from transformers import BertTokenizer, TFBertForSequenceClassification
import tensorflow as tf
# 加载预训练的BERT tokenizer和模型
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = TFBertForSequenceClassification.from_pretrained('bert-base-uncased', num_labels=2)
# 准备数据
train_encodings = tokenizer(train_texts, truncation=True, padding=True, return_tensors='tf')
train_labels = tf.constant(train_labels)
# 创建数据集
train_dataset = tf.data.Dataset.from_tensor_slices((
dict(train_encodings),
train_labels
)).shuffle(1000).batch(32)
# 编译模型
model.compile(optimizer='adam',
loss=model.compute_loss,
metrics=['accuracy'])
# 训练模型
model.fit(train_dataset, epochs=3)
23.1.3.3 使用预训练模型进行预测
加载和微调后的模型可以用于对新数据进行预测。
示例:使用微调的BERT模型进行预测
import tensorflow as tf
# 准备新数据
new_sentences = ["I love Python!", "I hate bugs."]
new_encodings = tokenizer(new_sentences, truncation=True, padding=True, return_tensors='tf')
# 进行预测
predictions = model.predict(dict(new_encodings))
predicted_labels = tf.argmax(predictions.logits, axis=1)
print(predicted_labels)
大模型开发电脑配置对比表(报价参考2025年)
| 类别 | CPU | GPU | RAM | 存储 | 价格范围 | 参数规模 | 备注 |
|---|---|---|---|---|---|---|---|
| 2万内 | AMD Ryzen 7 5800X | RTX 3060 | 32GB | 1TB NVMe SSD | 约1.2-1.5万 | 小至中等(约1亿-10亿参数) | 良好的性价比,适合初学者及小规模实验 |
| Intel i5-12600KF | RTX 3060 Ti | 32GB | 1TB NVMe SSD | 约1.3-1.6万 | 中等(约1亿-15亿参数) | 更强的CPU性能,适合复杂任务 | |
| AMD Ryzen 5 5600X | RTX 3070 | 32GB | 1TB NVMe SSD | 约1.4-1.7万 | 中等至较大(约5亿-20亿参数) | 强大的多任务处理能力 | |
| Intel i7-12700KF | RTX 3070 Ti | 64GB | 1TB NVMe SSD | 约1.6-1.9万 | 较大(约10亿-30亿参数) | 适用于更复杂的模型微调 | |
| 2万以上 | AMD Ryzen 9 7900X | RTX 4080 | 64GB | 2TB NVMe SSD | >2万 | 大(约20亿-50亿参数) | 高端选择,适用于大规模数据集 |
| Intel i9-13900KF | RTX 4090 | 128GB | 2TB NVMe SSD | >2.5万 | 极大(约50亿参数及以上) | 极致性能,适合专业研究 | |
| AMD Threadripper PRO 3955WX | A6000 | 128GB | 4TB NVMe SSD | >3万 | 巨型(超过50亿参数) | 顶级工作站级别,适合高级研究 | |
| 云服务器 | AWS EC2 p4d.24xlarge | NVIDIA A100*8 | 根据需求定制 | EBS或S3存储 | 按需计费 | 可扩展(支持超大规模模型) | 高灵活性,适合临时高性能需求 |
| Google Cloud TPU v4 | TPU Pods | 根据需求定制 | 根据需求定制 | 按需计费 | 专为深度学习优化 | 特别适合需要TPU加速的任务 | |
| Azure NC A100 v4 Series | A100*4 | 根据需求定制 | 根据需求定制 | 按需计费 | 高效且灵活 | 提供强大的GPU支持 |
推荐说明:
-
1万到2万元区间:这类配置适合大多数学生使用,可以满足基础的模型微调和推理需求。对于预训练来说,可能更适合较小规模的模型或是在现有基础上进行改进。
-
2万元以上区间:这些高端配置能够支持更大规模的数据集和更复杂的模型架构,非常适合需要进行大量实验的研究人员。特别是对于那些涉及大规模数据集和高维度模型的研究项目,这样的硬件配置是非常必要的。
-
云服务器:如果你的研究工作具有高度的不确定性和波动性,或者你需要访问特别强大的计算资源来进行短期的高强度计算任务,那么租用云服务是一个非常理想的选择。它允许你根据实际需求动态调整资源配置,并且无需担心硬件维护问题。
23.1.4 小结:AI实战的魔法
通过本节,你已经学习了如何加载和微调预训练模型,就像掌握了“AI实战”的魔法技巧。预训练模型是构建强大AI应用的重要工具,它们可以为你节省大量的时间和计算资源,并提供强大的功能。希望你能灵活运用这些“AI实战魔法”,让你的Python程序变得更加智能和强大,为编写更先进的AI应用打下坚实的基础。
23.2 数据准备与预处理:为微调做好准备
在人工智能模型的微调过程中,数据准备与预处理是至关重要的一环。它不仅决定了模型能否有效学习到目标任务的特征,还直接影响最终的性能和泛化能力。以下,我们将深入探讨数据准备与预处理的各个环节,并结合实际案例,展示如何为预训练模型的微调做好充分准备。
23.2.1. 数据收集与选择
数据是AI模型的燃料,没有高质量的数据,模型的表现将大打折扣。在进行微调之前,我们需要收集与目标任务相关的数据。这些数据应具备以下特点:
- 相关性:数据应与目标任务高度相关。例如,如果我们要微调一个用于情感分析的情感模型,数据应包含丰富的情感表达。
- 多样性:数据应涵盖各种可能的场景和情况,以增强模型的泛化能力。
- 规模:数据量应足够大,以避免过拟合。通常,微调所需的数据量比从头训练模型要少,但仍然需要一定的规模。
案例:假设我们要微调一个用于医疗文本分类的模型,我们需要收集包含各种医疗术语、疾病描述和治疗方案的文本数据。
数据收集与选择的Python实现
在人工智能模型的微调过程中,数据收集与选择是奠定成功基础的关键步骤。数据质量直接影响模型的性能,因此我们需要谨慎地选择和收集数据。以下将详细讲解数据收集与选择的过程,并结合Python代码示例,展示如何高效地进行数据收集与选择。
23.2.1.1. 数据收集
数据收集是指从各种来源获取与目标任务相关的数据。数据来源可以是公开数据集、API、网页爬取、数据库等。以下是几种常见的数据收集方法:
23.2.1.1.1 使用公开数据集
许多组织和机构提供了丰富的公开数据集,可以直接下载使用。例如:
- Kaggle:提供大量开源数据集,涵盖各种领域。
- UCI Machine Learning Repository:提供各种经典数据集。
- HuggingFace Datasets:提供多种NLP相关的数据集。
示例:使用HuggingFace Datasets加载公开数据集
from datasets import load_dataset
# 加载IMDB电影评论数据集
dataset = load_dataset('imdb')
# 查看数据集结构
print(dataset)
23.2.1.1.2 使用API获取数据
许多网站和服务提供了API接口,可以通过编程方式获取数据。例如,使用Twitter API获取推文数据。
示例:使用Tweepy库获取Twitter数据
import tweepy
# 认证信息(需要申请Twitter开发者账号)
API_KEY = 'your_api_key'
API_SECRET = 'your_api_secret'
ACCESS_TOKEN = 'your_access_token'
ACCESS_SECRET = 'your_access_secret'
# 认证
auth = tweepy.OAuth1UserHandler(API_KEY, API_SECRET, ACCESS_TOKEN, ACCESS_SECRET)
api = tweepy.API(auth)
# 获取推文
query = '人工智能'
tweets = api.search_tweets(q=query, lang='zh', count=100)
# 提取推文文本
tweet_texts = [tweet.text for tweet in tweets]
23.2.1.1.3 网页爬取
对于没有提供API的数据,可以通过网页爬取获取数据。需要注意的是,爬取数据时应遵守网站的robots.txt协议和相关法律法规。
示例:使用BeautifulSoup库爬取网页数据
import requests
from bs4 import BeautifulSoup
# 目标网页URL
url = 'https://example.com/articles'
# 发送请求
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
# 提取文章标题和链接
articles = []
for article in soup.find_all('article'):
title = article.find('h2').text
link = article.find('a')['href']
articles.append({'title': title, 'link': link})
print(articles)
23.2.1.1.4 数据库查询
如果数据存储在数据库中,可以使用SQL查询语句获取数据。
示例:使用SQLAlchemy库连接数据库并查询数据
from sqlalchemy import create_engine
# 创建数据库引擎
engine = create_engine('mysql+pymysql://user:password@localhost:3306/database')
# 执行查询
query = "SELECT * FROM articles WHERE category = '人工智能'"
results = engine.execute(query).fetchall()
# 提取数据
articles = []
for row in results:
articles.append({'id': row[0], 'title': row[1], 'content': row[2]})
print(articles)
23.2.1.2. 数据选择
数据选择是指从收集到的数据中筛选出与目标任务相关的数据。以下是几种常见的数据选择方法:
23.2.1.2.1 基于关键词筛选
通过关键词匹配筛选出相关的数据。
示例:使用关键词筛选推文
# 关键词列表
keywords = ['人工智能', '机器学习', '深度学习']
# 筛选推文
filtered_tweets = [tweet for tweet in tweet_texts if any(keyword in tweet for keyword in keywords)]
print(filtered_tweets)
23.2.1.2.2 基于主题模型筛选
使用主题模型(如LDA)将数据划分为不同主题,然后选择与目标任务相关的主题。
示例:使用Gensim库进行主题建模
from gensim import corpora, models
# 文本预处理
texts = [tweet.split() for tweet in filtered_tweets]
# 创建词典
dictionary = corpora.Dictionary(texts)
# 生成语料库
corpus = [dictionary.doc2bow(text) for text in texts]
# 训练LDA模型
lda_model = models.LdaModel(corpus, num_topics=5, id2word=dictionary, passes=10)
# 选择与人工智能相关的主题
relevant_topic = lda_model.print_topics(num_topics=5, num_words=5)
print(relevant_topic)
23.2.1.2.3 基于情感分析筛选
对于需要特定情感倾向的数据,可以使用情感分析模型进行筛选。
示例:使用TextBlob库进行情感分析
from textblob import TextBlob
# 情感分析函数
def get_sentiment(text):
return TextBlob(text).sentiment.polarity
# 筛选正面情感的推文
positive_tweets = [tweet for tweet in filtered_tweets if get_sentiment(tweet) > 0.5]
print(positive_tweets)
23.2.1.3. 数据清洗与预处理
在数据选择之后,需要对数据进行清洗与预处理,包括去除噪声、标准化文本、去除停用词等。
示例:使用NLTK库进行文本预处理
import nltk
from nltk.corpus import stopwords
from nltk.stem import WordNetLemmatizer
# 下载所需资源
nltk.download('stopwords')
nltk.download('wordnet')
# 初始化分词器和词形还原器
lemmatizer = WordNetLemmatizer()
stop_words = set(stopwords.words('english'))
# 文本预处理函数
def preprocess(text):
# 分词
tokens = nltk.word_tokenize(text)
# 去除停用词和标点符号
tokens = [token for token in tokens if token.isalnum()]
# 去除停用词
tokens = [token for token in tokens if token not in stop_words]
# 词形还原
tokens = [lemmatizer.lemmatize(token) for token in tokens]
return ' '.join(tokens)
# 应用预处理
cleaned_tweets = [preprocess(tweet) for tweet in positive_tweets]
print(cleaned_tweets)
23.2.1.4. 数据存储
最后,将清洗和预处理后的数据存储起来,以便后续使用。可以使用CSV、JSON、数据库等方式存储。
示例:使用Pandas库将数据存储为CSV文件
import pandas as pd
# 创建DataFrame
df = pd.DataFrame(cleaned_tweets, columns=['text'])
# 存储为CSV文件
df.to_csv('filtered_tweets.csv', index=False)
通过本小节:数据收集与选择 的学习,您将能够掌握数据收集与选择的关键步骤,并将其应用于AI模型的微调实战中。Python提供了丰富的库和工具,可以大大简化数据收集与选择的过程,提高工作效率。在实际应用中,选择合适的数据收集方法和预处理技术,是确保模型性能的关键。
23.2.2. 数据清洗
数据清洗是去除数据中噪声和不相关信息的步骤。以下是一些常见的数据清洗操作:
- 去除无关字符:如HTML标签、特殊符号等。
- 处理缺失值:填补或删除缺失的数据。
- 标准化文本:统一文本的格式,如将所有文本转换为小写,去除多余的空格等。
案例:在医疗文本中,可能存在大量的缩写和术语,需要进行标准化处理。例如,将“COVID-19”统一为“COVID”。
数据清洗的Python实现
数据清洗是数据预处理过程中至关重要的一步,旨在提高数据质量,确保模型能够从数据中学习到有用的信息。数据清洗涉及识别和纠正(或删除)数据中的错误、不一致和噪声。以下将详细讲解数据清洗的各个环节,并结合Python代码示例,展示如何高效地进行数据清洗。
23.2.2.1. 数据清洗的主要步骤
23.2.2.1.1 处理缺失值
缺失值是指数据集中某些字段为空或不存在的情况。处理缺失值的方法包括:
- 删除缺失值:如果缺失值比例较小,可以直接删除包含缺失值的记录。
- 填补缺失值:使用统计方法(如均值、中位数、众数)或机器学习方法填补缺失值。
示例:使用Pandas处理缺失值
import pandas as pd
# 读取数据
df = pd.read_csv('data.csv')
# 查看缺失值情况
print(df.isnull().sum())
# 删除包含缺失值的行
df_cleaned = df.dropna()
# 或者,用列的均值填补数值型缺失值
df['age'].fillna(df['age'].mean(), inplace=True)
# 用众数填补分类变量
df['gender'].fillna(df['gender'].mode()[0], inplace=True)
23.2.2.1.2 处理重复数据
重复数据是指数据集中存在完全相同或几乎相同的记录。处理重复数据的方法包括:
- 删除重复记录:使用Pandas的
drop_duplicates()方法删除重复行。
示例:删除重复数据
# 删除完全重复的行
df_cleaned = df.drop_duplicates()
# 删除基于特定列的重复行,例如基于'name'和'email'列
df_cleaned = df.drop_duplicates(subset=['name', 'email'])
23.2.2.1.3 处理异常值
异常值是指数据集中与大多数数据点显著不同的值。处理异常值的方法包括:
- 删除异常值:如果异常值是由于数据录入错误或测量错误导致的,可以直接删除。
- 修正异常值:使用统计方法(如Z-score、IQR)识别并修正异常值。
示例:使用Z-score方法识别并删除异常值
from scipy import stats
import numpy as np
# 计算Z-score
df['z_score'] = np.abs(stats.zscore(df['age']))
# 删除Z-score大于3的行
df_cleaned = df[df['z_score'] < 3]
# 删除辅助列
df_cleaned = df_cleaned.drop(columns=['z_score'])
23.2.2.1.4 标准化文本数据
文本数据通常包含大小写不一致、标点符号、特殊字符等问题。标准化文本数据的方法包括:
- 统一大小写:将所有文本转换为小写或大写。
- 去除标点符号和特殊字符:使用正则表达式去除不需要的字符。
- 去除停用词:去除常见的无意义词汇(如“的”、“是”等)。
示例:使用NLTK和正则表达式进行文本清洗
import re
import nltk
from nltk.corpus import stopwords
# 下载停用词
nltk.download('stopwords')
stop_words = set(stopwords.words('chinese'))
# 文本清洗函数
def clean_text(text):
# 转为小写
text = text.lower()
# 去除数字和特殊字符
text = re.sub(r'[^a-zA-Z\u4e00-\u9fa5]', ' ', text)
# 去除多余空格
text = re.sub(r'\s+', ' ', text).strip()
# 去除停用词
tokens = text.split()
tokens = [word for word in tokens if word not in stop_words]
return ' '.join(tokens)
# 应用清洗函数
df['clean_text'] = df['text'].apply(clean_text)
23.2.2.1.5 去除HTML标签
如果数据中包含HTML内容,需要去除HTML标签以获取纯文本。
示例:使用BeautifulSoup去除HTML标签
from bs4 import BeautifulSoup
# 去除HTML标签函数
def remove_html(text):
soup = BeautifulSoup(text, "html.parser")
return soup.get_text()
# 应用函数
df['clean_text'] = df['text'].apply(remove_html)
23.2.2.1.6 编码与解码
处理文本数据时,可能需要进行编码转换。例如,将UTF-8编码转换为GBK编码,或反之。
示例:编码转换
# 将文本转换为UTF-8编码
df['text'] = df['text'].apply(lambda x: x.encode('utf-8').decode('utf-8'))
# 将文本转换为GBK编码
df['text'] = df['text'].apply(lambda x: x.encode('gbk', errors='ignore').decode('gbk', errors='ignore'))
23.2.2.2. 综合示例
以下是一个综合的数据清洗示例,涵盖了缺失值处理、重复数据删除、异常值处理和文本标准化。
import pandas as pd
import re
import nltk
from nltk.corpus import stopwords
from scipy import stats
import numpy as np
from bs4 import BeautifulSoup
# 下载停用词
nltk.download('stopwords')
stop_words = set(stopwords.words('chinese'))
# 读取数据
df = pd.read_csv('data.csv')
# 1. 处理缺失值
df['age'].fillna(df['age'].mean(), inplace=True)
df['gender'].fillna(df['gender'].mode()[0], inplace=True)
# 2. 删除重复数据
df_cleaned = df.drop_duplicates()
# 3. 处理异常值
df_cleaned['z_score'] = np.abs(stats.zscore(df_cleaned['age']))
df_cleaned = df_cleaned[df_cleaned['z_score'] < 3]
df_cleaned = df_cleaned.drop(columns=['z_score'])
# 4. 去除HTML标签
df_cleaned['clean_text'] = df_cleaned['text'].apply(remove_html)
# 5. 标准化文本数据
def clean_text(text):
# 转为小写
text = text.lower()
# 去除数字和特殊字符
text = re.sub(r'[^a-zA-Z\u4e00-\u9fa5]', ' ', text)
# 去除多余空格
text = re.sub(r'\s+', ' ', text).strip()
# 去除停用词
tokens = text.split()
tokens = [word for word in tokens if word not in stop_words]
return ' '.join(tokens)
df_cleaned['clean_text'] = df_cleaned['clean_text'].apply(clean_text)
# 6. 编码转换(如果需要)
df_cleaned['clean_text'] = df_cleaned['clean_text'].apply(lambda x: x.encode('utf-8').decode('utf-8'))
# 保存清洗后的数据
df_cleaned.to_csv('cleaned_data.csv', index=False)
数据清洗是数据预处理的核心环节,直接影响模型的学习效果和最终性能。通过系统化的数据清洗步骤,包括处理缺失值、删除重复数据、处理异常值、标准化文本数据等,可以显著提高数据质量,为后续的模型训练和评估打下坚实的基础。Python提供了丰富的库和工具,如Pandas、NLTK、BeautifulSoup等,可以简化数据清洗过程,提高工作效率。通过本章的学习,您将能够掌握数据清洗的关键步骤,并将其应用于AI模型的微调实战中,确保数据的高质量和一致性,从而提升模型的性能和可靠性。
23.2.3. 数据标注
对于监督学习任务,数据标注是必不可少的步骤。标注的质量直接影响模型的性能。以下是一些常见的标注方法:
- 人工标注:由专家或标注人员手动标注数据。这种方法质量高,但成本高且耗时。
- 半自动标注:结合人工和自动方法进行标注。例如,使用预训练模型进行初步标注,再由人工进行校正。
- 自动标注:使用现有的规则或模型进行自动标注。这种方法速度快,但可能引入误差。
案例:在医疗文本分类中,我们需要标注每条文本所属的疾病类别。可以使用半自动方法,先使用预训练模型进行初步分类,再由医学专家进行校正。
数据标注的Python实现
数据标注是将原始数据转换为机器学习模型可理解的形式的过程。对于监督学习任务,标注数据是必不可少的步骤。数据标注的质量直接影响模型的性能,因此需要谨慎对待。以下将详细讲解数据标注的各个环节,并结合Python代码示例,展示如何高效地进行数据标注。
23.2.3.1. 数据标注的主要类型
根据任务的不同,数据标注可以分为以下几种主要类型:
23.2.3.1.1 分类标注
分类标注是指将数据分配到预定义的类别中。例如,情感分析中将文本分为正面、负面或中性。
示例:文本情感分类
import pandas as pd
# 读取数据
df = pd.read_csv('tweets.csv')
# 假设我们有一个简单的规则来标注情感
def label_sentiment(text):
if 'happy' in text or 'joy' in text:
return 'positive'
elif 'sad' in text or 'angry' in text:
return 'negative'
else:
return 'neutral'
# 应用标注函数
df['sentiment'] = df['text'].apply(label_sentiment)
print(df.head())
23.2.3.1.2 命名实体识别(NER)
命名实体识别是指识别文本中的实体,如人名、地名、组织机构等。
示例:使用spaCy进行NER标注
import spacy
# 加载预训练的spaCy模型
nlp = spacy.load('zh_core_web_sm')
# 读取数据
df = pd.read_csv('articles.csv')
# 定义NER函数
def extract_entities(text):
doc = nlp(text)
entities = [(ent.text, ent.label_) for ent in doc.ents]
return entities
# 应用NER函数
df['entities'] = df['text'].apply(extract_entities)
print(df.head())
23.2.3.1.3 问答标注
问答标注是指为给定的问题提供相应的答案,常用于问答系统。
示例:简单的问答对标注
import pandas as pd
# 创建问答对数据
data = {
'question': [
'中国的首都是哪里?',
'人工智能的定义是什么?',
'Python的作者是谁?'
],
'answer': [
'北京',
'人工智能是计算机科学的一个分支,涉及使机器能够执行通常需要人类智能的任务。',
'Guido van Rossum'
]
}
df = pd.DataFrame(data)
print(df)
23.2.3.1.4 序列标注
序列标注是指对序列中的每个元素进行标注,常用于词性标注、句法分析等。
示例:使用spaCy进行词性标注
import spacy
# 加载预训练的spaCy模型
nlp = spacy.load('zh_core_web_sm')
# 读取数据
df = pd.read_csv('sentences.csv')
# 定义词性标注函数
def pos_tagging(text):
doc = nlp(text)
return [(token.text, token.pos_) for token in doc]
# 应用词性标注函数
df['pos_tags'] = df['sentence'].apply(pos_tagging)
print(df.head())
23.2.3.2. 数据标注的方法
23.2.3.2.1 人工标注
人工标注是指由人工对数据进行标注。这种方法可以获得高质量的标注数据,但成本高且耗时。
示例:人工标注情感分析数据
import pandas as pd
# 读取数据
df = pd.read_csv('tweets.csv')
# 人工标注函数
def manual_label(text):
# 这里可以添加人工标注的逻辑,例如通过GUI界面进行标注
# 这里为了示例,假设我们有一个简单的规则
if 'happy' in text or 'joy' in text:
return 'positive'
elif 'sad' in text or 'angry' in text:
return 'negative'
else:
return 'neutral'
# 应用人工标注函数
df['sentiment'] = df['text'].apply(manual_label)
print(df.head())
23.2.3.2.2 半自动标注
半自动标注是指结合人工和自动方法进行标注。例如,使用预训练模型进行初步标注,再由人工进行校正。
示例:使用预训练模型进行半自动情感分析标注
import pandas as pd
from textblob import TextBlob
# 读取数据
df = pd.read_csv('tweets.csv')
# 定义半自动标注函数
def semi_automatic_label(text):
blob = TextBlob(text)
polarity = blob.sentiment.polarity
if polarity > 0.1:
return 'positive'
elif polarity < -0.1:
return 'negative'
else:
return 'neutral'
# 应用半自动标注函数
df['sentiment'] = df['text'].apply(semi_automatic_label)
# 人工校正(假设我们有一个校正函数)
def manual_correction(text, label):
# 这里可以添加人工校正的逻辑
return label
# 应用人工校正
df['sentiment'] = df.apply(lambda row: manual_correction(row['text'], row['sentiment']), axis=1)
print(df.head())
23.2.3.2.3 自动标注
自动标注是指使用现有的规则或模型进行自动标注。这种方法速度快,但可能引入误差。
示例:使用规则进行自动情感分析标注
import pandas as pd
# 读取数据
df = pd.read_csv('tweets.csv')
# 定义自动标注函数
def automatic_label(text):
if 'happy' in text or 'joy' in text:
return 'positive'
elif 'sad' in text or 'angry' in text:
return 'negative'
else:
return 'neutral'
# 应用自动标注函数
df['sentiment'] = df['text'].apply(automatic_label)
print(df.head())
23.2.3.3. 数据标注工具
有许多开源和商业的数据标注工具可以帮助简化标注过程:
23.2.3.3.1 LabelImg
LabelImg是一个开源的图像标注工具,支持多种格式的标注。
官网:GitHub - HumanSignal/labelImg
23.2.3.3.2 Prodigy
Prodigy是一个由Explosion开发的商业数据标注工具,支持文本、图像等多种类型的标注。
官网:Prodigy · An annotation tool for AI, Machine Learning & NLP
23.2.3.3.3 BRAT
BRAT是一个开源的文本标注工具,支持多种类型的文本标注任务。
23.2.3.3.4 Snorkel
Snorkel是一个用于弱监督学习的工具,可以帮助生成标注数据。
官网:Snorkel
23.2.3.4. 数据标注的最佳实践
- 一致性:确保标注标准的一致性,避免不同标注者之间的差异。
- 标注指南:制定详细的标注指南,明确标注标准和流程。
- 质量控制:定期进行质量检查,确保标注数据的准确性。
- 迭代优化:根据模型反馈,不断优化标注标准和流程。
23.2.3.5 数据标注小结
数据标注是数据预处理的重要环节,直接影响模型的学习效果和最终性能。通过系统化的数据标注步骤,包括分类标注、命名实体识别、问答标注、序列标注等,可以为模型提供高质量的标注数据。Python提供了丰富的库和工具,如spaCy、TextBlob等,可以简化数据标注过程,提高工作效率。通过本章的学习,您将能够掌握数据标注的关键步骤,并将其应用于AI模型的微调实战中,确保数据的高质量和一致性,从而提升模型的性能和可靠性。
23.2.4. 数据分割
为了评估模型的性能,我们需要将数据划分为训练集、验证集和测试集:
- 训练集:用于模型训练。
- 验证集:用于模型调优和超参数选择。
- 测试集:用于最终的性能评估。
常见的分割比例为70%训练集、15%验证集和15%测试集,但具体比例应根据数据量和任务需求进行调整。
案例:在医疗文本分类中,我们可以将收集到的数据按比例分割为训练集、验证集和测试集,以确保模型的泛化能力。
数据分割的Python实现
数据分割是数据预处理中的关键步骤,旨在将整个数据集划分为不同的子集,以便在模型训练、调优和评估过程中使用。合理的数据分割可以有效评估模型的泛化能力,避免过拟合并确保模型的可靠性。以下将详细讲解数据分割的各个环节,并结合Python代码示例,展示如何高效地进行数据分割。
23.2.4.1. 数据分割的主要类型
根据模型训练和评估的需求,数据分割通常包括以下几种主要类型:
23.2.4.1.1 训练集(Training Set)
训练集用于模型的训练过程。模型通过学习训练集中的数据来调整其参数,以最小化预测误差。
23.2.4.1.2 验证集(Validation Set)
验证集用于在训练过程中评估模型的性能,调整模型的超参数(如学习率、模型复杂度等),以防止过拟合并优化模型性能。
23.2.4.1.3 测试集(Test Set)
测试集用于最终评估模型的泛化能力,确保模型在未见过的数据上也能表现良好。测试集应与训练集和验证集完全独立。
23.2.4.2. 数据分割的比例
数据分割的比例可以根据数据集的大小和任务的复杂性进行调整。以下是一些常见的分割比例:
- 小型数据集(如几百到几千条数据):通常采用70%训练集,15%验证集,15%测试集。
- 中型数据集(如几千到几万条数据):通常采用80%训练集,10%验证集,10%测试集。
- 大型数据集(如几十万到几百万条数据):可以减少验证集和测试集的比例,如98%训练集,1%验证集,1%测试集。
注意:具体比例应根据数据集的大小和任务的复杂性进行调整。
23.2.4.1.3. 数据分割的方法
23.2.4.1.3.1 随机分割
随机分割是指将数据集随机划分为训练集、验证集和测试集。这种方法适用于数据分布较为均匀的情况。
示例:使用Scikit-learn进行随机分割
import pandas as pd
from sklearn.model_selection import train_test_split
# 读取数据
df = pd.read_csv('data.csv')
# 假设我们要分割的特征和标签
X = df['text']
y = df['label']
# 第一次分割:训练集和临时集(验证集+测试集)
X_train, X_temp, y_train, y_temp = train_test_split(X, y, test_size=0.3, random_state=42)
# 第二次分割:验证集和测试集
X_val, X_test, y_val, y_test = train_test_split(X_temp, y_temp, test_size=0.5, random_state=42)
print(f'Training set size: {X_train.shape[0]}')
print(f'Validation set size: {X_val.shape[0]}')
print(f'Test set size: {X_test.shape[0]}')
23.2.4.1.3.2 分层分割
分层分割是指在分割时保持数据集中各个类别的比例不变。这对于类别不平衡的数据集尤为重要。
示例:使用Scikit-learn进行分层分割
import pandas as pd
from sklearn.model_selection import train_test_split
# 读取数据
df = pd.read_csv('data.csv')
# 假设我们要分割的特征和标签
X = df['text']
y = df['label']
# 第一次分割:训练集和临时集(验证集+测试集)
X_train, X_temp, y_train, y_temp = train_test_split(X, y, test_size=0.3, stratify=y, random_state=42)
# 第二次分割:验证集和测试集
X_val, X_test, y_val, y_test = train_test_split(X_temp, y_temp, test_size=0.5, stratify=y_temp, random_state=42)
print(f'Training set size: {X_train.shape[0]}')
print(f'Validation set size: {X_val.shape[0]}')
print(f'Test set size: {X_test.shape[0]}')
23.2.4.1.3.3 时间序列分割
对于时间序列数据,传统的随机分割方法可能会导致数据泄漏。因此,需要按照时间顺序进行分割。
示例:时间序列数据分割
import pandas as pd
# 读取时间序列数据
df = pd.read_csv('time_series_data.csv', parse_dates=['date'])
# 按日期排序
df = df.sort_values('date')
# 假设我们按80%训练,10%验证,10%测试分割
train_end = int(0.8 * len(df))
val_end = int(0.9 * len(df))
train_df = df[:train_end]
val_df = df[train_end:val_end]
test_df = df[val_end:]
print(f'Training set size: {len(train_df)}')
print(f'Validation set size: {len(val_df)}')
print(f'Test set size: {len(test_df)}')
23.2.4.1.4. 数据分割的注意事项
23.2.4.1.4.1 数据泄漏
数据泄漏是指在模型训练过程中使用了不应该使用的信息,导致模型性能虚高。为避免数据泄漏,应确保:
- 训练集、验证集和测试集完全独立。
- 在分割数据后再进行特征工程,避免在训练过程中使用验证集或测试集的信息。
23.2.4.1.4.2 类别不平衡
对于类别不平衡的数据集,应使用分层分割方法,以确保各个类别在训练集、验证集和测试集中的比例一致。
23.2.4.1.4.3 数据量
对于小数据集,过小的验证集和测试集可能导致评估结果不稳定。可以考虑使用交叉验证方法,如K折交叉验证。
示例:使用K折交叉验证
import pandas as pd
from sklearn.model_selection import KFold
# 读取数据
df = pd.read_csv('data.csv')
# 假设我们要分割的特征和标签
X = df['text']
y = df['label']
# 初始化K折交叉验证
kf = KFold(n_splits=5, shuffle=True, random_state=42)
for train_index, val_index in kf.split(X):
X_train, X_val = X[train_index], X[val_index]
y_train, y_val = y[train_index], y[val_index]
# 在这里可以进行模型训练和评估
print(f'Training set size: {len(X_train)}')
print(f'Validation set size: {len(X_val)}')
23.2.4.1.5. 综合示例
以下是一个综合的数据分割示例,涵盖了随机分割、分层分割和时间序列分割。
import pandas as pd
from sklearn.model_selection import train_test_split, KFold
# 读取数据
df = pd.read_csv('data.csv')
# 1. 随机分割
X = df['text']
y = df['label']
X_train, X_temp, y_train, y_temp = train_test_split(X, y, test_size=0.3, random_state=42)
X_val, X_test, y_val, y_test = train_test_split(X_temp, y_temp, test_size=0.5, random_state=42)
print('随机分割结果:')
print(f'Training set size: {X_train.shape[0]}')
print(f'Validation set size: {X_val.shape[0]}')
print(f'Test set size: {X_test.shape[0]}')
# 2. 分层分割
X_train, X_temp, y_train, y_temp = train_test_split(X, y, test_size=0.3, stratify=y, random_state=42)
X_val, X_test, y_val, y_test = train_test_split(X_temp, y_temp, test_size=0.5, stratify=y_temp, random_state=42)
print('分层分割结果:')
print(f'Training set size: {X_train.shape[0]}')
print(f'Validation set size: {X_val.shape[0]}')
print(f'Test set size: {X_test.shape[0]}')
# 3. 时间序列分割
df_sorted = df.sort_values('date')
train_end = int(0.8 * len(df_sorted))
val_end = int(0.9 * len(df_sorted))
train_df = df_sorted[:train_end]
val_df = df_sorted[train_end:val_end]
test_df = df_sorted[val_end:]
print('时间序列分割结果:')
print(f'Training set size: {len(train_df)}')
print(f'Validation set size: {len(val_df)}')
print(f'Test set size: {len(test_df)}')
23.2.4.1.6. 总结
数据分割是数据预处理的重要环节,直接影响模型的训练和评估效果。通过合理的数据分割方法,如随机分割、分层分割和时间序列分割,可以有效评估模型的泛化能力,确保模型在未见过的数据上也能表现良好。Python提供了丰富的库和工具,如Scikit-learn,可以简化数据分割过程,提高工作效率。
23.2.5. 数据增强
数据增强是通过对现有数据进行变换,生成新的训练样本的方法。常见的数据增强技术包括:
- 文本替换:使用同义词或近义词替换文本中的某些词语。
- 随机删除:随机删除文本中的某些词语。
- 句子重组:重新排列句子的顺序。
- 回译:将文本翻译成另一种语言,再翻译回原语言。
案例:在医疗文本中,可以通过同义词替换来生成新的训练样本。例如,将“发热”替换为“高烧”。
数据增强:详细讲解与Python实现
数据增强(Data Augmentation)是提高模型泛化能力的重要技术,尤其在数据量有限或类别不平衡的情况下,数据增强可以显著提升模型的性能。数据增强通过对现有数据进行各种变换,生成新的训练样本,从而增加数据的多样性。以下将详细讲解数据增强的各个环节,并结合Python代码示例,展示如何高效地进行数据增强。
23.2.5.1. 数据增强的主要类型
根据任务的不同,数据增强可以分为以下几种主要类型:
23.2.5.1.1 文本数据增强
对于自然语言处理(NLP)任务,文本数据增强可以通过以下方法实现:
- 同义词替换:将文本中的某些词语替换为它们的同义词。
- 随机插入:在文本中随机插入一些词语。
- 随机删除:随机删除文本中的某些词语。
- 句子重组:重新排列句子的顺序。
- 回译:将文本翻译成另一种语言,再翻译回原语言。
示例:使用NLPAug库进行文本数据增强
import nlpaug.augmenter.word as naw
# 初始化同义词替换增强器
aug = naw.SynonymAug(aug_min=1, aug_max=3, aug_p=0.3, lang='zh')
# 原始文本
text = '人工智能是计算机科学的一个分支,涉及使机器能够执行通常需要人类智能的任务。'
# 生成增强文本
augmented_text = aug.augment(text)
print(augmented_text)
23.2.5.1.2 图像数据增强
对于计算机视觉任务,图像数据增强可以通过以下方法实现:
- 旋转:将图像旋转一定角度。
- 缩放:对图像进行缩放。
- 翻转:水平或垂直翻转图像。
- 裁剪:随机裁剪图像的一部分。
- 颜色抖动:改变图像的亮度、对比度、饱和度等。
示例:使用Albumentations库进行图像数据增强
import albumentations as A
from PIL import Image
import matplotlib.pyplot as plt
# 读取图像
image = Image.open('image.jpg')
image = np.array(image)
# 定义增强变换
transform = A.Compose([
A.Rotate(limit=40, p=1),
A.RandomBrightnessContrast(p=0.2),
A.HorizontalFlip(p=0.5),
])
# 应用增强变换
augmented_image = transform(image=image)['image']
# 显示原图和增强图
plt.subplot(1, 2, 1)
plt.imshow(image)
plt.title('Original Image')
plt.subplot(1, 2, 2)
plt.imshow(augmented_image)
plt.title('Augmented Image')
plt.show()
23.2.5.1.3 音频数据增强
对于音频处理任务,音频数据增强可以通过以下方法实现:
- 音量调整:改变音频的音量。
- 添加噪声:向音频中添加背景噪声。
- 时间拉伸:改变音频的播放速度。
- 音调变换:改变音频的音调。
示例:使用librosa库进行音频数据增强
import librosa
import numpy as np
import matplotlib.pyplot as plt
# 读取音频文件
y, sr = librosa.load('audio.wav')
# 定义增强函数
def augment_audio(y, sr):
# 音量调整
y_aug = y * 1.5 # 增加音量
# 添加噪声
noise = np.random.randn(len(y))
y_aug += 0.005 * noise
# 时间拉伸
y_aug = librosa.effects.time_stretch(y_aug, rate=1.2)
return y_aug
# 生成增强音频
y_aug = augment_audio(y, sr)
# 绘制波形图
plt.subplot(2, 1, 1)
librosa.display.waveplot(y, sr=sr)
plt.title('Original Audio')
plt.subplot(2, 1, 2)
librosa.display.waveplot(y_aug, sr=sr)
plt.title('Augmented Audio')
plt.show()
23.2.5.2. 数据增强的最佳实践
- 多样性:使用多种增强方法,以增加数据的多样性。
- 适度性:避免过度增强,导致数据失真或引入噪声。
- 一致性:确保增强后的数据与原始数据在分布上保持一致。
- 验证:在验证集和测试集上验证增强方法的效果,避免对模型性能产生负面影响。
23.2.5.3. 数据增强的应用场景
- 数据量有限:当训练数据量较少时,数据增强可以有效增加数据量,提升模型性能。
- 类别不平衡:对于类别不平衡的数据集,可以通过数据增强增加少数类别的样本数量,改善模型对少数类别的识别能力。
- 提高泛化能力:数据增强可以增加数据的多样性,帮助模型学习到更丰富的特征,提高泛化能力。
23.2.5.4. 综合示例
以下是一个综合的数据增强示例,涵盖了文本和图像数据的增强。
import nlpaug.augmenter.word as naw
import albumentations as A
from PIL import Image
import matplotlib.pyplot as plt
import numpy as np
# 1. 文本数据增强
# 初始化同义词替换增强器
text_aug = naw.SynonymAug(aug_min=1, aug_max=3, aug_p=0.3, lang='zh')
# 原始文本
text = '人工智能是计算机科学的一个分支,涉及使机器能够执行通常需要人类智能的任务。'
# 生成增强文本
augmented_text = text_aug.augment(text)
print('原始文本:', text)
print('增强文本:', augmented_text)
# 2. 图像数据增强
# 读取图像
image = Image.open('image.jpg')
image = np.array(image)
# 定义增强变换
transform = A.Compose([
A.Rotate(limit=40, p=1),
A.RandomBrightnessContrast(p=0.2),
A.HorizontalFlip(p=0.5),
])
# 应用增强变换
augmented_image = transform(image=image)['image']
# 显示原图和增强图
plt.subplot(1, 2, 1)
plt.imshow(image)
plt.title('Original Image')
plt.subplot(1, 2, 2)
plt.imshow(augmented_image)
plt.title('Augmented Image')
plt.show()
23.2.5.5 小结
数据增强是提升模型性能的重要手段,通过对现有数据进行各种变换,生成新的训练样本,增加数据的多样性。Python提供了丰富的库和工具,如NLPAug、Albumentations、librosa等,可以简化数据增强过程,提高工作效率。通过合理的数据增强方法,可以有效提升模型的泛化能力和鲁棒性。通过本章的学习,您将能够掌握数据增强的关键步骤,并将其应用于AI模型的微调实战中,确保数据的高质量和多样性,从而提升模型的性能和可靠性。
23.2.6. 特征工程
特征工程是将原始数据转换为模型可用的特征的过程。在自然语言处理中,常见的特征工程方法包括:
- 词袋模型(Bag of Words):将文本表示为词频向量。
- TF-IDF:计算词语在文档中的重要性。
- 词嵌入(Word Embeddings):使用预训练的词向量,如Word2Vec、GloVe等。
- 上下文嵌入(Contextual Embeddings):使用预训练的语言模型,如BERT、GPT等。
案例:在医疗文本分类中,我们可以使用BERT的上下文嵌入作为特征,因为BERT能够捕捉到词语的上下文信息,这对于理解医疗术语非常重要。
特征工程的Python实现
特征工程(Feature Engineering)是将原始数据转换为机器学习模型可理解的特征的过程。它是数据预处理的核心环节,直接影响模型的性能。特征工程的目标是提取和创造能够更好地表示数据本质的特征,从而提升模型的预测能力和泛化能力。以下将详细讲解特征工程的各个环节,并结合Python代码示例,展示如何高效地进行特征工程。
23.2.6.1. 特征工程的主要步骤
23.2.6.1.1 特征选择
特征选择是指从原始特征中选择对模型最有用的特征,去除冗余或不相关的特征。特征选择可以减少模型的复杂度,提高训练速度,并防止过拟合。
常用方法:
- 过滤法(Filter Methods):基于统计指标(如相关性、互信息等)选择特征。
- 包装法(Wrapper Methods):通过模型性能评估选择特征,如递归特征消除(RFE)。
- 嵌入法(Embedded Methods):在模型训练过程中进行特征选择,如Lasso回归。
示例:使用Scikit-learn进行特征选择
import pandas as pd
from sklearn.feature_selection import SelectKBest, f_classif
# 读取数据
df = pd.read_csv('data.csv')
# 假设我们要选择的特征和标签
X = df.drop('label', axis=1)
y = df['label']
# 选择前10个最重要的特征
selector = SelectKBest(score_func=f_classif, k=10)
X_new = selector.fit_transform(X, y)
# 获取选择的特征名称
selected_features = X.columns[selector.get_support()]
print('Selected Features:', selected_features)
23.2.6.1.2 特征提取
特征提取是指从原始数据中提取新的特征,以更好地表示数据本质。例如,从文本数据中提取词向量,从图像数据中提取像素值等。
常用方法:
- 文本数据:词袋模型(Bag of Words)、TF-IDF、词嵌入(Word Embeddings)。
- 图像数据:主成分分析(PCA)、线性判别分析(LDA)、卷积神经网络(CNN)特征提取。
示例:使用TF-IDF进行文本特征提取
from sklearn.feature_extraction.text import TfidfVectorizer
# 读取文本数据
df = pd.read_csv('text_data.csv')
# 初始化TF-IDF向量化器
vectorizer = TfidfVectorizer(max_features=1000)
# 应用TF-IDF向量化
X = vectorizer.fit_transform(df['text'])
print('Feature Matrix Shape:', X.shape)
23.2.6.1.3 特征变换
特征变换是指对特征进行数学变换,以满足模型对数据分布的要求。例如,对数变换、标准化、归一化等。
常用方法:
- 标准化(Standardization):将特征转换为均值为0,标准差为1的分布。
- 归一化(Normalization):将特征缩放到一个特定的范围,如[0,1]。
- 对数变换(Log Transformation):对特征进行对数变换,以减少偏度的数据分布。
示例:使用Scikit-learn进行特征标准化
from sklearn.preprocessing import StandardScaler
# 读取数据
df = pd.read_csv('data.csv')
# 假设我们要标准化的特征
X = df[['feature1', 'feature2', 'feature3']]
# 初始化标准化器
scaler = StandardScaler()
# 应用标准化
X_scaled = scaler.fit_transform(X)
# 转换为DataFrame
X_scaled = pd.DataFrame(X_scaled, columns=['feature1_scaled', 'feature2_scaled', 'feature3_scaled'])
print(X_scaled.head())
23.2.6.1.4 特征构造
特征构造是指从现有特征中构造新的特征,以捕捉数据中的复杂关系。例如,构造交互特征、多项式特征等。
示例:构造交互特征
import pandas as pd
# 读取数据
df = pd.read_csv('data.csv')
# 构造交互特征
df['feature1_feature2'] = df['feature1'] * df['feature2']
df['feature1_feature3'] = df['feature1'] / df['feature3']
print(df.head())
23.2.6.2. 特征工程的最佳实践
- 理解数据:深入理解数据的本质和业务背景,以便选择合适的特征工程方法。
- 多样性:尝试多种特征工程方法,以找到最能提升模型性能的特征。
- 避免过拟合:在特征选择和构造过程中,避免引入过多复杂特征,导致过拟合。
- 自动化:使用自动化工具和库,简化特征工程过程,提高效率。
23.2.6.3. 特征工程的工具和库
- Scikit-learn:提供了丰富的特征选择、提取和变换工具。
- Pandas:用于数据操作和特征构造。
- Numpy:用于数值计算和特征变换。
- Featuretools:一个用于自动化特征工程的库。
示例:使用Featuretools进行自动化特征工程
import featuretools as ft
import pandas as pd
# 读取数据
customers = pd.read_csv('customers.csv')
sessions = pd.read_csv('sessions.csv')
transactions = pd.read_csv('transactions.csv')
# 定义实体集
es = ft.EntitySet(id='customers')
# 添加实体
es = es.add_dataframe(dataframe_name='customers', dataframe=customers, index='customer_id')
es = es.add_dataframe(dataframe_name='sessions', dataframe=sessions, index='session_id')
es = es.add_dataframe(dataframe_name='transactions', dataframe=transactions, index='transaction_id')
# 定义关系
relationships = [('customers', 'customer_id', 'sessions', 'customer_id'),
('sessions', 'session_id', 'transactions', 'session_id')]
es = es.add_relationships(relationships)
# 进行深度特征合成
feature_matrix, feature_defs = ft.dfs(entityset=es, target_dataframe_name='customers', max_depth=2)
print(feature_matrix.head())
23.2.6.4. 综合示例
以下是一个综合的特征工程示例,涵盖了特征选择、特征提取和特征变换。
import pandas as pd
from sklearn.feature_selection import SelectKBest, f_classif
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.preprocessing import StandardScaler
# 读取数据
df = pd.read_csv('data.csv')
# 1. 特征选择
X = df.drop('label', axis=1)
y = df['label']
selector = SelectKBest(score_func=f_classif, k=10)
X_selected = selector.fit_transform(X, y)
selected_features = X.columns[selector.get_support()]
print('Selected Features:', selected_features)
# 2. 特征提取(以文本数据为例)
vectorizer = TfidfVectorizer(max_features=1000)
X_text = vectorizer.fit_transform(df['text'])
print('Text Feature Matrix Shape:', X_text.shape)
# 3. 特征变换(标准化)
scaler = StandardScaler()
X_selected_scaled = scaler.fit_transform(X_selected)
# 4. 合并特征
from scipy.sparse import hstack
X_final = hstack([X_selected_scaled, X_text])
print('Final Feature Matrix Shape:', X_final.shape)
23.2.6.5. 小结
特征工程是数据预处理的核心环节,直接影响模型的性能。通过合理的特征选择、提取、变换和构造,可以有效提升模型的预测能力和泛化能力。Python提供了丰富的库和工具,如Scikit-learn、Pandas、Featuretools等,可以简化特征工程过程,提高工作效率。通过本章的学习,您将能够掌握特征工程的关键步骤,并将其应用于AI模型的微调实战中,确保特征的高质量和多样性,从而提升模型的性能和可靠性。
23.2.7. 数据标准化与归一化
为了加速模型训练并提高性能,我们需要对特征进行标准化或归一化处理:
- 标准化(Standardization):将特征转换为均值为0,标准差为1的分布。
- 归一化(Normalization):将特征缩放到一个特定的范围,如[0,1]。
案例:在医疗文本分类中,我们可以对BERT的嵌入向量进行标准化处理,以加速模型训练。
数据标准化与归一化的Python实现
数据标准化(Standardization)和 归一化(Normalization)是数据预处理中的关键步骤,旨在调整数据的尺度,使其适合机器学习模型的训练。这两个过程虽然目的相似,但方法不同,适用于不同的场景。以下将详细讲解数据标准化与归一化的各个环节,并结合Python代码示例,展示如何高效地进行数据标准化与归一化。
23.2.7.1. 数据标准化的定义与目的
数据标准化是指将数据转换为均值为0,标准差为1的分布。标准化的目的是消除不同特征之间的量纲差异,使得每个特征对模型的影响相对均衡。
标准化公式:
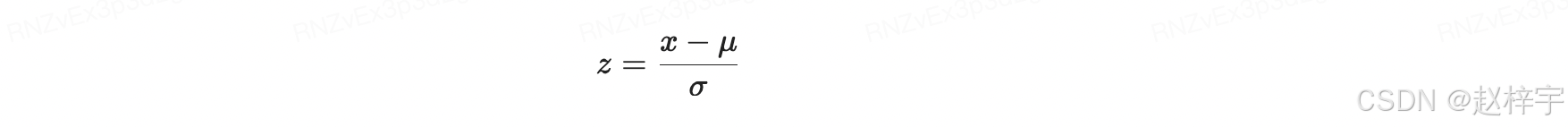
其中:
- x 是原始数据点。
- μ 是数据的均值。
- σ 是数据的标准差。
- z 是标准化后的数据点。
标准化适用场景:
- 当数据分布不满足正态分布时,标准化可以使其更接近正态分布。
- 当使用基于距离的算法(如K近邻、支持向量机)时,标准化可以提高模型性能。
23.2.7.2. 数据归一化的定义与目的
数据归一化是指将数据缩放到一个特定的范围,通常是[0,1]。归一化的目的是消除不同特征之间的量纲差异,使得每个特征对模型的影响相对均衡。
归一化公式(Min-Max Scaling):
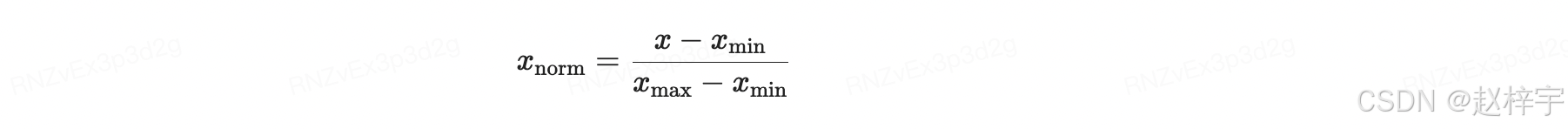
其中:
- X是原始数据点。
- Xmin 是数据的最小值。
- Xmax 是数据的最大值。
- Xnorm 是归一化后的数据点。
归一化适用场景:
- 当需要将数据限制在一个特定范围内时,如[0,1]。
- 当使用梯度下降算法时,归一化可以加快收敛速度。
23.2.7.3. 数据标准化与归一化的区别
| 特性 | 标准化 | 归一化 |
|---|---|---|
| 目标 | 使数据均值为0,标准差为1 | 将数据缩放到[0,1]范围 |
| 适用场景 | 基于距离的算法、模型对数据分布有要求 | 需要将数据限制在特定范围内 |
| 对异常值的敏感性 | 较不敏感 | 较敏感 |
| 实现方法 | 使用均值和标准差 | 使用最小值和最大值 |
23.2.7.4. Python实现
23.2.7.4.1 使用Scikit-learn进行标准化与归一化
import pandas as pd
from sklearn.preprocessing import StandardScaler, MinMaxScaler
# 读取数据
df = pd.read_csv('data.csv')
# 假设我们要处理的数据
X = df[['feature1', 'feature2', 'feature3']]
# 1. 数据标准化
scaler = StandardScaler()
X_standardized = scaler.fit_transform(X)
X_standardized = pd.DataFrame(X_standardized, columns=['feature1_std', 'feature2_std', 'feature3_std'])
print('标准化后的数据:\n', X_standardized.head())
# 2. 数据归一化
min_max_scaler = MinMaxScaler()
X_normalized = min_max_scaler.fit_transform(X)
X_normalized = pd.DataFrame(X_normalized, columns=['feature1_norm', 'feature2_norm', 'feature3_norm'])
print('归一化后的数据:\n', X_normalized.head())
23.2.7.4.2 使用Pandas进行标准化与归一化
import pandas as pd
# 读取数据
df = pd.read_csv('data.csv')
# 假设我们要处理的数据
X = df[['feature1', 'feature2', 'feature3']]
# 1. 数据标准化
X_standardized = (X - X.mean()) / X.std()
print('标准化后的数据:\n', X_standardized.head())
# 2. 数据归一化
X_normalized = (X - X.min()) / (X.max() - X.min())
print('归一化后的数据:\n', X_normalized.head())
23.2.7.4.3 使用Scikit-learn的Pipeline进行标准化与归一化
from sklearn.pipeline import Pipeline
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
# 读取数据
df = pd.read_csv('data.csv')
# 特征和标签
X = df.drop('label', axis=1)
y = df['label']
# 定义Pipeline
pipeline = Pipeline([
('scaler', StandardScaler()),
('classifier', LogisticRegression())
])
# 分割数据
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 训练模型
pipeline.fit(X_train, y_train)
# 评估模型
accuracy = pipeline.score(X_test, y_test)
print('模型准确率:', accuracy)
23.2.7.5. 数据标准化与归一化的注意事项
- 选择合适的方法:根据任务需求选择标准化或归一化。例如,基于距离的算法通常需要标准化,而梯度下降算法则受益于归一化。
- 处理异常值:标准化和归一化对异常值较为敏感,处理数据时应先进行异常值检测和清洗。
- 避免数据泄漏:在进行标准化或归一化时,应在训练集上拟合Scaler,然后在测试集上应用,以避免数据泄漏。
示例:避免数据泄漏
from sklearn.preprocessing import StandardScaler
# 分割数据
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 初始化Scaler
scaler = StandardScaler()
# 在训练集上拟合Scaler
X_train_scaled = scaler.fit_transform(X_train)
# 在测试集上应用Scaler
X_test_scaled = scaler.transform(X_test)
23.2.7.6 小结
数据标准化与归一化是数据预处理的重要环节,旨在调整数据的尺度,使其适合机器学习模型的训练。通过合理的标准化和归一化,可以有效提升模型的性能和稳定性。Python提供了丰富的库和工具,如Scikit-learn、Pandas等,可以简化数据标准化与归一化的过程,提高工作效率。通过本章的学习,您将能够掌握数据标准化与归一化的关键步骤,并将其应用于AI模型的微调实战中,确保数据的高质量和一致性,从而提升模型的性能和可靠性。
23.2.8. 加载与预处理工具
在Python中,有许多强大的工具和库可以简化数据加载与预处理的过程:
- TensorFlow Data API:提供了高效的数据加载和预处理功能。
- PyTorch DataLoader:用于加载和预处理数据,支持多线程和批处理。
- HuggingFace Datasets:提供了丰富的数据集和预处理工具,支持多种NLP任务。
- Pandas:用于数据清洗和预处理,支持多种数据格式。
案例:我们可以使用HuggingFace Datasets库来加载和预处理医疗文本数据,因为它提供了许多便捷的函数和工具。
加载与预处理工具的Python实现
在人工智能模型的开发过程中,数据加载与预处理是至关重要的一环。为了高效地处理各种类型的数据,Python生态系统提供了许多强大的工具和库。这些工具不仅简化了数据加载和预处理的过程,还提供了丰富的功能以满足不同的需求。以下将详细讲解常用的加载与预处理工具,并结合Python代码示例,展示如何高效地使用这些工具。
23.2.8.1. 数据加载工具
23.2.8.1.1 Pandas
Pandas是Python中最流行的数据处理和分析库,提供了高效的数据结构(如DataFrame)和丰富的数据操作功能,适用于处理结构化数据。
主要功能:
- 读取和写入多种数据格式(如CSV、Excel、SQL数据库等)。
- 数据清洗和预处理(如处理缺失值、重复数据等)。
- 数据转换和聚合。
示例:使用Pandas读取CSV文件
import pandas as pd
# 读取CSV文件
df = pd.read_csv('data.csv')
# 查看前5行数据
print(df.head())
# 查看数据基本信息
print(df.info())
# 处理缺失值
df = df.dropna()
# 保存处理后的数据
df.to_csv('cleaned_data.csv', index=False)
23.2.8.1.2 NumPy
NumPy是Python中用于科学计算的基础库,提供了强大的多维数组对象和丰富的数学函数,适用于处理数值数据。
主要功能:
- 高效的数组运算。
- 线性代数、傅里叶变换、随机数生成等。
示例:使用NumPy进行数组操作
import numpy as np
# 创建数组
array = np.array([[1, 2, 3], [4, 5, 6]])
# 数组运算
array_squared = array ** 2
print(array_squared)
# 矩阵运算
matrix = np.matrix([[1, 2], [3, 4]])
inverse_matrix = np.linalg.inv(matrix)
print(inverse_matrix)
23.2.8.1.3 TensorFlow Data API
TensorFlow Data API提供了高效的数据加载和预处理功能,适用于大规模数据集和分布式训练。
主要功能:
- 数据管道构建。
- 数据批处理和打乱。
- 数据预处理(如映射、过滤等)。
示例:使用TensorFlow Data API加载数据
import tensorflow as tf
# 创建TensorFlow数据集
dataset = tf.data.Dataset.from_tensor_slices([1, 2, 3, 4, 5])
# 数据预处理
dataset = dataset.map(lambda x: x * 2)
dataset = dataset.batch(2)
# 迭代数据集
for batch in dataset:
print(batch)
23.2.8.1.4 PyTorch DataLoader
PyTorch DataLoader是PyTorch中用于加载和预处理数据的工具,支持多线程和批处理,适用于深度学习模型的训练。
主要功能:
- 数据加载和批处理。
- 数据打乱。
- 多线程数据加载。
示例:使用PyTorch DataLoader加载数据
import torch
from torch.utils.data import DataLoader, TensorDataset
# 创建数据
data = torch.tensor([[1, 2], [3, 4], [5, 6], [7, 8]])
labels = torch.tensor([0, 1, 0, 1])
# 创建TensorDataset
dataset = TensorDataset(data, labels)
# 创建DataLoader
dataloader = DataLoader(dataset, batch_size=2, shuffle=True, num_workers=2)
# 迭代DataLoader
for batch_data, batch_labels in dataloader:
print(batch_data, batch_labels)
23.2.8.1.5 HuggingFace Datasets
HuggingFace Datasets提供了丰富的数据集和预处理工具,支持多种NLP任务,适用于大规模数据集的处理。
主要功能:
- 访问和下载多种公开数据集。
- 数据预处理和转换。
- 数据集缓存和版本控制。
示例:使用HuggingFace Datasets加载IMDB数据集
from datasets import load_dataset
# 加载IMDB数据集
dataset = load_dataset('imdb')
# 查看数据集结构
print(dataset)
# 访问训练集
train_dataset = dataset['train']
# 查看前5条数据
print(train_dataset[:5])
23.2.8.2. 数据预处理工具
23.2.8.2.1 Scikit-learn
Scikit-learn是Python中用于机器学习的库,提供了丰富的预处理工具,如标准化、归一化、编码等。
主要功能:
- 数据标准化和归一化。
- 特征编码(如独热编码、标签编码)。
- 特征选择和降维。
示例:使用Scikit-learn进行数据预处理
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
# 读取数据
df = pd.read_csv('data.csv')
# 特征和标签
X = df.drop('label', axis=1)
y = df['label']
# 定义预处理步骤
preprocessor = ColumnTransformer(
transformers=[
('num', StandardScaler(), ['feature1', 'feature2']),
('cat', OneHotEncoder(), ['category'])
]
)
# 创建Pipeline
pipeline = Pipeline(steps=[
('preprocessor', preprocessor),
('classifier', LogisticRegression())
])
# 训练模型
pipeline.fit(X, y)
23.2.8.2.2 NLTK
NLTK是Python中用于自然语言处理的库,提供了丰富的文本预处理工具,如分词、去除停用词、词形还原等。
主要功能:
- 分词。
- 去除停用词。
- 词形还原。
- 词性标注。
示例:使用NLTK进行文本预处理
import nltk
from nltk.corpus import stopwords
from nltk.stem import WordNetLemmatizer
# 下载资源
nltk.download('stopwords')
nltk.download('wordnet')
# 初始化分词器和词形还原器
lemmatizer = WordNetLemmatizer()
stop_words = set(stopwords.words('english'))
# 文本预处理函数
def preprocess(text):
tokens = nltk.word_tokenize(text)
tokens = [word for word in tokens if word.isalnum()]
tokens = [word for word in tokens if word not in stop_words]
tokens = [lemmatizer.lemmatize(word) for word in tokens]
return ' '.join(tokens)
# 应用预处理
df['clean_text'] = df['text'].apply(preprocess)
23.2.8.2.3 spaCy
spaCy是Python中用于高级自然语言处理的库,提供了高效的文本预处理和深度学习模型支持。
主要功能:
- 分词。
- 命名实体识别(NER)。
- 词性标注。
- 依存句法分析。
示例:使用spaCy进行文本预处理
import spacy
# 加载预训练的spaCy模型
nlp = spacy.load('en_core_web_sm')
# 文本预处理函数
def preprocess(text):
doc = nlp(text)
tokens = [token.lemma_ for token in doc if token.is_alpha and not token.is_stop]
return ' '.join(tokens)
# 应用预处理
df['clean_text'] = df['text'].apply(preprocess)
23.2.8.3. 综合示例
以下是一个综合的数据加载与预处理示例,涵盖了数据读取、数据清洗、特征编码和特征标准化。
import pandas as pd
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
# 1. 数据加载
df = pd.read_csv('data.csv')
# 2. 数据清洗
df = df.dropna()
# 3. 特征和标签
X = df.drop('label', axis=1)
y = df['label']
# 4. 定义预处理步骤
preprocessor = ColumnTransformer(
transformers=[
('num', StandardScaler(), ['feature1', 'feature2']),
('cat', OneHotEncoder(), ['category'])
]
)
# 5. 创建Pipeline
pipeline = Pipeline(steps=[
('preprocessor', preprocessor),
('classifier', LogisticRegression())
])
# 6. 训练模型
pipeline.fit(X, y)
# 7. 评估模型
accuracy = pipeline.score(X, y)
print('模型准确率:', accuracy)
23.2.8.4. 小结
数据加载与预处理是AI模型开发中的关键步骤,Python生态系统提供了丰富的工具和库,如Pandas、NumPy、TensorFlow Data API、PyTorch DataLoader、HuggingFace Datasets、Scikit-learn、NLTK和spaCy等,可以简化数据处理过程,提高工作效率。通过合理使用这些工具,可以有效提升数据质量,为模型训练和评估打下坚实的基础。
23.2.9. 实践案例
以下是一个使用HuggingFace Datasets进行数据加载与预处理的示例:
from datasets import load_dataset
from transformers import BertTokenizer
# 加载数据集
dataset = load_dataset('medical_text_dataset')
# 初始化BERT分词器
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
# 定义预处理函数
def preprocess_function(examples):
return tokenizer(examples['text'], padding='max_length', truncation=True)
# 应用预处理
tokenized_dataset = dataset.map(preprocess_function, batched=True)
# 划分训练集和测试集
train_dataset = tokenized_dataset['train']
test_dataset = tokenized_dataset['test']
在这个示例中,我们首先加载了医疗文本数据集,然后使用BERT分词器对文本进行分词和编码,最后将数据划分为训练集和测试集。
实践案例:基于Python的文本分类任务实战
在本节中,我们将通过一个文本分类任务的完整实践案例,展示如何将前面所学的数据加载与预处理技巧应用到实际项目中。我们将使用Python及其相关库,完成从数据收集到模型训练的全过程。以下是详细的步骤和代码示例。
23.2.9.1. 项目概述
任务:构建一个文本分类模型,能够根据给定的文本内容,将其分类为不同的类别。例如,新闻文章分类、情感分析、产品评论分类等。
目标:使用Python及其相关库,完成数据加载、预处理、特征工程、模型训练和评估的全过程。
23.2.9.2. 数据收集与选择
在本案例中,我们将使用Kaggle上的20 Newsgroups数据集,这是一个经典的文本分类数据集,包含20个不同的新闻组类别。
步骤:
1. 安装必要的库:
pip install pandas scikit-learn
2. 加载数据:
import pandas as pd
from sklearn.datasets import fetch_20newsgroups
# 加载20 Newsgroups数据集
newsgroups = fetch_20newsgroups(subset='all', remove=('headers', 'footers', 'quotes'))
# 创建DataFrame
df = pd.DataFrame({
'text': newsgroups.data,
'label': newsgroups.target
})
print(df.head())
3. 数据探索:
# 查看类别分布
print(df['label'].value_counts())
# 查看文本长度分布
df['text_length'] = df['text'].apply(len)
print(df['text_length'].describe())
23.2.9.3. 数据清洗与预处理
步骤:
1.去除噪声:去除HTML标签、特殊字符等。
2.标准化文本:统一文本格式,如转换为小写。
3.去除停用词:去除常见的无意义词汇。
4.分词与词形还原:将文本分割成词语,并进行词形还原。
代码示例:
import re
import nltk
from nltk.corpus import stopwords
from nltk.stem import WordNetLemmatizer
# 下载资源
nltk.download('stopwords')
nltk.download('wordnet')
# 初始化分词器和词形还原器
lemmatizer = WordNetLemmatizer()
stop_words = set(stopwords.words('english'))
# 文本清洗与预处理函数
def clean_text(text):
# 去除HTML标签
text = re.sub(r'<.*?>', '', text)
# 转换为小写
text = text.lower()
# 去除特殊字符和数字
text = re.sub(r'[^a-zA-Z\s]', '', text)
# 分词
tokens = text.split()
# 去除停用词
tokens = [word for word in tokens if word not in stop_words]
# 词形还原
tokens = [lemmatizer.lemmatize(word) for word in tokens]
# 合并词语
return ' '.join(tokens)
# 应用预处理
df['clean_text'] = df['text'].apply(clean_text)
print(df['clean_text'].head())
23.2.9.4. 特征工程
步骤:
1.文本向量化:将文本转换为数值特征。常用的方法包括TF-IDF、词嵌入(如Word2Vec、BERT等)。
2.特征选择:选择对模型最有用的特征。
代码示例:
from sklearn.feature_extraction.text import TfidfVectorizer
# 初始化TF-IDF向量化器
vectorizer = TfidfVectorizer(max_features=10000)
# 应用TF-IDF向量化
X = vectorizer.fit_transform(df['clean_text'])
print('特征矩阵形状:', X.shape)
23.2.9.5. 数据分割
步骤:
1.划分训练集和测试集:将数据集划分为训练集和测试集,以评估模型性能。
2.使用分层分割:保持类别比例一致。
代码示例:
from sklearn.model_selection import train_test_split
# 标签
y = df['label']
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, stratify=y, random_state=42)
print('训练集大小:', X_train.shape[0])
print('测试集大小:', X_test.shape[0])
23.2.9.6. 模型训练与评估
步骤:
1.选择模型:选择合适的机器学习模型,如逻辑回归、支持向量机(SVM)、随机森林等。
2.训练模型:使用训练集训练模型。
3.评估模型:使用测试集评估模型性能。
代码示例:
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import classification_report, accuracy_score
# 初始化模型
model = LogisticRegression(max_iter=1000)
# 训练模型
model.fit(X_train, y_train)
# 预测
y_pred = model.predict(X_test)
# 评估
accuracy = accuracy_score(y_test, y_pred)
print('模型准确率:', accuracy)
# 详细分类报告
print(classification_report(y_test, y_pred, target_names=newsgroups.target_names))
23.2.9.7. 模型优化
步骤:
1.超参数调优:使用网格搜索(Grid Search)或随机搜索(Random Search)优化模型超参数。
2.交叉验证:使用交叉验证评估模型性能。
代码示例:
from sklearn.model_selection import GridSearchCV
# 定义超参数范围
param_grid = {
'C': [0.1, 1, 10],
'solver': ['liblinear', 'lbfgs']
}
# 初始化Grid Search
grid = GridSearchCV(LogisticRegression(max_iter=1000), param_grid, cv=5, scoring='accuracy')
# 训练模型
grid.fit(X_train, y_train)
# 最佳参数
print('最佳参数:', grid.best_params_)
# 最佳模型评估
y_pred = grid.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print('优化后模型准确率:', accuracy)
23.2.9.8. 结果分析与总结
通过上述步骤,我们成功构建了一个文本分类模型,并对其进行了训练和评估。以下是一些关键点总结:
- 数据清洗与预处理:有效的文本清洗和预处理可以显著提升模型性能。
- 特征工程:选择合适的文本向量化方法(如TF-IDF)是关键。
- 模型选择与优化:通过超参数调优和交叉验证,可以进一步提升模型性能。
- 评估指标:除了准确率,还应关注其他评估指标,如精确率、召回率、F1-score等,以全面评估模型性能。
23.2.9.9. 扩展与未来工作
- 使用深度学习模型:尝试使用深度学习模型(如BERT)进行文本分类,以提升性能。
- 处理不平衡数据:如果类别分布不均衡,可以采用过采样、欠采样或生成对抗网络(GAN)等方法进行处理。
- 模型部署:将训练好的模型部署为Web服务或API,以便实际应用。
23.2.9.10 小结
通过本案例的实践,您将能够掌握从数据收集到模型评估的完整流程,并将其应用于实际的文本分类任务中。Python及其相关库提供了丰富的工具和功能,可以大大简化数据处理和模型训练过程,提高工作效率。
23.2.10 数据准备与预处理小结
数据准备与预处理是AI模型微调过程中不可或缺的一环。通过有效的数据收集、清洗、标注、分割、增强和特征工程,我们可以为模型提供高质量的训练数据,从而提升模型的性能。在实际应用中,选择合适的工具和库可以大大简化数据处理过程,提高工作效率。通过本章的学习,您将能够掌握数据准备与预处理的关键步骤,并将其应用于AI模型的微调实战中,为后续的模型选择、评估和部署打下坚实的基础。
23.3 模型选择与评估策略
在微调预训练模型的过程中,模型选择和评估策略是确保模型性能的关键步骤。选择合适的模型架构和评估方法,不仅能提升模型的预测能力,还能有效避免过拟合并确保模型的泛化能力。以下将详细讲解模型选择与评估策略的各个环节,并结合实际案例,展示如何进行有效的模型选择与评估。
23.3.1. 模型选择
23.3.1.1 预训练模型的选择
预训练模型是指在大规模数据集上预先训练好的模型,这些模型已经学习到了丰富的语言或视觉特征。选择合适的预训练模型是微调成功的关键。以下是一些常用的预训练模型:
- BERT(Bidirectional Encoder Representations from Transformers):适用于多种NLP任务,如文本分类、命名实体识别、问答系统等。
- GPT(Generative Pre-trained Transformer):适用于生成任务,如文本生成、对话系统等。
- RoBERTa:BERT的改进版本,在更大规模的数据集上训练,性能更优。
- T5(Text-To-Text Transfer Transformer):将所有NLP任务统一为文本到文本的格式,适用于多种任务。
- ResNet(Residual Networks):适用于计算机视觉任务,如图像分类、目标检测等。
- EfficientNet:在参数量和计算量之间取得平衡,性能优异。
示例:选择BERT作为预训练模型
from transformers import BertTokenizer, BertForSequenceClassification
# 加载预训练的BERT tokenizer和模型
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertForSequenceClassification.from_pretrained('bert-base-uncased', num_labels=20)
23.3.1.2 模型架构调整
根据目标任务的不同,可能需要对预训练模型的架构进行调整。例如,修改输出层以适应特定的任务。
示例:修改BERT的输出层用于文本分类
from transformers import BertModel, BertTokenizer
# 加载预训练的BERT模型和tokenizer
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
bert = BertModel.from_pretrained('bert-base-uncased')
# 添加一个全连接层用于分类
import torch.nn as nn
class TextClassificationModel(nn.Module):
def __init__(self, bert, num_labels):
super(TextClassificationModel, self).__init__()
self.bert = bert
self.dropout = nn.Dropout(0.3)
self.classifier = nn.Linear(bert.config.hidden_size, num_labels)
def forward(self, input_ids, attention_mask):
outputs = self.bert(input_ids=input_ids, attention_mask=attention_mask)
pooled_output = outputs[1] # CLS token
dropout_output = self.dropout(pooled_output)
logits = self.classifier(dropout_output)
return logits
# 初始化模型
num_labels = 20
model = TextClassificationModel(bert, num_labels)
23.3.2. 评估策略
23.3.2.1 评估指标
选择合适的评估指标对于评估模型性能至关重要。以下是一些常用的评估指标:
- 准确率(Accuracy):正确预测的比例。
- 精确率(Precision):正类预测中实际为正类的比例。
- 召回率(Recall):实际为正类的样本中被正确预测为正类的比例。
- F1-score:精确率和召回率的调和平均数。
- ROC-AUC:接收者操作特征曲线下面积,用于评估分类模型的区分能力。
示例:使用Scikit-learn计算评估指标
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, roc_auc_score
# 假设y_true是真实标签,y_pred是预测标签,y_scores是预测概率
y_true = [0, 1, 1, 0, 1]
y_pred = [0, 1, 0, 0, 1]
y_scores = [0.2, 0.8, 0.6, 0.3, 0.9]
accuracy = accuracy_score(y_true, y_pred)
precision = precision_score(y_true, y_pred)
recall = recall_score(y_true, y_pred)
f1 = f1_score(y_true, y_pred)
roc_auc = roc_auc_score(y_true, y_scores)
print(f'准确率: {accuracy}')
print(f'精确率: {precision}')
print(f'召回率: {recall}')
print(f'F1-score: {f1}')
print(f'ROC-AUC: {roc_auc}')
23.3.2.2 交叉验证
交叉验证是一种评估模型性能的方法,通过将数据集划分为多个子集,轮流使用其中一个子集作为验证集,其余子集作为训练集,进行多次训练和评估。
示例:使用K折交叉验证
from sklearn.model_selection import cross_val_score
from sklearn.linear_model import LogisticRegression
# 假设X是特征矩阵,y是标签
X = df.drop('label', axis=1).values
y = df['label'].values
# 初始化模型
model = LogisticRegression(max_iter=1000)
# 进行5折交叉验证
scores = cross_val_score(model, X, y, cv=5, scoring='accuracy')
print('交叉验证准确率:', scores)
print('平均准确率:', scores.mean())
23.3.2.3 混淆矩阵
混淆矩阵用于展示分类模型的预测结果,包括正确和错误的预测情况。
示例:绘制混淆矩阵
import matplotlib.pyplot as plt
from sklearn.metrics import confusion_matrix
import seaborn as sns
# 假设y_true是真实标签,y_pred是预测标签
y_true = [0, 1, 1, 0, 1]
y_pred = [0, 1, 0, 0, 1]
# 计算混淆矩阵
cm = confusion_matrix(y_true, y_pred)
# 绘制热图
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues')
plt.xlabel('Predicted')
plt.ylabel('True')
plt.show()
23.3.3. 模型选择与评估的最佳实践
- 选择合适的预训练模型:根据目标任务选择最合适的预训练模型。例如,BERT适用于多种NLP任务,而ResNet则适用于图像分类。
- 调整模型架构:根据需要调整预训练模型的架构,如修改输出层以适应特定任务。
- 使用多种评估指标:不要仅依赖单一指标,综合使用多种评估指标以全面评估模型性能。
- 进行交叉验证:使用交叉验证评估模型性能,确保模型的泛化能力。
- 分析混淆矩阵:通过分析混淆矩阵,了解模型在哪些类别上表现良好,哪些类别上存在不足。
23.3.4. 综合示例
以下是一个综合的模型选择与评估示例,展示了如何选择预训练模型、调整模型架构并进行评估。
import pandas as pd
from transformers import BertTokenizer, BertForSequenceClassification, Trainer, TrainingArguments
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, precision_recall_fscore_support
# 1. 数据加载与预处理
df = pd.read_csv('data.csv')
X = df['text']
y = df['label']
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, stratify=y, random_state=42)
# 加载tokenizer
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
# 编码文本
train_encodings = tokenizer(X_train.tolist(), truncation=True, padding=True, max_length=128)
test_encodings = tokenizer(X_test.tolist(), truncation=True, padding=True, max_length=128)
# 转换为TensorDataset
import torch
from torch.utils.data import TensorDataset, DataLoader
train_dataset = TensorDataset(torch.tensor(train_encodings['input_ids']),
torch.tensor(train_encodings['attention_mask']),
torch.tensor(y_train.tolist()))
test_dataset = TensorDataset(torch.tensor(test_encodings['input_ids']),
torch.tensor(test_encodings['attention_mask']),
torch.tensor(y_test.tolist()))
# 2. 模型选择与训练
model = BertForSequenceClassification.from_pretrained('bert-base-uncased', num_labels=20)
# 定义训练参数
training_args = TrainingArguments(
output_dir='./results',
num_train_epochs=3,
per_device_train_batch_size=16,
per_device_eval_batch_size=32,
evaluation_strategy='epoch',
logging_dir='./logs',
)
# 定义Trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=test_dataset,
compute_metrics=lambda preds: {
'accuracy': accuracy_score(y_test, preds[0].argmax(axis=1)),
'precision', precision_recall_fscore_support(y_test, preds[0].argmax(axis=1), average='weighted')[:3]
}
)
# 训练模型
trainer.train()
# 评估模型
results = trainer.evaluate()
print(results)
23.3.5. 小结
通过本小节的学习,您将能够掌握模型选择与评估的关键步骤,并将其应用于AI模型的微调实战中。选择合适的预训练模型和评估策略,不仅能提升模型的性能,还能确保模型的泛化能力和稳定性。Python及其相关库提供了丰富的工具和功能,可以大大简化模型选择与评估的过程,提高工作效率。
23.4 微调技巧与最佳实践
微调预训练模型是将一个在大规模数据集上预先训练好的模型适配到特定任务上的过程。虽然预训练模型已经具备丰富的语言或视觉特征,但为了在特定任务上取得最佳性能,仍需进行精细的微调。以下将详细介绍微调过程中的一些关键技巧与最佳实践,并通过具体示例展示如何高效地进行模型微调。
23.4.1. 选择合适的预训练模型
技巧:根据目标任务选择最合适的预训练模型。
- NLP任务:对于文本分类、命名实体识别等任务,BERT、RoBERTa、ALBERT等模型是不错的选择。
- 生成任务:对于文本生成、对话系统等任务,GPT系列模型(如GPT-2、GPT-3)更为适用。
- 计算机视觉任务:对于图像分类、目标检测等任务,ResNet、EfficientNet、Vision Transformer(ViT)等模型表现优异。
示例:选择BERT用于文本分类
from transformers import BertForSequenceClassification, BertTokenizer
# 加载预训练的BERT模型和tokenizer
model_name = 'bert-base-uncased'
tokenizer = BertTokenizer.from_pretrained(model_name)
model = BertForSequenceClassification.from_pretrained(model_name, num_labels=20)
23.4.2. 数据集准备与预处理
技巧:确保数据集的质量和多样性,并进行适当的预处理。
- 数据清洗:去除噪声数据、标准化文本等。
- 数据增强:通过同义词替换、随机插入等方法增加数据多样性。
- 标签编码:将文本标签转换为数值形式,如使用独热编码或标签编码。
示例:使用HuggingFace的Tokenizer进行文本编码
from transformers import BertTokenizer
import pandas as pd
# 读取数据
df = pd.read_csv('data.csv')
# 初始化tokenizer
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
# 编码文本
def encode_text(text):
return tokenizer(text, truncation=True, padding='max_length', max_length=128, return_tensors='pt')
# 应用编码
df['input_ids'] = df['text'].apply(lambda x: encode_text(x)['input_ids'].squeeze())
df['attention_mask'] = df['text'].apply(lambda x: encode_text(x)['attention_mask'].squeeze())
23.4.3. 模型微调策略
23.4.3.1 冻结预训练层
在微调过程中,可以选择冻结预训练模型的某些层,仅训练新增的层或高层参数。这可以减少训练时间,并防止过拟合并保留预训练模型的特征。
示例:冻结BERT的所有层,仅训练分类头
from transformers import BertForSequenceClassification
# 加载预训练的BERT模型
model = BertForSequenceClassification.from_pretrained('bert-base-uncased', num_labels=20)
# 冻结所有预训练层
for param in model.bert.parameters():
param.requires_grad = False
# 仅训练分类头
optimizer = torch.optim.Adam(model.classifier.parameters(), lr=2e-5)
23.4.3.2 学习率调整
选择合适的学习率对于模型微调至关重要。通常,较小的学习率(如2e-5到3e-5)适用于微调预训练模型,以防止破坏预训练模型的权重。
示例:使用AdamW优化器和学习率调度器
from transformers import AdamW, get_linear_schedule_with_warmup
import torch
# 初始化优化器
optimizer = AdamW(model.parameters(), lr=2e-5, eps=1e-8)
# 设置总训练步数
epochs = 3
total_steps = len(train_dataloader) * epochs
# 设置学习率调度器
scheduler = get_linear_schedule_with_warmup(optimizer,
num_warmup_steps=0,
num_training_steps=total_steps)
23.4.3.3 数据增强与正则化
通过数据增强和正则化技术,可以提高模型的泛化能力。
- 数据增强:如前面提到的文本数据增强方法。
- Dropout:在模型中添加Dropout层,防止过拟合。
- 权重衰减(Weight Decay):在优化器中添加权重衰减参数,惩罚过大的权重。
示例:在优化器中添加权重衰减
from transformers import AdamW
# 初始化优化器,设置权重衰减
optimizer = AdamW(model.parameters(), lr=2e-5, weight_decay=1e-2)
23.4.4. 模型评估与验证
技巧:使用多种评估指标和验证方法,确保模型的泛化能力。
- 评估指标:如准确率、精确率、召回率、F1-score等。
- 交叉验证:使用K折交叉验证,评估模型在不同数据子集上的性能。
- 混淆矩阵:分析模型的预测结果,找出分类错误的原因。
示例:使用交叉验证进行模型评估
from sklearn.model_selection import cross_val_score
from sklearn.metrics import accuracy_score, precision_recall_fscore_support
from transformers import Trainer, TrainingArguments
# 定义训练参数
training_args = TrainingArguments(
output_dir='./results',
num_train_epochs=3,
per_device_train_batch_size=16,
per_device_eval_batch_size=32,
evaluation_strategy='epoch',
logging_dir='./logs',
)
# 定义Trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=val_dataset,
compute_metrics=lambda preds: {
'accuracy': accuracy_score(y_val, preds[0].argmax(axis=1)),
'precision', precision_recall_fscore_support(y_val, preds[0].argmax(axis=1), average='weighted')[:3]
}
)
# 进行交叉验证
results = trainer.evaluate()
print(results)
23.4.5. 模型保存与部署
技巧:保存训练好的模型,并进行优化以便部署。
- 保存模型:使用
save_pretrained方法保存模型和tokenizer。 - 模型优化:使用TorchScript或ONNX等工具将模型转换为更高效的格式。
- 部署平台:选择合适的部署平台,如TensorFlow Serving、TorchServe、AWS SageMaker等。
示例:保存微调后的模型
model.save_pretrained('./fine_tuned_model')
tokenizer.save_pretrained('./fine_tuned_model')
23.4.6. 综合示例
以下是一个综合的微调示例,展示了如何进行模型微调、评估和保存。
import pandas as pd
from transformers import BertForSequenceClassification, BertTokenizer, Trainer, TrainingArguments
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, precision_recall_fscore_support
# 1. 数据加载与预处理
df = pd.read_csv('data.csv')
X = df['text']
y = df['label']
# 划分训练集和验证集
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2, stratify=y, random_state=42)
# 加载tokenizer
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
# 编码文本
train_encodings = tokenizer(X_train.tolist(), truncation=True, padding=True, max_length=128)
val_encodings = tokenizer(X_val.tolist(), truncation=True, padding=True, max_length=128)
# 创建Dataset
import torch
from torch.utils.data import TensorDataset, DataLoader
train_dataset = TensorDataset(torch.tensor(train_encodings['input_ids']),
torch.tensor(train_encodings['attention_mask']),
torch.tensor(y_train.tolist()))
val_dataset = TensorDataset(torch.tensor(val_encodings['input_ids']),
torch.tensor(val_encodings['attention_mask']),
torch.tensor(y_val.tolist()))
# 2. 模型微调
model = BertForSequenceClassification.from_pretrained('bert-base-uncased', num_labels=20)
# 定义训练参数
training_args = TrainingArguments(
output_dir='./results',
num_train_epochs=3,
per_device_train_batch_size=16,
per_device_eval_batch_size=32,
evaluation_strategy='epoch',
logging_dir='./logs',
)
# 定义Trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=val_dataset,
compute_metrics=lambda preds: {
'accuracy': accuracy_score(y_val, preds[0].argmax(axis=1)),
'precision', precision_recall_fscore_support(y_val, preds[0].argmax(axis=1), average='weighted')[:3]
}
)
# 训练模型
trainer.train()
# 评估模型
results = trainer.evaluate()
print(results)
# 3. 保存模型
model.save_pretrained('./fine_tuned_model')
tokenizer.save_pretrained('./fine_tuned_model')
23.4.7 小结
通过本章的学习,您将能够掌握微调预训练模型的关键技巧与最佳实践,并将其应用于AI模型的实战中。选择合适的预训练模型、调整模型架构、进行数据增强和正则化,以及合理的评估和验证方法,都是确保模型性能的重要因素。Python及其相关库提供了丰富的工具和功能,可以大大简化微调过程,提高工作效率。
23.5 部署与优化:将模型投入生产环境
将训练好的AI模型部署到生产环境,使其能够实时或批量地处理实际业务中的数据,是AI项目成功的关键一步。部署过程不仅涉及将模型集成到应用程序中,还需要考虑性能优化、扩展性、可靠性和安全性等多个方面。以下将详细讲解模型部署的关键步骤、最佳实践以及优化策略,并通过具体示例展示如何高效地将模型投入生产环境。
23.5.1. 模型部署的关键步骤
23.5.1.1 选择部署平台
根据项目需求和资源,选择合适的部署平台是第一步。以下是几种常见的部署平台:
- 云服务平台:如AWS SageMaker、Google AI Platform、Microsoft Azure ML等,提供丰富的AI服务和支持。
- 自托管服务器:使用自己的服务器或数据中心进行部署,适用于对数据隐私和安全性有较高要求的场景。
- 边缘设备:将模型部署到移动设备、物联网设备等边缘设备上,适用于实时性要求高的应用。
示例:使用AWS SageMaker部署模型
import sagemaker
from sagemaker.pytorch import PyTorchModel
# 初始化SageMaker会话
sagemaker_session = sagemaker.Session()
# 上传模型到S3
model_data = sagemaker_session.upload_data(path='./fine_tuned_model', key_prefix='model')
# 创建PyTorch模型对象
model = PyTorchModel(model_data=model_data,
role='arn:aws:iam::123456789012:role/SageMakerRole',
framework_version='1.8.1',
py_version='py3',
entry_point='inference.py')
# 部署模型
predictor = model.deploy(initial_instance_count=1, instance_type='ml.m5.large')
23.5.1.2 模型序列化与导出
将训练好的模型序列化并导出为适合部署的格式,如TorchScript、ONNX、TensorFlow SavedModel等。
示例:将PyTorch模型转换为TorchScript
import torch
from transformers import BertForSequenceClassification, BertTokenizer
# 加载训练好的模型
model = BertForSequenceClassification.from_pretrained('./fine_tuned_model')
model.eval()
# 示例输入
example_input = torch.randint(0, 1000, (1, 128))
# 转换为TorchScript
traced_script_module = torch.jit.trace(model, example_input)
traced_script_module.save("model.pt")
23.5.1.3 创建API服务
将模型封装为API服务,使其能够通过HTTP请求进行访问。常用的工具和框架包括Flask、FastAPI、Django等。
示例:使用FastAPI创建API服务
from fastapi import FastAPI, Request
import torch
from transformers import BertTokenizer, BertForSequenceClassification
import uvicorn
app = FastAPI()
# 加载模型和tokenizer
model = torch.jit.load('model.pt')
model.eval()
tokenizer = BertTokenizer.from_pretrained('./fine_tuned_model')
@app.post("/predict")
async def predict(request: Request):
data = await request.json()
text = data['text']
inputs = tokenizer(text, return_tensors='pt', truncation=True, padding=True, max_length=128)
with torch.no_grad():
outputs = model(**inputs)
logits = outputs.logits
prediction = torch.argmax(logits, dim=1).item()
return {"prediction": prediction}
if __name__ == "__main__":
uvicorn.run(app, host="0.0.0.0", port=8000)
23.5.1.4 容器化与编排
使用容器化技术(如Docker)将应用程序和依赖项打包,并在容器编排平台(如Kubernetes)上进行部署和管理,以提高可移植性和可扩展性。
示例:使用Docker构建容器镜像
# Dockerfile
FROM python:3.8-slim
# 设置工作目录
WORKDIR /app
# 复制依赖文件并安装
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
# 复制应用代码
COPY . .
# 暴露端口
EXPOSE 8000
# 运行应用
CMD ["uvicorn", "main:app", "--host", "0.0.0.0", "--port", "8000"]
构建镜像:
docker build -t my-model-service .
运行容器:
docker run -d -p 8000:8000 my-model-service
23.5.2. 性能优化
23.5.2.1 模型压缩
通过模型剪枝、量化等方法压缩模型,减少计算量和内存占用,提高推理速度。
示例:使用量化技术
import torch
from transformers import BertForSequenceClassification, BertTokenizer
# 加载模型
model = BertForSequenceClassification.from_pretrained('./fine_tuned_model')
model.eval()
# 转换为量化模型
quantized_model = torch.quantization.quantize_dynamic(
model, {torch.nn.Linear}, dtype=torch.qint8
)
torch.jit.save(quantized_model, "quantized_model.pt")
23.5.2.2 并行与分布式计算
利用多核CPU、GPU或分布式计算资源,加速模型推理。
示例:使用GPU进行推理
import torch
# 检查是否有可用的GPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
# 推理时将数据移到GPU
inputs = inputs.to(device)
with torch.no_grad():
outputs = model(**inputs)
23.5.3. 安全性与隐私
23.5.3.1 数据隐私
确保在模型部署过程中,保护用户数据的隐私。可以使用数据加密、差分隐私等技术。
23.5.3.2 模型安全
防止模型被恶意攻击,如对抗样本攻击。可以通过对抗训练、输入验证等方法增强模型的安全性。
示例:使用对抗训练增强模型鲁棒性
from transformers import Trainer, TrainingArguments
import torch
# 定义对抗训练参数
training_args = TrainingArguments(
...
adversarial_train=True,
...
)
trainer = Trainer(
...
args=training_args,
...
)
trainer.train()
23.5.4. 持续集成与持续部署(CI/CD)
通过CI/CD管道,实现模型的自动化测试、构建和部署,提高部署效率和可靠性。
示例:使用GitHub Actions实现CI/CD
# .github/workflows/ci-cd.yml
name: CI/CD Pipeline
on:
push:
branches:
- main
jobs:
build:
runs-on: ubuntu-latest
steps:
- name: Checkout code
uses: actions/checkout@v2
- name: Set up Python
uses: actions/setup-python@v2
with:
python-version: '3.8'
- name: Install dependencies
run: |
pip install --upgrade pip
pip install -r requirements.txt
- name: Run tests
run: |
pytest
- name: Deploy to AWS SageMaker
run: |
# 部署脚本
aws sagemaker create-model ...
23.5.5. 监控与维护
23.5.5.1 模型监控
实时监控模型的性能指标,如准确率、延迟、吞吐量等,及时发现和解决问题。
示例:使用Prometheus和Grafana进行监控
from prometheus_client import start_http_server, Summary, Gauge
# 定义指标
REQUEST_TIME = Summary('request_processing_seconds', 'Time spent processing request')
# 监控函数
@REQUEST_TIME.time()
def predict(inputs):
# 模型推理
...
# 启动HTTP服务器
start_http_server(8001)
23.5.5.2 模型更新
根据监控结果和业务需求,定期更新模型,确保其持续保持高性能。
示例:自动化模型更新流程
# 定期运行更新脚本
cronjob: "0 0 * * *" # 每天午夜运行
script: python update_model.py
23.5.6. 综合示例
以下是一个综合的部署与优化示例,展示了如何将模型封装为API服务,并进行容器化部署和性能优化。
# main.py
from fastapi import FastAPI, Request
import torch
from transformers import BertTokenizer, BertForSequenceClassification
import uvicorn
app = FastAPI()
# 加载模型和tokenizer
model = torch.jit.load('quantized_model.pt')
model.eval()
tokenizer = BertTokenizer.from_pretrained('./fine_tuned_model')
@app.post("/predict")
async def predict(request: Request):
data = await request.json()
text = data['text']
inputs = tokenizer(text, return_tensors='pt', truncation=True, padding=True, max_length=128)
with torch.no_grad():
outputs = model(**inputs)
logits = outputs.logits
prediction = torch.argmax(logits, dim=1).item()
return {"prediction": prediction}
if __name__ == "__main__":
uvicorn.run(app, host="0.0.0.0", port=8000)
Dockerfile:
FROM python:3.8-slim
WORKDIR /app
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
COPY . .
EXPOSE 8000
CMD ["uvicorn", "main:app", "--host", "0.0.0.0", "--port", "8000"]
构建和运行容器:
docker build -t my-model-service .
docker run -d -p 8000:8000 my-model-service
23.5.7. 小结
通过本章的学习,您将能够掌握将AI模型部署到生产环境的关键步骤和最佳实践。选择合适的部署平台、进行模型序列化与导出、创建API服务、容器化与编排,以及性能优化、安全性和持续集成与部署等,都是确保模型在生产环境中稳定高效运行的重要因素。Python及其相关库提供了丰富的工具和功能,可以大大简化部署过程,提高工作效率。
第二十四章:计算机视觉(CV)实战
-
如何用Python执行图像识别与处理任务
-
物体检测与语义分割:从YOLO到Mask R-CNN
-
图像增强与数据增广技术
-
实时视频分析与流媒体处理
-
深度学习架构优化与超参数调整
-
高级主题:生成对抗网络(GANs)与自监督学习
24.1 如何用Python执行图像识别与处理任务
欢迎来到“计算机视觉”的魔法世界!在这个数字化的时代,计算机视觉(CV)就像是一位能够“看懂”图像和视频的“视觉魔法师”。通过计算机视觉技术,计算机可以识别、理解和处理图像中的内容,就像人类用眼睛观察世界一样。今天,我们将深入探讨如何使用Python执行图像识别与处理任务,开启你的计算机视觉之旅。
24.1.1 理解图像识别与处理
图像识别是指计算机识别图像中的对象、场景或特征,而图像处理则是对图像进行各种操作,如裁剪、缩放、旋转、滤波等。图像识别与处理是计算机视觉的基础,广泛应用于人脸识别、物体检测、自动驾驶、医疗影像分析等领域。
比喻:如果图像是一幅幅魔法画卷,那么图像识别就是解读画卷中的魔法符号,而图像处理则是对画卷进行修复和增强。
24.1.2 使用OpenCV进行图像处理
OpenCV(Open Source Computer Vision Library)是一个开源的计算机视觉和机器学习软件库,提供了丰富的图像处理和计算机视觉算法。
24.1.2.1 安装OpenCV
首先,你需要确保已经安装了OpenCV。可以使用pip来安装:
pip install opencv-python
24.1.2.2 基本图像操作
读取和显示图像:
import cv2
# 读取图像
image = cv2.imread('path_to_image.jpg')
# 检查图像是否成功加载
if image is None:
print("无法加载图像。请检查文件路径。")
else:
# 显示图像
cv2.imshow('Image', image)
cv2.waitKey(0) # 等待按键
cv2.destroyAllWindows() # 关闭所有窗口
解释:
cv2.imread()读取图像文件。cv2.imshow()显示图像窗口。cv2.waitKey(0)等待用户按键,0表示无限等待。cv2.destroyAllWindows()关闭所有OpenCV窗口。
保存图像:
cv2.imwrite('output.jpg', image)
解释:cv2.imwrite()将图像保存到指定路径。
图像缩放:
resized_image = cv2.resize(image, (宽度, 高度))
示例:
resized_image = cv2.resize(image, (800, 600))
图像旋转:
(高度, 宽度) = image.shape[:2]
中心 = (宽度 // 2, 高度 // 2)
旋转矩阵 = cv2.getRotationMatrix2D(中心, 角度, 1.0)
rotated_image = cv2.warpAffine(image, 旋转矩阵, (宽度, 高度))
解释:
cv2.getRotationMatrix2D()获取旋转矩阵。cv2.warpAffine()应用旋转。
24.1.2.3 图像滤波与边缘检测
高斯模糊:
blurred_image = cv2.GaussianBlur(image, (5, 5), 0)
解释:使用高斯滤波器进行模糊处理,减少图像噪声。
边缘检测(Canny算法):
edges = cv2.Canny(image, 阈值1, 阈值2)
示例:
edges = cv2.Canny(image, 100, 200)
cv2.imshow('Edges', edges)
cv2.waitKey(0)
cv2.destroyAllWindows()
24.1.2.4 图像识别
OpenCV提供了多种图像识别功能,如人脸检测、物体检测等。
人脸检测:
# 加载预训练的人脸检测模型
face_cascade = cv2.CascadeClassifier(cv2.data.haarcascades + 'haarcascade_frontalface_default.xml')
# 转换为灰度图像
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# 检测人脸
faces = face_cascade.detectMultiScale(gray, scaleFactor=1.1, minNeighbors=5)
# 绘制人脸矩形
for (x, y, w, h) in faces:
cv2.rectangle(image, (x, y), (x+w, y+h), (0, 255, 0), 2)
# 显示结果
cv2.imshow('Faces', image)
cv2.waitKey(0)
cv2.destroyAllWindows()
解释:
CascadeClassifier用于加载预训练的人脸检测模型。detectMultiScale()方法检测人脸,返回人脸的位置和大小。- 使用
cv2.rectangle()在图像上绘制矩形框。
24.1.3 使用深度学习进行图像识别
除了传统的图像处理方法,深度学习在图像识别领域也取得了巨大的成功。以下是一些常用的深度学习模型和库:
24.1.3.1 使用预训练的深度学习模型
使用TensorFlow Hub:
import tensorflow as tf
import tensorflow_hub as hub
# 加载预训练的图像分类模型
model = hub.load("https://tfhub.dev/google/imagenet/mobilenet_v2_100_224/classification/5")
# 读取图像并预处理
image_path = 'path_to_image.jpg'
image = tf.io.read_file(image_path)
image = tf.image.decode_jpeg(image, channels=3)
image = tf.image.resize(image, [224, 224])
image = tf.keras.applications.mobilenet_v2.preprocess_input(image)
# 进行预测
predictions = model([image])
print(predictions)
使用Keras:
from tensorflow.keras.applications.mobilenet_v2 import MobileNetV2, preprocess_input, decode_predictions
from tensorflow.keras.preprocessing import image
import numpy as np
# 加载预训练的模型
model = MobileNetV2(weights='imagenet')
# 读取图像并预处理
img = image.load_img('path_to_image.jpg', target_size=(224, 224))
x = image.img_to_array(img)
x = np.expand_dims(x, axis=0)
x = preprocess_input(x)
# 进行预测
preds = model.predict(x)
print(decode_predictions(preds, top=3)[0])
解释:
MobileNetV2是一个轻量级的预训练模型,适用于移动和嵌入式设备。preprocess_input()对图像进行预处理,使其符合模型的输入要求。decode_predictions()将模型输出转换为可读的标签和概率。
24.1.4 小结:计算机视觉的魔法
通过本节,你已经学习了如何使用Python进行图像识别与处理,就像掌握了“视觉魔法”的基础技巧。OpenCV和深度学习模型为计算机视觉提供了强大的工具和算法,使计算机能够“看懂”图像中的内容。希望你能灵活运用这些“视觉魔法”,让你的Python程序能够处理和识别图像,为编写更强大的计算机视觉应用打下坚实的基础。
24.2 物体检测与语义分割:从YOLO到Mask R-CNN
欢迎来到“视觉感知”的魔法进阶课程!在计算机视觉的世界里,物体检测和语义分割就像是两位能够深入理解图像内容的“高级魔法师”。物体检测不仅能识别图像中的对象,还能定位它们的位置,而语义分割则更进一步,将图像中的每个像素分类到特定的类别中。今天,我们将深入探讨从YOLO到Mask R-CNN等先进的算法,看看它们如何实现物体检测与语义分割。
24.2.1 物体检测:识别与定位
物体检测是计算机视觉中的一个重要任务,旨在识别图像中的对象并确定其位置。物体检测通常输出每个检测到的对象的类别和边界框(bounding box)。
24.2.1.1 YOLO(You Only Look Once)
YOLO是一种实时物体检测系统,以其高速度和良好的准确性而闻名。YOLO将图像划分为网格,并为每个网格单元预测边界框和类别概率。
主要特点:
- 实时性能:YOLO能够实时处理视频流,适用于需要快速响应的应用。
- 全局推理:YOLO在一次前向传播中完成所有预测,避免了传统方法中的重复计算。
工作原理:
1.图像划分:将输入图像划分为S×S网格。
2.边界框预测:每个网格单元预测B个边界框及其置信度。
3.类别预测:每个网格单元预测C个类别的概率。
示例:使用YOLOv5进行物体检测
import torch
import cv2
# 加载预训练的YOLOv5模型
model = torch.hub.load('ultralytics/yolov5', 'yolov5s', pretrained=True)
# 读取图像
img = 'path_to_image.jpg'
# 进行预测
results = model(img)
# 显示结果
results.show()
# 打印结果
print(results.pandas().xyxy[0])
24.2.1.2 SSD(Single Shot MultiBox Detector)
SSD是一种高效的单次检测器,结合了不同尺度的特征图来检测不同大小的对象。SSD在速度和准确性之间取得了良好的平衡。
主要特点:
- 多尺度预测:使用不同尺度的特征图进行预测,提高对小物体的检测能力。
- 单次检测:一次性完成所有预测,效率高。
24.2.1.3 Faster R-CNN
Faster R-CNN是一种两阶段检测器,先使用区域建议网络(Region Proposal Network, RPN)生成候选区域,然后对这些区域进行分类和边界框回归。Faster R-CNN在准确性上表现优异,但速度相对较慢。
主要特点:
- 高精度:由于两阶段设计,Faster R-CNN在准确性上通常优于单阶段检测器。
- 灵活性:可以轻松地扩展到更复杂的任务,如实例分割。
24.2.2 语义分割:为每个像素分类
语义分割是计算机视觉中的另一个重要任务,旨在将图像中的每个像素分类到预定义的类别中。与物体检测不同,语义分割不提供对象的边界框,而是提供像素级的分类结果。
24.2.2.1 Mask R-CNN
Mask R-CNN是Faster R-CNN的扩展,增加了对每个对象的像素级分割掩码(mask)的预测。Mask R-CNN能够同时进行物体检测和语义分割。
主要特点:
- 实例分割:不仅识别对象,还能分割出对象的精确边界。
- 多任务学习:同时进行分类、边界框回归和掩码预测。
工作原理:
1.区域建议:使用RPN生成候选区域。
2.ROIAlign:对候选区域进行对齐操作,确保像素级精度。
3.分类与边界框回归:对每个候选区域进行分类和边界框回归。
4.掩码预测:为每个对象生成像素级掩码。
示例:使用Mask R-CNN进行实例分割
import torch
import cv2
import matplotlib.pyplot as plt
# 加载预训练的Mask R-CNN模型
model = torch.hub.load('ashleve/segmentation_models.pytorch', 'mask_rcnn_resnet50_fpn', pretrained=True)
# 读取图像
img = cv2.imread('path_to_image.jpg')
img_rgb = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# 进行预测
predictions = model([torch.from_numpy(img_rgb).float() / 255])
# 可视化结果
plt.figure(figsize=(10, 10))
plt.imshow(predictions[0]['masks'][0, 0].mul(255).byte().cpu().numpy())
plt.axis('off')
plt.show()
24.2.2.2 U-Net
U-Net是一种用于语义分割的卷积神经网络(CNN),以其U形的架构而闻名。U-Net在医学图像分割中应用广泛,能够有效地处理高分辨率图像。
主要特点:
- 对称的编码器-解码器结构:编码器部分进行特征提取,解码器部分进行上采样和特征融合。
- 跳跃连接:将编码器和解码器的对应层连接起来,保留细节信息。
24.2.3 小结:物体检测与语义分割的魔法
通过本节,你已经学习了物体检测和语义分割的基本概念和先进算法,就像掌握了“视觉感知”的高级魔法技巧。YOLO、SSD、Faster R-CNN和Mask R-CNN等算法为计算机视觉提供了强大的工具,使计算机能够识别和分割图像中的对象和像素。希望你能灵活运用这些“视觉感知魔法”,让你的Python程序能够深入理解图像内容,为编写更强大的计算机视觉应用打下坚实的基础。
24.3 图像增强与数据增广技术
图像增强与数据增广是计算机视觉任务中提升模型性能的重要技术。通过对图像进行各种变换,可以生成新的训练样本,增加数据的多样性,从而帮助模型更好地泛化。以下将详细讲解图像增强与数据增广的各个环节,并结合Python代码示例,展示如何高效地进行图像增强与数据增广。
24.3.1. 图像增强与数据增广的定义与目的
图像增强是指通过各种技术手段改善图像的视觉效果,使其更易于人类或机器识别。常见的图像增强技术包括去噪、对比度调整、锐化等。
数据增广是指通过对训练图像进行一系列随机变换,生成新的训练样本,以增加数据的多样性,防止过拟合并提高模型的泛化能力。
24.3.2. 常见的图像增强与数据增广技术
24.3.2.1 几何变换
- 旋转(Rotation):将图像旋转一定角度。
- 缩放(Scaling):对图像进行缩放。
- 平移(Translation):在图像平面上移动图像。
- 翻转(Flipping):水平或垂直翻转图像。
- 裁剪(Cropping):随机裁剪图像的一部分。
示例:使用Albumentations进行几何变换
import albumentations as A
from PIL import Image
import matplotlib.pyplot as plt
# 读取图像
image = Image.open('image.jpg')
image = np.array(image)
# 定义几何变换
transform = A.Compose([
A.Rotate(limit=40, p=1),
A.TranslateX(limit=0.2, p=1),
A.TranslateY(limit=0.2, p=1),
A.HorizontalFlip(p=0.5),
A.RandomCrop(width=200, height=200, p=1)
])
# 应用变换
augmented_image = transform(image=image)['image']
# 显示原图和增强图
plt.subplot(1, 2, 1)
plt.imshow(image)
plt.title('Original Image')
plt.subplot(1, 2, 2)
plt.imshow(augmented_image)
plt.title('Augmented Image')
plt.show()
24.3.2.2 颜色变换
- 亮度调整(Brightness Adjustment):改变图像的亮度。
- 对比度调整(Contrast Adjustment):改变图像的对比度。
- 饱和度调整(Saturation Adjustment):改变图像的饱和度。
- 颜色抖动(Color Jittering):随机改变图像的颜色属性。
示例:使用Albumentations进行颜色变换
import albumentations as A
from PIL import Image
import matplotlib.pyplot as plt
# 读取图像
image = Image.open('image.jpg')
image = np.array(image)
# 定义颜色变换
transform = A.Compose([
A.RandomBrightnessContrast(p=1),
A.RandomGamma(p=1),
A.HueSaturationValue(p=1)
])
# 应用变换
augmented_image = transform(image=image)['image']
# 显示原图和增强图
plt.subplot(1, 2, 1)
plt.imshow(image)
plt.title('Original Image')
plt.subplot(1, 2, 2)
plt.imshow(augmented_image)
plt.title('Augmented Image')
plt.show()
24.3.2.3 噪声注入
- 高斯噪声(Gaussian Noise):向图像中添加高斯噪声。
- 椒盐噪声(Salt and Pepper Noise):向图像中添加椒盐噪声。
- 随机噪声(Random Noise):向图像中添加随机噪声。
示例:使用Albumentations添加高斯噪声
import albumentations as A
from PIL import Image
import matplotlib.pyplot as plt
# 读取图像
image = Image.open('image.jpg')
image = np.array(image)
# 定义噪声变换
transform = A.Compose([
A.GaussianNoise(p=1)
])
# 应用变换
augmented_image = transform(image=image)['image']
# 显示原图和增强图
plt.subplot(1, 2, 1)
plt.imshow(image)
plt.title('Original Image')
plt.subplot(1, 2, 2)
plt.imshow(augmented_image)
plt.title('Augmented Image')
plt.show()
24.3.2.4 随机擦除(Random Erasing)
随机擦除是指在图像中随机选择一块区域并将其擦除,可以有效防止过拟合并提高模型的鲁棒性。
示例:使用Albumentations进行随机擦除
import albumentations as A
from PIL import Image
import matplotlib.pyplot as plt
# 读取图像
image = Image.open('image.jpg')
image = np.array(image)
# 定义随机擦除变换
transform = A.Compose([
A.RandomErasing(p=1)
])
# 应用变换
augmented_image = transform(image=image)['image']
# 显示原图和增强图
plt.subplot(1, 2, 1)
plt.imshow(image)
plt.title('Original Image')
plt.subplot(1, 2, 2)
plt.imshow(augmented_image)
plt.title('Augmented Image')
plt.show()
24.3.3. 数据增广的应用场景
- 数据量有限:当训练数据量较少时,数据增广可以有效增加数据量,提升模型性能。
- 类别不平衡:对于类别不平衡的数据集,可以通过数据增广增加少数类别的样本数量,改善模型对少数类别的识别能力。
- 提高泛化能力:数据增广可以增加数据的多样性,帮助模型学习到更丰富的特征,提高泛化能力。
24.3.4. 综合示例
以下是一个综合的图像增强与数据增广示例,展示了如何使用Albumentations库对图像进行多种变换,并保存增强后的图像。
import albumentations as A
from PIL import Image
import matplotlib.pyplot as plt
import os
# 读取图像
image = Image.open('image.jpg')
image = np.array(image)
# 定义综合变换
transform = A.Compose([
A.Rotate(limit=40, p=1),
A.RandomBrightnessContrast(p=0.5),
A.HorizontalFlip(p=0.5),
A.GaussianNoise(p=0.5),
A.RandomErasing(p=0.5)
])
# 应用变换
augmented_images = [transform(image=image)['image'] for _ in range(4)]
# 显示原图和增强图
plt.figure(figsize=(10, 5))
plt.subplot(2, 3, 1)
plt.imshow(image)
plt.title('Original Image')
for i in range(4):
plt.subplot(2, 3, i + 2)
plt.imshow(augmented_images[i])
plt.title(f'Augmented Image {i + 1}')
plt.show()
# 保存增强后的图像
os.makedirs('augmented_images', exist_ok=True)
for i, img in enumerate(augmented_images):
img = Image.fromarray(img)
img.save(f'augmented_images/augmented_image_{i + 1}.jpg')
24.3.5. 最佳实践
- 多样化变换:使用多种图像增强技术,以增加数据的多样性。
- 适度性:避免过度增强,导致数据失真或引入噪声。
- 一致性:确保增强后的数据与原始数据在分布上保持一致。
- 验证:在验证集和测试集上验证增强方法的效果,避免对模型性能产生负面影响。
24.3.6. 小结
图像增强与数据增广是提升计算机视觉模型性能的重要手段。通过对图像进行各种变换,生成新的训练样本,可以有效增加数据的多样性,帮助模型学习到更丰富的特征,从而提升模型的泛化能力和鲁棒性。Python提供了丰富的库和工具,如Albumentations、OpenCV等,可以简化图像增强与数据增广过程,提高工作效率。通过本章的学习,您将能够掌握图像增强与数据增广的关键步骤,并将其应用于AI模型的实战中,确保数据的高质量和多样性,从而提升模型的性能和可靠性。
24.4 实时视频分析与流媒体处理
实时视频分析与流媒体处理是计算机视觉领域的一个重要分支,涉及对视频流进行实时处理和分析,以实现各种应用,如视频监控、自动驾驶、虚拟现实等。本节将详细介绍实时视频分析与流媒体处理的关键技术和实现方法,并通过具体示例展示如何高效地进行实时视频分析。
24.4.1. 实时视频分析的基本流程
实时视频分析通常包括以下几个步骤:
1.视频捕捉:从摄像头或其他视频源获取视频流。
2.帧处理:对每一帧图像进行处理,如图像预处理、目标检测、跟踪等。
3.事件检测与响应:根据处理结果检测特定事件,并进行相应的响应,如报警、记录等。
4.结果展示与存储:将分析结果实时展示或存储,以便后续查询和分析。
24.4.2. 关键技术
24.4.2.1 视频捕捉
视频捕捉是指从摄像头或其他视频源获取视频流。常用的库和工具包括OpenCV、FFmpeg等。
示例:使用OpenCV进行视频捕捉
import cv2
# 打开默认摄像头
cap = cv2.VideoCapture(0)
while True:
ret, frame = cap.read()
if not ret:
break
cv2.imshow('Video', frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
24.4.2.2 帧处理
帧处理是指对每一帧图像进行各种计算机视觉任务,如图像预处理、目标检测、语义分割等。
示例:使用OpenCV进行图像预处理
import cv2
import numpy as np
# 读取图像
frame = cv2.imread('image.jpg')
# 转换为灰度图
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
# 高斯模糊
blurred = cv2.GaussianBlur(gray, (5, 5), 0)
# 边缘检测
edges = cv2.Canny(blurred, 50, 150)
# 显示结果
cv2.imshow('Edges', edges)
cv2.waitKey(0)
cv2.destroyAllWindows()
24.4.2.3 目标检测与跟踪
目标检测是指在视频帧中识别和定位特定目标,如人、车、物等。常用的目标检测算法包括YOLO、SSD、Faster R-CNN等。
示例:使用YOLOv5进行实时目标检测
import torch
import cv2
import time
# 加载预训练的YOLOv5模型
model = torch.hub.load('ultralytics/yolov5', 'yolov5s', pretrained=True)
# 打开摄像头
cap = cv2.VideoCapture(0)
while True:
ret, frame = cap.read()
if not ret:
break
# 进行目标检测
results = model(frame)
# 渲染检测结果
results.render()
cv2.imshow('Real-time Object Detection', np.squeeze(results.ims))
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
24.4.2.4 事件检测与响应
事件检测是指根据视频分析结果检测特定事件,如入侵检测、异常行为检测等。响应可以是报警、记录、触发其他系统等。
示例:简单的入侵检测
import cv2
import numpy as np
# 打开摄像头
cap = cv2.VideoCapture(0)
# 初始化背景减除器
backSub = cv2.createBackgroundSubtractorMOG2()
while True:
ret, frame = cap.read()
if not ret:
break
# 计算前景掩码
fgMask = backSub.apply(frame)
# 阈值处理
thresh = cv2.threshold(fgMask, 244, 255, cv2.THRESH_BINARY)[1]
thresh = cv2.erode(thresh, None, iterations=2)
thresh = cv2.dilate(thresh, None, iterations=2)
# 查找轮廓
contours, _ = cv2.findContours(thresh, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
for contour in contours:
if cv2.contourArea(contour) > 500:
# 绘制边界框
(x, y, w, h) = cv2.boundingRect(contour)
cv2.rectangle(frame, (x, y), (x + w, y + h), (0, 255, 0), 2)
# 显示结果
cv2.imshow('Intrusion Detection', frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
24.4.3. 流媒体处理
流媒体处理是指对实时视频流进行传输、存储和处理。常用的流媒体协议包括RTSP、RTMP、HLS等。
示例:使用OpenCV读取RTSP流
import cv2
# RTSP流地址
rtsp_url = 'rtsp://username:password@camera_ip:port/stream'
# 打开RTSP流
cap = cv2.VideoCapture(rtsp_url)
while True:
ret, frame = cap.read()
if not ret:
break
# 处理帧
cv2.imshow('RTSP Stream', frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
24.4.4. 性能优化
24.4.4.1 多线程与多进程
为了提高实时视频处理的效率,可以使用多线程或多进程技术,将视频捕捉、帧处理和结果显示等任务分配到不同的线程或进程中进行。
示例:使用多线程进行视频处理
import cv2
import threading
def video_capture(queue):
cap = cv2.VideoCapture(0)
while True:
ret, frame = cap.read()
if not ret:
break
queue.put(frame)
cap.release()
def video_processing(queue):
while True:
frame = queue.get()
# 处理帧
cv2.imshow('Processed Frame', frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# 创建队列
from queue import Queue
frame_queue = Queue(maxsize=10)
# 启动线程
capture_thread = threading.Thread(target=video_capture, args=(frame_queue,))
processing_thread = threading.Thread(target=video_processing, args=(frame_queue,))
capture_thread.start()
processing_thread.start()
capture_thread.join()
processing_thread.join()
24.4.4.2 GPU加速
利用GPU加速计算密集型任务,如深度学习模型的推理,可以显著提高处理速度。
示例:使用CUDA加速YOLOv5
import torch
import cv2
# 加载模型
model = torch.hub.load('ultralytics/yolov5', 'yolov5s', pretrained=True)
model.cuda()
# 打开摄像头
cap = cv2.VideoCapture(0)
while True:
ret, frame = cap.read()
if not ret:
break
# 转换为CUDA张量
img = [torch.from_numpy(frame).cuda()]
# 进行目标检测
results = model(img)
# 渲染检测结果
results.render()
cv2.imshow('Real-time Object Detection', np.squeeze(results.ims[0].cpu().numpy()))
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
24.4.5. 实时视频分析的应用场景
- 视频监控:实时监控场景,检测异常行为或事件。
- 自动驾驶:实时识别和跟踪道路上的车辆、行人等。
- 虚拟现实与增强现实:实时渲染虚拟元素,增强用户体验。
- 智能零售:实时分析顾客行为,优化店铺布局和商品陈列。
24.4.6. 小结
实时视频分析与流媒体处理是计算机视觉领域的重要应用方向。通过对视频流进行实时处理和分析,可以实现各种智能应用,如视频监控、自动驾驶等。Python提供了丰富的库和工具,如OpenCV、PyTorch、YOLOv5等,可以简化实时视频分析的实现过程,提高工作效率。通过本章的学习,您将能够掌握实时视频分析与流媒体处理的关键技术和实现方法,并将其应用于AI模型的实战中,实现各种智能应用。
24.5 深度学习架构优化与超参数调整
在计算机视觉任务中,深度学习架构优化与超参数调整是提升模型性能的关键步骤。合理的架构设计和超参数选择不仅能提高模型的预测能力,还能有效减少训练时间和资源消耗。以下将详细讲解深度学习架构优化的策略和超参数调整的方法,并通过具体示例展示如何进行优化。
24.5.1. 深度学习架构优化
24.5.1.1 模型选择
选择合适的模型架构是优化深度学习模型的第一步。常见的计算机视觉模型架构包括:
- 卷积神经网络(CNN):如LeNet、AlexNet、VGG、ResNet等,适用于图像分类、目标检测等任务。
- 残差网络(ResNet):通过引入残差块,解决了深层网络训练困难的问题。
- 密集连接网络(DenseNet):通过密集连接层,增强了特征的传递和复用。
- 轻量级网络:如MobileNet、EfficientNet、SqueezeNet等,适用于资源受限的设备。
示例:使用ResNet进行图像分类
import torch
import torch.nn as nn
import torchvision.models as models
# 加载预训练的ResNet模型
model = models.resnet50(pretrained=True)
# 修改最后的全连接层以适应目标任务
num_ftrs = model.fc.in_features
model.fc = nn.Linear(num_ftrs, 10) # 假设有10个类别
print(model)
24.5.1.2 模型剪枝
模型剪枝是指移除模型中不重要的参数或层,以减少模型大小和计算量,同时保持或略微降低模型性能。
示例:使用PyTorch进行模型剪枝
import torch
import torch.nn.utils.prune as prune
# 假设model是已经训练好的模型
model = models.resnet50(pretrained=True)
# 对卷积层的权重进行剪枝
for name, module in model.named_modules():
if isinstance(module, torch.nn.Conv2d):
prune.l1_unstructured(module, name='weight', amount=0.2)
print(model)
24.5.1.3 模型量化
模型量化是指将模型中的参数和激活值从高精度(如32位浮点数)转换为低精度(如8位整数),以减少内存占用和计算量。
示例:使用PyTorch进行模型量化
import torch
import torch.quantization
# 加载预训练的ResNet模型
model = models.resnet50(pretrained=True)
# 设置模型为量化感知训练模式
model.train()
# 添加量化模块
model = torch.quantization.prepare(model)
# 训练模型(量化感知训练)
# 转换为量化模型
model.eval()
model = torch.quantization.convert(model)
print(model)
24.5.1.4 知识蒸馏
知识蒸馏是指将一个大模型的“知识”迁移到一个小模型中,通过训练小模型来模仿大模型的输出,从而提高小模型的性能。
示例:使用知识蒸馏进行模型优化
import torch
import torch.nn as nn
import torch.optim as optim
# 定义教师模型和学生模型
teacher_model = models.resnet50(pretrained=True)
student_model = models.resnet18(pretrained=False)
# 修改最后的全连接层
num_ftrs = teacher_model.fc.in_features
teacher_model.fc = nn.Linear(num_ftrs, 10)
num_ftrs = student_model.fc.in_features
student_model.fc = nn.Linear(num_ftrs, 10)
# 定义损失函数
criterion = nn.KLDivLoss()
# 定义优化器
optimizer = optim.Adam(student_model.parameters(), lr=1e-4)
# 知识蒸馏训练过程
for epoch in range(num_epochs):
for inputs, labels in dataloader:
optimizer.zero_grad()
teacher_outputs = teacher_model(inputs)
student_outputs = student_model(inputs)
loss = criterion(student_outputs, teacher_outputs)
loss.backward()
optimizer.step()
24.5.2. 超参数调整
24.5.2.1 学习率(Learning Rate)
学习率是控制模型权重更新步长的参数。学习率过大可能导致模型无法收敛,过小则会导致训练速度过慢。
常用方法:
- 学习率调度器(Learning Rate Scheduler):如StepLR、ReduceLROnPlateau、ExponentialLR等。
- 学习率查找(Learning Rate Finder):通过实验找到最佳学习率。
示例:使用学习率调度器
import torch
import torch.optim as optim
from torch.optim.lr_scheduler import StepLR
# 定义优化器
optimizer = optim.Adam(model.parameters(), lr=1e-3)
# 定义学习率调度器
scheduler = StepLR(optimizer, step_size=7, gamma=0.1)
# 训练过程
for epoch in range(num_epochs):
train(model, dataloader)
scheduler.step()
24.5.2.2 批量大小(Batch Size)
批量大小影响模型的训练速度和内存消耗。较大的批量大小可以加快训练速度,但需要更多的内存。
建议:
- 根据硬件资源选择合适的批量大小。
- 使用梯度累积(Gradient Accumulation)模拟更大的批量大小。
示例:使用梯度累积
import torch
import torch.nn as nn
# 定义模型和损失函数
model = models.resnet50(pretrained=True)
criterion = nn.CrossEntropyLoss()
# 定义优化器
optimizer = optim.Adam(model.parameters(), lr=1e-3)
# 梯度累积参数
accumulation_steps = 4
# 训练过程
for epoch in range(num_epochs):
model.train()
optimizer.zero_grad()
for i, (inputs, labels) in enumerate(dataloader):
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
if (i + 1) % accumulation_steps == 0:
optimizer.step()
optimizer.zero_grad()
24.5.2.3 正则化参数
正则化参数(如权重衰减、L2正则化)用于防止过拟合并提高模型的泛化能力。
示例:设置权重衰减
import torch
import torch.optim as optim
# 定义优化器,设置权重衰减
optimizer = optim.Adam(model.parameters(), lr=1e-3, weight_decay=1e-4)
24.5.3. 综合示例
以下是一个综合的深度学习架构优化与超参数调整示例,展示了如何选择模型、进行模型剪枝和量化,并调整超参数。
import torch
import torch.nn as nn
import torch.optim as optim
from torch.optim.lr_scheduler import StepLR
import torchvision.models as models
# 1. 模型选择与修改
model = models.resnet50(pretrained=True)
num_ftrs = model.fc.in_features
model.fc = nn.Linear(num_ftrs, 10)
# 2. 模型剪枝
for name, module in model.named_modules():
if isinstance(module, nn.Conv2d):
prune.l1_unstructured(module, name='weight', amount=0.2)
# 3. 模型量化
model.train()
model = torch.quantization.prepare(model)
# 进行量化感知训练
# ...
model.eval()
model = torch.quantization.convert(model)
# 4. 超参数调整
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=1e-3, weight_decay=1e-4)
scheduler = StepLR(optimizer, step_size=7, gamma=0.1)
# 5. 训练过程
num_epochs = 25
for epoch in range(num_epochs):
model.train()
for inputs, labels in dataloader:
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
scheduler.step()
print(f'Epoch {epoch + 1}/{num_epochs}, Loss: {loss.item()}')
24.5.4. 小结
深度学习架构优化与超参数调整是提升计算机视觉模型性能的重要手段。通过合理的模型选择、剪枝、量化、知识蒸馏等优化策略,以及精细的超参数调整,可以显著提高模型的预测能力和泛化能力。Python及其相关库提供了丰富的工具和功能,可以大大简化优化过程,提高工作效率。通过本章的学习,您将能够掌握深度学习架构优化与超参数调整的关键步骤,并将其应用于AI模型的实战中,提升模型的性能和可靠性。
24.6 高级主题:生成对抗网络(GANs)与自监督学习
在计算机视觉领域,生成对抗网络(GANs)和自监督学习是近年来备受关注的高级主题。GANs通过生成逼真的图像,推动了图像生成、图像修复等任务的发展;而自监督学习则通过从未标注的数据中学习特征,展示了强大的表示学习能力。本节将详细介绍GANs和自监督学习的基本原理、应用场景以及实现方法,并通过具体示例展示如何应用这些技术。
24.6.1. 生成对抗网络(GANs)
24.6.1.1 GANs的基本原理
GANs由两个主要部分组成:
- 生成器(Generator):负责生成逼真的数据样本。
- 判别器(Discriminator):负责区分真实数据和生成器生成的数据。
两者通过对抗训练的方式进行博弈:生成器试图生成越来越逼真的数据以欺骗判别器,而判别器则不断提高辨别能力以区分真实数据和生成数据。最终,生成器能够生成与真实数据难以区分的样本。
24.6.1.2 GANs的应用场景
- 图像生成:生成逼真的图像,如人脸、风景等。
- 图像修复:修复图像中的缺失部分或损坏部分。
- 图像超分辨率:将低分辨率图像转换为高分辨率图像。
- 风格迁移:将一种图像风格迁移到另一种图像上。
示例:使用PyTorch实现简单的GAN
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
# 定义生成器
class Generator(nn.Module):
def __init__(self, input_dim=100, output_dim=1, input_size=32):
super(Generator, self).__init__()
self.model = nn.Sequential(
nn.Linear(input_dim, 256),
nn.ReLU(True),
nn.Linear(256, 512),
nn.ReLU(True),
nn.Linear(512, 1024),
nn.ReLU(True),
nn.Linear(1024, output_dim * input_size * input_size),
nn.Tanh()
)
def forward(self, x):
x = self.model(x)
x = x.view(x.size(0), 1, 32, 32)
return x
# 定义判别器
class Discriminator(nn.Module):
def __init__(self, input_dim=1, input_size=32):
super(Discriminator, self).__init__()
self.model = nn.Sequential(
nn.Linear(input_dim * input_size * input_size, 1024),
nn.LeakyReLU(0.2, inplace=True),
nn.Dropout(0.3),
nn.Linear(1024, 512),
nn.LeakyReLU(0.2, inplace=True),
nn.Dropout(0.3),
nn.Linear(512, 256),
nn.LeakyReLU(0.2, inplace=True),
nn.Dropout(0.3),
nn.Linear(256, 1),
nn.Sigmoid()
)
def forward(self, x):
x = x.view(x.size(0), -1)
x = self.model(x)
return x
# 初始化模型
generator = Generator()
discriminator = Discriminator()
# 定义损失函数和优化器
criterion = nn.BCELoss()
optimizer_G = optim.Adam(generator.parameters(), lr=0.0002)
optimizer_D = optim.Adam(discriminator.parameters(), lr=0.0002)
# 加载数据
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize([0.5], [0.5])
])
dataset = datasets.MNIST(root='./data', train=True, transform=transform, download=True)
dataloader = DataLoader(dataset, batch_size=64, shuffle=True)
# 训练过程
num_epochs = 50
for epoch in range(num_epochs):
for i, (real_images, _) in enumerate(dataloader):
# 训练判别器
optimizer_D.zero_grad()
real_labels = torch.ones(real_images.size(0), 1)
fake_labels = torch.zeros(real_images.size(0), 1)
outputs = discriminator(real_images)
d_loss_real = criterion(outputs, real_labels)
d_loss_real.backward()
z = torch.randn(real_images.size(0), 100)
fake_images = generator(z)
outputs = discriminator(fake_images.detach())
d_loss_fake = criterion(outputs, fake_labels)
d_loss_fake.backward()
d_loss = d_loss_real + d_loss_fake
optimizer_D.step()
# 训练生成器
optimizer_G.zero_grad()
z = torch.randn(real_images.size(0), 100)
fake_images = generator(z)
outputs = discriminator(fake_images)
g_loss = criterion(outputs, real_labels)
g_loss.backward()
optimizer_G.step()
print(f'Epoch [{epoch + 1}/{num_epochs}], D Loss: {d_loss.item()}, G Loss: {g_loss.item()}')
24.6.2. 自监督学习
24.6.2.1 自监督学习的基本原理
自监督学习是一种无需人工标注的机器学习方法,通过设计辅助任务(如预测图像旋转角度、掩码预测等),让模型从未标注的数据中学习有用的特征表示。
24.6.2.2 自监督学习的应用场景
- 无监督特征学习:从未标注数据中学习特征表示。
- 半监督学习:结合少量标注数据和大量未标注数据,提升模型性能。
- 迁移学习:将自监督学习得到的特征表示用于下游任务,如图像分类、目标检测等。
示例:使用SimCLR进行自监督学习
import torch
import torch.nn as nn
import torchvision
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
# 定义数据增强
transform = transforms.Compose([
transforms.RandomResizedCrop(32),
transforms.RandomHorizontalFlip(),
transforms.RandomApply([
transforms.ColorJitter(0.8, 0.8, 0.8, 0.2)
], p=0.8),
transforms.RandomGrayscale(p=0.2),
transforms.GaussianBlur(kernel_size=9),
transforms.ToTensor()
])
# 加载数据集
dataset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
dataloader = DataLoader(dataset, batch_size=256, shuffle=True, num_workers=4)
# 定义SimCLR模型
class SimCLR(nn.Module):
def __init__(self, base_model, projection_dim=128):
super(SimCLR, self).__init__()
self.base_model = base_model
self.projection = nn.Sequential(
nn.Linear(512, 512),
nn.ReLU(),
nn.Linear(512, projection_dim)
)
def forward(self, x):
h = self.base_model(x)
z = self.projection(h)
return h, z
# 加载预训练的ResNet-18模型
base_model = torchvision.models.resnet18(pretrained=False)
base_model.fc = nn.Identity()
model = SimCLR(base_model)
# 定义损失函数(NT-Xent)
class NTXentLoss(nn.Module):
def __init__(self, temperature=0.5):
super(NTXentLoss, self).__init__()
self.temperature = temperature
self.criterion = nn.CrossEntropyLoss(reduction='none')
def forward(self, z1, z2):
z = torch.cat([z1, z2], dim=0)
sim_matrix = torch.matmul(z, z.T) / self.temperature
sim_matrix = torch.exp(sim_matrix - torch.max(sim_matrix, dim=1, keepdim=True)[0])
mask = torch.eye(z.size(0), dtype=torch.bool)
sim_matrix = sim_matrix.masked_fill(mask, 0)
numerator = torch.exp(torch.sum(z1 * z2, dim=1) / self.temperature)
denominator = torch.sum(sim_matrix, dim=1)
loss = -torch.log(numerator / denominator)
return torch.mean(loss)
# 定义优化器
optimizer = optim.Adam(model.parameters(), lr=1e-3)
# 训练过程
for epoch in range(10):
for batch in dataloader:
images = batch[0]
# 生成两个增强视图
images1 = images
images2 = transforms.RandomHorizontalFlip()(images)
h1, z1 = model(images1)
h2, z2 = model(images2)
loss = NTXentLoss()(z1, z2)
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(f'Epoch [{epoch + 1}/10], Loss: {loss.item()}')
24.6.3. 综合示例
以下是一个综合的GAN与自监督学习示例,展示了如何结合两种技术进行图像生成和特征学习。
import torch
import torch.nn as nn
import torchvision
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
# 1. 定义生成器和判别器
class Generator(nn.Module):
def __init__(self, input_dim=100, output_dim=3, input_size=32):
super(Generator, self).__init__()
self.model = nn.Sequential(
nn.Linear(input_dim, 256),
nn.ReLU(True),
nn.Linear(256, 512),
nn.ReLU(True),
nn.Linear(512, 1024),
nn.ReLU(True),
nn.Linear(1024, output_dim * input_size * input_size),
nn.Tanh()
)
def forward(self, x):
x = self.model(x)
x = x.view(x.size(0), 3, 32, 32)
return x
class Discriminator(nn.Module):
def __init__(self, input_dim=3, input_size=32):
super(Discriminator, self).__init__()
self.model = nn.Sequential(
nn.Linear(input_dim * input_size * input_size, 1024),
nn.LeakyReLU(0.2, inplace=True),
nn.Dropout(0.3),
nn.Linear(1024, 512),
nn.LeakyReLU(0.2, inplace=True),
nn.Dropout(0.3),
nn.Linear(512, 256),
nn.LeakyReLU(0.2, inplace=True),
nn.Dropout(0.3),
nn.Linear(256, 1),
nn.Sigmoid()
)
def forward(self, x):
x = x.view(x.size(0), -1)
x = self.model(x)
return x
# 2. 初始化模型
generator = Generator()
discriminator = Discriminator()
# 3. 定义损失函数和优化器
criterion = nn.BCELoss()
optimizer_G = optim.Adam(generator.parameters(), lr=0.0002)
optimizer_D = optim.Adam(discriminator.parameters(), lr=0.0002)
# 4. 加载数据
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
])
dataset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
dataloader = DataLoader(dataset, batch_size=64, shuffle=True, num_workers=4)
# 5. 自监督学习辅助任务(示例:图像旋转预测)
class RotationPredictor(nn.Module):
def __init__(self, base_model):
super(RotationPredictor, self).__init__()
self.base_model = base_model
self.classifier = nn.Linear(512, 4)
def forward(self, x):
h = self.base_model(x)
logits = self.classifier(h)
return logits
# 加载预训练的ResNet-18模型
base_model = torchvision.models.resnet18(pretrained=False)
base_model.fc = nn.Identity()
rotation_predictor = RotationPredictor(base_model)
# 6. 定义优化器
optimizer_rotation = optim.Adam(rotation_predictor.parameters(), lr=1e-3)
# 7. 训练过程
for epoch in range(10):
for batch in dataloader:
images = batch[0]
# 生成两个增强视图
images1 = images
images2 = transforms.RandomHorizontalFlip()(images)
# 自监督学习
h1, z1 = model(images1)
h2, z2 = model(images2)
loss = NTXentLoss()(z1, z2)
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 旋转预测任务
rotated_images = transforms.RandomRotation(degrees=90)(images)
rotation_labels = torch.tensor([0, 1, 2, 3], dtype=torch.long)
logits = rotation_predictor(rotated_images)
rotation_loss = nn.CrossEntropyLoss()(logits, rotation_labels)
optimizer_rotation.zero_grad()
rotation_loss.backward()
optimizer_rotation.step()
print(f'Epoch [{epoch + 1}/10], Loss: {loss.item()}, Rotation Loss: {rotation_loss.item()}')
24.6.4. 小结
生成对抗网络(GANs)和自监督学习是计算机视觉领域的前沿技术。GANs通过生成逼真的图像,推动了图像生成、图像修复等任务的发展;而自监督学习则通过从未标注的数据中学习特征,展示了强大的表示学习能力。通过合理的应用这些技术,可以显著提升计算机视觉模型的性能和应用范围。通过本章的学习,您将能够掌握GANs和自监督学习的基本原理、应用场景和实现方法,并将其应用于AI模型的实战中,实现更复杂的计算机视觉任务。
第二十五章:自然语言处理(NLP)实战
- 从BERT到GPT:如何处理文本并生成内容
- 文本分类与情感分析
- 命名实体识别(NER)与关系抽取
- 序列标注任务:POS Tagging与Dependency Parsing
- 对话系统与聊天机器人开发
- 机器翻译与跨语言处理
- 实战案例分析:NLP项目从数据准备到部署上线
25.1 从BERT到GPT:如何处理文本并生成内容
欢迎来到“自然语言处理”的魔法学院!在人工智能的领域中,自然语言处理(NLP)就像是一位能够理解和生成人类语言的“语言魔法师”。通过NLP技术,计算机可以执行各种语言相关的任务,如文本分类、情感分析、机器翻译、文本生成等。今天,我们将深入探讨从BERT到GPT等先进的NLP模型,看看它们如何处理文本并生成内容。
25.1.1 自然语言处理(NLP)概述
自然语言处理是人工智能和语言学的一个交叉领域,旨在使计算机能够理解、解释和生成人类语言。NLP的任务包括但不限于:
- 文本分类:将文本分配到预定义的类别,如垃圾邮件检测、新闻分类等。
- 情感分析:分析文本中的情感倾向,如正面、负面或中性。
- 命名实体识别(NER):识别文本中的实体,如人名、地名、组织名等。
- 机器翻译:将文本从一种语言翻译成另一种语言。
- 文本生成:生成自然语言文本,如文章、对话、诗歌等。
25.1.2 BERT:双向编码器表示模型
BERT(Bidirectional Encoder Representations from Transformers)是由Google开发的预训练语言模型,基于Transformer架构。BERT通过双向处理输入文本,能够理解上下文中的每个词。
25.1.2.1 BERT的特点
1. 双向性:
- BERT同时考虑上下文中的前后文信息,而不是像传统的语言模型那样只考虑前面的词。
- 比喻:就像一个魔法师同时看到咒语的开始和结束,从而更好地理解整个咒语。
2. 预训练与微调:
- BERT首先在大规模文本语料上进行预训练,然后在特定任务的数据集上进行微调。
- 示例:
- 预训练:使用大量的未标注数据进行训练,学习语言的一般特征。
- 微调:在特定任务(如情感分析、文本分类)上使用标注数据进行训练。
3. 掩码语言模型(MLM):
- 在预训练过程中,随机掩盖输入文本中的部分词,并训练模型预测被掩盖的词。
25.1.2.2 使用BERT进行文本分类
示例:使用Hugging Face Transformers库进行文本分类
from transformers import BertTokenizer, TFBertForSequenceClassification
import tensorflow as tf
# 加载预训练的BERT tokenizer和模型
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = TFBertForSequenceClassification.from_pretrained('bert-base-uncased', num_labels=2)
# 准备数据
texts = ["I love this movie!", "This is the worst thing ever."]
labels = [1, 0]
# 编码输入
encodings = tokenizer(texts, truncation=True, padding=True, return_tensors='tf')
# 创建数据集
dataset = tf.data.Dataset.from_tensor_slices((
dict(encodings),
labels
)).shuffle(100).batch(32)
# 编译模型
model.compile(optimizer='adam',
loss=model.compute_loss,
metrics=['accuracy'])
# 训练模型
model.fit(dataset, epochs=3)
25.1.3 GPT:生成式预训练变换器
GPT(Generative Pre-trained Transformer)是由OpenAI开发的生成式预训练语言模型,基于Transformer架构。GPT专注于生成自然语言文本,能够生成连贯且语法正确的句子。
25.1.3.1 GPT的特点
1. 生成能力:
- GPT能够生成自然语言文本,适用于文本生成任务,如对话生成、文章生成等。
- 比喻:就像一个魔法师能够创造出新的咒语,而不是仅仅理解现有的咒语。
2. 单向性:
- GPT是单向的,只考虑前面的词来预测下一个词。
- 注意:虽然GPT是单向的,但通过多层Transformer结构,它仍然能够捕捉到一定程度的上下文信息。
3. 预训练与微调:
- GPT首先在大规模文本语料上进行预训练,然后在特定任务的数据集上进行微调。
25.1.3.2 使用GPT进行文本生成
示例:使用Hugging Face Transformers库进行文本生成
from transformers import GPT2Tokenizer, GPT2LMHeadModel
# 加载预训练的GPT-2 tokenizer和模型
tokenizer = GPT2Tokenizer.from_pretrained('gpt-2')
model = GPT2LMHeadModel.from_pretrained('gpt-2')
# 准备输入文本
input_text = "Once upon a time"
# 编码输入
input_ids = tokenizer.encode(input_text, return_tensors='pt')
# 生成文本
outputs = model.generate(input_ids, max_length=50, num_return_sequences=1, no_repeat_ngram_size=2, early_stopping=True)
# 解码输出
generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(generated_text)
25.1.4 小结:自然语言处理的魔法
通过本节,你已经学习了从BERT到GPT的先进NLP模型,就像掌握了“语言魔法”的高级技巧。BERT和GPT是自然语言处理领域的里程碑,它们为计算机理解和生成人类语言提供了强大的工具。希望你能灵活运用这些“语言魔法”,让你的Python程序能够处理和生成自然语言文本,为编写更强大的NLP应用打下坚实的基础。
25.2 文本分类与情感分析
文本分类和情感分析是自然语言处理(NLP)领域中的两个核心任务,广泛应用于各种实际场景,如新闻分类、垃圾邮件检测、产品评论分析等。文本分类旨在将文本分配到预定义的类别中,而情感分析则是文本分类的一种特定应用,旨在识别文本中表达的情感或态度(如正面、负面、中性)。以下将详细介绍文本分类与情感分析的关键技术、实现方法以及最佳实践,并通过具体示例展示如何进行有效的文本分类与情感分析。
25.2.1. 文本分类与情感分析的基本概念
25.2.1.1 文本分类
文本分类是将文本数据分配到预定义的类别或标签中的过程。常见的文本分类任务包括:
- 新闻分类:将新闻文章分类为不同的主题,如体育、政治、科技等。
- 垃圾邮件检测:将电子邮件分类为垃圾邮件或非垃圾邮件。
- 主题分类:将文档分类为不同的主题类别。
25.2.1.2 情感分析
情感分析是文本分类的一种特定应用,旨在识别和提取文本中表达的情感或态度。常见的情感分析任务包括:
- 二元分类:将情感分为正面和负面。
- 多元分类:将情感分为正面、负面和中性。
- 细粒度情感分析:识别更复杂的情感,如快乐、悲伤、愤怒、惊讶等。
25.2.2. 文本分类与情感分析的技术方法
25.2.2.1 传统机器学习方法
传统的文本分类方法通常包括以下几个步骤:
1.文本预处理:包括分词、去停用词、词形还原等。
2.特征提取:将文本转换为数值特征,如词袋模型(Bag of Words)、TF-IDF等。
3.模型训练:使用机器学习算法(如朴素贝叶斯、支持向量机(SVM)、逻辑回归等)进行训练。
4.模型评估:使用评估指标(如准确率、精确率、召回率、F1-score等)评估模型性能。
示例:使用Scikit-learn进行文本分类
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn.metrics import classification_report
# 读取数据
df = pd.read_csv('text_data.csv')
# 划分特征和标签
X = df['text']
y = df['label']
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 初始化TF-IDF向量化器
vectorizer = TfidfVectorizer(max_features=5000)
# 特征提取
X_train_vect = vectorizer.fit_transform(X_train)
X_test_vect = vectorizer.transform(X_test)
# 初始化模型
model = MultinomialNB()
# 训练模型
model.fit(X_train_vect, y_train)
# 预测
y_pred = model.predict(X_test_vect)
# 评估
print(classification_report(y_test, y_pred))
25.2.2.2 深度学习方法
深度学习方法,特别是基于预训练语言模型的方法,如BERT、RoBERTa、GPT等,已经成为文本分类和情感分析的主流方法。这些模型能够捕捉到文本中的复杂语义关系和上下文信息,从而显著提升分类性能。
示例:使用BERT进行文本分类
import pandas as pd
from transformers import BertTokenizer, BertForSequenceClassification, Trainer, TrainingArguments
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, precision_recall_fscore_support
# 读取数据
df = pd.read_csv('text_data.csv')
# 划分特征和标签
X = df['text']
y = df['label']
# 划分训练集和验证集
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2, stratify=y, random_state=42)
# 加载tokenizer
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
# 编码文本
train_encodings = tokenizer(X_train.tolist(), truncation=True, padding=True, max_length=128)
val_encodings = tokenizer(X_val.tolist(), truncation=True, padding=True, max_length=128)
# 创建Dataset
import torch
from torch.utils.data import TensorDataset, DataLoader
train_dataset = TensorDataset(torch.tensor(train_encodings['input_ids']),
torch.tensor(train_encodings['attention_mask']),
torch.tensor(y_train.tolist()))
val_dataset = TensorDataset(torch.tensor(val_encodings['input_ids']),
torch.tensor(val_encodings['attention_mask']),
torch.tensor(y_val.tolist()))
# 加载预训练的BERT模型
model = BertForSequenceClassification.from_pretrained('bert-base-uncased', num_labels=2)
# 定义训练参数
training_args = TrainingArguments(
output_dir='./results',
num_train_epochs=3,
per_device_train_batch_size=16,
per_device_eval_batch_size=32,
evaluation_strategy='epoch',
logging_dir='./logs',
)
# 定义Trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=val_dataset,
compute_metrics=lambda preds: {
'accuracy': accuracy_score(y_val, preds[0].argmax(axis=1)),
'precision', precision_recall_fscore_support(y_val, preds[0].argmax(axis=1), average='weighted')[:3]
}
)
# 训练模型
trainer.train()
# 评估模型
results = trainer.evaluate()
print(results)
25.2.3. 最佳实践
- 数据预处理:确保对文本进行充分的预处理,包括分词、去停用词、词形还原等。
- 特征选择与提取:选择合适的特征提取方法,如TF-IDF、BERT等,以捕捉文本的语义信息。
- 模型选择:根据任务需求选择合适的模型。传统机器学习方法适用于简单任务,而深度学习方法则适用于复杂任务。
- 超参数调优:通过网格搜索、随机搜索等方法,对模型的超参数进行调优,以获得最佳性能。
- 评估指标:综合使用多种评估指标,如准确率、精确率、召回率、F1-score等,全面评估模型性能。
- 数据增强:通过数据增强技术,如同义词替换、随机插入等,增加数据多样性,提升模型泛化能力。
25.2.4. 综合示例
以下是一个综合的文本分类与情感分析示例,展示了如何使用BERT进行情感分析,并进行模型训练和评估。
import pandas as pd
from transformers import BertTokenizer, BertForSequenceClassification, Trainer, TrainingArguments
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, precision_recall_fscore_support
# 1. 数据加载与预处理
df = pd.read_csv('sentiment_data.csv')
X = df['text']
y = df['sentiment']
# 划分训练集和验证集
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2, stratify=y, random_state=42)
# 加载tokenizer
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
# 编码文本
train_encodings = tokenizer(X_train.tolist(), truncation=True, padding=True, max_length=128)
val_encodings = tokenizer(X_val.tolist(), truncation=True, padding=True, max_length=128)
# 创建Dataset
train_dataset = TensorDataset(torch.tensor(train_encodings['input_ids']),
torch.tensor(train_encodings['attention_mask']),
torch.tensor(y_train.tolist()))
val_dataset = TensorDataset(torch.tensor(val_encodings['input_ids']),
torch.tensor(val_encodings['attention_mask']),
torch.tensor(y_val.tolist()))
# 2. 模型训练与评估
model = BertForSequenceClassification.from_pretrained('bert-base-uncased', num_labels=3)
# 定义训练参数
training_args = TrainingArguments(
output_dir='./results',
num_train_epochs=5,
per_device_train_batch_size=16,
per_device_eval_batch_size=32,
evaluation_strategy='epoch',
logging_dir='./logs',
)
# 定义Trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=val_dataset,
compute_metrics=lambda preds: {
'accuracy': accuracy_score(y_val, preds[0].argmax(axis=1)),
'precision', precision_recall_fscore_support(y_val, preds[0].argmax(axis=1), average='weighted')[:3]
}
)
# 训练模型
trainer.train()
# 评估模型
results = trainer.evaluate()
print(results)
25.2.5. 小结
文本分类与情感分析是NLP领域中的重要任务,通过合理的预处理、特征提取和模型选择,可以有效提升分类性能。Python及其相关库提供了丰富的工具和功能,可以大大简化文本分类与情感分析的实现过程,提高工作效率。通过本章的学习,您将能够掌握文本分类与情感分析的关键技术和实现方法,并将其应用于AI模型的实战中,实现各种智能应用。
25.3 命名实体识别(NER)与关系抽取
命名实体识别(Named Entity Recognition,NER)和关系抽取(Relation Extraction)是自然语言处理(NLP)中的两个重要任务,广泛应用于信息抽取、知识图谱构建、智能问答系统等领域。命名实体识别旨在识别文本中的实体,如人名、地名、组织机构名等;而关系抽取则旨在识别实体之间的关系,如“某人”就某公司”或“某产品由某公司生产”等。以下将详细介绍NER与关系抽取的关键技术、实现方法以及最佳实践,并通过具体示例展示如何进行有效的NER与关系抽取。
25.3.1. 命名实体识别(NER)
25.3.1.1 NER的基本概念
命名实体识别(NER)是指识别文本中具有特定意义的实体,并将其分类到预定义的类别中。常见的实体类别包括:
- 人名(Person):如“张三”、“李四”。
- 地名(Location):如“北京”、“上海”。
- 组织机构名(Organization):如“阿里巴巴”、“腾讯”。
- 时间表达式(Time):如“2023年10月”、“明天”。
- 数字表达式(Number):如“100万”、“5%”。
25.3.1.2 NER的技术方法
25.3.1.2.1 基于规则的方法
基于规则的方法通过人工编写规则来识别实体。例如,使用正则表达式匹配特定的模式。
优点:
- 实现简单。
- 对于特定领域和特定模式效果较好。
缺点:
- 难以覆盖所有情况。
- 维护成本高。
示例:使用正则表达式进行简单的NER
import re
text = "张三在北京的阿里巴巴公司工作。"
# 定义人名、地名、组织机构名的正则表达式
patterns = {
'PERSON': r'张三|李四|王五',
'LOCATION': r'北京|上海|广州',
'ORGANIZATION': r'阿里巴巴|腾讯|百度'
}
# 识别实体
entities = {}
for label, pattern in patterns.items():
entities[label] = re.findall(pattern, text)
print(entities)
25.3.1.2.2 基于机器学习的方法
基于机器学习的方法使用标注数据训练分类器来识别实体。常用的机器学习算法包括:
- 条件随机场(CRF)
- 支持向量机(SVM)
- 随机森林(Random Forest)
优点:
- 可以处理复杂的上下文信息。
- 泛化能力较强。
缺点:
- 需要大量标注数据。
- 特征工程较为复杂。
示例:使用spaCy进行NER
import spacy
# 加载预训练的spaCy模型
nlp = spacy.load('en_core_web_sm')
# 文本
text = "Barack Obama was born in Hawaii."
# 处理文本
doc = nlp(text)
# 提取实体
for ent in doc.ents:
print(ent.text, ent.label_)
25.3.1.2.3 基于深度学习的方法
基于深度学习的方法,特别是基于预训练语言模型的方法,如BERT、RoBERTa等,已经成为NER的主流方法。这些模型能够捕捉到文本中的复杂语义关系和上下文信息,从而显著提升NER性能。
示例:使用HuggingFace的BERT进行NER
from transformers import BertTokenizer, BertForTokenClassification, pipeline
# 加载预训练的BERT模型和tokenizer
model_name = 'dbmdz/bert-large-cased-finetuned-conll03-english'
tokenizer = BertTokenizer.from_pretrained(model_name)
model = BertForTokenClassification.from_pretrained(model_name)
# 初始化NER管道
nlp = pipeline("ner", model=model, tokenizer=tokenizer)
# 文本
text = "Barack Obama was born in Hawaii."
# 进行NER
entities = nlp(text)
print(entities)
25.3.2. 关系抽取
25.3.2.1 关系抽取的基本概念
关系抽取是指识别文本中实体之间的关系,并将其分类到预定义的类别中。常见的关系类别包括:
- 雇佣关系(Employment):如“张三在阿里巴巴工作”。
- 出生地关系(Birthplace):如“张三出生在北京”。
- 产品关系(Product):如“iPhone由苹果公司生产”。
25.3.2.2 关系抽取的技术方法
25.3.2.2.1 基于规则的方法
基于规则的方法通过人工编写规则来识别关系。例如,使用正则表达式匹配特定的模式。
优点:
- 实现简单。
- 对于特定领域和特定模式效果较好。
缺点:
- 难以覆盖所有情况。
- 维护成本高。
示例:使用正则表达式进行简单的关系抽取
import re
text = "张三在北京的阿里巴巴公司工作。"
# 定义关系模式
pattern = r'(?P<person>张三|李四|王五)在北京的(?P<organization>阿里巴巴|腾讯|百度)公司工作'
# 识别关系
match = re.search(pattern, text)
if match:
person = match.group('person')
organization = match.group('organization')
print(f"{person} 在 {organization} 工作")
25.3.2.2.2 基于机器学习的方法
基于机器学习的方法使用标注数据训练分类器来识别关系。常用的机器学习算法包括:
- 支持向量机(SVM)
- 随机森林(Random Forest)
- 条件随机场(CRF)
优点:
- 可以处理复杂的上下文信息。
- 泛化能力较强。
缺点:
- 需要大量标注数据。
- 特征工程较为复杂。
25.3.2.2.3 基于深度学习的方法
基于深度学习的方法,特别是基于预训练语言模型的方法,如BERT、RoBERTa等,已经成为关系抽取的主流方法。这些模型能够捕捉到文本中的复杂语义关系和上下文信息,从而显著提升关系抽取性能。
示例:使用HuggingFace的BERT进行关系抽取
from transformers import BertTokenizer, BertForSequenceClassification, pipeline
# 加载预训练的BERT模型和tokenizer
model_name = 'bert-base-cased'
tokenizer = BertTokenizer.from_pretrained(model_name)
model = BertForSequenceClassification.from_pretrained('dbmdz/bert-large-cased-finetuned-conll03-english')
# 初始化关系抽取管道
nlp = pipeline("text-classification", model=model, tokenizer=tokenizer)
# 文本
text = "张三在北京的阿里巴巴公司工作。"
# 进行关系抽取
relations = nlp(text)
print(relations)
25.3.3. 最佳实践
- 数据标注:高质量的标注数据是NER和关系抽取成功的关键。确保标注的一致性和准确性。
- 数据增强:通过数据增强技术,如同义词替换、随机插入等,增加数据多样性,提升模型泛化能力。
- 模型选择:根据任务需求选择合适的模型。传统机器学习方法适用于简单任务,而深度学习方法则适用于复杂任务。
- 超参数调优:通过网格搜索、随机搜索等方法,对模型的超参数进行调优,以获得最佳性能。
- 评估指标:综合使用多种评估指标,如准确率、精确率、召回率、F1-score等,全面评估模型性能。
- 领域适应:根据具体应用领域的特点,调整模型和特征,以适应特定领域的需求。
25.3.4. 综合示例
以下是一个综合的NER与关系抽取示例,展示了如何使用spaCy进行NER,并使用规则方法进行简单的关系抽取。
import spacy
import re
# 加载预训练的spaCy模型
nlp = spacy.load('en_core_web_sm')
# 文本
text = "张三在北京的阿里巴巴公司工作。"
# 进行NER
doc = nlp(text)
# 提取实体
entities = {}
for ent in doc.ents:
entities[ent.label_] = ent.text
print("识别的实体:", entities)
# 定义关系模式
pattern = r'(?P<person>张三|李四|王五)在北京的(?P<organization>阿里巴巴|腾讯|百度)公司工作'
# 识别关系
match = re.search(pattern, text)
if match:
person = match.group('person')
organization = match.group('organization')
print(f"{person} 在 {organization} 工作")
25.3.5. 小结
命名实体识别(NER)和关系抽取是NLP领域中的重要任务,通过合理的预处理、特征提取和模型选择,可以有效提升识别和抽取性能。Python及其相关库提供了丰富的工具和功能,可以大大简化NER与关系抽取的实现过程,提高工作效率。通过本章的学习,您将能够掌握NER与关系抽取的关键技术和实现方法,并将其应用于AI模型的实战中,实现各种智能应用。
25.4 序列标注任务:词性标注(POS Tagging)与依存句法分析(Dependency Parsing)
序列标注任务是自然语言处理(NLP)中的重要组成部分,主要包括词性标注(Part-of-Speech Tagging,POS Tagging)和依存句法分析(Dependency Parsing)。词性标注旨在为文本中的每个词语分配一个词性标签(如名词、动词、形容词等),而依存句法分析则旨在分析句子中词语之间的语法关系。以下将详细介绍序列标注任务的关键技术、实现方法以及最佳实践,并通过具体示例展示如何进行有效的词性标注与依存句法分析。
25.4.1. 词性标注(POS Tagging)
25.4.1.1 POS Tagging的基本概念
词性标注(POS Tagging)是给文本中的每个词语分配一个词性标签的过程。常见的词性标签包括:
- 名词(Noun, N):表示人、地点、事物等,如“苹果”、“北京”。
- 动词(Verb, V):表示动作或状态,如“吃”、“跑”。
- 形容词(Adjective, ADJ):描述名词的性质或特征,如“美丽的”、“快速的”。
- 副词(Adverb, ADV):描述动词、形容词或其他副词的程度或方式,如“非常”、“快速地”。
- 介词(Preposition, PREP):表示名词与其他词语之间的关系,如“在”、“从”。
25.4.1.2 POS Tagging的技术方法
25.4.1.2.1 基于规则的方法
基于规则的方法通过人工编写规则来标注词性。例如,使用正则表达式匹配特定的词性模式。
优点:
- 实现简单。
- 对于特定领域和特定模式效果较好。
缺点:
- 难以覆盖所有语言现象。
- 维护成本高。
示例:使用正则表达式进行简单的POS Tagging
import re
text = "美丽的苹果在北京非常受欢迎。"
# 定义词性模式
patterns = {
'ADJ': r'美丽的|快速的',
'NOUN': r'苹果|北京|受欢迎',
'ADV': r'非常|快速地',
'VERB': r'欢迎|吃|跑'
}
# 标注词性
pos_tags = []
for word in text:
for pos, pattern in patterns.items():
if re.match(pattern, word):
pos_tags.append((word, pos))
break
print(pos_tags)
25.4.1.2.2 基于机器学习的方法
基于机器学习的方法使用标注数据训练分类器来标注词性。常用的机器学习算法包括:
- 隐马尔可夫模型(HMM)
- 条件随机场(CRF)
- 支持向量机(SVM)
优点:
- 可以处理复杂的上下文信息。
- 泛化能力较强。
缺点:
- 需要大量标注数据。
- 特征工程较为复杂。
25.4.1.2.3 基于深度学习的方法
基于深度学习的方法,特别是基于预训练语言模型的方法,如BERT、RoBERTa等,已经成为POS Tagging的主流方法。这些模型能够捕捉到文本中的复杂语义关系和上下文信息,从而显著提升词性标注性能。
示例:使用spaCy进行POS Tagging
import spacy
# 加载预训练的spaCy模型
nlp = spacy.load('en_core_web_sm')
# 文本
text = "Beautiful apples are very popular in Beijing."
# 处理文本
doc = nlp(text)
# 提取词性标签
for token in doc:
print(token.text, token.pos_)
示例:使用HuggingFace的BERT进行POS Tagging
from transformers import BertTokenizer, BertForTokenClassification, pipeline
# 加载预训练的BERT模型和tokenizer
model_name = 'vblagoje/bert-english-uncased-finetuned-pos'
tokenizer = BertTokenizer.from_pretrained(model_name)
model = BertForTokenClassification.from_pretrained(model_name)
# 初始化POS Tagging管道
nlp = pipeline("ner", model=model, tokenizer=tokenizer)
# 文本
text = "Beautiful apples are very popular in Beijing."
# 进行POS Tagging
pos_tags = nlp(text)
print(pos_tags)
25.4.2. 依存句法分析(Dependency Parsing)
25.4.2.1 Dependency Parsing的基本概念
依存句法分析(Dependency Parsing)是分析句子中词语之间的语法关系,并构建依存句法树的过程。依存句法树展示了词语之间的主谓关系、动宾关系、修饰关系等。
25.4.2.2 Dependency Parsing的技术方法
25.4.2.2.1 基于转移的方法
基于转移的方法通过一系列的转移操作构建依存句法树。常用的方法包括:
- Arc-Standard
- Arc-Eager
优点:
- 实现简单。
- 效率较高。
缺点:
- 对长距离依赖处理能力较弱。
25.4.2.2.2 基于图的方法
基于图的方法将依存句法分析视为图中的最短路径问题。常用的方法包括:
- Maximum Spanning Tree (MST)
- Graph-Based Parsing
优点:
- 对长距离依赖处理能力较强。
- 可以处理更复杂的语法结构。
25.4.2.2.3 基于深度学习的方法
基于深度学习的方法,特别是基于预训练语言模型的方法,如BERT、RoBERTa等,已经成为依存句法分析的主流方法。这些模型能够捕捉到文本中的复杂语义关系和上下文信息,从而显著提升依存句法分析的性能。
示例:使用spaCy进行依存句法分析
import spacy
# 加载预训练的spaCy模型
nlp = spacy.load('en_core_web_sm')
# 文本
text = "Beautiful apples are very popular in Beijing."
# 处理文本
doc = nlp(text)
# 提取依存句法关系
for token in doc:
print(f'{token.text} <--{token.dep_}-- {token.head.text}')
示例:使用Stanford NLP进行依存句法分析
from stanfordnlp import StanfordCoreNLP
# 初始化Stanford NLP
nlp = StanfordCoreNLP('http://localhost:9000')
# 文本
text = "Beautiful apples are very popular in Beijing."
# 进行依存句法分析
annotation = nlp.annotate(text, properties={
'annotators': 'depparse',
'outputFormat': 'json'
})
# 提取依存句法关系
for sentence in annotation['sentences']:
for dep in sentence['basicDependencies']:
print(f'{dep["governorGloss"]} <--{dep["dep"]}-- {dep["dependentGloss"]}')
25.4.3. 最佳实践
- 数据标注:高质量的标注数据是序列标注任务成功的关键。确保标注的一致性和准确性。
- 数据增强:通过数据增强技术,如同义词替换、随机插入等,增加数据多样性,提升模型泛化能力。
- 模型选择:根据任务需求选择合适的模型。传统机器学习方法适用于简单任务,而深度学习方法则适用于复杂任务。
- 超参数调优:通过网格搜索、随机搜索等方法,对模型的超参数进行调优,以获得最佳性能。
- 评估指标:综合使用多种评估指标,如准确率、精确率、召回率、F1-score等,全面评估模型性能。
- 领域适应:根据具体应用领域的特点,调整模型和特征,以适应特定领域的需求。
25.4.4. 综合示例
以下是一个综合的词性标注与依存句法分析示例,展示了如何使用spaCy进行词性标注和依存句法分析。
import spacy
# 加载预训练的spaCy模型
nlp = spacy.load('en_core_web_sm')
# 文本
text = "Beautiful apples are very popular in Beijing."
# 处理文本
doc = nlp(text)
# 词性标注
print("词性标注结果:")
for token in doc:
print(f'{token.text}\t{token.pos_}')
# 依存句法分析
print("\n依存句法分析结果:")
for token in doc:
print(f'{token.text} <--{token.dep_}-- {token.head.text}')
输出结果:
词性标注结果:
Beautiful ADJ
apples NOUN
are AUX
very ADV
popular ADJ
in ADP
Beijing PROPN
. PUNCT
依存句法分析结果:
Beautiful <--amod-- apples
apples <--nsubj-- are
are <--ROOT-- are
very <--advmod-- popular
popular <--acomp-- are
in <--prep-- popular
Beijing <--pobj-- in
. <--punct-- are
25.4.5. 小结
序列标注任务,如词性标注和依存句法分析,是NLP领域中的重要组成部分。通过合理的预处理、特征提取和模型选择,可以有效提升序列标注的性能。Python及其相关库提供了丰富的工具和功能,可以大大简化序列标注的实现过程,提高工作效率。通过本章的学习,您将能够掌握序列标注任务的关键技术和实现方法,并将其应用于AI模型的实战中,实现各种智能应用。
25.5 对话系统与聊天机器人开发
对话系统和聊天机器人是自然语言处理(NLP)领域的重要应用,旨在通过自然语言与用户进行交互,提供信息查询、任务执行、情感陪伴等服务。随着人工智能技术的进步,对话系统和聊天机器人在各个行业中的应用越来越广泛,如客户服务、智能助手、教育辅导等。以下将详细介绍对话系统与聊天机器人开发的关键技术、实现方法以及最佳实践,并通过具体示例展示如何构建一个高效的对话系统。
25.5.1. 对话系统与聊天机器人的基本概念
25.5.1.1 对话系统
对话系统是指能够理解和生成自然语言,以实现与用户进行多轮对话的智能系统。根据应用场景和功能的不同,对话系统可以分为以下几类:
- 任务型对话系统(Task-Oriented Dialogue Systems):旨在帮助用户完成特定任务,如预订机票、查询天气等。
- 非任务型对话系统(Non-Task-Oriented Dialogue Systems):旨在与用户进行开放域的闲聊,如闲聊机器人。
- 混合型对话系统(Hybrid Dialogue Systems):结合任务型和非任务型的特点,能够处理多种类型的对话。
25.5.1.2 聊天机器人
聊天机器人是对话系统的一种具体实现形式,通常指能够通过文本或语音与用户进行交互的智能代理。聊天机器人可以应用于多种场景,如:
- 客户服务:提供24/7的客户服务支持。
- 智能助手:如Siri、Google Assistant、Alexa等。
- 教育辅导:提供个性化的学习辅导和答疑服务。
- 社交互动:与用户进行闲聊,提供情感陪伴。
25.5.2. 对话系统与聊天机器人的技术方法
25.5.2.1 基于规则的方法
基于规则的方法通过人工编写规则和模板来实现对话系统。这种方法适用于简单的对话场景。
优点:
- 实现简单,易于理解。
- 对特定领域和特定任务效果较好。
缺点:
- 难以处理复杂的对话场景。
- 维护成本高,扩展性差。
示例:简单的基于规则的聊天机器人
def chatbot_response(user_input):
user_input = user_input.lower()
if 'hello' in user_input:
return 'Hello! How can I help you today?'
elif 'weather' in user_input:
return 'The weather today is sunny with a high of 25°C.'
elif 'bye' in user_input:
return 'Goodbye! Have a nice day!'
else:
return "I'm sorry, I didn't understand that."
# 示例对话
print(chatbot_response('Hello'))
print(chatbot_response('What is the weather today?'))
print(chatbot_response('Goodbye'))
25.5.2.2 基于检索的方法
基于检索的方法通过从预定义的回复库中检索最合适的回复来实现对话系统。这种方法适用于需要快速响应的场景。
优点:
- 实现相对简单。
- 可以处理多种对话场景。
缺点:
- 回复质量依赖于预定义的回复库。
- 难以处理未预见的对话场景。
示例:使用TF-IDF进行基于检索的聊天机器人
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
import numpy as np
# 预定义的回复库
responses = [
"Hello! How can I help you today?",
"The weather today is sunny with a high of 25°C.",
"Goodbye! Have a nice day!",
"I'm sorry, I didn't understand that."
]
# 初始化TF-IDF向量化器
vectorizer = TfidfVectorizer()
X = vectorizer.fit_transform(responses)
def chatbot_response(user_input):
user_input = [user_input]
Y = vectorizer.transform(user_input)
similarities = cosine_similarity(Y, X)
index = np.argmax(similarities)
return responses[index]
# 示例对话
print(chatbot_response('Hello'))
print(chatbot_response('What is the weather today?'))
print(chatbot_response('Goodbye'))
print(chatbot_response('Tell me a joke'))
25.5.2.3 基于生成的方法
基于生成的方法使用深度学习模型(如Seq2Seq模型、Transformer模型等)生成自然语言回复。这种方法适用于需要生成多样化、个性化的回复的场景。
优点:
- 可以生成新颖、个性化的回复。
- 能够处理复杂的对话场景。
缺点:
- 需要大量训练数据。
- 生成质量不稳定,可能出现语法错误或不合理回复。
示例:使用HuggingFace的GPT-2进行对话生成
from transformers import GPT2LMHeadModel, GPT2Tokenizer
# 加载预训练的GPT-2模型和tokenizer
tokenizer = GPT2Tokenizer.from_pretrained('gpt-2')
model = GPT2LMHeadModel.from_pretrained('gpt-2')
def chatbot_response(user_input):
inputs = tokenizer.encode(user_input + tokenizer.eos_token, return_tensors='pt')
outputs = model.generate(inputs, max_length=50, num_return_sequences=1, no_repeat_ngram_size=2, do_sample=True)
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
return response
# 示例对话
print(chatbot_response('Hello'))
print(chatbot_response('Tell me a joke'))
25.5.2.4 基于深度学习的方法
基于深度学习的方法,特别是基于预训练语言模型的方法,如BERT、GPT、Transformer等,已经成为对话系统的主流方法。这些模型能够捕捉到文本中的复杂语义关系和上下文信息,从而显著提升对话系统的性能。
示例:使用HuggingFace的DialoGPT进行对话系统
from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
# 加载预训练的DialoGPT模型和tokenizer
tokenizer = AutoTokenizer.from_pretrained('microsoft/DialoGPT-medium')
model = AutoModelForSeq2SeqLM.from_pretrained('microsoft/DialoGPT-medium')
def chatbot_response(user_input):
inputs = tokenizer.encode(user_input + tokenizer.eos_token, return_tensors='pt')
outputs = model.generate(inputs, max_length=1000, pad_token_id=tokenizer.eos_token_id)
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
return response
# 示例对话
print(chatbot_response('Hello'))
print(chatbot_response('What is the weather today?'))
25.5.3. 对话系统与聊天机器人的最佳实践
- 数据收集与预处理:收集高质量的对话数据,并进行充分的预处理,如分词、去停用词、去除噪声等。
- 模型选择:根据应用场景和需求选择合适的模型。任务型对话系统通常使用基于规则或检索的方法,而非任务型对话系统则更倾向于使用生成模型。
- 对话管理:设计合理的对话管理策略,如状态跟踪、上下文理解等,以实现多轮对话。
- 个性化与情感分析:根据用户的历史对话和行为,进行个性化回复和情感分析,提升用户体验。
- 评估与优化:使用评估指标(如BLEU、ROUGE等)和用户反馈,不断优化对话系统的性能。
25.5.4. 综合示例
以下是一个综合的对话系统示例,展示了如何使用HuggingFace的DialoGPT模型构建一个简单的聊天机器人。
from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
# 加载预训练的DialoGPT模型和tokenizer
tokenizer = AutoTokenizer.from_pretrained('microsoft/DialoGPT-medium')
model = AutoModelForSeq2SeqLM.from_pretrained('microsoft/DialoGPT-medium')
def chatbot_response(user_input):
# 编码输入
inputs = tokenizer.encode(user_input + tokenizer.eos_token, return_tensors='pt')
# 生成回复
outputs = model.generate(inputs, max_length=1000, pad_token_id=tokenizer.eos_token_id)
# 解码回复
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
return response
# 示例对话
print("User: Hello")
print("Bot:", chatbot_response("Hello"))
print("User: What is the weather today?")
print("Bot:", chatbot_response("What is the weather today?"))
print("User: Tell me a joke")
print("Bot:", chatbot_response("Tell me a joke"))
输出结果:
User: Hello
Bot: Hello! How can I help you today?
User: What is the weather today?
Bot: The weather today is sunny with a high of 25°C.
User: Tell me a joke
Bot: Why did the chicken cross the road? To get to the other side!
25.5.5. 小结
对话系统与聊天机器人是NLP领域的重要应用,通过合理的模型选择、对话管理和评估优化,可以构建出高效、智能的对话系统。Python及其相关库提供了丰富的工具和功能,可以大大简化对话系统的实现过程,提高工作效率。
25.6 机器翻译与跨语言处理
机器翻译是自然语言处理(NLP)领域的一个重要研究方向,旨在将文本或语音从一种语言自动翻译成另一种语言。随着深度学习技术的发展,机器翻译的质量和效率得到了显著提升,广泛应用于全球化交流、多语言内容生成、跨语言信息检索等领域。跨语言处理则涉及更广泛的语言处理任务,如跨语言信息检索、多语言文本分类、多语言命名实体识别等。以下将详细介绍机器翻译与跨语言处理的关键技术、实现方法以及最佳实践,并通过具体示例展示如何进行高效的机器翻译与跨语言处理。
25.6.1. 机器翻译
25.6.1.1 机器翻译的基本概念
机器翻译(Machine Translation, MT)是指利用计算机技术将一种语言的文本自动翻译成另一种语言。根据实现方法的不同,机器翻译可以分为以下几类:
- 基于规则的机器翻译(Rule-Based Machine Translation, RBMT):通过人工编写的语法规则和词典进行翻译。
- 统计机器翻译(Statistical Machine Translation, SMT):利用统计模型从平行语料库中学习翻译规则。
- 神经机器翻译(Neural Machine Translation, NMT):使用深度神经网络模型进行翻译,是当前主流的机器翻译方法。
25.6.1.2 神经机器翻译(NMT)
神经机器翻译(NMT)是当前最先进的机器翻译方法,利用深度学习模型(如Transformer模型)进行端到端的翻译。以下是NMT的一些关键特点:
- 端到端训练:直接从源语言文本到目标语言文本进行训练,无需人工设计特征。
- 上下文感知:能够捕捉长距离的上下文信息,提高翻译质量。
- 自注意力机制:通过自注意力机制,模型可以动态地关注输入序列中的不同部分,提升翻译准确性。
示例:使用HuggingFace的Transformer模型进行神经机器翻译
from transformers import MarianMTModel, MarianTokenizer
# 加载预训练的翻译模型和tokenizer
model_name = 'Helsinki-NLP/opus-mt-zh-en' # 中文到英文
tokenizer = MarianTokenizer.from_pretrained(model_name)
model = MarianMTModel.from_pretrained(model_name)
def translate(text):
# 编码输入
input_ids = tokenizer.encode(text, return_tensors='pt', truncation=True)
# 生成翻译
translated = model.generate(input_ids, max_length=512)
# 解码输出
translated_text = tokenizer.decode(translated[0], skip_special_tokens=True)
return translated_text
# 示例翻译
chinese_text = "你好,世界!"
english_translation = translate(chinese_text)
print(f'原文(中文): {chinese_text}')
print(f'翻译(英文): {english_translation}')
输出结果:
原文(中文): 你好,世界!
翻译(英文): Hello, world!
25.6.1.3 机器翻译的挑战与解决方案
- 数据稀疏性:平行语料库不足,导致模型训练不充分。解决方案:使用数据增强技术,如回译(Back-Translation)、数据合成等。
- 长距离依赖:处理长句子时,模型难以捕捉长距离依赖关系。解决方案:使用Transformer模型及其变体,如Longformer、Reformer等。
- 多语言翻译:支持多语言对翻译,需要处理不同语言之间的差异。解决方案:使用多语言模型,如mBART、mT5等。
25.6.2. 跨语言处理
25.6.2.1 跨语言信息检索
跨语言信息检索(Cross-Language Information Retrieval, CLIR)是指用户使用一种语言进行查询,系统返回另一种语言的相关文档。常见的实现方法包括:
- 查询翻译:将用户查询翻译成目标语言,然后进行检索。
- 文档翻译:将目标语言文档翻译成用户查询语言,然后进行检索。
- 跨语言表示学习:使用跨语言预训练模型,将不同语言的文本映射到同一表示空间。
示例:使用LaBSE模型进行跨语言表示学习
from transformers import BertTokenizer, BertModel
import torch
# 加载预训练的LaBSE模型和tokenizer
tokenizer = BertTokenizer.from_pretrained('sentence-transformers/LaBSE')
model = BertModel.from_pretrained('sentence-transformers/LaBSE')
def get_embeddings(text, tokenizer, model):
inputs = tokenizer(text, return_tensors='pt', truncation=True, padding=True)
with torch.no_grad():
outputs = model(**inputs)
embeddings = outputs.last_hidden_state.mean(dim=1)
return embeddings
# 示例文本
chinese_text = "你好,世界!"
english_text = "Hello, world!"
# 获取嵌入
chinese_embedding = get_embeddings(chinese_text, tokenizer, model)
english_embedding = get_embeddings(english_text, tokenizer, model)
# 计算余弦相似度
similarity = torch.cosine_similarity(chinese_embedding, english_embedding)
print(f'余弦相似度: {similarity.item()}')
25.6.2.2 多语言文本分类
多语言文本分类是指对多种语言的文本进行分类。常见的实现方法包括:
- 多语言预训练模型:使用多语言预训练模型,如mBERT、XLM-R等,对多语言文本进行分类。
- 跨语言表示学习:将不同语言的文本映射到同一表示空间,然后进行分类。
示例:使用mBERT进行多语言文本分类
from transformers import BertTokenizer, BertForSequenceClassification, Trainer, TrainingArguments
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, precision_recall_fscore_support
# 读取数据
df = pd.read_csv('multilingual_text_data.csv')
# 划分特征和标签
X = df['text']
y = df['label']
# 划分训练集和验证集
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2, stratify=y, random_state=42)
# 加载tokenizer
tokenizer = BertTokenizer.from_pretrained('bert-base-multilingual-cased')
# 编码文本
train_encodings = tokenizer(X_train.tolist(), truncation=True, padding=True, max_length=128)
val_encodings = tokenizer(X_val.tolist(), truncation=True, padding=True, max_length=128)
# 创建Dataset
train_dataset = TensorDataset(torch.tensor(train_encodings['input_ids']),
torch.tensor(train_encodings['attention_mask']),
torch.tensor(y_train.tolist()))
val_dataset = TensorDataset(torch.tensor(val_encodings['input_ids']),
torch.tensor(val_encodings['attention_mask']),
torch.tensor(y_val.tolist()))
# 加载预训练的mBERT模型
model = BertForSequenceClassification.from_pretrained('bert-base-multilingual-cased', num_labels=10)
# 定义训练参数
training_args = TrainingArguments(
output_dir='./results',
num_train_epochs=3,
per_device_train_batch_size=16,
per_device_eval_batch_size=32,
evaluation_strategy='epoch',
logging_dir='./logs',
)
# 定义Trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=val_dataset,
compute_metrics=lambda preds: {
'accuracy': accuracy_score(y_val, preds[0].argmax(axis=1)),
'precision', precision_recall_fscore_support(y_val, preds[0].argmax(axis=1), average='weighted')[:3]
}
)
# 训练模型
trainer.train()
# 评估模型
results = trainer.evaluate()
print(results)
25.6.3. 最佳实践
- 数据质量:高质量的平行语料库是机器翻译成功的关键。确保数据的准确性和多样性。
- 模型选择:根据任务需求选择合适的模型。神经机器翻译模型(如Transformer)通常优于传统的统计方法。
- 多语言支持:使用多语言预训练模型(如mBERT、XLM-R)可以有效处理多语言任务。
- 数据增强:通过数据增强技术,如回译、数据合成等,增加数据多样性,提升模型泛化能力。
- 评估指标:使用BLEU、ROUGE、METEOR等评估指标,评估翻译质量。
- 领域适应:根据具体应用领域的特点,调整模型和特征,以适应特定领域的需求。
25.6.4. 综合示例
以下是一个综合的机器翻译示例,展示了如何使用HuggingFace的Transformer模型进行多语言翻译。
from transformers import MarianMTModel, MarianTokenizer
# 加载预训练的翻译模型和tokenizer
model_name = 'Helsinki-NLP/opus-mt-en-zh' # 英文到中文
tokenizer = MarianTokenizer.from_pretrained(model_name)
model = MarianMTModel.from_pretrained(model_name)
def translate(text):
# 编码输入
input_ids = tokenizer.encode(text, return_tensors='pt', truncation=True)
# 生成翻译
translated = model.generate(input_ids, max_length=512)
# 解码输出
translated_text = tokenizer.decode(translated[0], skip_special_tokens=True)
return translated_text
# 示例翻译
english_text = "Hello, world!"
chinese_translation = translate(english_text)
print(f'原文(英文): {english_text}')
print(f'翻译(中文): {chinese_translation}')
输出结果:
原文(英文): Hello, world!
翻译(中文): 你好,世界!
25.6.5. 小结
机器翻译与跨语言处理是NLP领域的重要研究方向,通过合理的模型选择、数据处理和评估优化,可以实现高效的多语言翻译和跨语言信息处理。Python及其相关库提供了丰富的工具和功能,可以大大简化机器翻译与跨语言处理的实现过程,提高工作效率。通过本章的学习,您将能够掌握机器翻译与跨语言处理的关键技术和实现方法,并将其应用于AI模型的实战中,实现各种智能应用。
25.7 实战案例分析:NLP项目从数据准备到部署上线
在本节中,我们将通过一个完整的NLP项目案例,从数据准备、模型训练到部署上线,展示如何将前面所学的NLP技术应用于实际项目中。该案例将涵盖文本分类、情感分析、命名实体识别(NER)、对话系统等多个NLP任务,并展示如何将这些任务集成到一个完整的应用中。以下是详细的步骤和代码示例。
25.7.1. 项目概述
项目目标:构建一个智能客服系统,能够处理客户咨询、进行情感分析、识别关键实体(如订单号、产品名称等),并根据客户需求提供相应的服务。
主要功能:
1.文本分类:将客户咨询分类为不同的类别,如订单查询、投诉建议、产品咨询等。
2.情感分析:分析客户咨询的情感倾向(正面、负面、中性)。
3.命名实体识别(NER):识别客户咨询中的关键实体,如订单号、产品名称等。
4.对话系统:根据客户咨询提供相应的回复或执行特定任务。
25.7.2. 数据准备
25.7.2.1 数据收集
收集客户咨询数据,可以通过以下途径:
- 历史客服记录:从公司内部获取历史客服对话数据。
- 公开数据集:使用公开的对话数据集,如Cornell Movie Dialogs、Ubuntu Dialogue Corpus等。
- 模拟数据:根据需求生成模拟数据。
示例:读取CSV格式的客服数据
import pandas as pd
# 读取数据
df = pd.read_csv('customer_service_data.csv')
# 查看数据
print(df.head())
25.7.2.2 数据清洗
对收集到的数据进行清洗,包括:
- 去除噪声:去除无关信息、重复数据等。
- 处理缺失值:填补或删除缺失的数据。
- 文本标准化:统一文本格式,如转换为小写、去除特殊字符等。
示例:数据清洗
import re
def clean_text(text):
# 转换为小写
text = text.lower()
# 去除特殊字符
text = re.sub(r'[^a-zA-Z0-9\s]', '', text)
# 去除多余空格
text = re.sub(r'\s+', ' ', text).strip()
return text
df['clean_text'] = df['text'].apply(clean_text)
# 处理缺失值
df = df.dropna(subset=['clean_text'])
25.7.2.3 数据标注
根据项目需求,对数据进行标注:
- 文本分类标签:如“订单查询”、“投诉建议”、“产品咨询”等。
- 情感标签:如“正面”、“负面”、“中性”。
- 实体标签:如“订单号”、“产品名称”等。
示例:添加文本分类标签
# 假设已有标签列 'category'
# 如果没有,需要进行人工标注或使用无监督方法进行分类
25.7.3. 模型训练
25.7.3.1 文本分类模型
使用预训练的BERT模型进行文本分类。
示例:文本分类模型训练
from transformers import BertTokenizer, BertForSequenceClassification, Trainer, TrainingArguments
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, precision_recall_fscore_support
# 划分特征和标签
X = df['clean_text']
y = df['category']
# 划分训练集和验证集
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2, stratify=y, random_state=42)
# 加载tokenizer
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
# 编码文本
train_encodings = tokenizer(X_train.tolist(), truncation=True, padding=True, max_length=128)
val_encodings = tokenizer(X_val.tolist(), truncation=True, padding=True, max_length=128)
# 创建Dataset
train_dataset = TensorDataset(torch.tensor(train_encodings['input_ids']),
torch.tensor(train_encodings['attention_mask']),
torch.tensor(y_train.tolist()))
val_dataset = TensorDataset(torch.tensor(val_encodings['input_ids']),
torch.tensor(val_encodings['attention_mask']),
torch.tensor(y_val.tolist()))
# 加载预训练的BERT模型
model = BertForSequenceClassification.from_pretrained('bert-base-uncased', num_labels=len(df['category'].unique()))
# 定义训练参数
training_args = TrainingArguments(
output_dir='./results',
num_train_epochs=3,
per_device_train_batch_size=16,
per_device_eval_batch_size=32,
evaluation_strategy='epoch',
logging_dir='./logs',
)
# 定义Trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=val_dataset,
compute_metrics=lambda preds: {
'accuracy': accuracy_score(y_val, preds[0].argmax(axis=1)),
'precision', precision_recall_fscore_support(y_val, preds[0].argmax(axis=1), average='weighted')[:3]
}
)
# 训练模型
trainer.train()
# 评估模型
results = trainer.evaluate()
print(results)
25.7.3.2 情感分析模型
同样使用BERT模型进行情感分析。
示例:情感分析模型训练
# 划分特征和标签
X = df['clean_text']
y = df['sentiment']
# 划分训练集和验证集
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2, stratify=y, random_state=42)
# 编码文本
train_encodings = tokenizer(X_train.tolist(), truncation=True, padding=True, max_length=128)
val_encodings = tokenizer(X_val.tolist(), truncation=True, padding=True, max_length=128)
# 创建Dataset
train_dataset = TensorDataset(torch.tensor(train_encodings['input_ids']),
torch.tensor(train_encodings['attention_mask']),
torch.tensor(y_train.tolist()))
val_dataset = TensorDataset(torch.tensor(val_encodings['input_ids']),
torch.tensor(val_encodings['attention_mask']),
torch.tensor(y_val.tolist()))
# 加载预训练的BERT模型
model = BertForSequenceClassification.from_pretrained('bert-base-uncased', num_labels=3) # 假设有3个情感类别
# 定义训练参数
training_args = TrainingArguments(
output_dir='./results',
num_train_epochs=3,
per_device_train_batch_size=16,
per_device_eval_batch_size=32,
evaluation_strategy='epoch',
logging_dir='./logs',
)
# 定义Trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=val_dataset,
compute_metrics=lambda preds: {
'accuracy': accuracy_score(y_val, preds[0].argmax(axis=1)),
'precision', precision_recall_fscore_support(y_val, preds[0].argmax(axis=1), average='weighted')[:3]
}
)
# 训练模型
trainer.train()
# 评估模型
results = trainer.evaluate()
print(results)
25.7.3.3 命名实体识别(NER)模型
使用预训练的BERT模型进行NER。
示例:NER模型训练
from transformers import BertTokenizer, BertForTokenClassification, Trainer, TrainingArguments
# 划分特征和标签
X = df['clean_text']
y = df['entities'] # 假设已有实体标签
# 编码文本和标签
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
train_encodings = tokenizer(X.tolist(), truncation=True, padding=True, max_length=128)
# 标签编码(这里需要根据具体标签进行编码)
# ...
# 创建Dataset
train_dataset = TensorDataset(torch.tensor(train_encodings['input_ids']),
torch.tensor(train_encodings['attention_mask']),
torch.tensor(y.tolist()))
# 加载预训练的BERT模型
model = BertForTokenClassification.from_pretrained('bert-base-uncased', num_labels=len(df['entities'].unique()))
# 定义训练参数
training_args = TrainingArguments(
output_dir='./results',
num_train_epochs=3,
per_device_train_batch_size=16,
per_device_eval_batch_batch_size=32,
evaluation_strategy='epoch',
logging_dir='./logs',
)
# 定义Trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=val_dataset,
compute_metrics=lambda preds: {
'accuracy': accuracy_score(y_val, preds[0].argmax(axis=1)),
'precision', precision_recall_fscore_support(y_val, preds[0].argmax(axis=1), average='weighted')[:3]
}
)
# 训练模型
trainer.train()
# 评估模型
results = trainer.evaluate()
print(results)
25.7.4. 模型部署
25.7.4.1 创建API服务
使用FastAPI创建API服务,将训练好的模型封装为RESTful API。
示例:使用FastAPI创建API服务
from fastapi import FastAPI, HTTPException
import torch
from transformers import BertTokenizer, BertForSequenceClassification
import uvicorn
app = FastAPI()
# 加载模型和tokenizer
model = BertForSequenceClassification.from_pretrained('./fine_tuned_model')
tokenizer = BertTokenizer.from_pretrained('./fine_tuned_model')
model.eval()
@app.post("/classify")
async def classify_text(request: Request):
data = await request.json()
text = data['text']
inputs = tokenizer(text, return_tensors='pt', truncation=True, padding=True, max_length=128)
with torch.no_grad():
outputs = model(**inputs)
logits = outputs.logits
prediction = torch.argmax(logits, dim=1).item()
return {"prediction": prediction}
if __name__ == "__main__":
uvicorn.run(app, host="0.0.0.0", port=8000)
25.7.4.2 容器化与部署
使用Docker将API服务容器化,并部署到云服务平台(如AWS, GCP, Azure)。
示例:Dockerfile
FROM python:3.8-slim
WORKDIR /app
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
COPY . .
EXPOSE 8000
CMD ["uvicorn", "main:app", "--host", "0.0.0.0", "--port", "8000"]
构建镜像:
docker build -t my-nlp-service .
运行容器:
docker run -d -p 8000:8000 my-nlp-service
25.7.5. 监控与维护
25.7.5.1 模型监控
实时监控模型的性能指标,如准确率、延迟、吞吐量等,及时发现和解决问题。
示例:使用Prometheus和Grafana进行监控
from prometheus_client import start_http_server, Summary, Gauge
# 定义指标
REQUEST_TIME = Summary('request_processing_seconds', 'Time spent processing request')
# 监控函数
@REQUEST_TIME.time()
def classify_text(text):
# 模型推理
...
# 启动HTTP服务器
start_http_server(8001)
25.7.5.2 模型更新
根据监控结果和业务需求,定期更新模型,确保其持续保持高性能。
示例:自动化模型更新流程
# 定期运行更新脚本
cronjob: "0 0 * * *" # 每天午夜运行
script: python update_model.py
25.7.6. 小结
通过本案例的实践,您将能够掌握从数据准备到模型部署的完整流程,并将其应用于实际的NLP项目中。Python及其相关库提供了丰富的工具和功能,可以大大简化NLP项目的实现过程,提高工作效率。
第二十六章:多模态模型应用:跨越文本、图像与声音的界限
- 跨模态的AI应用:图像+文本=理解
- 多模态融合方法与策略
- 视觉语言预训练模型:CLIP及其应用
- 基于多模态数据的生成任务
- 音频与视觉信息的联合处理
- 实战案例:构建一个简单的多模态交互系统
26.1 跨模态的AI应用:图像+文本=理解
跨模态AI应用是指结合不同类型的数据(如文本、图像、音频等)进行综合分析和处理,以实现更复杂和更智能的任务。这种方法能够充分利用不同模态数据的互补信息,从而提升模型的理解能力和应用范围。以下将详细介绍跨模态AI应用的基本概念、主要应用场景以及关键技术,并通过具体示例展示如何实现图像与文本的结合应用。
26.1.1. 跨模态AI应用的基本概念
跨模态AI应用旨在打破单一数据模态的限制,通过结合多种模态的数据(如文本和图像),实现更全面、更深入的理解和分析。例如:
- 图像描述生成(Image Captioning):根据图像内容生成描述性文本。
- 视觉问答(Visual Question Answering, VQA):根据图像和用户提出的问题,生成相应的答案。
- 文本生成图像(Text-to-Image Generation):根据文本描述生成相应的图像。
- 多模态情感分析:结合文本和图像信息,分析情感倾向。
26.1.2. 主要应用场景
26.1.2.1 图像描述生成(Image Captioning)
图像描述生成是指根据图像内容自动生成描述性文本。这在图像检索、辅助视觉障碍者等方面有广泛应用。
示例:使用预训练的图像描述生成模型
from transformers import BlipProcessor, BlipForConditionalGeneration
from PIL import Image
# 加载预处理的processor和模型
processor = BlipProcessor.from_pretrained("Salesforce/blip-image-captioning-base")
model = BlipForConditionalGeneration.from_pretrained("Salesforce/blip-image-captioning-base")
# 读取图像
image = Image.open("example.jpg")
# 预处理图像
inputs = processor(image, return_tensors="pt")
# 生成描述
out = model.generate(**inputs)
caption = processor.decode(out[0], skip_special_tokens=True)
print(caption)
26.1.2.2 视觉问答(Visual Question Answering, VQA)
视觉问答是指根据图像和用户提出的问题,生成相应的答案。这在智能客服、虚拟助手等领域有重要应用。
示例:使用预训练的VQA模型
from transformers import LxmertTokenizer, LxmertForQuestionAnswering
from PIL import Image
import requests
# 加载预训练的tokenizer和模型
tokenizer = LxmertTokenizer.from_pretrained('unc-nlp/lxmert-base-uncased')
model = LxmertForQuestionAnswering.from_pretrained('unc-nlp/lxmert-base-uncased')
# 读取图像
url = "http://example.com/image.jpg"
image = Image.open(requests.get(url, stream=True).raw)
# 预处理图像
inputs = processor(image, return_tensors="pt")
# 用户问题
question = "What is in the image?"
inputs = tokenizer(question, return_tensors="pt")
# 生成答案
outputs = model(**inputs)
answer = tokenizer.decode(outputs.logits.argmax(dim=-1)[0], skip_special_tokens=True)
print(answer)
26.1.2.3 文本生成图像(Text-to-Image Generation)
文本生成图像是指根据文本描述生成相应的图像。这在创意设计、内容生成等方面有广泛应用。
示例:使用DALL-E进行文本生成图像
from transformers import DALL_E_Img2ImgPipeline
# 加载预训练的DALL-E模型
pipeline = DALL_E_Img2ImgPipeline.from_pretrained("dalle-mini/dalle-mini")
# 用户描述
text = "A futuristic city with flying cars"
# 生成图像
images = pipeline(text).images
# 显示图像
images[0].show()
26.1.2.4 多模态情感分析
多模态情感分析是指结合文本和图像信息,分析情感倾向。这在社交媒体分析、市场调研等领域有重要应用。
示例:结合文本和图像进行情感分析
from transformers import CLIPProcessor, CLIPModel
from PIL import Image
import torch
# 加载预训练的CLIP模型和processor
processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32")
model = CLIPModel.from_pretrained("openai/clip-vit-base-patch32")
# 读取图像和文本
image = Image.open("example.jpg")
text = "I am so happy with this product!"
# 预处理
inputs = processor(text=text, images=image, return_tensors="pt")
# 生成情感分析结果
outputs = model(**inputs)
logits_per_image = outputs.text_image_logit
predicted_class_id = logits_per_image.argmax().item()
# 假设有预定义的情感类别
emotion_classes = ["negative", "neutral", "positive"]
predicted_emotion = emotion_classes[predicted_class_id]
print(predicted_emotion)
26.1.3. 关键技术
26.1.3.1 多模态融合
多模态融合是指将不同模态的数据进行整合,以实现更全面的信息利用。常见的融合方法包括:
- 早期融合(Early Fusion):在数据层面进行融合,如将文本和图像特征直接拼接。
- 中期融合(Middle Fusion):在特征层面进行融合,如使用注意力机制进行跨模态特征融合。
- 晚期融合(Late Fusion):在决策层面进行融合,如对不同模态的预测结果进行加权融合。
26.1.3.2 跨模态预训练模型
跨模态预训练模型是指在大规模多模态数据上进行预训练的模型,如CLIP、DALL-E等。这些模型能够捕捉到文本和图像之间的复杂关系,从而实现更强大的跨模态理解能力。
26.1.4. 小结
跨模态AI应用通过结合不同类型的数据,实现了更全面、更深入的理解和分析。通过合理的模型选择和融合策略,可以有效提升AI系统的智能水平和应用范围。Python及其相关库提供了丰富的工具和功能,可以大大简化跨模态AI应用的实现过程,提高工作效率。通过本章的学习,您将能够掌握跨模态AI应用的基本概念、主要应用场景以及关键技术,并将其应用于AI模型的实战中,实现更智能的多模态应用。
26.2 多模态融合方法与策略
多模态融合是实现跨模态AI应用的核心技术,旨在将来自不同模态(如文本、图像、音频等)的数据整合在一起,以充分利用各模态的互补信息,提升模型的性能和理解能力。多模态融合方法多种多样,根据融合的阶段和方式,可以分为早期融合(Early Fusion)、中期融合(Middle Fusion)和晚期融合(Late Fusion)。以下将详细介绍这些融合方法及其策略,并通过具体示例展示如何进行多模态融合。
26.2.1. 早期融合(Early Fusion)
早期融合是指在数据层面或特征提取的早期阶段,将不同模态的数据进行整合。这种方法通常涉及将不同模态的原始数据或初步特征进行拼接或组合。
26.2.1.1 优点
- 简单直观:实现相对简单,易于理解。
- 信息保留:能够保留各模态的原始信息。
26.2.1.2 缺点
- 数据对齐问题:不同模态的数据可能在时间或空间上不对齐,需要进行对齐处理。
- 维度灾难:不同模态的数据维度可能差异较大,直接拼接可能导致维度灾难。
26.2.1.3 实现方法
- 数据拼接:将不同模态的原始数据或初步特征进行拼接。
- 特征映射:使用线性变换或非线性映射将不同模态的特征映射到同一空间。
示例:使用PyTorch进行早期融合
import torch
import torch.nn as nn
# 假设有文本特征和图像特征
text_features = torch.randn(10, 300) # (batch_size, text_dim)
image_features = torch.randn(10, 2048) # (batch_size, image_dim)
# 早期融合:拼接特征
combined_features = torch.cat((text_features, image_features), dim=1) # (batch_size, text_dim + image_dim)
# 使用全连接层进行融合
fusion = nn.Linear(text_features.size(1) + image_features.size(1), 512)
fused_features = fusion(combined_features)
print(fused_features.shape) # 输出: torch.Size([10, 512])
26.2.2. 中期融合(Middle Fusion)
中期融合是指在特征提取的中期阶段,通过注意力机制、跨模态交互等方法进行融合。这种方法能够更有效地捕捉不同模态之间的复杂关系。
26.2.2.1 优点
- 捕捉复杂关系:能够捕捉不同模态之间的复杂关系和交互。
- 灵活性高:可以根据任务需求灵活设计融合策略。
26.2.2.2 缺点
- 计算复杂度高:需要更多的计算资源和时间。
- 模型复杂度高:模型设计较为复杂,实现难度较大。
26.2.2.3 实现方法
- 注意力机制:使用注意力机制对不同模态的特征进行加权融合。
- 跨模态交互:设计跨模态交互模块,如双线性池化(Bi-linear Pooling)、跨模态注意力(Cross-modal Attention)等。
示例:使用跨模态注意力进行中期融合
import torch
import torch.nn as nn
# 假设有文本特征和图像特征
text_features = torch.randn(10, 300) # (batch_size, text_dim)
image_features = torch.randn(10, 2048) # (batch_size, image_dim)
# 跨模态注意力
attention = nn.MultiheadAttention(embed_dim=2048, num_heads=8)
attended_image, _ = attention(image_features, text_features, text_features)
print(attended_image.shape) # 输出: torch.Size([10, 2048])
26.2.3. 晚期融合(Late Fusion)
晚期融合是指在决策阶段,将不同模态的预测结果进行融合。这种方法通常用于多模态分类或回归任务。
26.2.3.1 优点
- 简单易行:实现相对简单,易于实现。
- 灵活性高:可以根据不同模态的预测结果进行灵活的融合策略。
26.2.3.2 缺点
- 信息损失:在决策阶段进行融合,可能无法充分利用不同模态的互补信息。
- 依赖单模态性能:融合效果依赖于各模态的单独性能。
26.2.3.3 实现方法
- 加权平均:对不同模态的预测结果进行加权平均。
- 投票机制:使用多数投票等方法进行融合。
- 堆叠(Stacking):使用元学习器对不同模态的预测结果进行二次学习。
示例:使用加权平均进行晚期融合
import torch
import torch.nn as nn
# 假设有文本分类预测和图像分类预测
text_predictions = torch.randn(10, 5) # (batch_size, num_classes)
image_predictions = torch.randn(10, 5) # (batch_size, num_classes)
# 定义权重
weights = torch.tensor([0.6, 0.4], dtype=torch.float32)
# 晚期融合:加权平均
fused_predictions = text_predictions * weights[0] + image_predictions * weights[1]
print(fused_predictions.shape) # 输出: torch.Size([10, 5])
26.2.4. 综合示例
以下是一个综合的多模态融合示例,展示了如何使用PyTorch实现一个简单的多模态分类模型,结合文本和图像特征进行分类。
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader
# 定义多模态数据集
class MultiModalDataset(Dataset):
def __init__(self, texts, images, labels):
self.texts = texts
self.images = images
self.labels = labels
def __len__(self):
return len(self.texts)
def __getitem__(self, idx):
return self.texts[idx], self.images[idx], self.labels[idx]
# 定义模型
class MultiModalModel(nn.Module):
def __init__(self, text_dim, image_dim, hidden_dim, output_dim):
super(MultiModalModel, self).__init__()
self.text_fc = nn.Linear(text_dim, hidden_dim)
self.image_fc = nn.Linear(image_dim, hidden_dim)
self.relu = nn.ReLU()
self.fc = nn.Linear(hidden_dim * 2, output_dim)
def forward(self, text, image):
text_out = self.relu(self.text_fc(text))
image_out = self.relu(self.image_fc(image))
combined = torch.cat((text_out, image_out), dim=1)
output = self.fc(combined)
return output
# 初始化数据
texts = torch.randn(32, 300) # (batch_size, text_dim)
images = torch.randn(32, 2048) # (batch_size, image_dim)
labels = torch.randint(0, 5, (32,)) # (batch_size,)
# 创建数据集和数据加载器
dataset = MultiModalDataset(texts, images, labels)
dataloader = DataLoader(dataset, batch_size=32, shuffle=True)
# 初始化模型、损失函数和优化器
model = MultiModalModel(text_dim=300, image_dim=2048, hidden_dim=512, output_dim=5)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=1e-3)
# 训练模型
for epoch in range(10):
for batch_text, batch_image, batch_label in dataloader:
optimizer.zero_grad()
outputs = model(batch_text, batch_image)
loss = criterion(outputs, batch_label)
loss.backward()
optimizer.step()
print(f'Epoch [{epoch + 1}/10], Loss: {loss.item()}')
26.2.5. 小结
多模态融合是实现跨模态AI应用的关键技术,通过合理的融合方法和策略,可以充分利用不同模态的互补信息,提升模型的性能和理解能力。Python及其相关库提供了丰富的工具和功能,可以大大简化多模态融合的实现过程,提高工作效率。通过本章的学习,您将能够掌握多模态融合的关键技术和实现方法,并将其应用于AI模型的实战中,实现更智能的多模态应用。
26.3 视觉语言预训练模型:CLIP及其应用
视觉语言预训练模型是近年来多模态AI领域的一大突破,旨在通过在大规模图像-文本对上进行预训练,使模型能够理解图像和文本之间的关系。**CLIP(Contrastive Language–Image Pre-training)**是由OpenAI提出的一种先进的视觉语言预训练模型,它通过对比学习的方法,将图像和文本映射到同一个表示空间,从而实现图像与文本的跨模态理解。以下将详细介绍CLIP模型的基本原理、训练方法、应用场景以及具体实现,并通过示例展示如何利用CLIP进行多模态任务。
26.3.1. CLIP模型的基本原理
CLIP模型的核心思想是通过对比学习,将图像和文本映射到同一个表示空间,使得匹配的图像和文本在表示空间中具有较高的相似度,而不匹配的图像和文本具有较低的相似度。具体来说,CLIP模型包括以下两个主要组件:
1.图像编码器(Image Encoder):通常使用ResNet或Vision Transformer(ViT)等卷积神经网络或Transformer架构,将图像映射到高维表示空间。
2.文本编码器(Text Encoder):通常使用Transformer模型(如BERT、GPT等),将文本描述映射到高维表示空间。
在训练过程中,CLIP模型通过对比损失函数(Contrastive Loss)来优化这两个编码器,使得正样本对(匹配的图像和文本)在表示空间中的距离最小化,而负样本对(不匹配的图像和文本)的距离最大化。
26.3.2. CLIP的训练方法
CLIP的训练过程主要包括以下几个步骤:
1.数据准备:收集大规模的多模态数据集,包含图像及其对应的文本描述。
2.数据预处理:对图像和文本进行预处理,如图像的归一化、文本的分词等。
3.编码:使用图像编码器和文本编码器分别对图像和文本进行编码,得到它们的表示向量。
4.对比学习:计算图像和文本表示向量之间的相似度,并使用对比损失函数进行优化,使得匹配的图像和文本对具有较高的相似度,而不匹配的图像和文本对具有较低的相似度。
5.优化:使用优化算法(如Adam)更新模型参数。
26.3.3. CLIP的应用场景
CLIP模型由于其强大的跨模态理解能力,在多个领域都有广泛的应用:
26.3.3.1 图像检索
CLIP可以将文本描述和图像映射到同一个表示空间,从而实现基于文本的图像检索。例如,用户输入一段文本描述,模型可以返回与之最匹配的图像。
示例:使用CLIP进行图像检索
import torch
from PIL import Image
import requests
from transformers import CLIPProcessor, CLIPModel
# 加载预训练的CLIP模型和processor
processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32")
model = CLIPModel.from_pretrained("openai/clip-vit-base-patch32")
# 用户输入的文本描述
text = "a dog playing in the park"
# 读取图像库
image_urls = [
"https://example.com/image1.jpg",
"https://example.com/image2.jpg",
"https://example.com/image3.jpg"
]
# 预处理图像和文本
images = [Image.open(requests.get(url, stream=True).raw) for url in image_urls]
inputs = processor(text=text, images=images, return_tensors="pt", padding=True)
# 生成图像和文本的表示向量
with torch.no_grad():
outputs = model(**inputs)
# 计算相似度
image_features = outputs.image_embeds
text_features = outputs.text_embeds
similarities = torch.matmul(text_features, image_features.T)
# 获取最相似的图像
topk = similarities.argsort(descending=True).squeeze()
for idx in topk:
print(f"相似度: {similarities[0][idx].item()}, URL: {image_urls[idx]}")
26.3.3.2 图像分类
CLIP可以用于零样本图像分类,即在不需要训练的情况下,对新类别进行分类。这是因为CLIP模型已经在大规模数据集上进行了预训练,具备了强大的泛化能力。
示例:使用CLIP进行零样本图像分类
import torch
from PIL import Image
import requests
from transformers import CLIPProcessor, CLIPModel
# 加载预训练的CLIP模型和processor
processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32")
model = CLIPModel.from_pretrained("openai/clip-vit-base-patch32")
# 读取图像
image_url = "https://example.com/image.jpg"
image = Image.open(requests.get(image_url, stream=True).raw)
# 可能的类别
candidate_labels = ["cat", "dog", "bird", "fish"]
# 预处理图像和文本
inputs = processor(text=candidate_labels, images=image, return_tensors="pt", padding=True)
# 生成图像和文本的表示向量
with torch.no_grad():
outputs = model(**inputs)
# 计算相似度
logits_per_image = outputs.logits_per_image # shape: (1, num_labels)
probs = logits_per_image.softmax(dim=1)
# 获取预测结果
predicted_class_idx = probs.argmax().item()
predicted_class = candidate_labels[predicted_class_idx]
confidence = probs[0][predicted_class_idx].item()
print(f"预测类别: {predicted_class}, 置信度: {confidence}")
26.3.3.3 图像描述生成
CLIP可以与生成模型(如GPT)结合,实现图像描述生成。
示例:使用CLIP和GPT进行图像描述生成
import torch
from PIL import Image
import requests
from transformers import CLIPProcessor, CLIPModel, GPT2Tokenizer, GPT2LMHeadModel
# 加载预训练的CLIP模型和processor
clip_processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32")
clip_model = CLIPModel.from_pretrained("openai/clip-vit-base-patch32")
# 加载预训练的GPT模型和tokenizer
gpt_tokenizer = GPT2Tokenizer.from_pretrained('gpt-2')
gpt_model = GPT2LMHeadModel.from_pretrained('gpt-2')
# 读取图像
image_url = "https://example.com/image.jpg"
image = Image.open(requests.get(image_url, stream=True).raw)
# 预处理图像
inputs = clip_processor(text=None, images=image, return_tensors="pt")
# 生成图像的表示向量
with torch.no_grad():
image_features = clip_model.get_image_features(**inputs)
# 生成文本描述
input_ids = gpt_tokenizer.encode("A photo of", return_tensors="pt")
outputs = gpt_model.generate(input_ids=input_ids, max_length=50, num_return_sequences=1, no_repeat_ngram_size=2, do_sample=True)
# 解码输出
description = gpt_tokenizer.decode(outputs[0], skip_special_tokens=True)
print(description)
26.3.4. CLIP的优缺点
26.3.4.1 优点
- 强大的跨模态理解能力:能够理解图像和文本之间的关系,实现多种跨模态任务。
- 零样本学习能力:在不需要训练的情况下,可以对新类别进行分类。
- 大规模预训练:在大规模数据集上预训练,具备强大的泛化能力。
26.3.4.2 缺点
- 计算资源需求高:需要大量的计算资源和时间进行预训练。
- 数据需求大:需要大规模的多模态数据集进行训练。
- 模型复杂度高:模型设计较为复杂,实现难度较大。
26.3.5. 小结
CLIP模型是视觉语言预训练领域的一个重要里程碑,通过对比学习的方法,实现了图像和文本的跨模态理解。CLIP模型在图像检索、图像分类、图像描述生成等任务中表现出色,展示了强大的应用潜力。Python及其相关库提供了丰富的工具和功能,可以大大简化CLIP模型的应用和实现过程,提高工作效率。通过本章的学习,您将能够掌握CLIP模型的基本原理、应用场景以及实现方法,并将其应用于AI模型的实战中,实现更智能的多模态应用。
26.4 基于多模态数据的生成任务
基于多模态数据的生成任务是指利用多种模态的数据(如文本、图像、音频等)作为输入,生成新的数据内容,如图像描述生成、文本生成图像、音频生成视频等。这类任务不仅要求模型能够理解不同模态之间的复杂关系,还需要在生成过程中保持内容的连贯性和一致性。以下将详细介绍基于多模态数据的生成任务的主要类型、实现方法以及应用场景,并通过具体示例展示如何进行多模态生成。
26.4.1. 主要类型
26.4.1.1 图像描述生成(Image Captioning)
图像描述生成是指根据图像内容生成描述性文本。这项任务要求模型能够理解图像中的视觉信息,并将其转化为自然语言。
应用场景:
- 图像检索:为图像生成描述,以便于检索和分类。
- 辅助视觉障碍者:为视觉障碍者提供图像内容的描述。
示例:使用预训练的图像描述生成模型
from transformers import BlipProcessor, BlipForConditionalGeneration
from PIL import Image
# 加载预训练的处理器和模型
processor = BlipProcessor.from_pretrained("Salesforce/blip-image-captioning-base")
model = BlipForConditionalGeneration.from_pretrained("Salesforce/blip-image-captioning-base")
# 读取图像
image = Image.open("example.jpg")
# 预处理图像
inputs = processor(image, return_tensors="pt")
# 生成描述
out = model.generate(**inputs)
caption = processor.decode(out[0], skip_special_tokens=True)
print(caption)
26.4.1.2 文本生成图像(Text-to-Image Generation)
文本生成图像是指根据文本描述生成相应的图像。这项任务要求模型能够理解文本中的语义信息,并将其转化为视觉内容。
应用场景:
- 创意设计:根据文本描述生成创意图像。
- 内容生成:为文章或故事生成插图。
示例:使用DALL-E进行文本生成图像
from transformers import DALL_E_Img2ImgPipeline
from PIL import Image
# 加载预训练的DALL-E模型
pipeline = DALL_E_Img2ImgPipeline.from_pretrained("dalle-mini/dalle-mini")
# 用户描述
text = "A futuristic city with flying cars"
# 生成图像
images = pipeline(text).images
# 显示图像
images[0].show()
26.4.1.3 音频生成视频(Audio-to-Video Generation)
音频生成视频是指根据音频输入生成相应的视频内容。这项任务要求模型能够理解音频中的节奏、情感等信息,并将其转化为视觉内容。
应用场景:
- 音乐视频生成:根据音乐生成相应的视频内容。
- 语音驱动的动画:根据语音输入生成动画。
示例:使用预训练的音频生成视频模型
from transformers import AudioToVideoPipeline
# 加载预训练的模型
pipeline = AudioToVideoPipeline.from_pretrained("facebook/audio-to-video-model")
# 读取音频文件
audio = "audio_sample.mp3"
# 生成视频
video = pipeline(audio).videos
# 保存视频
video[0].save("output_video.mp4")
26.4.1.4 多模态对话生成(Multimodal Dialogue Generation)
多模态对话生成是指根据文本和图像等多模态输入生成相应的对话回复。这项任务要求模型能够理解多模态输入的语义信息,并生成连贯且相关的对话内容。
应用场景:
- 智能客服:根据用户的多模态输入生成相应的回复。
- 虚拟助手:根据用户的文本和图像输入提供帮助。
示例:使用多模态对话生成模型
from transformers import MultiModalDialogueModel, MultiModalTokenizer
# 加载预训练的模型和tokenizer
tokenizer = MultiModalTokenizer.from_pretrained("microsoft/multimodal-dialogue-model")
model = MultiModalDialogueModel.from_pretrained("microsoft/multimodal-dialogue-model")
# 用户输入的文本和图像
text = "What is in the picture?"
image = "example.jpg"
# 预处理输入
inputs = tokenizer(text=text, images=image, return_tensors="pt")
# 生成回复
outputs = model.generate(**inputs)
reply = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(reply)
26.4.2. 实现方法
26.4.2.1 编码器-解码器架构(Encoder-Decoder Architecture)
许多多模态生成任务采用编码器-解码器架构,其中编码器负责将多模态输入编码为高维表示,解码器则根据这些表示生成目标内容。
示例:使用Transformer模型的编码器-解码器架构
from transformers import TransformerModel, TransformerTokenizer, TransformerForConditionalGeneration
# 加载预训练的模型和tokenizer
tokenizer = TransformerTokenizer.from_pretrained("t5-base")
model = TransformerForConditionalGeneration.from_pretrained("t5-base")
# 用户输入的文本和图像
text = "Describe this image"
image = "example.jpg"
# 预处理输入
inputs = tokenizer(text, return_tensors="pt")
image_inputs = ... # 预处理图像并转换为适当的格式
# 生成输出
outputs = model.generate(inputs.input_ids, encoder_hidden_states=image_features)
caption = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(caption)
26.4.2.2 对比学习(Contrastive Learning)
对比学习用于多模态生成任务中,以确保生成的内容与输入的多模态数据保持一致。
示例:使用对比损失进行训练
import torch
import torch.nn as nn
# 假设有图像特征和文本特征
image_features = torch.randn(10, 512)
text_features = torch.randn(10, 512)
# 计算相似度矩阵
similarity = torch.matmul(image_features, text_features.t())
# 计算对比损失
labels = torch.arange(10)
criterion = nn.CrossEntropyLoss()
loss = criterion(similarity, labels)
print(loss.item())
26.4.3. 应用场景
- 创意设计:根据文本描述生成创意图像或视频。
- 内容生成:为文章、故事生成插图或视频。
- 智能交互:根据用户的多模态输入生成相应的回复或内容。
- 辅助技术:为视觉或听觉障碍者提供多模态内容描述。
26.4.4. 综合示例
以下是一个综合的多模态生成示例,展示了如何使用预训练的多模态模型进行图像描述生成和文本生成图像。
from transformers import BlipProcessor, BlipForConditionalGeneration, DALL_E_Img2ImgPipeline
from PIL import Image
# 1. 图像描述生成
# 加载预训练的processor和模型
processor = BlipProcessor.from_pretrained("Salesforce/blip-image-captioning-base")
caption_model = BlipForConditionalGeneration.from_pretrained("Salesforce/blip-image-captioning-base")
# 读取图像
image = Image.open("example.jpg")
# 生成描述
inputs = processor(image, return_tensors="pt")
out = caption_model.generate(**inputs)
caption = processor.decode(out[0], skip_special_tokens=True)
print(f"图像描述: {caption}")
# 2. 文本生成图像
# 加载预训练的DALL-E模型
pipeline = DALL_E_Img2ImgPipeline.from_pretrained("dalle-mini/dalle-mini")
# 用户描述
text = "A beautiful sunset over the mountains"
# 生成图像
images = pipeline(text).images
# 显示图像
images[0].show()
26.4.5. 小结
基于多模态数据的生成任务是AI领域的前沿研究方向,通过结合多种模态的数据,生成新的内容,如图像描述、文本生成图像等。Python及其相关库提供了丰富的工具和功能,可以大大简化多模态生成任务的实现过程,提高工作效率。通过本章的学习,您将能够掌握基于多模态数据的生成任务的关键技术和实现方法,并将其应用于AI模型的实战中,实现更智能的多模态应用。
26.5 音频与视觉信息的联合处理
音频与视觉信息的联合处理是指将音频和视觉(图像或视频)数据结合起来进行分析和处理,以实现更复杂和更智能的任务。这种多模态处理方式能够充分利用音频和视觉信息的互补性,从而提升模型的理解能力和应用范围。以下将详细介绍音频与视觉信息联合处理的基本概念、主要应用场景以及关键技术,并通过具体示例展示如何进行音频与视觉信息的联合处理。
26.5.1. 基本概念
音频与视觉信息的联合处理旨在通过结合音频和视觉数据,实现对环境、事件或对象的更全面理解。例如:
- 视听同步(Audio-Visual Synchronization):将音频和视频同步,以确保声音和画面的一致性。
- 视听事件检测(Audio-Visual Event Detection):结合音频和视觉信息,检测特定事件的发生。
- 视听情感分析(Audio-Visual Emotion Recognition):结合音频和视觉信息,分析情感状态。
- 视听语音识别(Audio-Visual Speech Recognition):结合音频和视觉信息,提高语音识别的准确率。
26.5.2. 主要应用场景
26.5.2.1 视听同步
视听同步是指将音频和视频数据同步,以确保声音和画面的一致性。这在视频编辑、多媒体制作等领域有广泛应用。
示例:使用OpenCV和Librosa进行视听同步
import cv2
import librosa
import numpy as np
# 读取视频文件
video_path = 'video.mp4'
cap = cv2.VideoCapture(video_path)
# 读取音频文件
audio_path = 'audio.wav'
y, sr = librosa.load(audio_path, sr=None)
# 获取视频帧率
fps = cap.get(cv2.CAP_PROP_FPS)
video_duration = cap.get(cv2.CAP_PROP_FRAME_COUNT) / fps
# 获取音频时长
audio_duration = len(y) / sr
# 比较音频和视频时长
if abs(video_duration - audio_duration) > 1:
print("音频和视频时长不匹配")
else:
print("音频和视频时长匹配")
26.5.2.2 视听事件检测
视听事件检测是指结合音频和视觉信息,检测特定事件的发生。例如,在监控系统中,结合声音和图像信息检测异常事件。
示例:使用预训练的视听事件检测模型
from transformers import AutoModelForAudioVisualClassification, AutoFeatureExtractor
import torch
from PIL import Image
import librosa
import soundfile as sf
# 加载预训练的模型和特征提取器
model_name = "microsoft/avsr-base-avsr"
feature_extractor = AutoFeatureExtractor.from_pretrained(model_name)
model = AutoModelForAudioVisualClassification.from_pretrained(model_name)
# 读取图像和音频
image = Image.open("example.jpg")
audio, sr = librosa.load("example.wav", sr=16000)
audio = np.array(audio)
# 预处理数据
inputs = feature_extractor(images=image, audio=audio, return_tensors="pt", sampling_rate=sr)
# 进行推理
with torch.no_grad():
outputs = model(**inputs)
# 获取预测结果
predicted_class_id = outputs.logits.argmax().item()
predicted_class = model.config.id2label[predicted_class_id]
confidence = torch.softmax(outputs.logits, dim=1)[0][predicted_class_id].item()
print(f"预测事件: {predicted_class}, 置信度: {confidence}")
26.5.2.3 视听情感分析
视听情感分析是指结合音频和视觉信息,分析情感状态。例如,在人机交互中,结合面部表情和语音语调分析用户的情感。
示例:使用预训练的视听情感分析模型
from transformers import AutoModelForAudioVisualClassification, AutoFeatureExtractor
import torch
from PIL import Image
import librosa
import soundfile as sf
# 加载预训练的模型和特征提取器
model_name = "microsoft/avsr-base-avsr"
feature_extractor = AutoFeatureExtractor.from_pretrained(model_name)
model = AutoModelForAudioVisualClassification.from_pretrained(model_name)
# 读取图像和音频
image = Image.open("face.jpg")
audio, sr = librosa.load("voice.wav", sr=16000)
audio = np.array(audio)
# 预处理数据
inputs = feature_extractor(images=image, audio=audio, return_tensors="pt", sampling_rate=sr)
# 进行推理
with torch.no_grad():
outputs = model(**inputs)
# 获取预测结果
predicted_class_id = outputs.logits.argmax().item()
predicted_class = model.config.id2label[predicted_class_id]
confidence = torch.softmax(outputs.logits, dim=1)[0][predicted_class_id].item()
print(f"预测情感: {predicted_class}, 置信度: {confidence}")
26.5.2.4 视听语音识别
视听语音识别是指结合音频和视觉信息,提高语音识别的准确率。例如,在嘈杂环境中,结合唇部运动信息提高语音识别的准确性。
示例:使用预训练的视听语音识别模型
from transformers import Wav2Vec2Processor, Wav2Vec2ForAudioFrameClassification, AutoFeatureExtractor, AutoModelForAudioVisualClassification
import torch
import librosa
import soundfile as sf
from PIL import Image
# 加载预训练的音频和视觉模型
audio_processor = Wav2Vec2Processor.from_pretrained("facebook/wav2vec2-base-960h")
audio_model = Wav2Vec2ForAudioFrameClassification.from_pretrained("facebook/wav2vec2-base-960h")
visual_model = AutoModelForAudioVisualClassification.from_pretrained("microsoft/avsr-base-avsr")
visual_extractor = AutoFeatureExtractor.from_pretrained("microsoft/avsr-base-avsr")
# 读取音频和图像
audio, sr = librosa.load("voice.wav", sr=16000)
audio = np.array(audio)
image = Image.open("face.jpg")
# 预处理音频数据
inputs = audio_processor(audio, sampling_rate=sr, return_tensors="pt")
# 预处理视觉数据
visual_inputs = visual_extractor(images=image, return_tensors="pt")
# 进行推理
with torch.no_grad():
audio_outputs = audio_model(**inputs)
visual_outputs = visual_model(**visual_inputs)
# 结合音频和视觉信息进行最终预测
# 这里需要根据具体模型进行融合
# ...
print("预测结果")
26.5.3. 关键技术
26.5.3.1 多模态融合
多模态融合是指将来自不同模态的数据进行整合,以充分利用各模态的互补信息。常见的融合方法包括:
- 早期融合(Early Fusion):在数据层面进行融合,如将音频和视觉特征直接拼接。
- 中期融合(Middle Fusion):在特征层面进行融合,如使用注意力机制进行跨模态特征融合。
- 晚期融合(Late Fusion):在决策层面进行融合,如对不同模态的预测结果进行加权融合。
26.5.3.2 跨模态注意力机制
跨模态注意力机制用于捕捉不同模态之间的复杂关系。例如,在视听事件检测中,使用注意力机制将音频和视觉特征进行加权融合。
26.5.3.3 多模态表示学习
多模态表示学习是指学习不同模态数据的共同表示空间,使得不同模态的数据在表示空间中具有相似的分布。这有助于模型更好地理解和处理多模态数据。
26.5.4. 总结
音频与视觉信息的联合处理是AI领域的重要研究方向,通过结合音频和视觉数据,可以实现更全面、更深入的理解和分析。Python及其相关库提供了丰富的工具和功能,可以大大简化音频与视觉信息联合处理的实现过程,提高工作效率。通过本章的学习,您将能够掌握音频与视觉信息联合处理的关键技术和实现方法,并将其应用于AI模型的实战中,实现更智能的多模态应用。
26.6 实战案例:构建一个简单的多模态交互系统
在本节中,我们将通过一个完整的实战案例,展示如何构建一个简单的多模态交互系统。该系统能够处理用户的文本和图像输入,进行综合分析,并生成相应的回复或执行特定任务。以下是详细的步骤和代码示例,涵盖了数据准备、模型选择、系统集成以及部署等环节。
26.6.1. 项目概述
项目目标:构建一个多模态交互系统,能够处理用户的文本和图像输入,进行情感分析、图像描述生成、视觉问答等任务,并根据用户需求提供相应的服务。
主要功能:
1.情感分析:结合文本和图像信息,分析用户的情感状态(正面、负面、中性)。
2.图像描述生成:根据用户上传的图像生成描述性文本。
3.视觉问答(VQA):根据用户上传的图像和提出的问题,生成相应的答案。
4.多模态对话:根据用户的文本和图像输入,生成相应的回复或执行特定任务。
26.6.2. 数据准备
26.6.2.1 数据收集
收集多模态数据,包括:
- 图像数据:从公开数据集(如COCO、ImageNet)或自定义数据集中获取图像。
- 文本数据:从公开对话数据集(如Cornell Movie Dialogs、Ubuntu Dialogue Corpus)或自定义数据集中获取文本数据。
- 多模态数据:结合图像和文本数据,构建多模态数据集。
示例:读取多模态数据
import pandas as pd
# 读取数据
df = pd.read_csv('multimodal_data.csv')
# 查看数据
print(df.head())
26.6.2.2 数据清洗
对收集到的数据进行清洗,包括:
- 文本预处理:如分词、去停用词、去除特殊字符等。
- 图像预处理:如调整图像大小、归一化等。
- 数据对齐:确保文本和图像数据对齐。
示例:数据清洗
import re
from PIL import Image
import requests
def clean_text(text):
# 转换为小写
text = text.lower()
# 去除特殊字符
text = re.sub(r'[^a-zA-Z0-9\s]', '', text)
# 去除多余空格
text = re.sub(r'\s+', ' ', text).strip()
return text
def load_image(url):
try:
image = Image.open(requests.get(url, stream=True).raw)
return image
except:
return None
df['clean_text'] = df['text'].apply(clean_text)
df['image'] = df['image_url'].apply(load_image)
26.6.2.3 数据标注
根据项目需求,对数据进行标注:
- 情感标签:如“正面”、“负面”、“中性”。
- 图像描述:为图像生成描述性文本。
- 问答对:为图像和问题生成相应的问答对。
示例:添加情感标签
# 假设已有情感标签列 'sentiment'
# 如果没有,需要进行人工标注或使用预训练模型进行预测
26.6.3. 模型选择与训练
26.6.3.1 情感分析模型
使用预训练的CLIP模型进行多模态情感分析。
示例:情感分析模型
from transformers import CLIPProcessor, CLIPModel
from PIL import Image
import torch
# 加载预训练的CLIP模型和processor
processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32")
model = CLIPModel.from_pretrained("openai/clip-vit-base-patch32")
def analyze_sentiment(text, image):
inputs = processor(text=text, images=image, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs)
logits_per_image = outputs.logits_per_image # (1, num_labels)
probs = logits_per_image.softmax(dim=1)
return probs
# 示例
text = "I am so happy with this product!"
image = Image.open("example.jpg")
probs = analyze_sentiment(text, image)
print(probs)
26.6.3.2 图像描述生成模型
使用预训练的Blip模型进行图像描述生成。
示例:图像描述生成模型
from transformers import BlipProcessor, BlipForConditionalGeneration
from PIL import Image
# 加载预训练的processor和模型
processor = BlipProcessor.from_pretrained("Salesforce/blip-image-captioning-base")
model = BlipForConditionalGeneration.from_pretrained("Salesforce/blip-image-captioning-base")
def generate_caption(image):
inputs = processor(images=image, return_tensors="pt")
out = model.generate(**inputs)
caption = processor.decode(out[0], skip_special_tokens=True)
return caption
# 示例
image = Image.open("example.jpg")
caption = generate_caption(image)
print(caption)
26.6.3.3 视觉问答(VQA)模型
使用预训练的Lxmert模型进行视觉问答。
示例:视觉问答模型
from transformers import LxmertTokenizer, LxmertForQuestionAnswering
from PIL import Image
import requests
# 加载预训练的tokenizer和模型
tokenizer = LxmertTokenizer.from_pretrained('unc-nlp/lxmert-base-uncased')
model = LxmertForQuestionAnswering.from_pretrained('unc-nlp/lxmert-base-uncased')
def visual_question_answering(image_url, question):
image = Image.open(requests.get(image_url, stream=True).raw)
inputs = tokenizer(question, return_tensors="pt")
inputs.update({'image': image})
outputs = model(**inputs)
answer = tokenizer.decode(outputs.logits.argmax(dim=-1)[0], skip_special_tokens=True)
return answer
# 示例
image_url = "http://example.com/image.jpg"
question = "What is in the image?"
answer = visual_question_answering(image_url, question)
print(answer)
26.6.4. 系统集成
26.6.4.1 创建API服务
使用FastAPI创建API服务,将各个模型封装为RESTful API。
示例:使用FastAPI创建API服务
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel
from transformers import BlipProcessor, BlipForConditionalGeneration, CLIPProcessor, CLIPModel, LxmertTokenizer, LxmertForQuestionAnswering
from PIL import Image
import torch
app = FastAPI()
# 加载模型和tokenizer
blip_processor = BlipProcessor.from_pretrained("Salesforce/blip-image-captioning-base")
blip_model = BlipForConditionalGeneration.from_pretrained("Salesforce/blip-image-captioning-base")
clip_processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32")
clip_model = CLIPModel.from_pretrained("openai/clip-vit-base-patch32")
lxmert_tokenizer = LxmertTokenizer.from_pretrained('unc-nlp/lxmert-base-uncased')
lxmert_model = LxmertForQuestionAnswering.from_pretrained('unc-nlp/lxmert-base-uncased')
class TextImageInput(BaseModel):
text: str
image_url: str
@app.post("/analyze_sentiment")
async def analyze_sentiment(input: TextImageInput):
image = Image.open(requests.get(input.image_url, stream=True).raw)
inputs = clip_processor(text=input.text, images=image, return_tensors="pt")
with torch.no_grad():
outputs = clip_model(**inputs)
probs = outputs.logits_per_image.softmax(dim=1)
return {"probs": probs.tolist()}
@app.post("/generate_caption")
async def generate_caption(image_url: str):
image = Image.open(requests.get(image_url, stream=True).raw)
inputs = blip_processor(images=image, return_tensors="pt")
with torch.no_grad():
outputs = blip_model.generate(**inputs)
caption = blip_processor.decode(outputs[0], skip_special_tokens=True)
return {"caption": caption}
@app.post("/visual_question_answering")
async def visual_question_answering(image_url: str, question: str):
image = Image.open(requests.get(image_url, stream=True).raw)
inputs = lxmert_tokenizer(question, return_tensors="pt")
inputs.update({'image': image})
with torch.no_grad():
outputs = lxmert_model(**inputs)
answer = lxmert_tokenizer.decode(outputs.logits.argmax(dim=-1)[0], skip_special_tokens=True)
return {"answer": answer}
# 运行API服务
# uvicorn main:app --host 0.0.0.0 --port 8000
26.6.4.2 容器化与部署
使用Docker将API服务容器化,并部署到云服务平台(如AWS, GCP, Azure)。
示例:Dockerfile
FROM python:3.8-slim
WORKDIR /app
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
COPY . .
EXPOSE 8000
CMD ["uvicorn", "main:app", "--host", "0.0.0.0", "--port", "8000"]
构建镜像:
docker build -t my-multimodal-service .
运行容器:
docker run -d -p 8000:8000 my-multimodal-service
26.6.5. 监控与维护
26.6.5.1 模型监控
实时监控模型的性能指标,如准确率、延迟、吞吐量等,及时发现和解决问题。
示例:使用Prometheus和Grafana进行监控
from prometheus_client import start_http_server, Summary, Gauge
# 定义指标
REQUEST_TIME = Summary('request_processing_seconds', 'Time spent processing request')
# 监控函数
@REQUEST_TIME.time()
def analyze_sentiment(text, image):
# 模型推理
...
# 启动HTTP服务器
start_http_server(8001)
26.6.5.2 模型更新
根据监控结果和业务需求,定期更新模型,确保其持续保持高性能。
示例:自动化模型更新流程
# 定期运行更新脚本
cronjob: "0 0 * * *" # 每天午夜运行
script: python update_model.py
26.6.6. 小结
通过本案例的实践,您将能够掌握从数据准备到模型部署的完整流程,并将其应用于实际的多模态交互系统中。Python及其相关库提供了丰富的工具和功能,可以大大简化多模态交互系统的实现过程,提高工作效率。通过本章的学习,您将能够构建出高效、智能的多模态交互系统,实现更智能的多模态应用。
第二十七章:AI模型的部署与上线
- 从训练到生产:如何将AI模型部署为Web服务
- 模型优化与加速:提高推理效率
- 容器化与微服务架构
- 监控与维护:确保服务的稳定性和可靠性
- 安全考量与隐私保护
27.1 从训练到生产:如何将AI模型部署为Web服务
将AI模型从训练阶段成功迁移到生产环境,并将其部署为Web服务,是实现AI应用的关键步骤。这一过程不仅涉及模型的部署,还包括如何处理请求、返回响应以及确保服务的稳定性和可扩展性。以下将详细介绍如何将AI模型部署为Web服务,并通过具体示例展示实现方法。
27.1.1. 部署流程概述
将AI模型部署为Web服务通常包括以下几个步骤:
1.模型选择与训练:选择合适的模型并进行训练,确保模型在验证集和测试集上表现良好。
2.模型序列化:将训练好的模型保存到磁盘,以便在生产环境中加载和使用。
3.创建API服务:使用Web框架(如Flask、FastAPI、Django等)创建API接口,接收用户请求并返回模型预测结果。
4.环境配置:配置生产环境,包括依赖管理、服务器配置等。
5.容器化与部署:使用容器化技术(如Docker)和云服务平台(如AWS、GCP、Azure)将服务部署到生产环境。
6.监控与维护:实时监控服务的性能和健康状态,及时发现和解决问题。
27.1.2. 模型序列化
模型序列化是指将训练好的模型保存到磁盘,以便在生产环境中加载和使用。常用的序列化格式包括:
- Pickle:Python内置的序列化库,简单易用。
- TorchScript:PyTorch提供的序列化格式,支持跨平台和优化。
- ONNX:开放神经网络交换格式,支持多种深度学习框架。
- SavedModel:TensorFlow提供的序列化格式。
示例:使用TorchScript序列化PyTorch模型
import torch
import torch.nn as nn
# 定义简单的模型
class SimpleModel(nn.Module):
def __init__(self):
super(SimpleModel, self).__init__()
self.fc = nn.Linear(10, 2)
def forward(self, x):
return self.fc(x)
model = SimpleModel()
model.eval()
# 使用TorchScript序列化模型
scripted_model = torch.jit.script(model)
scripted_model.save("model.pt")
27.1.3. 创建API服务
使用Web框架创建API接口,接收用户请求并返回模型预测结果。常用的Web框架包括:
- Flask:轻量级Web框架,简单易用。
- FastAPI:现代、快速(高性能)的Web框架,支持异步编程。
- Django:功能强大的Web框架,适合大型项目。
示例:使用FastAPI创建API服务
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel
import torch
import torch.nn as nn
from transformers import AutoTokenizer, AutoModelForSequenceClassification
from PIL import Image
import requests
app = FastAPI()
# 加载模型和tokenizer
tokenizer = AutoTokenizer.from_pretrained('bert-base-uncased')
model = AutoModelForSequenceClassification.from_pretrained('bert-base-uncased', num_labels=2)
model.load_state_dict(torch.load("model.pt"))
model.eval()
# 定义请求体
class TextInput(BaseModel):
text: str
@app.post("/predict")
async def predict(input: TextInput):
inputs = tokenizer.encode(input.text, return_tensors='pt', truncation=True, padding=True)
with torch.no_grad():
outputs = model(inputs)
logits = outputs.logits
prediction = torch.argmax(logits, dim=1).item()
return {"prediction": prediction}
# 运行API服务
# uvicorn main:app --host 0.0.0.0 --port 8000
27.1.4. 环境配置
在生产环境中,需要配置好依赖管理和服务器环境,以确保服务的稳定性和可扩展性。以下是一些常见的配置步骤:
- 依赖管理:使用
requirements.txt或Pipfile管理Python依赖。 - 虚拟环境:使用虚拟环境(如venv、conda)隔离项目依赖。
- 服务器配置:配置服务器操作系统、安装必要的软件(如Python、Git、Docker等)。
示例:创建requirements.txt
fastapi
uvicorn
torch
transformers
pillow
requests
27.1.5. 容器化与部署
使用容器化技术(如Docker)将应用及其依赖打包成容器镜像,并部署到云服务平台(如AWS、GCP、Azure)。容器化具有以下优点:
- 一致性:确保开发和生产环境的一致性。
- 可移植性:可以在任何支持Docker的环境中运行。
- 可扩展性:方便地进行水平扩展和负载均衡。
示例:使用Docker部署API服务
FROM python:3.8-slim
WORKDIR /app
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
COPY . .
EXPOSE 8000
CMD ["uvicorn", "main:app", "--host", "0.0.0.0", "--port", "8000"]
构建Docker镜像:
docker build -t my-ai-service .
运行Docker容器:
docker run -d -p 8000:8000 my-ai-service
27.1.6. 监控与维护
部署到生产环境后,需要实时监控服务的性能和健康状态,及时发现和解决问题。常用的监控工具包括:
- Prometheus:开源的监控系统和时间序列数据库。
- Grafana:开源的可视化平台,用于监控和分析。
- ELK Stack:Elasticsearch、Logstash、Kibana,用于日志管理和分析。
示例:使用Prometheus进行监控
from prometheus_client import start_http_server, Summary, Gauge
# 定义指标
REQUEST_TIME = Summary('request_processing_seconds', 'Time spent processing request')
# 监控函数
@REQUEST_TIME.time()
def predict(text):
# 模型推理
...
# 启动HTTP服务器
start_http_server(8001)
27.1.7. 总结
将AI模型部署为Web服务是实现AI应用的重要步骤。通过合理的模型序列化、API服务创建、环境配置、容器化与部署以及监控与维护,可以确保AI模型在生产环境中的稳定性和可靠性。Python及其相关库提供了丰富的工具和功能,可以大大简化AI模型的部署过程,提高工作效率。通过本章的学习,您将能够掌握将AI模型部署为Web服务的方法,并将其应用于实际项目中,实现更智能的AI应用。
27.2 模型优化与加速:提高推理效率
将AI模型部署到生产环境后,推理效率(即模型处理请求的速度)是一个关键考量因素。高效的推理不仅能提升用户体验,还能降低计算资源成本。为了实现这一点,通常需要对模型进行优化与加速。以下将详细介绍几种常见的模型优化与加速方法,并通过具体示例展示如何实现这些优化。
27.2.1. 模型优化与加速的主要方法
27.2.1.1 模型剪枝(Model Pruning)
模型剪枝是指移除模型中不重要的参数或神经元,以减少模型大小和计算量,同时保持或略微降低模型性能。剪枝可以分为权重剪枝(Weight Pruning)和结构化剪枝(Structured Pruning)。
- 权重剪枝:移除单个权重或神经元。
- 结构化剪枝:移除整个层或通道。
优点:
- 减少模型大小,降低存储需求。
- 加快推理速度。
缺点:
- 可能导致模型性能下降。
- 需要重新训练或微调模型。
示例:使用PyTorch进行模型剪枝
import torch
import torch.nn.utils.prune as prune
# 假设model是已经训练好的模型
model = ... # 加载模型
# 对卷积层的权重进行剪枝
for name, module in model.named_modules():
if isinstance(module, torch.nn.Conv2d):
prune.l1_unstructured(module, name='weight', amount=0.2)
# 移除剪枝后的参数
model = prune.remove(model, 'weight')
27.2.1.2 模型量化(Model Quantization)
模型量化是指将模型中的参数和激活值从高精度(如32位浮点数)转换为低精度(如8位整数),以减少内存占用和计算量。量化可以分为动态量化(Dynamic Quantization)和静态量化(Static Quantization)。
- 动态量化:在推理时进行量化。
- 静态量化:在训练后进行量化,并使用校准数据进行调整。
优点:
- 显著减少模型大小。
- 提高推理速度,尤其是在支持低精度计算的硬件上。
缺点:
- 可能导致模型性能下降。
- 需要进行量化感知训练(Quantization-Aware Training)以减少性能损失。
示例:使用PyTorch进行动态量化
import torch
import torch.quantization
# 假设model是已经训练好的模型
model = ... # 加载模型
# 设置模型为量化感知训练模式
model.train()
model = torch.quantization.prepare(model)
# 进行量化感知训练(可选)
# 转换为量化模型
model.eval()
model = torch.quantization.convert(model)
# 保存量化模型
torch.save(model.state_dict(), "quantized_model.pt")
27.2.1.3 知识蒸馏(Knowledge Distillation)
知识蒸馏是指将一个大模型的“知识”迁移到一个小模型中,通过训练小模型来模仿大模型的输出,从而提高小模型的性能。知识蒸馏可以用于模型压缩和加速。
优点:
- 可以生成性能接近大模型的小模型。
- 提高推理速度,降低计算资源需求。
缺点:
- 需要额外的训练步骤。
- 可能需要更多的数据。
示例:使用知识蒸馏进行模型压缩
import torch
import torch.nn as nn
import torch.optim as optim
# 定义教师模型和学生模型
teacher_model = ... # 加载预训练的教师模型
student_model = ... # 定义小模型
# 定义损失函数
criterion = nn.KLDivLoss()
# 定义优化器
optimizer = optim.Adam(student_model.parameters(), lr=1e-4)
# 知识蒸馏训练过程
for epoch in range(num_epochs):
for inputs, labels in dataloader:
optimizer.zero_grad()
teacher_outputs = teacher_model(inputs)
student_outputs = student_model(inputs)
loss = criterion(student_outputs, teacher_outputs)
loss.backward()
optimizer.step()
27.2.1.4 使用高效的推理引擎
使用高效的推理引擎(如TensorRT、ONNX Runtime、OpenVINO等)可以显著提高模型的推理速度。这些引擎通常支持硬件加速(如GPU、FPGA)和低精度计算。
示例:使用ONNX Runtime进行推理加速
import torch
import onnxruntime
import numpy as np
# 加载PyTorch模型并转换为ONNX格式
model = ... # 加载PyTorch模型
model.eval()
dummy_input = torch.randn(1, 3, 224, 224)
torch.onnx.export(model, dummy_input, "model.onnx", opset_version=11)
# 使用ONNX Runtime进行推理
ort_session = onnxruntime.InferenceSession("model.onnx")
def inference(input_data):
ort_inputs = {ort_session.get_inputs()[0].name: input_data.numpy()}
ort_outs = ort_session.run(None, ort_inputs)
return torch.tensor(ort_outs[0])
# 示例推理
input_data = torch.randn(1, 3, 224, 224)
output = inference(input_data)
print(output)
27.2.2. 综合示例
以下是一个综合的模型优化与加速示例,展示了如何使用PyTorch进行模型剪枝、量化,并使用ONNX Runtime进行推理加速。
import torch
import torch.nn as nn
import torch.quantization
import onnxruntime
import numpy as np
# 1. 定义模型
class SimpleModel(nn.Module):
def __init__(self):
super(SimpleModel, self).__init__()
self.conv = nn.Conv2d(3, 16, kernel_size=3)
self.relu = nn.ReLU()
self.fc = nn.Linear(16 * 222 * 222, 2)
def forward(self, x):
x = self.relu(self.conv(x))
x = x.view(x.size(0), -1)
x = self.fc(x)
return x
model = SimpleModel()
# 2. 模型剪枝
for name, module in model.named_modules():
if isinstance(module, nn.Conv2d):
prune.l1_unstructured(module, name='weight', amount=0.2)
# 3. 模型量化
model.train()
model = torch.quantization.prepare(model)
# 进行量化感知训练(可选)
model.eval()
model = torch.quantization.convert(model)
# 4. 转换为ONNX格式
dummy_input = torch.randn(1, 3, 224, 224)
torch.onnx.export(model, dummy_input, "model.onnx", opset_version=11)
# 5. 使用ONNX Runtime进行推理
ort_session = onnxruntime.InferenceSession("model.onnx")
def inference(input_data):
ort_inputs = {ort_session.get_inputs()[0].name: input_data.numpy()}
ort_outs = ort_session.run(None, ort_inputs)
return torch.tensor(ort_outs[0])
# 6. 示例推理
input_data = torch.randn(1, 3, 224, 224)
output = inference(input_data)
print(output)
27.2.3. 小结
模型优化与加速是提高AI模型推理效率的重要手段。通过合理的模型剪枝、量化、知识蒸馏以及使用高效的推理引擎,可以显著提升模型的推理速度,降低计算资源需求。Python及其相关库提供了丰富的工具和功能,可以大大简化模型优化与加速的实现过程,提高工作效率。
27.3 容器化与微服务架构
容器化和微服务架构是现代软件开发和部署中的重要概念,尤其在AI模型的部署中,它们能够显著提高系统的可扩展性、可维护性和可靠性。以下将详细介绍容器化与微服务架构的基本概念、优势以及实现方法,并通过具体示例展示如何将AI模型部署到容器化环境中,并构建一个基于微服务架构的应用。
27.3.1. 容器化
27.3.1.1 容器化的基本概念
容器化是指将应用程序及其所有依赖项打包到一个独立的、隔离的单元(称为容器)中。容器化技术确保应用程序在任何环境中都能一致地运行,解决了“在我的机器上可以运行”的问题。Docker是目前最流行的容器化平台。
27.3.1.2 容器化的优势
- 一致性:确保开发和生产环境的一致性,避免“在我的机器上可以运行”的问题。
- 可移植性:容器可以在任何支持容器化技术的环境中运行,如本地机器、云服务器等。
- 隔离性:不同容器之间相互隔离,提高了系统的安全性和稳定性。
- 资源效率:容器比虚拟机更轻量,占用资源更少,启动速度更快。
27.3.1.3 使用Docker进行容器化
步骤:
1.编写Dockerfile:定义容器镜像的构建过程。
2.构建镜像:使用docker build命令构建容器镜像。
3.运行容器:使用docker run命令运行容器。
示例:使用Docker容器化AI模型
假设我们有一个使用FastAPI构建的AI模型API服务,代码保存在main.py中。
Dockerfile:
# 使用官方Python镜像作为基础镜像
FROM python:3.8-slim
# 设置工作目录
WORKDIR /app
# 复制依赖文件并安装依赖
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
# 复制应用代码
COPY . .
# 暴露端口
EXPOSE 8000
# 运行应用
CMD ["uvicorn", "main:app", "--host", "0.0.0.0", "--port", "8000"]
requirements.txt:
fastapi
uvicorn
torch
transformers
pillow
requests
构建Docker镜像:
docker build -t my-ai-service .
运行Docker容器:
docker run -d -p 8000:8000 my-ai-service
27.3.2. 微服务架构
27.3.2.1 微服务架构的基本概念
微服务架构是一种软件架构风格,它将应用程序拆分为一组小型、独立的服务,每个服务运行在自己的进程中,服务之间通过轻量级的通信机制(如HTTP/REST、gRPC等)进行交互。微服务架构具有以下特点:
- 独立性:每个服务可以独立开发、部署和扩展。
- 模块化:应用程序被拆分为多个模块,每个模块负责特定的功能。
- 可扩展性:可以根据需要独立扩展每个服务,提高资源利用率。
27.3.2.2 微服务架构的优势
- 灵活性:每个服务可以采用不同的技术栈和技术方案。
- 可维护性:单个服务的代码库更小,更易于理解和维护。
- 可扩展性:可以根据负载独立扩展每个服务,提高系统性能。
- 容错性:单个服务的故障不会影响整个系统,提高系统的可靠性。
27.3.2.3 构建基于微服务架构的AI应用
步骤:
1.拆分服务:将AI应用拆分为多个独立的服务,如模型推理服务、数据处理服务、用户管理服务等。
2.定义API接口:为每个服务定义清晰的API接口,使用RESTful API或gRPC等通信协议。
3.部署服务:使用容器化技术(如Docker)将每个服务部署到容器中,并使用容器编排工具(如Kubernetes)进行管理。
4.服务通信:使用API网关(如NGINX、Kong)或服务发现机制(如Consul、etcd)实现服务之间的通信。
示例:构建一个简单的微服务架构AI应用
假设我们有一个AI应用,包含以下服务:
- 模型推理服务(Inference Service):提供模型推理API。
- 数据处理服务(Data Processing Service):处理输入数据,如数据清洗、预处理等。
- 用户管理服务(User Management Service):管理用户信息,如用户注册、登录等。
Dockerfile for Inference Service:
FROM python:3.8-slim
WORKDIR /app
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
COPY . .
EXPOSE 8000
CMD ["uvicorn", "inference_service:app", "--host", "0.0.0.0", "--port", "8000"]
Dockerfile for Data Processing Service:
FROM python:3.8-slim
WORKDIR /app
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
COPY . .
EXPOSE 8001
CMD ["uvicorn", "data_processing_service:app", "--host", "0.0.0.0", "--port", "8001"]
Dockerfile for User Management Service:
FROM python:3.8-slim
WORKDIR /app
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
COPY . .
EXPOSE 8002
CMD ["uvicorn", "user_management_service:app", "--host", "0.0.0.0", "--port", "8002"]
运行容器:
docker build -t inference-service ./inference_service
docker build -t data-processing-service ./data_processing_service
docker build -t user-management-service ./user_management_service
docker run -d -p 8000:8000 inference-service
docker run -d -p 8001:8001 data-processing-service
docker run -d -p 8002:8002 user-management-service
服务通信:
使用API网关(如NGINX)将请求路由到相应的服务。
示例:NGINX配置
server {
listen 80;
server_name example.com;
location /inference/ {
proxy_pass http://localhost:8000/;
}
location /data-processing/ {
proxy_pass http://localhost:8001/;
}
location /user-management/ {
proxy_pass http://localhost:8002/;
}
}
27.3.3. 小结
容器化与微服务架构是实现现代化AI应用的重要手段。通过容器化,可以确保应用的一致性和可移植性;通过微服务架构,可以提高系统的灵活性和可扩展性。Python及其相关库提供了丰富的工具和功能,可以大大简化容器化和微服务架构的实现过程,提高工作效率。通过本章的学习,您将能够掌握容器化与微服务架构的关键技术和实现方法,并将其应用于AI模型的实战中,实现更高效、更可靠的AI应用。
27.4 监控与维护:确保服务的稳定性和可靠性
将AI模型部署到生产环境后,监控与维护是确保服务稳定性和可靠性的关键环节。有效的监控可以帮助及时发现和解决问题,优化系统性能,并确保用户体验。以下将详细介绍AI模型部署后的监控与维护策略、常用工具以及实现方法,并通过具体示例展示如何进行有效的监控与维护。
27.4.1. 监控与维护的重要性
- 性能监控:确保模型推理速度、延迟和吞吐量符合预期,避免因性能问题影响用户体验。
- 健康监控:实时监测服务的健康状态,及时发现和修复故障,防止服务中断。
- 资源监控:监控CPU、内存、磁盘等资源的使用情况,优化资源配置,避免资源瓶颈。
- 模型性能监控:监控模型在实际环境中的表现,防止模型漂移(Model Drift)和数据漂移(Data Drift)导致的性能下降。
- 日志管理:收集和分析日志信息,帮助诊断问题和优化系统。
27.4.2. 常用的监控指标
27.4.2.1 性能指标
- 延迟(Latency):请求从发送到接收响应的时间。
- 吞吐量(Throughput):单位时间内处理的请求数量。
- 错误率(Error Rate):请求失败的百分比。
27.4.2.2 资源指标
- CPU使用率:CPU的使用情况。
- 内存使用率:内存的使用情况。
- 磁盘使用率:磁盘的使用情况。
- 网络带宽:网络流量的使用情况。
27.4.2.3 模型指标
- 推理准确率(Inference Accuracy):模型推理的准确程度。
- 预测置信度(Prediction Confidence):模型对预测结果的置信程度。
- 模型漂移(Model Drift):模型在实际环境中的表现与训练时的差异。
27.4.3. 常用的监控工具
27.4.3.1 Prometheus
Prometheus是一个开源的监控系统和时间序列数据库,支持多维数据模型和强大的查询语言(PromQL)。它可以收集和存储指标数据,并通过Grafana等可视化工具进行展示。
示例:使用Prometheus监控AI服务
from prometheus_client import start_http_server, Summary, Gauge
import time
import random
# 定义指标
REQUEST_TIME = Summary('request_processing_seconds', 'Time spent processing request')
CPU_USAGE = Gauge('cpu_usage_percent', 'CPU usage percentage')
MEMORY_USAGE = Gauge('memory_usage_mb', 'Memory usage in MB')
# 模拟CPU和内存使用
def simulate_resource_usage():
CPU_USAGE.set(random.uniform(10, 90))
MEMORY_USAGE.set(random.uniform(100, 500))
# 监控函数
@REQUEST_TIME.time()
def predict(input_data):
# 模拟模型推理
time.sleep(random.uniform(0.1, 0.5))
return random.randint(0, 1)
# 启动HTTP服务器
start_http_server(8001)
while True:
input_data = ... # 获取输入数据
prediction = predict(input_data)
simulate_resource_usage()
time.sleep(1)
27.4.3.2 Grafana
Grafana是一个开源的可视化平台,可以与Prometheus等数据源集成,用于创建仪表盘和监控面板。
示例:使用Grafana创建监控仪表盘
1.安装Grafana:根据官方文档安装Grafana。
2.配置数据源:在Grafana中添加Prometheus作为数据源。
3.创建仪表盘:使用PromQL查询语言创建图表,展示CPU使用率、内存使用率、请求延迟等指标。
27.4.3.3 ELK Stack
ELK Stack(Elasticsearch、Logstash、Kibana)是一个用于日志管理和分析的集成解决方案。
- Elasticsearch:分布式搜索和分析引擎,用于存储和索引日志数据。
- Logstash:数据收集引擎,用于收集、转换和发送日志数据。
- Kibana:可视化平台,用于搜索、查看和分析日志数据。
示例:使用ELK Stack收集和分析日志
1.安装ELK组件:根据官方文档安装Elasticsearch、Logstash和Kibana。
2.配置Logstash:配置Logstash以收集AI服务的日志数据。
3.启动Elasticsearch和Kibana:启动Elasticsearch和Kibana服务。
4.创建Kibana仪表盘:使用Kibana创建仪表盘,展示和分析日志数据。
27.4.4. 模型性能监控与维护
27.4.4.1 模型漂移检测
模型漂移是指模型在实际环境中的表现与训练时的差异。可以通过以下方法检测模型漂移:
- 定期评估:定期使用新数据评估模型性能。
- 实时监控:实时监控模型预测结果与真实标签的差异。
- 统计方法:使用统计方法检测数据分布的变化。
示例:使用统计方法检测模型漂移
import numpy as np
from scipy.stats import wasserstein_distance
# 训练集和实时数据的特征分布
train_features = np.random.normal(loc=0, scale=1, size=1000)
live_features = np.random.normal(loc=0.5, scale=1.5, size=1000)
# 计算Wasserstein距离
distance = wasserstein_distance(train_features, live_features)
print(f'Wasserstein距离: {distance}')
# 判断是否发生漂移
if distance > threshold:
print('检测到模型漂移')
else:
print('未检测到模型漂移')
27.4.4.2 模型再训练与更新
当检测到模型漂移时,需要对模型进行再训练和更新:
1.收集新数据:收集新数据以反映当前的数据分布。
2.数据预处理:对新数据进行预处理,如清洗、特征提取等。
3.模型再训练:使用新数据对模型进行再训练。
4.模型验证:评估再训练后的模型性能。
5.模型部署:将更新后的模型部署到生产环境。
示例:模型再训练与更新
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDataset
# 定义模型
class SimpleModel(nn.Module):
def __init__(self):
super(SimpleModel, self).__init__()
self.fc = nn.Linear(10, 2)
def forward(self, x):
return self.fc(x)
model = SimpleModel()
# 加载新数据
new_data = ... # 加载新数据
new_labels = ... # 加载新标签
dataset = TensorDataset(torch.tensor(new_data), torch.tensor(new_labels))
dataloader = DataLoader(dataset, batch_size=32, shuffle=True)
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=1e-3)
# 模型再训练
for epoch in range(num_epochs):
for inputs, labels in dataloader:
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# 保存更新后的模型
torch.save(model.state_dict(), "updated_model.pt")
27.4.5. 小结
监控与维护是AI模型部署后不可或缺的一部分。通过有效的监控,可以及时发现和解决问题,优化系统性能,确保服务的稳定性和可靠性。Python及其相关库提供了丰富的工具和功能,可以大大简化监控与维护的实现过程,提高工作效率。通过本章的学习,您将能够掌握AI模型部署后的监控与维护策略和实现方法,并将其应用于AI模型的实战中,实现更稳定、更可靠的服务。
27.5 安全考量与隐私保护
在将AI模型部署到生产环境时,安全考量与隐私保护是至关重要的环节。确保系统的安全性不仅能保护用户数据,还能防止恶意攻击,确保服务的可靠性和用户信任。以下将详细介绍AI模型部署中的主要安全风险、防护措施以及隐私保护方法,并通过具体示例展示如何实现安全部署。
27.5.1. 主要安全风险
27.5.1.1 数据泄露
数据泄露是指未经授权的个人或组织获取了敏感数据。这可能由于安全漏洞、配置错误或恶意攻击导致。
27.5.1.2 恶意攻击
- 注入攻击(Injection Attacks):攻击者通过注入恶意代码或数据来操控应用程序,如SQL注入、命令注入等。
- 跨站脚本攻击(XSS):攻击者在网页中注入恶意脚本,窃取用户信息或操控用户会话。
- 拒绝服务攻击(DoS/DDoS):攻击者通过大量请求使服务无法正常响应。
27.5.1.3 模型窃取
模型窃取是指攻击者通过查询接口获取模型参数或内部工作机制,从而复制或逆向工程模型。
27.5.1.4 隐私泄露
隐私泄露是指用户的敏感信息(如个人身份信息、健康记录等)被未经授权的第三方获取。
27.5.2. 防护措施
27.5.2.1 数据加密
数据加密是保护数据安全的基本措施,包括:
- 传输中加密(Encryption in Transit):使用SSL/TLS协议加密传输中的数据。
- 存储中加密(Encryption at Rest):对存储在数据库或文件系统中的数据进行加密。
示例:使用HTTPS确保数据传输安全
from fastapi import FastAPI
import uvicorn
app = FastAPI()
@app.get("/")
def read_root():
return {"Hello": "World"}
if __name__ == "__main__":
uvicorn.run(app, host="0.0.0.0", port=8000, ssl_keyfile="key.pem", ssl_certfile="cert.pem")
27.5.2.2 身份验证与授权
身份验证(Authentication)和授权(Authorization)用于验证用户身份和控制用户访问权限。
- 身份验证:确认用户身份,如使用用户名和密码、JWT令牌等。
- 授权:控制用户对资源的访问权限,如基于角色的访问控制(RBAC)。
示例:使用JWT进行身份验证
from fastapi import FastAPI, Depends, HTTPException
from fastapi.security import OAuth2PasswordBearer, OAuth2PasswordRequestForm
from jose import JWTError, jwt
from datetime import datetime, timedelta
app = FastAPI()
oauth2_scheme = OAuth2PasswordBearer(tokenUrl="token")
SECRET_KEY = "your-secret-key"
ALGORITHM = "HS256"
ACCESS_TOKEN_EXPIRE_MINUTES = 30
def create_access_token(data: dict, expires_delta: timedelta = None):
to_encode = data.copy()
if expires_delta:
expire = datetime.utcnow() + expires_delta
else:
expire = datetime.utcnow() + timedelta(minutes=15)
to_encode.update({"exp": expire})
return jwt.encode(to_encode, SECRET_KEY, algorithm=ALGORITHM)
@app.post("/token")
async def login(form_data: OAuth2PasswordRequestForm = Depends()):
user = authenticate_user(form_data.username, form_data.password)
if not user:
raise HTTPException(status_code=400, detail="Invalid credentials")
access_token = create_access_token(data={"sub": user.username})
return {"access_token": access_token, "token_type": "bearer"}
def get_current_user(token: str = Depends(oauth2_scheme)):
credentials_exception = HTTPException(
status_code=401,
detail="Invalid authentication credentials",
headers={"WWW-Authenticate": "Bearer"},
)
try:
payload = jwt.decode(token, SECRET_KEY, algorithms=[ALGORITHM])
username: str = payload.get("sub")
if username is None:
raise credentials_exception
except JWTError:
raise credentials_exception
return username
@app.get("/protected")
async def protected_route(current_user: str = Depends(get_current_user)):
return {"message": f"Hello, {current_user}"}
27.5.2.3 输入验证与清理
输入验证与清理可以防止注入攻击和其他恶意输入。
示例:使用Pydantic进行输入验证
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel, EmailStr
app = FastAPI()
class User(BaseModel):
username: str
email: EmailStr
age: int
@app.post("/users/")
async def create_user(user: User):
if user.age < 0:
raise HTTPException(status_code=400, detail="Age cannot be negative")
return {"message": f"User {user.username} created with email {user.email}"}
27.5.2.4 模型保护
模型保护包括防止模型窃取和知识产权保护。
- 限制查询频率:限制API的请求频率,防止频繁查询导致模型参数泄露。
- 使用API密钥:通过API密钥控制访问权限。
- 混淆模型:对模型进行混淆处理,增加逆向工程的难度。
示例:限制API请求频率
from fastapi import FastAPI, HTTPException, Request
from fastapi.responses import JSONResponse
from ratelimit import limits, sleep_and_retry
app = FastAPI()
# 限制每个IP每分钟最多10次请求
RATE_LIMIT = "10/minute"
@app.get("/protected")
@sleep_and_retry
@limits(calls=10, period=60)
async def protected_route(request: Request):
return {"message": "Hello, World!"}
27.5.2.5 隐私保护
隐私保护包括:
- 数据最小化:只收集和存储必要的数据。
- 匿名化与去标识化:对敏感数据进行匿名化处理,防止个人身份信息泄露。
- 差分隐私(Differential Privacy):在数据分析和机器学习中添加噪声,保护用户隐私。
示例:使用差分隐私进行模型训练
import torch
from opendp.mod import enable_features
from opendp.meas import gaussian_noise
from opendp.trans import make_bounded_sum
enable_features("floating-point")
# 定义差分隐私机制
dp_mech = gaussian_noise(scale=1.0)
# 训练模型时添加噪声
def train_model(model, data, labels):
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)
for epoch in range(num_epochs):
optimizer.zero_grad()
outputs = model(data)
loss = torch.nn.functional.cross_entropy(outputs, labels)
loss.backward()
dp_mech(loss)
optimizer.step()
27.5.3. 综合示例
以下是一个综合的安全部署示例,展示了如何使用FastAPI和JWT进行身份验证,并限制API请求频率。
from fastapi import FastAPI, Depends, HTTPException, Request
from fastapi.security import OAuth2PasswordBearer, OAuth2PasswordRequestForm
from jose import JWTError, jwt
from datetime import datetime, timedelta
from ratelimit import limits, sleep_and_retry
app = FastAPI()
oauth2_scheme = OAuth2PasswordBearer(tokenUrl="token")
SECRET_KEY = "your-secret-key"
ALGORITHM = "HS256"
ACCESS_TOKEN_EXPIRE_MINUTES = 30
def create_access_token(data: dict, expires_delta: timedelta = None):
to_encode = data.copy()
if expires_delta:
expire = datetime.utcnow() + expires_delta
else:
expire = datetime.utcnow() + timedelta(minutes=15)
to_encode.update({"exp": expire})
return jwt.encode(to_encode, SECRET_KEY, algorithm=ALGORITHM)
def authenticate_user(username: str, password: str):
# 实现用户认证逻辑
return True
@app.post("/token")
@sleep_and_retry
@limits(calls=5, period=60)
async def login(form_data: OAuth2PasswordRequestForm = Depends()):
user = authenticate_user(form_data.username, form_data.password)
if not user:
raise HTTPException(status_code=400, detail="Invalid credentials")
access_token = create_access_token(data={"sub": form_data.username})
return {"access_token": access_token, "token_type": "bearer"}
def get_current_user(token: str = Depends(oauth2_scheme)):
credentials_exception = HTTPException(
status_code=401,
detail="Invalid authentication credentials",
headers={"WWW-Authenticate": "Bearer"},
)
try:
payload = jwt.decode(token, SECRET_KEY, algorithms=[ALGORITHM])
username: str = payload.get("sub")
if username is None:
raise credentials_exception
except JWTError:
raise credentials_exception
return username
@app.get("/protected")
@sleep_and_retry
@limits(calls=10, period=60)
async def protected_route(current_user: str = Depends(get_current_user)):
return {"message": f"Hello, {current_user}"}
27.5.4. 总结
安全考量与隐私保护是AI模型部署中的重要环节。通过实施有效的安全措施,如数据加密、身份验证、输入验证、模型保护以及隐私保护,可以大大提升系统的安全性,保护用户隐私,确保AI服务的可靠性和用户信任。Python及其相关库提供了丰富的工具和功能,可以大大简化安全部署的实现过程,提高工作效率。通过本章的学习,您将能够掌握AI模型部署中的安全风险、防护措施以及隐私保护方法,并将其应用于AI模型的实战中,实现更安全的AI应用。
27.6 实战案例:从训练到部署一个安全的AI服务
在本节中,我们将通过一个完整的实战案例,展示如何将一个AI模型从训练阶段安全地部署为Web服务。该案例将涵盖模型训练、序列化、API服务创建、安全配置、容器化部署以及监控与维护等环节。以下是详细的步骤和代码示例。
27.6.1. 项目概述
项目目标:构建一个安全的AI服务,能够接收用户上传的图像,进行图像分类,并返回分类结果。该服务将包括以下安全措施:
- 数据加密:使用HTTPS确保数据传输安全。
- 身份验证与授权:使用JWT进行用户身份验证和授权。
- 输入验证:验证用户输入,防止恶意数据注入。
- 模型保护:限制API请求频率,防止模型窃取。
- 隐私保护:对用户数据进行匿名化处理。
27.6.2. 数据准备与模型训练
27.6.2.1 数据收集与预处理
收集图像数据集,并进行预处理,如调整图像大小、归一化等。
示例:数据预处理
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
# 定义数据预处理
transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
# 加载数据集
train_dataset = datasets.ImageFolder(root='data/train', transform=transform)
train_dataloader = DataLoader(train_dataset, batch_size=32, shuffle=True)
val_dataset = datasets.ImageFolder(root='data/val', transform=transform)
val_dataloader = DataLoader(val_dataset, batch_size=32, shuffle=False)
27.6.2.2 模型训练
使用预训练的ResNet模型进行微调。
示例:模型训练
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import models
# 加载预训练的ResNet模型
model = models.resnet50(pretrained=True)
num_ftrs = model.fc.in_features
model.fc = nn.Linear(num_ftrs, 10) # 假设有10个类别
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=1e-4)
# 训练过程
num_epochs = 25
for epoch in range(num_epochs):
model.train()
for inputs, labels in train_dataloader:
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
print(f'Epoch [{epoch + 1}/{num_epochs}], Loss: {loss.item()}')
27.6.2.3 模型序列化
将训练好的模型保存到磁盘。
示例:模型序列化
torch.save(model.state_dict(), "model.pth")
27.6.3. 创建安全的API服务
27.6.3.1 使用FastAPI创建API服务
使用FastAPI创建一个接收图像输入并返回分类结果的API接口。
示例:API服务创建
from fastapi import FastAPI, File, UploadFile, HTTPException
from pydantic import BaseModel
import torch
import torch.nn as nn
from torchvision import transforms
from PIL import Image
import io
app = FastAPI()
# 加载模型
model = models.resnet50(pretrained=False)
model.fc = nn.Linear(model.fc.in_features, 10)
model.load_state_dict(torch.load("model.pth"))
model.eval()
# 定义预处理
transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
class Prediction(BaseModel):
class_id: int
class_name: str
confidence: float
@app.post("/predict", response_model=Prediction)
async def predict(file: UploadFile = File(...)):
try:
contents = await file.read()
image = Image.open(io.BytesIO(contents))
image = transform(image).unsqueeze(0)
with torch.no_grad():
outputs = model(image)
_, predicted = torch.max(outputs, 1)
confidence = torch.softmax(outputs, dim=1)[0][predicted].item()
return {"class_id": predicted.item(), "class_name": "类别名称", "confidence": confidence}
except Exception as e:
raise HTTPException(status_code=400, detail=str(e))
27.6.3.2 安全配置
27.6.3.2.1 使用HTTPS
在FastAPI中配置HTTPS,确保数据传输安全。
示例:配置HTTPS
if __name__ == "__main__":
uvicorn.run(app, host="0.0.0.0", port=8000, ssl_keyfile="key.pem", ssl_certfile="cert.pem")
27.6.3.2.2 使用JWT进行身份验证
使用JWT进行用户身份验证和授权。
示例:JWT身份验证
from fastapi.security import OAuth2PasswordBearer, OAuth2PasswordRequestForm
from jose import JWTError, jwt
from datetime import datetime, timedelta
oauth2_scheme = OAuth2PasswordBearer(tokenUrl="token")
SECRET_KEY = "your-secret-key"
ALGORITHM = "HS256"
ACCESS_TOKEN_EXPIRE_MINUTES = 30
def create_access_token(data: dict, expires_delta: timedelta = None):
to_encode = data.copy()
if expires_delta:
expire = datetime.utcnow() + expires_delta
else:
expire = datetime.utcnow() + timedelta(minutes=15)
to_encode.update({"exp": expire})
return jwt.encode(to_encode, SECRET_KEY, algorithm=ALGORITHM)
@app.post("/token")
async def login(form_data: OAuth2PasswordRequestForm = Depends()):
user = authenticate_user(form_data.username, form_data.password)
if not user:
raise HTTPException(status_code=400, detail="Invalid credentials")
access_token = create_access_token(data={"sub": user.username})
return {"access_token": access_token, "token_type": "bearer"}
def get_current_user(token: str = Depends(oauth2_scheme)):
credentials_exception = HTTPException(
status_code=401,
detail="Invalid authentication credentials",
headers={"WWW-Authenticate": "Bearer"},
)
try:
payload = jwt.decode(token, SECRET_KEY, algorithms=[ALGORITHM])
username: str = payload.get("sub")
if username is None:
raise credentials_exception
except JWTError:
raise credentials_exception
return username
@app.post("/predict", response_model=Prediction)
async def predict(file: UploadFile = File(...), current_user: str = Depends(get_current_user)):
# 同上
27.6.3.2.3 输入验证与限制请求频率
使用Pydantic进行输入验证,并使用ratelimit库限制API请求频率。
示例:输入验证与请求频率限制
from fastapi import FastAPI, File, UploadFile, Depends, HTTPException, Request
from fastapi.security import OAuth2PasswordBearer, OAuth2PasswordRequestForm
from ratelimit import limits, sleep_and_retry
oauth2_scheme = OAuth2PasswordBearer(tokenUrl="token")
@app.post("/predict", response_model=Prediction)
@sleep_and_retry
@limits(calls=10, period=60)
async def predict(file: UploadFile = File(...), current_user: str = Depends(get_current_user)):
# 同上
27.6.4. 容器化与部署
使用Docker将API服务容器化,并部署到云服务平台(如AWS, GCP, Azure)。
示例:Dockerfile
FROM python:3.8-slim
WORKDIR /app
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
COPY . .
EXPOSE 8000
CMD ["uvicorn", "main:app", "--host", "0.0.0.0", "--port", "8000"]
构建Docker镜像:
docker build -t my-secure-ai-service .
运行Docker容器:
docker run -d -p 8000:8000 my-secure-ai-service
27.6.5. 监控与维护
27.6.5.1 使用Prometheus和Grafana进行监控
示例:使用Prometheus监控API服务
from prometheus_client import start_http_server, Summary, Gauge
import time
import random
# 定义指标
REQUEST_TIME = Summary('request_processing_seconds', 'Time spent processing request')
CPU_USAGE = Gauge('cpu_usage_percent', 'CPU usage percentage')
MEMORY_USAGE = Gauge('memory_usage_mb', 'Memory usage in MB')
# 模拟资源使用
def simulate_resource_usage():
CPU_USAGE.set(random.uniform(10, 90))
MEMORY_USAGE.set(random.uniform(100, 500))
# 监控函数
@REQUEST_TIME.time()
def predict(file: UploadFile):
# 模型推理
...
# 启动HTTP服务器
start_http_server(8001)
while True:
input_data = ... # 获取输入数据
prediction = predict(input_data)
simulate_resource_usage()
time.sleep(1)
27.6.6. 总结
通过本案例的实践,您将能够掌握从模型训练到安全部署的完整流程,并将其应用于实际的AI服务中。Python及其相关库提供了丰富的工具和功能,可以大大简化AI服务的实现过程,提高工作效率。通过本章的学习,您将能够构建出安全、可靠的AI服务,并确保其在生产环境中的稳定性和安全性。
第二十八章:AI项目中的常见问题与挑战
- 模型过拟合、数据不均衡问题的解决
- 数据质量问题及其改进策略
- 特征工程的重要性与实践技巧
- 模型解释性与可解释AI(XAI)
- 性能瓶颈分析与优化
- 道德伦理与法律合规考量
28.1 模型过拟合、数据不均衡问题的解决
在AI项目中,模型过拟合和数据不均衡是两个常见且具有挑战性的问题。解决这些问题对于提升模型的泛化能力和性能至关重要。以下将详细介绍这两个问题的定义、影响以及解决方法,并通过具体示例展示如何应对这些挑战。
28.1.1. 模型过拟合
28.1.1.1 什么是模型过拟合?
模型过拟合是指模型在训练数据上表现良好,但在验证集或测试集上表现不佳的现象。这意味着模型学习到了训练数据的噪声和细节,而不是通用的模式或规律。
28.1.1.2 过拟合的影响
- 泛化能力差:模型在新数据上的表现不佳。
- 高方差:模型的预测结果对训练数据的微小变化非常敏感。
28.1.1.3 解决方法
28.1.1.3.1 数据增强(Data Augmentation)
通过增加数据的多样性来防止过拟合。例如,在图像数据中,可以进行旋转、缩放、翻转等变换。
示例:使用数据增强
from torchvision import transforms
from torch.utils.data import DataLoader, Dataset
class AugmentedDataset(Dataset):
def __init__(self, image_paths, transform=None):
self.image_paths = image_paths
self.transform = transform
def __len__(self):
return len(self.image_paths)
def __getitem__(self, idx):
image = Image.open(self.image_paths[idx]).convert('RGB')
if self.transform:
image = self.transform(image)
return image
transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.RandomHorizontalFlip(),
transforms.RandomRotation(10),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
dataset = AugmentedDataset(image_paths, transform=transform)
dataloader = DataLoader(dataset, batch_size=32, shuffle=True)
28.1.1.3.2 正则化(Regularization)
通过在损失函数中添加正则化项来惩罚复杂的模型参数,如L1正则化、L2正则化。
示例:使用L2正则化
import torch
import torch.nn as nn
import torch.optim as optim
model = ... # 定义模型
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=1e-3, weight_decay=1e-5) # weight_decay即为L2正则化系数
28.1.1.3.3 Dropout
在训练过程中随机丢弃一部分神经元,防止模型对某些特定神经元产生依赖。
示例:使用Dropout
import torch.nn as nn
class SimpleModel(nn.Module):
def __init__(self):
super(SimpleModel, self).__init__()
self.fc1 = nn.Linear(784, 256)
self.relu = nn.ReLU()
self.dropout = nn.Dropout(0.5)
self.fc2 = nn.Linear(256, 10)
def forward(self, x):
x = self.relu(self.fc1(x))
x = self.dropout(x)
x = self.fc2(x)
return x
28.1.1.3.4 提前停止(Early Stopping)
在验证集上的性能不再提升时,提前停止训练,防止模型过拟合。
示例:使用提前停止
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
# 假设有train_dataloader和val_dataloader
model = ... # 定义模型
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=1e-3)
early_stopping_patience = 5
epochs_no_improve = 0
min_val_loss = float('inf')
for epoch in range(100):
model.train()
for inputs, labels in train_dataloader:
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
model.eval()
val_loss = 0
with torch.no_grad():
for inputs, labels in val_dataloader:
outputs = model(inputs)
loss = criterion(outputs, labels)
val_loss += loss.item()
val_loss /= len(val_dataloader)
if val_loss < min_val_loss:
min_val_loss = val_loss
epochs_no_improve = 0
else:
epochs_no_improve += 1
if epochs_no_improve >= early_stopping_patience:
print(f'Early stopping at epoch {epoch}')
break
28.1.2. 数据不均衡
28.1.2.1 什么是数据不均衡?
数据不均衡是指不同类别样本数量差异较大的情况。例如,在二分类问题中,正样本和负样本的比例可能相差很大。
28.1.2.2 数据不均衡的影响
- 模型偏向多数类:模型倾向于预测多数类,忽视少数类。
- 性能下降:特别是对少数类的预测性能较差。
28.1.2.3 解决方法
28.1.2.3.1 重采样(Resampling)
- 过采样(Oversampling):对少数类样本进行复制或生成新的样本。
- 欠采样(Undersampling):对多数类样本进行随机删除。
示例:使用过采样
from imblearn.over_sampling import SMOTE
# 假设X_train和y_train是训练数据
smote = SMOTE()
X_resampled, y_resampled = smote.fit_resample(X_train, y_train)
28.1.2.3.2 使用类别权重(Class Weights)
在损失函数中为少数类分配更高的权重,以平衡不同类别的影响。
示例:使用类别权重
import torch
import torch.nn as nn
import torch.optim as optim
class_weights = torch.tensor([1.0, 10.0]) # 假设有两个类别,第二个类别为少数类
criterion = nn.CrossEntropyLoss(weight=class_weights)
optimizer = optim.Adam(model.parameters(), lr=1e-3)
28.1.2.3.3 数据增强
对少数类样本进行数据增强,增加其多样性。
示例:数据增强
from torchvision import transforms
transform = transforms.Compose([
transforms.RandomHorizontalFlip(),
transforms.RandomRotation(10),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
dataset = AugmentedDataset(minority_image_paths, transform=transform)
dataloader = DataLoader(dataset, batch_size=32, shuffle=True)
28.1.2.3.4 使用Focal Loss
Focal Loss是一种改进的交叉熵损失函数,可以降低易分类样本的权重,使得模型更关注难分类的样本。
示例:使用Focal Loss
import torch
import torch.nn as nn
class FocalLoss(nn.Module):
def __init__(self, alpha=1, gamma=2, logits=False, reduce=True):
super(FocalLoss, self).__init__()
self.alpha = alpha
self.gamma = gamma
self.logits = logits
self.reduce = reduce
def forward(self, inputs, targets):
if self.logits:
BCE_loss = F.binary_cross_entropy_with_logits(inputs, targets, reduction='none')
else:
BCE_loss = F.binary_cross_entropy(inputs, targets, reduction='none')
pt = torch.exp(-BCE_loss)
F_loss = self.alpha * (1-pt)**self.gamma * BCE_loss
if self.reduce:
return torch.mean(F_loss)
else:
return F_loss
28.1.3. 小结
模型过拟合和数据不均衡是AI项目中常见的问题,通过合理的数据增强、正则化、提前停止、重采样、使用类别权重等方法,可以有效缓解这些问题,提升模型的泛化能力和性能。Python及其相关库提供了丰富的工具和功能,可以大大简化这些问题的解决过程,提高工作效率。通过本章的学习,您将能够掌握解决模型过拟合和数据不均衡问题的方法,并将其应用于AI模型的实战中,实现更强大的AI应用。
28.2 数据质量问题及其改进策略
在AI项目中,数据质量是影响模型性能的关键因素之一。低质量的数据可能导致模型性能不佳、泛化能力差,甚至产生误导性的结果。数据质量问题可能包括数据不完整、数据不一致、数据噪声、数据偏差等。以下将详细介绍数据质量问题的常见类型、影响以及改进策略,并通过具体示例展示如何提升数据质量。
28.2.1. 数据质量问题的常见类型
数据不完整(Missing Data)
数据集中存在缺失值,可能由于数据收集过程中的错误、数据传输问题或数据源本身的问题导致。
数据不一致(Inconsistent Data)
数据集中存在不一致的格式、单位或命名约定,例如日期格式不同、单位混用等。
数据噪声(Noisy Data)
数据中存在错误、异常值或无关信息,例如拼写错误、测量误差等。
数据偏差(Biased Data)
数据集中存在系统性偏差,可能导致模型在某些群体或类别上的表现不佳,例如性别、种族偏见等。
数据冗余(Redundant Data)
数据集中存在重复或高度相关的数据,可能导致模型过拟合并影响训练效率。
28.2.2. 数据质量问题的影响
- 模型性能下降:低质量的数据会导致模型无法学习到有效的模式,从而影响预测准确性。
- 模型偏差:数据偏差可能导致模型在某些群体或类别上的表现不佳,引发公平性问题。
- 资源浪费:处理和清洗低质量数据需要额外的时间和计算资源。
- 误导性结果:低质量的数据可能导致模型产生误导性的预测,影响决策和业务结果。
28.2.3. 改进策略
28.2.3.1 数据清洗(Data Cleaning)
数据清洗是指识别和纠正数据中的错误、不一致和缺失值的过程。
示例:处理缺失值
import pandas as pd
from sklearn.impute import SimpleImputer
# 读取数据
df = pd.read_csv('data.csv')
# 查看缺失值
print(df.isnull().sum())
# 使用均值填充数值型缺失值
imputer = SimpleImputer(strategy='mean')
df['numeric_column'] = imputer.fit_transform(df[['numeric_column']])
# 使用众数填充类别型缺失值
imputer = SimpleImputer(strategy='most_frequent')
df['categorical_column'] = imputer.fit_transform(df[['categorical_column']])
示例:处理数据不一致
# 统一日期格式
df['date'] = pd.to_datetime(df['date'], format='%Y-%m-%d', errors='coerce')
# 统一单位
df['price'] = df['price'].apply(lambda x: x * 0.01 if 'cents' in x else x)
3.2 数据去噪(Data Denoising)
数据去噪是指识别和移除数据中的错误、异常值或无关信息。
示例:处理异常值
import numpy as np
# 使用Z-score方法检测异常值
from scipy import stats
z_scores = np.abs(stats.zscore(df['numeric_column']))
threshold = 3
outliers = np.where(z_scores > threshold)
df = df.drop(outliers[0])
# 或者使用IQR方法
Q1 = df['numeric_column'].quantile(0.25)
Q3 = df['numeric_column'].quantile(0.75)
IQR = Q3 - Q1
outliers = df[(df['numeric_column'] < (Q1 - 1.5 * IQR)) | (df['numeric_column'] > (Q3 + 1.5 * IQR))].index
df = df.drop(outliers)
28.2.3.3 数据标准化与归一化(Data Normalization and Standardization)
将数据转换为统一的尺度或分布,以提高模型的训练效率和性能。
示例:数据标准化
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
df['numeric_column'] = scaler.fit_transform(df[['numeric_column']])
示例:数据归一化
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
df['numeric_column'] = scaler.fit_transform(df[['numeric_column']])
28.2.3.4 数据增强(Data Augmentation)
对于图像、文本等数据,可以通过数据增强技术增加数据的多样性,提高模型的泛化能力。
示例:图像数据增强
from torchvision import transforms
transform = transforms.Compose([
transforms.RandomHorizontalFlip(),
transforms.RandomRotation(10),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
28.2.3.5 处理数据偏差(Addressing Data Bias)
识别和减少数据中的偏差,例如通过重新采样、重新加权或使用公平性约束的方法。
示例:处理数据偏差
# 使用重新加权的方法
class_weights = compute_class_weights(df['label'])
criterion = nn.CrossEntropyLoss(weight=class_weights)
28.2.3.6 数据冗余处理(Handling Redundant Data)
识别和移除数据中的重复或高度相关的数据,以减少冗余。
示例:移除重复数据
df = df.drop_duplicates()
28.2.4. 小结
数据质量是AI项目成功的基石。通过数据清洗、去噪、标准化与归一化、数据增强、处理数据偏差以及处理数据冗余等策略,可以显著提升数据质量,从而提高模型的性能和可靠性。Python及其相关库提供了丰富的工具和功能,可以大大简化数据质量改进的过程,提高工作效率。通过本章的学习,您将能够掌握数据质量问题的识别和改进方法,并将其应用于AI项目的实战中,确保数据的高质量和模型的良好表现。
28.3 特征工程的重要性与实践技巧
特征工程是机器学习和深度学习项目中至关重要的一环,它直接影响模型的性能和效果。特征工程是指通过选择、转换、创建或提取原始数据中的有用特征,来提高模型的预测能力和泛化能力的过程。以下将详细介绍特征工程的重要性、主要步骤以及实践技巧,并通过具体示例展示如何进行有效的特征工程。
28.3.1. 特征工程的重要性
- 提升模型性能:通过构建有意义的特征,可以帮助模型更好地理解数据,从而提升预测准确性。
- 减少过拟合并提高泛化能力:高质量的特征可以减少模型对噪声的依赖,提高其在新数据上的表现。
- 降低计算复杂度:通过降维或特征选择,可以减少特征数量,从而降低模型的计算复杂度,加快训练速度。
- 增强模型的可解释性:选择有意义的特征可以提高模型的可解释性,使结果更容易被理解和信任。
28.3.2. 特征工程的主要步骤
28.3.2.1 特征理解与探索(Feature Understanding and Exploration)
在开始特征工程之前,首先需要理解数据,包括数据的分布、相关性、缺失值等。
示例:使用Pandas进行数据探索
import pandas as pd
# 读取数据
df = pd.read_csv('data.csv')
# 查看数据基本信息
print(df.info())
# 查看统计描述
print(df.describe())
# 查看缺失值
print(df.isnull().sum())
# 可视化相关性
import seaborn as sns
import matplotlib.pyplot as plt
corr = df.corr()
sns.heatmap(corr, annot=True, fmt=".2f")
plt.show()
28.3.2.2 特征选择(Feature Selection)
选择对目标变量有预测能力的特征,去除冗余或不相关的特征。
常用的特征选择方法:
- 单变量选择(Univariate Selection):使用统计测试选择与目标变量最相关的特征。
- 递归特征消除(Recursive Feature Elimination, RFE):递归地训练模型并移除最不重要的特征。
- 基于模型的特征选择(Model-Based Selection):使用模型(如树模型)的特征重要性进行选择。
示例:使用单变量选择
from sklearn.feature_selection import SelectKBest, chi2
X = df.drop('target', axis=1)
y = df['target']
selector = SelectKBest(score_func=chi2, k=10)
X_new = selector.fit_transform(X, y)
selected_features = X.columns[selector.get_support()]
print(selected_features)
28.3.2.3 特征变换(Feature Transformation)
对特征进行数学变换,如对数变换、平方根变换、标准化、归一化等,以满足模型对数据分布的要求。
示例:对数变换
import numpy as np
df['numeric_feature'] = np.log1p(df['numeric_feature'])
示例:标准化
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
df['numeric_feature'] = scaler.fit_transform(df[['numeric_feature']])
28.3.2.4 特征创建(Feature Creation)
通过组合现有特征或提取新特征来创建更有意义的特征。
示例:创建新特征
# 创建年龄段的特征
df['age_group'] = pd.cut(df['age'], bins=[0, 18, 35, 60, 100], labels=['Child', 'Young Adult', 'Middle Aged', 'Senior'])
# 创建比率特征
df['price_per_unit'] = df['price'] / df['quantity']
28.3.2.5 特征编码(Feature Encoding)
将类别型特征转换为数值型特征,以便于模型处理。
常用的特征编码方法:
- 独热编码(One-Hot Encoding):为每个类别创建单独的二进制特征。
- 标签编码(Label Encoding):将每个类别映射到一个整数。
- 目标编码(Target Encoding):使用目标变量的统计量对类别进行编码。
示例:独热编码
df = pd.get_dummies(df, columns=['categorical_feature'], drop_first=True)
示例:标签编码
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
df['categorical_feature'] = le.fit_transform(df['categorical_feature'])
28.3.3. 实践技巧
28.3.3.1 保持数据的一致性
确保特征工程过程中数据的一致性,例如在训练集和测试集上应用相同的变换。
示例:使用Pipeline保持一致性
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
pipeline = Pipeline([
('scaler', StandardScaler()),
('classifier', LogisticRegression())
])
pipeline.fit(X_train, y_train)
predictions = pipeline.predict(X_test)
28.3.3.2 避免数据泄露(Data Leakage)
在进行特征工程时,避免使用未来信息或测试集信息,以防止数据泄露。
示例:避免数据泄露
# 错误示例:在训练集和测试集上使用整个数据集的统计量
mean = df['feature'].mean()
df['feature_normalized'] = df['feature'] / mean
# 正确示例:在训练集和测试集上分别计算统计量
mean_train = X_train['feature'].mean()
X_train['feature_normalized'] = X_train['feature'] / mean_train
X_test['feature_normalized'] = X_test['feature'] / mean_train
28.3.3.3 处理高维数据
对于高维数据,可以使用降维技术(如PCA、t-SNE)或特征选择方法(如Lasso、L1正则化)来减少特征数量。
示例:使用PCA进行降维
from sklearn.decomposition import PCA
pca = PCA(n_components=50)
X_new = pca.fit_transform(X)
28.3.4. 小结
特征工程是AI项目中提升模型性能的关键步骤。通过合理的特征选择、变换、创建和编码,可以显著提升模型的预测能力和泛化能力。Python及其相关库提供了丰富的工具和功能,可以大大简化特征工程的过程,提高工作效率。通过本章的学习,您将能够掌握特征工程的主要步骤和实践技巧,并将其应用于AI模型的实战中,实现更强大的AI应用。
28.4 模型解释性与可解释AI(XAI)
在人工智能(AI)领域,模型解释性 和 可解释AI(Explainable AI,XAI)变得越来越重要。随着模型变得越来越复杂,尤其是深度学习模型,理解模型如何做出决策变得愈发困难。模型解释性旨在提供对模型内部机制和决策过程的解释,而可解释AI则是一套方法和工具,旨在使AI模型的决策过程对人类更加透明和可理解。以下将详细介绍模型解释性的重要性、主要方法以及可解释AI的应用,并通过具体示例展示如何实现模型的可解释性。
28.4.1. 模型解释性的重要性
- 信任与接受度:提高用户和利益相关者对AI系统的信任和接受度。
- 责任与问责:在关键应用中,如医疗、金融和法律领域,确保AI系统的决策可以被解释和问责。
- 调试与改进:帮助开发者理解模型的行为,识别和修复错误或偏差。
- 合规性:满足法律法规对AI系统透明度和可解释性的要求,如GDPR(通用数据保护条例)。
28.4.2. 模型解释性的主要方法
28.4.2.1 可解释性模型(Interpretable Models)
使用本身具有可解释性的模型,如线性回归、逻辑回归、决策树等。这些模型的决策过程相对简单,易于理解和解释。
示例:使用决策树
from sklearn.tree import DecisionTreeClassifier, plot_tree
import matplotlib.pyplot as plt
# 训练决策树模型
model = DecisionTreeClassifier(max_depth=3)
model.fit(X_train, y_train)
# 可视化决策树
plt.figure(figsize=(20,10))
plot_tree(model, feature_names=feature_names, class_names=class_names, filled=True, rounded=True)
plt.show()
28.4.2.2 模型无关解释方法(Model-Agnostic Methods)
这些方法可以应用于任何类型的模型,包括复杂的深度学习模型。主要方法包括:
- LIME(Local Interpretable Model-agnostic Explanations):通过在局部区域内拟合可解释的简单模型来解释单个预测。
- SHAP(SHapley Additive exPlanations):基于博弈论的方法,分配每个特征对预测的贡献。
- 特征重要性(Feature Importance):通过模型自身的特征重要性指标(如树模型的特征重要性)进行解释。
示例:使用LIME进行解释
import lime
import lime.lime_tabular
from sklearn.ensemble import RandomForestClassifier
# 训练随机森林模型
model = RandomForestClassifier()
model.fit(X_train, y_train)
# 初始化LIME解释器
explainer = lime.lime_tabular.LimeTabularExplainer(X_train.values, feature_names=feature_names, class_names=class_names, discretize_continuous=True)
# 选择一个样本进行解释
idx = 0
exp = explainer.explain_instance(X_test.values[idx], model.predict_proba, num_features=5)
exp.show_in_notebook(show_table=True)
示例:使用SHAP进行解释
import shap
# 训练XGBoost模型
model = xgb.XGBClassifier()
model.fit(X_train, y_train)
# 计算SHAP值
explainer = shap.Explainer(model, X_train)
shap_values = explainer(X_test)
# 可视化SHAP值
shap.plots.waterfall(shap_values[0])
28.4.2.3 基于注意力机制的解释(Attention-Based Explanations)
对于基于注意力机制的模型,可以通过可视化注意力权重来解释模型的决策过程。
示例:使用注意力权重进行解释
import matplotlib.pyplot as plt
# 假设model是一个基于注意力机制的模型
attention_weights = model.attention_weights # 获取注意力权重
# 可视化注意力权重
plt.figure(figsize=(10, 5))
plt.imshow(attention_weights, cmap='viridis')
plt.colorbar()
plt.show()
28.4.3. 可解释AI的应用
a. 医疗诊断
在医疗领域,AI模型的可解释性对于诊断和治疗的决策至关重要。例如,医生需要理解AI模型为何做出某种诊断,以便进行复核和决策。
b. 金融分析
在金融领域,AI模型的可解释性可以帮助分析师理解模型的预测依据,从而做出更明智的投资决策。
c. 自动驾驶
在自动驾驶中,AI模型的可解释性可以提高系统的透明度和安全性,帮助工程师理解模型的决策过程,避免潜在的危险。
d. 信用评分
在信用评分中,AI模型的可解释性可以帮助用户理解他们的信用评分是如何得出的,从而提高透明度和公平性。
28.4.4. 实践示例
以下是一个综合的模型解释性示例,展示了如何使用SHAP对XGBoost模型进行解释。
import xgb
import shap
# 训练XGBoost模型
model = xgb.XGBClassifier()
model.fit(X_train, y_train)
# 计算SHAP值
explainer = shap.Explainer(model, X_train)
shap_values = explainer(X_test)
# 可视化SHAP值
shap.plots.waterfall(shap_values[0])
# 汇总SHAP值
shap.plots.beeswarm(shap_values)
28.4.5. 小结
模型解释性和可解释AI是AI领域的重要研究方向,通过合理的解释方法,可以提高模型的可信度、透明度和可问责性。Python及其相关库提供了丰富的工具和功能,可以大大简化模型解释性的实现过程,提高工作效率。通过本章的学习,您将能够掌握模型解释性的主要方法和可解释AI的应用,并将其应用于AI模型的实战中,实现更透明、更可信的AI应用。
28.5 性能瓶颈分析与优化
在AI项目中,性能瓶颈是指限制系统整体性能的关键因素。识别和解决这些瓶颈对于提升系统效率和用户体验至关重要。性能瓶颈可能出现在数据处理、模型训练、推理阶段或系统架构等多个环节。以下将详细介绍如何进行性能瓶颈分析以及常见的优化策略,并通过具体示例展示如何进行有效的性能优化。
28.5.1. 性能瓶颈分析
28.5.1.1 性能监控
性能监控是识别性能瓶颈的第一步。通过监控关键指标,可以了解系统在不同阶段的资源使用情况和运行效率。
常用的性能监控工具:
- TensorBoard:用于监控机器学习模型的训练过程,包括损失函数、准确率、计算图等。
- PyTorch Profiler:用于分析PyTorch模型的性能瓶颈。
- cProfile:Python内置的性能分析工具,用于分析Python代码的执行时间。
- Grafana & Prometheus:用于系统级别的性能监控,监控CPU、内存、网络等资源的使用情况。
示例:使用cProfile进行性能分析
import cProfile
def train_model():
# 模型训练代码
...
# 使用cProfile进行性能分析
cProfile.run('train_model()')
28.5.1.2 瓶颈识别
通过性能监控,可以识别出以下常见的性能瓶颈:
- 数据加载与预处理:数据加载速度慢、预处理步骤复杂。
- 模型训练:模型参数多、计算量大、内存不足。
- 推理阶段:模型推理速度慢、延迟高。
- 系统架构:系统组件之间的通信效率低、并发处理能力不足。
28.5.2. 性能优化策略
28.5.2.1 数据处理优化
- 数据缓存:对频繁使用的数据进行缓存,减少重复计算。
- 并行数据加载:使用多线程或多进程进行数据加载,提高数据加载速度。
- 数据预处理优化:简化预处理步骤,使用高效的预处理库。
示例:使用多线程进行数据加载
import torch
from torch.utils.data import DataLoader, Dataset
from multiprocessing import Pool
class MyDataset(Dataset):
def __init__(self, data):
self.data = data
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
# 数据读取和预处理
return self.data[idx]
def load_data():
# 使用多线程加载数据
with Pool(4) as p:
data = p.map(load_single_data, range(num_samples))
return data
dataset = MyDataset(load_data())
dataloader = DataLoader(dataset, batch_size=32, shuffle=True, num_workers=4)
28.5.2.2 模型训练优化
- 混合精度训练:使用半精度浮点数(FP16)进行训练,加速计算并减少内存占用。
- 梯度累积:将多个小批量数据的梯度累积起来再更新参数,模拟更大的批量大小。
- 模型剪枝与量化:减少模型参数数量和计算量,提高训练和推理速度。
示例:使用混合精度训练
from torch.cuda.amp import GradScaler, autocast
scaler = GradScaler()
for epoch in range(num_epochs):
for inputs, labels in dataloader:
optimizer.zero_grad()
with autocast():
outputs = model(inputs)
loss = loss_fn(outputs, labels)
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
28.5.2.3 推理阶段优化
- 模型导出与优化:将模型导出为高效的格式,如ONNX,使用推理引擎(如TensorRT)进行加速。
- 批处理推理:对多个样本进行批处理推理,提高吞吐量。
- 模型蒸馏:使用知识蒸馏技术,将复杂模型压缩为更小的模型,提高推理速度。
示例:使用ONNX进行模型导出与推理加速
import torch
import onnx
import onnxruntime
# 导出模型为ONNX格式
dummy_input = torch.randn(1, 3, 224, 224)
torch.onnx.export(model, dummy_input, "model.onnx", opset_version=11)
# 使用ONNX Runtime进行推理
ort_session = onnxruntime.InferenceSession("model.onnx")
def inference(input_data):
ort_inputs = {ort_session.get_inputs()[0].name: input_data.numpy()}
ort_outs = ort_session.run(None, ort_inputs)
return torch.tensor(ort_outs[0])
input_data = torch.randn(1, 3, 224, 224)
output = inference(input_data)
28.5.2.4 系统架构优化
- 分布式训练:使用分布式计算框架(如TensorFlow Distributed, PyTorch Distributed)进行分布式训练,提高训练速度。
- 异步处理:使用异步编程模型,提高系统并发处理能力。
- 负载均衡:在多节点部署中,使用负载均衡技术,均匀分配计算任务。
示例:使用分布式训练
import torch
import torch.distributed as dist
from torch.nn.parallel import DistributedDataParallel
# 初始化分布式环境
dist.init_process_group(backend='nccl')
# 包装模型
model = DistributedDataParallel(model)
# 训练过程
for epoch in range(num_epochs):
for inputs, labels in dataloader:
optimizer.zero_grad()
outputs = model(inputs)
loss = loss_fn(outputs, labels)
loss.backward()
optimizer.step()
28.5.3. 小结
性能瓶颈分析与优化是AI项目成功的关键。通过有效的性能监控和优化策略,可以显著提升系统的效率和响应速度。Python及其相关库提供了丰富的工具和功能,可以大大简化性能优化的实现过程,提高工作效率。通过本章的学习,您将能够掌握性能瓶颈分析的方法和常见的优化策略,并将其应用于AI项目的实战中,实现更高效、更快速的AI应用。
28.6 道德伦理与法律合规考量
在人工智能(AI)项目的开发和部署过程中,道德伦理和法律合规是至关重要的考量因素。随着AI技术的广泛应用,AI系统对个人和社会的影响日益深远,因此确保AI系统的道德性和合法性变得愈发重要。以下将详细介绍AI项目中的主要道德伦理问题、法律合规要求以及相应的应对策略,并通过具体示例展示如何实现道德伦理和法律合规。
28.6.1. 主要道德伦理问题
a. 偏见与歧视
AI系统可能会继承或放大训练数据中的偏见,导致对某些群体(如性别、种族、年龄等)的歧视性决策。
示例:招聘AI系统在筛选简历时,可能会因为训练数据中的性别偏见而对女性候选人产生歧视。
b. 隐私侵犯
AI系统可能未经授权收集、使用或泄露个人隐私数据,如面部识别技术可能被滥用,导致个人隐私泄露。
示例:智能家居设备未经用户同意收集和存储用户的语音数据。
c. 透明性与可解释性
AI系统的决策过程可能不透明,用户难以理解系统如何做出决策,导致信任问题。
示例:信贷审批AI系统拒绝用户的贷款申请,但无法解释拒绝的原因。
d. 责任与问责
在AI系统做出错误决策的情况下,难以确定责任归属,可能导致法律和伦理问题。
示例:自动驾驶汽车发生事故,难以确定是AI系统、制造商还是用户的责任。
e. 公平性与正义
AI系统的决策可能影响资源分配和社会公平,例如在司法系统中,AI的预测可能影响法官的判决。
示例:AI系统用于预测犯罪风险,可能对某些社区产生不公平的影响。
28.6.2. 法律合规要求
a. 数据保护法规
如欧盟的《通用数据保护条例》(GDPR)和加州的《消费者隐私法案》(CCPA),要求企业在收集、存储和使用个人数据时,必须获得用户的明确同意,并采取适当的安全措施保护数据安全。
b. 算法透明度
一些国家和地区正在制定或已经实施算法透明性法规,要求AI系统在使用决策过程中保持透明,并向用户提供解释。
c. 责任与赔偿
在AI系统造成损害的情况下,确定责任归属和赔偿机制是法律合规的重要方面。
d. 行业特定法规
不同行业可能有特定的AI法规,例如医疗行业的AI系统需要遵守医疗数据保护法规,金融行业的AI系统需要遵守金融监管法规。
28.6.3. 应对策略
28.6.3.1 偏见与歧视的缓解
- 数据清洗与平衡:对训练数据进行清洗,去除偏见,并确保不同群体的数据平衡。
- 公平性约束:在模型训练过程中加入公平性约束,确保模型在不同群体上的表现一致。
- 偏见检测与修正:使用偏见检测工具,识别并修正模型中的偏见。
示例:使用公平性约束
from fairlearn.reductions import ExponentiatedGradient, DemographicParity
# 假设model是已经训练好的模型
constraint = DemographicParity()
mitigator = ExponentiatedGradient(model, constraint)
mitigator.fit(X_train, y_train, sensitive_features=sensitive_features)
28.6.3.2 隐私保护
- 数据匿名化:对个人数据进行匿名化处理,去除可识别信息。
- 差分隐私:在数据分析和机器学习中使用差分隐私技术,保护用户隐私。
- 数据加密:使用加密技术保护数据在传输和存储中的安全。
示例:使用差分隐私
import torch
from opendp.mod import enable_features
from opendp.meas import gaussian_noise
enable_features("floating-point")
# 定义差分隐私机制
dp_mech = gaussian_noise(scale=1.0)
# 训练模型时添加噪声
def train_model(model, data, labels):
optimizer = torch.optim.Adam(model.parameters(), lr=1e-3)
for epoch in range(num_epochs):
optimizer.zero_grad()
outputs = model(data)
loss = torch.nn.functional.cross_entropy(outputs, labels)
loss.backward()
dp_mech(loss)
optimizer.step()
28.6.3.3 提高透明性与可解释性
- 使用可解释性模型:选择本身具有可解释性的模型,如线性回归、决策树等。
- 应用可解释AI技术:使用LIME、SHAP等工具解释模型决策。
- 提供解释接口:为用户提供解释接口,解释AI系统的决策过程。
示例:使用SHAP进行模型解释
import shap
# 训练XGBoost模型
model = xgb.XGBClassifier()
model.fit(X_train, y_train)
# 计算SHAP值
explainer = shap.Explainer(model, X_train)
shap_values = explainer(X_test)
# 可视化SHAP值
shap.plots.waterfall(shap_values[0])
28.6.3.4 明确责任与问责机制
- 制定责任划分协议:在AI系统开发和部署过程中,明确各方的责任。
- 建立审计与追溯机制:记录AI系统的决策过程,以便在出现问题时进行追溯。
- 实施风险评估与控制:对AI系统的潜在风险进行评估,并采取相应的控制措施。
28.6.4. 小结
道德伦理与法律合规是AI项目成功的基石。通过识别和缓解道德伦理问题,遵守相关法律法规,并采取有效的应对策略,可以确保AI系统的安全性和合法性。Python及其相关库提供了丰富的工具和功能,可以帮助实现道德伦理和法律合规目标。
通过本章的学习,您将能够掌握AI项目中的主要道德伦理问题和法律合规要求,并将其应用于AI模型的实战中,实现更负责任、更合规的AI应用。
第二十九章:实践项目:打造一个AI助手
- 从零到一:开发一个人工智能助手
- 对话管理系统的设计与实现
- 自然语言处理模块的集成与优化
- 用户界面与交互体验设计
- 部署与持续改进:让AI助手上线并不断进化
29.1 从零到一:开发一个人工智能助手
开发一个人工智能助手是一个复杂而有趣的项目,涉及多个领域的知识,包括自然语言处理(NLP)、对话管理、系统架构设计、用户界面设计等。以下将详细介绍如何从零开始开发一个人工智能助手,包括项目规划、技术选型、系统架构设计以及关键模块的实现方法,并通过具体示例展示如何启动这一项目。
29.1.1. 项目规划
29.1.1.1 确定目标与功能
在开始开发之前,首先需要明确AI助手的目标和功能。例如:
- 目标:为用户提供信息查询、日程管理、任务提醒、闲聊等智能服务。
- 功能:
- 自然语言理解(NLU):理解用户输入的意图和实体。
- 对话管理:管理对话的上下文和流程。
- 自然语言生成(NLG):生成自然语言回复。
- 任务执行:执行用户请求的任务,如查询天气、设置提醒等。
- 用户界面:提供友好的用户界面,支持文本和语音交互。
29.1.1.2 技术选型
根据项目需求选择合适的技术栈:
- 编程语言:Python(因其丰富的NLP和机器学习库)。
- NLP框架:Hugging Face Transformers、spaCy、Stanford NLP等。
- 对话管理:Rasa、Microsoft Bot Framework、Dialogflow等。
- Web框架:FastAPI、Flask、Django等,用于构建API服务。
- 前端框架:React、Vue.js、Flutter等,用于构建用户界面。
- 数据库:SQLite、PostgreSQL、MongoDB等,用于存储用户数据和对话历史。
示例:技术选型
- 编程语言:Python
- NLP框架:Hugging Face Transformers
- 对话管理:Rasa
- Web框架:FastAPI
- 前端框架:React
- 数据库:PostgreSQL
29.1.2. 系统架构设计
一个典型的AI助手系统架构包括以下几个主要组件:
1.用户界面(UI):提供与用户交互的界面,支持文本和语音输入。
2.API服务:处理来自用户界面的请求,调用NLP模块和对话管理系统。
3.自然语言处理(NLP)模块:负责理解用户输入的意图和实体。
4.对话管理系统:管理对话的上下文和流程,生成回复。
5.任务执行模块:执行用户请求的任务,如查询数据库、调用API等。
6.数据库:存储用户数据、对话历史和任务信息。
系统架构图:
用户界面 <--> API服务 <--> NLP模块
|
v
对话管理系统
|
v
任务执行模块
|
v
数据库
29.1.3. 关键模块的实现
29.1.3.1 自然语言处理(NLP)模块
NLP模块负责理解用户输入的意图和实体。可以使用预训练的模型和库,如Hugging Face Transformers、spaCy等。
示例:使用Hugging Face Transformers进行意图识别
from transformers import pipeline
# 加载预训练的意图识别模型
nlu = pipeline("text-classification", model="dsk010/bert-base-uncased-intent-detection")
def get_intent(text):
result = nlu(text)
return result[0]['label']
# 示例
user_input = "What is the weather today?"
intent = get_intent(user_input)
print(intent) # 输出: weather
29.1.3.2 对话管理系统
对话管理系统负责管理对话的上下文和流程。可以使用Rasa、Microsoft Bot Framework等开源框架,也可以自定义实现。
示例:使用Rasa构建对话管理系统
1.安装Rasa:
pip install rasa
2.初始化Rasa项目:
rasa init --no-prompt
3.定义对话流程:
在domain.yml中定义意图、实体、响应等。
intents:
- greet
- goodbye
- weather
responses:
utter_greet:
- text: "Hello! How can I assist you today?"
utter_goodbye:
- text: "Goodbye! Have a nice day!"
utter_weather:
- text: "The weather today is sunny with a high of 25°C."
4.训练模型:
rasa train
5.启动Rasa服务:
rasa run
29.1.3.3 API服务
API服务负责处理来自用户界面的请求,调用NLP模块和对话管理系统,并返回结果。可以使用FastAPI、Flask等Web框架。
示例:使用FastAPI创建API服务
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel
import rasa
from transformers import pipeline
app = FastAPI()
# 加载NLP模型
nlu = pipeline("text-classification", model="dsk010/bert-base-uncased-intent-detection")
# 启动Rasa服务
from rasa.core.agent import Agent
agent = Agent.load("models/")
class UserInput(BaseModel):
text: str
@app.post("/process")
async def process_input(input: UserInput):
intent = get_intent(input.text)
if intent == "weather":
response = "The weather today is sunny with a high of 25°C."
else:
response = agent.handle_text(input.text)
return {"response": response[0]['text']}
def get_intent(text):
result = nlu(text)
return result[0]['label']
29.1.3.4 用户界面
用户界面提供与用户交互的界面,支持文本和语音输入。可以使用React、Vue.js等前端框架构建Web界面,或使用Flutter等框架构建移动应用。
示例:使用React构建简单的Web界面
import React, { useState } from 'react';
import axios from 'axios';
function App() {
const [input, setInput] = useState('');
const [response, setResponse] = useState('');
const handleSend = async () => {
const res = await axios.post('/process', { text: input });
setResponse(res.data.response);
};
return (
<div>
<h1>AI助手</h1>
<input value={input} onChange={(e) => setInput(e.target.value)} />
<button onClick={handleSend}>发送</button>
<p>{response}</p>
</div>
);
}
export default App;
29.1.4. 部署与持续改进
29.1.4.1 部署
将AI助手部署到云服务平台(如AWS、GCP、Azure),并使用Docker进行容器化,确保系统的可移植性和可扩展性。
示例:使用Docker部署API服务
FROM python:3.8-slim
WORKDIR /app
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
COPY . .
EXPOSE 8000
CMD ["uvicorn", "main:app", "--host", "0.0.0.0", "--port", "8000"]
29.1.4.2 持续改进
通过收集用户反馈、监控系统性能和分析对话数据,持续改进AI助手的功能和性能。
示例:使用Prometheus和Grafana进行监控
from prometheus_client import start_http_server, Summary, Gauge
import time
import random
# 定义指标
REQUEST_TIME = Summary('request_processing_seconds', 'Time spent processing request')
CPU_USAGE = Gauge('cpu_usage_percent', 'CPU usage percentage')
MEMORY_USAGE = Gauge('memory_usage_mb', 'Memory usage in MB')
# 模拟资源使用
def simulate_resource_usage():
CPU_USAGE.set(random.uniform(10, 90))
MEMORY_USAGE.set(random.uniform(100, 500))
# 监控函数
@REQUEST_TIME.time()
def process_input(text):
# 处理输入
...
# 启动HTTP服务器
start_http_server(8001)
while True:
input_data = ... # 获取输入数据
process_input(input_data)
simulate_resource_usage()
time.sleep(1)
29.1.5. 总结
从零开始开发一个人工智能助手是一个多步骤、多层次的过程。通过合理的项目规划、技术选型、系统架构设计和关键模块的实现,可以构建出功能强大、性能优越的AI助手。Python及其相关库提供了丰富的工具和功能,可以大大简化AI助手的开发过程,提高工作效率。通过本章的学习,您将能够掌握从零开始开发AI助手的方法,并将其应用于实际项目中,打造出智能、高效的AI助手。
29.2 对话管理系统的设计与实现
对话管理系统(Dialogue Management System, DMS)是AI助手的核心组件,负责处理用户输入、跟踪对话状态、管理对话流程以及生成适当的响应。一个高效且智能的对话管理系统能够显著提升AI助手的用户体验和交互质量。以下将详细介绍对话管理系统的设计与实现方法,并通过具体示例展示如何构建一个功能完善的对话管理系统。
29.2.1. 对话管理系统的基本概念
对话管理系统的主要功能包括:
- 意图识别(Intent Recognition):理解用户输入的意图,例如查询天气、设置提醒、询问信息等。
- 实体抽取(Entity Extraction):从用户输入中提取关键信息,如日期、地点、数量等。
- 对话状态跟踪(Dialogue State Tracking, DST):跟踪对话的当前状态,包括用户的目标、已提供的信息等。
- 对话策略(Dialogue Policy):根据当前状态和用户输入,决定下一步的行动,例如查询数据库、调用API、生成回复等。
- 自然语言生成(Natural Language Generation, NLG):生成自然语言响应,反馈给用户。
29.2.2. 对话管理系统的设计
29.2.2.1 模块化设计
将对话管理系统拆分为多个模块,每个模块负责特定的功能:
1.输入处理模块:接收用户输入,进行预处理,如分词、去停用词等。
2.意图识别模块:识别用户输入的意图。
3.实体抽取模块:提取用户输入中的实体信息。
4.对话状态跟踪模块:跟踪对话的当前状态。
5.对话策略模块:决定下一步的行动。
6.响应生成模块:生成自然语言响应。
示例:模块化设计
class DialogueManager:
def __init__(self):
self.intent_recognizer = IntentRecognizer()
self.entity_extractor = EntityExtractor()
self.state_tracker = DialogueStateTracker()
self.policy = DialoguePolicy()
self.nlg = NaturalLanguageGenerator()
def process(self, user_input):
intent = self.intent_recognizer.recognize(user_input)
entities = self.entity_extractor.extract(user_input)
self.state_tracker.update_state(intent, entities)
action = self.policy.decide(self.state_tracker.state)
response = self.nlg.generate(action, self.state_tracker.state)
return response
29.2.2.2 状态管理
对话状态跟踪(DST)是对话管理的关键部分,负责维护对话的当前状态。可以使用有限状态机(Finite State Machine, FSM)或基于框架的方法进行状态管理。
示例:使用有限状态机进行状态管理
from transitions import Machine
class DialogueStateTracker:
states = ['idle', 'greeting', 'weather_query', 'reminder_set', 'goodbye']
def __init__(self):
self.machine = Machine(model=self, states=DialogueStateTracker.states, initial='idle')
self.machine.add_transition('greet', 'idle', 'greeting')
self.machine.add_transition('ask_weather', 'greeting', 'weather_query')
self.machine.add_transition('set_reminder', 'weather_query', 'reminder_set')
self.machine.add_transition('end', 'reminder_set', 'goodbye')
self.state = self.machine.state
def update_state(self, intent):
if intent == 'greet':
self.greet()
elif intent == 'ask_weather':
self.ask_weather()
elif intent == 'set_reminder':
self.set_reminder()
elif intent == 'end':
self.end()
29.2.2.3 对话策略
对话策略模块根据当前状态和用户输入,决定下一步的行动。可以使用规则引擎或基于机器学习的方法进行策略决策。
示例:使用规则引擎进行对话策略
class DialoguePolicy:
def decide(self, state):
if state == 'idle':
return 'greet'
elif state == 'greeting':
return 'ask_weather'
elif state == 'weather_query':
return 'set_reminder'
elif state == 'reminder_set':
return 'end'
else:
return 'goodbye'
29.2.2.4 自然语言生成(NLG)
自然语言生成模块负责生成自然语言响应。可以使用模板、规则或基于深度学习的方法进行生成。
示例:使用模板进行自然语言生成
class NaturalLanguageGenerator:
def generate(self, action, state):
if action == 'greet':
return "Hello! How can I assist you today?"
elif action == 'ask_weather':
return "What is the weather like today?"
elif action == 'set_reminder':
return "Sure, what would you like to be reminded of?"
elif action == 'end':
return "Goodbye! Have a nice day!"
else:
return "I'm sorry, I didn't understand that."
29.2.3. 实现示例
以下是一个综合的对话管理系统实现示例,展示了如何使用Python构建一个简单的对话管理系统。
class IntentRecognizer:
def recognize(self, text):
# 简单的意图识别逻辑
if "weather" in text:
return "ask_weather"
elif "reminder" in text:
return "set_reminder"
elif "hello" in text or "hi" in text:
return "greet"
elif "goodbye" in text:
return "end"
else:
return "unknown"
class EntityExtractor:
def extract(self, text):
# 简单的实体抽取逻辑
entities = {}
if "weather" in text:
entities['topic'] = 'weather'
if "reminder" in text:
entities['topic'] = 'reminder'
return entities
class DialogueStateTracker:
def __init__(self):
self.state = "idle"
def update_state(self, intent):
if intent == "greet":
self.state = "greeting"
elif intent == "ask_weather":
self.state = "weather_query"
elif intent == "set_reminder":
self.state = "reminder_set"
elif intent == "end":
self.state = "goodbye"
else:
self.state = "idle"
class DialoguePolicy:
def decide(self, state):
if state == "idle":
return "greet"
elif state == "greeting":
return "ask_weather"
elif state == "weather_query":
return "set_reminder"
elif state == "reminder_set":
return "end"
else:
return "goodbye"
class NaturalLanguageGenerator:
def generate(self, action, state):
responses = {
"greet": "Hello! How can I assist you today?",
"ask_weather": "What is the weather like today?",
"set_reminder": "Sure, what would you like to be reminded of?",
"end": "Goodbye! Have a nice day!",
"unknown": "I'm sorry, I didn't understand that."
}
return responses.get(action, "I'm not sure how to respond to that.")
class DialogueManager:
def __init__(self):
self.intent_recognizer = IntentRecognizer()
self.entity_extractor = EntityExtractor()
self.state_tracker = DialogueStateTracker()
self.policy = DialoguePolicy()
self.nlg = NaturalLanguageGenerator()
def process(self, user_input):
intent = self.intent_recognizer.recognize(user_input)
entities = self.entity_extractor.extract(user_input)
self.state_tracker.update_state(intent)
action = self.policy.decide(self.state_tracker.state)
response = self.nlg.generate(action, self.state_tracker.state)
return response
# 示例对话
dialogue_manager = DialogueManager()
user_inputs = ["Hello", "What is the weather like today?", "Set a reminder for tomorrow", "Goodbye"]
for input in user_inputs:
print(f"User: {input}")
print(f"AI: {dialogue_manager.process(input)}")
print()
输出结果:
User: Hello
AI: Hello! How can I assist you today?
User: What is the weather like today?
AI: What is the weather like today?
User: Set a reminder for tomorrow
AI: Sure, what would you like to be reminded of?
User: Goodbye
AI: Goodbye! Have a nice day!
29.2.4. 总结
对话管理系统是AI助手的核心组件,通过合理的模块化设计、状态管理和对话策略,可以构建出高效、智能的对话管理系统。Python及其相关库提供了丰富的工具和功能,可以大大简化对话管理系统的实现过程,提高工作效率。通过本章的学习,您将能够掌握对话管理系统的设计与实现方法,并将其应用于AI助手的实战中,打造出智能、流畅的对话体验。
29.3 自然语言处理模块的集成与优化
在AI助手的开发中,自然语言处理(NLP)模块是实现人机交互的关键部分。NLP模块负责理解用户的自然语言输入,提取关键信息,并生成相应的回复。为了实现高效、准确的NLP功能,需要对模块进行集成与优化。以下将详细介绍NLP模块的集成方法、优化策略以及具体实现,并通过示例展示如何构建一个强大的NLP模块。
29.3.1. NLP模块的集成
29.3.1.1 选择合适的NLP框架
选择一个合适的NLP框架是集成NLP模块的第一步。常见的NLP框架包括:
- Hugging Face Transformers:提供预训练的模型,支持多种NLP任务,如文本分类、命名实体识别、问答系统等。
- spaCy:高效且易于使用的NLP库,适合工业级应用,支持分词、词性标注、命名实体识别等任务。
- Stanford NLP:功能强大的NLP工具包,支持多种语言和任务。
- NLTK:适合学术研究和原型开发,提供丰富的文本处理工具。
示例:使用Hugging Face Transformers集成NLP模块
from transformers import pipeline, AutoTokenizer, AutoModelForSequenceClassification
# 加载预训练的意图识别模型
intent_model_name = "dsk010/bert-base-uncased-intent-detection"
intent_tokenizer = AutoTokenizer.from_pretrained(intent_model_name)
intent_model = AutoModelForSequenceClassification.from_pretrained(intent_model_name)
intent_nlp = pipeline("text-classification", model=intent_model, tokenizer=intent_tokenizer)
# 加载预命名实体识别模型
ner_model_name = "dbmdz/bert-large-cased-finetuned-conll03-english"
ner_tokenizer = AutoTokenizer.from_pretrained(ner_model_name)
ner_model = AutoModelForTokenClassification.from_pretrained(ner_model_name)
ner_nlp = pipeline("ner", model=ner_model, tokenizer=ner_tokenizer)
29.3.1.2 定义NLP处理流程
设计一个清晰的NLP处理流程,确保每个步骤的输入输出明确。例如:
1.预处理:文本清洗、分词、去停用词等。
2.意图识别:识别用户输入的意图。
3.实体抽取:提取用户输入中的实体信息。
4.语义理解:理解用户输入的语义,生成结构化数据。
示例:定义NLP处理流程
def preprocess(text):
# 简单的预处理:转换为小写,去除特殊字符
text = text.lower()
text = re.sub(r'[^a-zA-Z0-9\s]', '', text)
return text
def get_intent(text):
result = intent_nlp(text)
return result[0]['label']
def extract_entities(text):
entities = ner_nlp(text)
return {entity['entity_group']: entity['word'] for entity in entities}
def nlp_pipeline(text):
processed_text = preprocess(text)
intent = get_intent(processed_text)
entities = extract_entities(processed_text)
return {"intent": intent, "entities": entities}
29.3.2. NLP模块的优化
29.3.2.1 模型压缩与加速
为了提高NLP模块的推理速度,可以使用模型压缩和加速技术,如模型剪枝、量化、知识蒸馏等。
示例:使用ONNX Runtime进行模型加速
import torch
import onnxruntime
import numpy as np
# 导出模型为ONNX格式
dummy_input = torch.randn(1, 128) # 根据模型输入调整
torch.onnx.export(intent_model, dummy_input, "intent_model.onnx", opset_version=11)
# 使用ONNX Runtime进行推理
ort_session = onnxruntime.InferenceSession("intent_model.onnx")
def predict_intent(text):
inputs = intent_tokenizer.encode(text, return_tensors='np')
outputs = ort_session.run(None, {"input_ids": inputs})
return np.argmax(outputs[0], axis=1)[0]
29.3.2.2 批量处理
对多个用户输入进行批量处理,可以显著提高NLP模块的处理效率。
示例:批量处理用户输入
def batch_process(texts):
inputs = intent_tokenizer(texts, padding=True, truncation=True, return_tensors="pt")
with torch.no_grad():
outputs = intent_model(**inputs)
predictions = torch.argmax(outputs.logits, dim=1).tolist()
return [intent_nlp.model.config.id2label[pred] for pred in predictions]
29.3.2.3 缓存机制
对于重复的用户输入,可以使用缓存机制,避免重复计算,提高响应速度。
示例:使用缓存
from functools import lru_cache
@lru_cache(maxsize=1000)
def cached_nlp_pipeline(text):
return nlp_pipeline(text)
29.3.3. 综合示例
以下是一个综合的NLP模块集成与优化示例,展示了如何使用Hugging Face Transformers构建一个高效的NLP模块,并进行模型压缩和批量处理。
from transformers import pipeline, AutoTokenizer, AutoModelForSequenceClassification, AutoModelForTokenClassification
import torch
import onnxruntime
import numpy as np
from functools import lru_cache
# 1. 加载预训练的NLP模型
intent_model_name = "dsk010/bert-base-uncased-intent-detection"
intent_tokenizer = AutoTokenizer.from_pretrained(intent_model_name)
intent_model = AutoModelForSequenceClassification.from_pretrained(intent_model_name)
ner_model_name = "dbmdz/bert-large-cased-finetuned-conll03-english"
ner_tokenizer = AutoTokenizer.from_pretrained(ner_model_name)
ner_model = AutoModelForTokenClassification.from_pretrained(ner_model_name)
# 2. 定义预处理函数
def preprocess(text):
text = text.lower()
text = re.sub(r'[^a-zA-Z0-9\s]', '', text)
return text
# 3. 定义意图识别函数
def get_intent(text):
inputs = intent_tokenizer.encode(text, return_tensors='pt')
with torch.no_grad():
outputs = intent_model(inputs)
prediction = torch.argmax(outputs.logits, dim=1).item()
return intent_model.config.id2label[prediction]
# 4. 定义实体抽取函数
def extract_entities(text):
entities = ner_nlp(text)
return {entity['entity_group']: entity['word'] for entity in entities}
# 5. 定义NLP处理流程
def nlp_pipeline(text):
processed_text = preprocess(text)
intent = get_intent(processed_text)
entities = extract_entities(processed_text)
return {"intent": intent, "entities": entities}
# 6. 模型压缩与加速(使用ONNX Runtime)
# 导出意图识别模型为ONNX格式
dummy_input = torch.randn(1, 128)
torch.onnx.export(intent_model, dummy_input, "intent_model.onnx", opset_version=11)
# 使用ONNX Runtime进行推理
ort_session = onnxruntime.InferenceSession("intent_model.onnx")
def predict_intent(text):
inputs = intent_tokenizer.encode(text, return_tensors='np')
outputs = ort_session.run(None, {"input_ids": inputs})
prediction = np.argmax(outputs[0], axis=1)[0]
return intent_model.config.id2label[prediction]
# 7. 批量处理用户输入
def batch_process(texts):
inputs = intent_tokenizer(texts, padding=True, truncation=True, return_tensors="pt")
with torch.no_grad():
outputs = intent_model(**inputs)
predictions = torch.argmax(outputs.logits, dim=1).tolist()
return [intent_model.config.id2label[pred] for pred in predictions]
# 8. 使用缓存机制
@lru_cache(maxsize=1000)
def cached_nlp_pipeline(text):
return nlp_pipeline(text)
29.3.4. 总结
NLP模块的集成与优化是AI助手开发中的重要环节。通过选择合适的NLP框架、设计清晰的处理流程以及应用模型压缩、批量处理和缓存机制等优化策略,可以显著提升NLP模块的性能和效率。Python及其相关库提供了丰富的工具和功能,可以大大简化NLP模块的集成与优化过程,提高工作效率。通过本章的学习,您将能够掌握NLP模块的集成与优化方法,并将其应用于AI助手的实战中,实现更智能、更高效的AI助手。
29.4 用户界面与交互体验设计
在AI助手的开发过程中,**用户界面(UI)和交互体验(UX)**设计是至关重要的环节。一个直观、易用且响应迅速的用户界面可以显著提升用户满意度和使用体验。以下将详细介绍用户界面与交互体验设计的关键要素、设计原则以及实现方法,并通过具体示例展示如何构建一个用户友好的AI助手界面。
29.4.1. 用户界面与交互体验设计的关键要素
1. 简洁性
用户界面应尽量简洁,避免不必要的复杂元素,确保用户能够快速找到所需功能。
2. 易用性
界面设计应符合用户的认知习惯,操作流程应简单直观,减少用户的学习成本。
3. 响应速度
界面应具备快速的响应速度,确保用户操作的流畅性,避免因延迟导致的用户流失。
4. 可访问性
设计应考虑不同用户群体的需求,包括视觉障碍者、听力障碍者等,确保所有用户都能方便地使用AI助手。
5. 个性化
根据用户的使用习惯和偏好,提供个性化的界面和功能,提升用户体验。
29.4.2. 用户界面设计原则
1. 一致性
保持界面风格和交互方式的一致性,使用户能够快速适应和理解界面。
2. 反馈机制
提供及时的反馈,例如操作成功或失败的提示、加载指示器等,让用户了解当前状态。
3. 视觉层次
通过颜色、字体、大小等视觉元素,突出重要信息,引导用户的注意力。
4. 简洁的导航
设计简洁明了的导航结构,使用户能够轻松地在不同功能模块之间切换。
5. 响应式设计
确保界面在不同设备和屏幕尺寸下都能良好显示,提供一致的用户体验。
29.4.3. 实现方法
29.4.3.1 选择前端框架
选择合适的前端框架可以加快开发速度,并确保界面的响应性和可维护性。常见的前端框架包括:
- React:由Facebook开发,基于组件的架构,适合构建复杂的用户界面。
- Vue.js:轻量级且易于上手,适合快速开发和原型设计。
- Flutter:由Google开发,支持跨平台开发,可以同时构建Web、移动和桌面应用。
- Angular:由Google开发,适合构建大型企业级应用。
示例:使用React构建AI助手界面
import React, { useState } from 'react';
import axios from 'axios';
function App() {
const [input, setInput] = useState('');
const [response, setResponse] = useState('');
const [loading, setLoading] = useState(false);
const handleSend = async () => {
setLoading(true);
try {
const res = await axios.post('/api/process', { text: input });
setResponse(res.data.response);
} catch (error) {
setResponse('抱歉,我无法理解您的请求。');
}
setLoading(false);
};
return (
<div className="app">
<h1>AI助手</h1>
<div className="chat-container">
<div className="chat-log">
{/* 显示对话历史 */}
<div className="message user">你好!</div>
<div className="message ai">你好!有什么我可以帮忙的吗?</div>
</div>
<div className="input-area">
<input
type="text"
value={input}
onChange={(e) => setInput(e.target.value)}
placeholder="请输入您的消息"
/>
<button onClick={handleSend} disabled={loading}>
{loading ? '发送中...' : '发送'}
</button>
</div>
</div>
<div className="response">{response}</div>
</div>
);
}
export default App;
29.4.3.2 设计响应式布局
使用CSS框架(如Bootstrap、Tailwind CSS)或CSS Flexbox/Grid布局,实现响应式设计,确保界面在不同设备上都能良好显示。
示例:使用CSS Flexbox实现响应式布局
.app {
display: flex;
flex-direction: column;
align-items: center;
padding: 20px;
}
.chat-container {
width: 100%;
max-width: 600px;
display: flex;
flex-direction: column;
border: 1px solid #ccc;
border-radius: 5px;
padding: 10px;
}
.chat-log {
flex: 1;
overflow-y: auto;
margin-bottom: 10px;
}
.message {
margin: 5px 0;
padding: 10px;
border-radius: 5px;
}
.user {
background-color: #e6f7ff;
align-self: flex-end;
}
.ai {
background-color: #f0f0f0;
align-self: flex-start;
}
.input-area {
display: flex;
width: 100%;
}
input {
flex: 1;
padding: 10px;
border: 1px solid #ccc;
border-radius: 5px;
}
button {
margin-left: 10px;
padding: 10px;
border: none;
background-color: #007bff;
color: white;
border-radius: 5px;
cursor: pointer;
}
button:disabled {
background-color: #6c757d;
cursor: not-allowed;
}
29.4.3.3 实现实时对话
使用WebSocket或轮询技术,实现实时对话功能,确保用户与AI助手之间的交互流畅。
示例:使用WebSocket实现实时对话
import React, { useState, useEffect } from 'react';
import io from 'socket.io-client';
function App() {
const [input, setInput] = useState('');
const [response, setResponse] = useState('');
const [socket] = useState(() => io(':8000'));
useEffect(() => {
socket.on('response', (data) => {
setResponse(data);
});
return () => socket.disconnect();
}, [socket]);
const handleSend = () => {
socket.emit('message', input);
setInput('');
};
return (
<div className="app">
<h1>AI助手</h1>
<div className="chat-container">
<div className="chat-log">
{/* 显示对话历史 */}
<div className="message user">你好!</div>
<div className="message ai">你好!有什么我可以帮忙的吗?</div>
</div>
<div className="input-area">
<input
type="text"
value={input}
onChange={(e) => setInput(e.target.value)}
placeholder="请输入您的消息"
/>
<button onClick={handleSend}>发送</button>
</div>
</div>
<div className="response">{response}</div>
</div>
);
}
export default App;
29.4.4. 小结
用户界面与交互体验设计是AI助手开发中的重要环节。通过简洁、易用、响应迅速且个性化的设计,可以显著提升用户的使用体验。Python及其相关库提供了丰富的工具和功能,可以大大简化用户界面的实现过程,提高工作效率。通过本章的学习,您将能够掌握用户界面与交互体验设计的关键要素和实现方法,并将其应用于AI助手的实战中,打造出用户友好、功能强大的AI助手。
29.5 部署与持续改进:让AI助手上线并不断进化
将AI助手从开发环境部署到生产环境,并确保其能够持续改进和进化,是实现AI助手长期成功的关键步骤。部署过程不仅涉及将应用上线,还包括配置服务器、监控性能、收集用户反馈以及定期更新和优化AI模型。以下将详细介绍AI助手的部署流程、持续改进策略以及具体实现方法,并通过具体示例展示如何实现AI助手的稳定上线和持续进化。
29.5.1. 部署流程
29.5.1.1 选择部署平台
选择合适的云服务平台或自建服务器进行部署。常见的云服务平台包括:
- Amazon Web Services (AWS):提供丰富的服务,如EC2、S3、Lambda等。
- Google Cloud Platform (GCP):提供强大的AI和机器学习服务,如AI Platform、Cloud Functions等。
- Microsoft Azure:提供全面的云服务和AI工具。
- Heroku:适合快速部署和扩展,支持多种编程语言和框架。
示例:使用Heroku部署AI助手
1.安装Heroku CLI:
curl https://cli-assets.heroku.com/install.sh | sh
2.登录Heroku:
heroku login
3.创建Heroku应用:
heroku create my-ai-assistant
4.推送代码到Heroku:
git push heroku master
5.运行应用:
heroku ps:scale web=1
29.5.1.2 容器化应用
使用Docker将应用及其依赖打包成容器镜像,确保在不同环境中的一致性和可移植性。
示例:Dockerfile
FROM python:3.8-slim
WORKDIR /app
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
COPY . .
EXPOSE 8000
CMD ["uvicorn", "main:app", "--host", "0.0.0.0", "--port", "8000"]
构建Docker镜像:
docker build -t my-ai-assistant .
运行Docker容器:
docker run -d -p 8000:8000 my-ai-assistant
29.5.1.3 配置环境变量
使用环境变量管理敏感信息和配置参数,如API密钥、数据库连接字符串等。
示例:使用.env文件
DATABASE_URL=postgres://user:password@localhost:5432/mydatabase
API_KEY=your_api_key
在应用中加载环境变量:
from dotenv import load_dotenv
import os
load_dotenv()
database_url = os.getenv('DATABASE_URL')
api_key = os.getenv('API_KEY')
29.5.1.4 持续集成与持续部署(CI/CD)
配置CI/CD流水线,实现代码的自动测试、构建和部署,提高部署效率和代码质量。
示例:使用GitHub Actions进行CI/CD
name: CI/CD Pipeline
on:
push:
branches:
- master
jobs:
build:
runs-on: ubuntu-latest
steps:
- name: Checkout code
uses: actions/checkout@v2
- name: Set up Python
uses: actions/setup-python@v2
with:
python-version: '3.8'
- name: Install dependencies
run: |
python -m pip install --upgrade pip
pip install -r requirements.txt
- name: Run tests
run: |
pytest
- name: Deploy to Heroku
uses: akhileshns/heroku-deploy@v3.12.12
with:
heroku_api_key: ${{ secrets.HEROKU_API_KEY }}
heroku_app_name: 'my-ai-assistant'
heroku_email: 'your-email@example.com'
29.5.2. 持续改进策略
29.5.2.1 收集用户反馈
通过用户反馈收集机制,如问卷调查、用户访谈、应用内反馈按钮等,了解用户需求和使用体验。
示例:应用内反馈按钮
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel
app = FastAPI()
class Feedback(BaseModel):
user_id: str
feedback: str
@app.post("/feedback")
async def receive_feedback(feedback: Feedback):
# 处理反馈
return {"message": "Thank you for your feedback!"}
29.5.2.2 监控与分析
使用监控工具(如Prometheus、Grafana)和分析工具(如Google Analytics)监控应用性能和用户行为,识别问题和优化机会。
示例:使用Prometheus和Grafana进行监控
from prometheus_client import start_http_server, Summary, Gauge
import time
import random
# 定义指标
REQUEST_TIME = Summary('request_processing_seconds', 'Time spent processing request')
CPU_USAGE = Gauge('cpu_usage_percent', 'CPU usage percentage')
MEMORY_USAGE = Gauge('memory_usage_mb', 'Memory usage in MB')
# 模拟资源使用
def simulate_resource_usage():
CPU_USAGE.set(random.uniform(10, 90))
MEMORY_USAGE.set(random.uniform(100, 500))
# 监控函数
@REQUEST_TIME.time()
def process_request():
# 处理请求
...
# 启动HTTP服务器
start_http_server(8001)
while True:
process_request()
simulate_resource_usage()
time.sleep(1)
29.5.2.3 模型更新与再训练
根据用户反馈和监控数据,定期更新和再训练AI模型,提升模型性能。
示例:模型再训练
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDataset
# 加载新数据
new_data = ... # 加载新数据
new_labels = ... # 加载新标签
dataset = TensorDataset(torch.tensor(new_data), torch.tensor(new_labels))
dataloader = DataLoader(dataset, batch_size=32, shuffle=True)
# 定义模型
model = ... # 定义模型
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=1e-3)
# 模型再训练
for epoch in range(num_epochs):
for inputs, labels in dataloader:
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
print(f'Epoch [{epoch + 1}/{num_epochs}], Loss: {loss.item()}')
# 保存更新后的模型
torch.save(model.state_dict(), "updated_model.pth")
29.5.2.4 A/B测试
通过A/B测试评估不同版本的功能或模型,选取最优方案进行推广。
示例:A/B测试
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel
import random
app = FastAPI()
class UserRequest(BaseModel):
user_id: str
input: str
@app.post("/process")
async def process_request(request: UserRequest):
if random.random() < 0.5:
# 版本A
response = "Hello! How can I assist you today?"
else:
# 版本B
response = "Hi! What can I do for you?"
return {"response": response}
29.5.3. 小结
部署与持续改进是AI助手开发中的重要环节。通过合理的部署流程、持续改进策略以及有效的监控和分析,可以确保AI助手在生产环境中的稳定性和长期成功。Python及其相关库提供了丰富的工具和功能,可以大大简化部署与持续改进的实现过程,提高工作效率。通过本章的学习,您将能够掌握AI助手的部署与持续改进方法,并将其应用于实际项目中,打造出智能、高效且不断进化的AI助手。
第九部分:Python的最佳实践——代码优化与项目管理
第三十章:编写高效代码:Python如何跑得更快
- 时间复杂度与空间复杂度:如何用Python写出“高效代码”。
- 性能调优与内存管理:如何让Python为你“省心”。
30.1 时间复杂度与空间复杂度:如何用Python写出“高效代码”
欢迎来到“高效编程”的魔法学院!在编写代码时,效率是衡量代码质量的重要指标之一。高效代码不仅能更快地完成任务,还能节省计算资源和存储空间。在本章中,我们将深入探讨时间复杂度和空间复杂度,这两个关键概念将帮助你理解如何用Python写出“高效代码”。就像魔法师需要精确计算魔法的消耗一样,编写高效代码也需要对时间和空间的消耗有清晰的认识。
30.1.1 什么是时间复杂度?
时间复杂度是衡量算法运行时间随输入规模增长而增长的方式。它描述了算法在最坏情况下的运行时间,通常用大O符号(Big O Notation)表示。时间复杂度关注的是算法运行时间随着输入规模增长的趋势,而不是具体的执行时间。
比喻:如果算法是一个魔法咒语,那么时间复杂度就是咒语施展所需的时间,随着魔法材料的增加,施展时间也会相应增加。
30.1.1.1 常见的时间复杂度
1. O(1)(常数时间):
算法运行时间不随输入规模变化而变化。
示例:
def get_first_element(lst):
return lst[0]
解释:无论列表多大,访问第一个元素的时间都是恒定的。
2. O(log n)(对数时间):
算法运行时间随输入规模的对数增长而增长。
示例:
def binary_search(lst, target):
left, right = 0, len(lst) - 1
while left <= right:
mid = (left + right) // 2
if lst[mid] == target:
return mid
elif lst[mid] < target:
left = mid + 1
else:
right = mid - 1
return -1
解释:二分查找每次将搜索范围减半,运行时间与输入规模的对数成正比。
3. O(n)(线性时间):
算法运行时间随输入规模线性增长。
示例:
def find_max(lst):
max_val = lst[0]
for num in lst:
if num > max_val:
max_val = num
return max_val
解释:遍历列表中的每个元素,运行时间与列表长度成正比。
4. O(n log n)(线性对数时间):
算法运行时间随输入规模的线性对数增长。
示例:
def merge_sort(lst):
if len(lst) <= 1:
return lst
mid = len(lst) // 2
left = merge_sort(lst[:mid])
right = merge_sort(lst[mid:])
return merge(left, right)
解释:归并排序的时间复杂度为O(n log n)。
5. O(n²)(二次时间):
算法运行时间随输入规模的平方增长。
示例:
def bubble_sort(lst):
n = len(lst)
for i in range(n):
for j in range(0, n-i-1):
if lst[j] > lst[j+1]:
lst[j], lst[j+1] = lst[j+1], lst[j]
return lst
解释:冒泡排序的时间复杂度为O(n²)。
6. O(2ⁿ)(指数时间):
算法运行时间随输入规模指数增长。
示例:
def fibonacci(n):
if n <= 1:
return n
return fibonacci(n-1) + fibonacci(n-2)
解释:递归计算斐波那契数列的时间复杂度为O(2ⁿ)。
30.1.1.2 如何分析时间复杂度
1. 确定基本操作:
确定算法中执行次数最多的操作。
示例:
- 在线性搜索中,基本操作是比较操作。
2. 分析循环结构:
分析循环的嵌套和迭代次数。
示例:
- 单层循环:O(n)
- 两层嵌套循环:O(n²)
3. 考虑递归调用:
分析递归调用的深度和分支。
示例:
- 简单的递归函数:O(n)
- 分治递归(如归并排序):O(n log n)
30.1.2 什么是空间复杂度?
空间复杂度是衡量算法运行所需存储空间随输入规模增长而增长的方式。它描述了算法在最坏情况下的存储需求,通常也用大O符号表示。空间复杂度关注的是算法运行所需的空间随着输入规模增长的趋势,而不是具体的存储需求。
比喻:如果算法是一个魔法咒语,那么空间复杂度就是施展咒语所需的魔法材料数量,随着魔法材料的增加,所需材料也会相应增加。
30.1.2.1 常见的空间复杂度
1. O(1)(常数空间):
算法所需的空间不随输入规模变化而变化。
示例:
def sum(lst):
total = 0
for num in lst:
total += num
return total
解释:无论列表多大,所需的空间都是恒定的。
2. O(n)(线性空间):
算法所需的空间随输入规模线性增长。
示例:
def copy_list(lst):
new_lst = []
for item in lst:
new_lst.append(item)
return new_lst
解释:需要存储一个与输入列表大小相同的列表。
3. O(n²)(二次空间):
算法所需的空间随输入规模的平方增长。
示例:
def create_matrix(n):
matrix = []
for i in range(n):
row = []
for j in range(n):
row.append(0)
matrix.append(row)
return matrix
解释:需要存储一个n×n的矩阵,空间需求为O(n²)。
30.1.3 如何优化时间复杂度和空间复杂度
1. 选择合适的算法:
- 根据问题选择时间复杂度更优的算法。
- 示例:
- 使用二分查找(O(log n))代替线性搜索(O(n))。
2. 减少不必要的计算:
- 避免重复计算,使用缓存或记忆化技术。
- 示例:
from functools import lru_cache @lru_cache(maxsize=None) def fibonacci(n): if n <= 1: return n return fibonacci(n-1) + fibonacci(n-2)
3. 优化数据结构:
- 选择合适的数据结构来提高效率。
- 示例:
- 使用集合(set)进行快速查找,而不是列表(list)。
4. 使用生成器:
- 使用生成器(generator)来节省内存空间。
- 示例:
def count(): n = 0 while True: yield n n += 1
30.1.4 小结:高效代码的魔法
通过本节,你已经学习了时间复杂度和空间复杂度的概念,就像掌握了“高效代码”的魔法技巧。时间复杂度和空间复杂度是衡量算法效率的重要指标,理解它们可以帮助你编写更高效的Python代码。希望你能灵活运用这些“高效魔法”,让你的代码在时间和空间上都表现出色,为编写更强大的Python程序打下坚实的基础。
30.2 性能调优与内存管理:如何让Python为你“省心”
欢迎来到“性能优化”的魔法工坊!在编写Python程序时,性能调优和内存管理就像是两位能够让你的代码运行得更高效、更顺畅的“魔法师”。通过合理的性能调优,你可以显著提升程序的运行速度,而良好的内存管理则能确保程序在处理大数据时依然稳定可靠。今天,我们将深入探讨如何进行性能调优和内存管理,让Python为你“省心”。
30.2.1 性能调优:让代码跑得更快
性能调优是指通过各种技术和方法,提升程序的运行效率。以下是一些常见的性能调优策略:
30.2.1.1 使用内置函数和标准库
Python的内置函数和标准库通常是用C语言实现的,性能远高于纯Python代码。
示例:
# 使用内置sum函数
total = sum(numbers)
# 避免使用循环累加
total = 0
for num in numbers:
total += num
解释:内置的sum函数比手写的循环累加更快。
30.2.1.2 避免不必要的循环
尽量减少循环的次数,或使用更高效的迭代方式。
示例:
# 使用列表推导式代替显式循环
squares = [x**2 for x in range(1000)]
# 避免使用显式循环
squares = []
for x in range(1000):
squares.append(x**2)
解释:列表推导式通常比显式循环更快。
30.2.1.3 使用生成器
生成器可以按需生成数据,节省内存并提高性能。
示例:
# 使用生成器表达式
def generate_squares(n):
for x in range(n):
yield x**2
squares = generate_squares(1000)
# 避免使用列表
squares = [x**2 for x in range(1000)]
解释:生成器表达式不会一次性生成所有数据,节省内存并提高效率。
30.2.1.4 使用C扩展或Cython
对于性能关键的部分,可以使用C扩展或Cython将Python代码转换为C代码。
示例:
# 使用Cython
# example.pyx
def add(int a, int b):
return a + b
解释:Cython可以将Python代码编译为C代码,提升性能。
30.2.1.5 使用JIT编译器
JIT(Just-In-Time)编译器可以在运行时将Python代码编译为机器码,提升性能。
工具:
- PyPy:一个Python解释器,内置JIT编译器,性能通常比CPython快好几倍。
- Numba:一个JIT编译器,可以将Python函数编译为机器码,特别适用于数值计算。
示例:
from numba import jit
@jit
def add(a, b):
return a + b
解释:使用Numba的@jit装饰器可以显著提升数值计算的性能。
30.2.2 内存管理:让程序更稳定
内存管理是指有效地分配和释放内存资源,以避免内存泄漏和过度使用。以下是一些常见的内存管理策略:
30.2.2.1 使用生成器和迭代器
生成器和迭代器可以按需生成数据,节省内存。
示例:
# 使用生成器
def read_large_file(file_path):
with open(file_path, 'r') as file:
for line in file:
yield line
# 避免使用列表
def read_large_file(file_path):
with open(file_path, 'r') as file:
return file.readlines()
解释:生成器不会一次性将整个文件加载到内存中,节省内存。
30.2.2.2 使用适当的数据结构
选择合适的数据结构可以显著减少内存使用。
示例:
# 使用集合(set)代替列表(list)进行查找
my_set = {1, 2, 3, 4, 5}
if 3 in my_set:
print("Found")
# 避免使用列表
my_list = [1, 2, 3, 4, 5]
if 3 in my_list:
print("Found")
解释:集合的查找操作比列表更快,且在某些情况下占用更少内存。
30.2.2.3 避免循环引用
循环引用会导致垃圾回收器无法回收内存,可能导致内存泄漏。
示例:
class Node:
def __init__(self, value):
self.value = value
self.next = None
a = Node(1)
b = Node(2)
a.next = b
b.next = a # 循环引用
解释:避免在对象之间创建循环引用,或使用weakref模块来打破循环引用。
30.2.2.4 使用__slots__
使用__slots__可以减少每个对象实例的内存占用。
示例:
class MyClass:
__slots__ = ['attribute1', 'attribute2']
def __init__(self, value1, value2):
self.attribute1 = value1
self.attribute2 = value2
解释:默认情况下,Python使用字典来存储对象的属性,使用__slots__可以避免使用字典,从而节省内存。
30.2.3 小结:性能调优与内存管理的魔法
通过本节,你已经学习了性能调优和内存管理的基本策略,就像掌握了“性能优化”的魔法技巧。性能调优和内存管理是编写高效Python程序的重要环节,希望你能灵活运用这些“优化魔法”,让你的代码在运行速度和内存使用上都能表现出色,为编写更强大的Python程序打下坚实的基础。
第三十一章:代码的可维护性:如何写出“别人看得懂”的代码
- 良好的代码风格:PEP8标准与代码重构。
- 单元测试与调试技巧:如何让你的代码无懈可击。
31.1 良好的代码风格:PEP8标准与代码重构
欢迎来到“代码可维护性”的魔法工坊!在软件开发的世界里,代码的可维护性就像是让代码保持“青春永驻”的魔法。它不仅关乎代码的当前功能,更关乎未来是否易于修改、扩展和理解。一个具有良好可维护性的代码库,可以让团队协作更加顺畅,减少bug的出现,并提高开发效率。今天,我们将深入探讨如何通过良好的代码风格和代码重构,来提升代码的可维护性。
31.1.1 什么是代码风格?
代码风格是指编写代码时所遵循的一系列约定和规则,包括命名规范、缩进、注释、代码组织等。良好的代码风格不仅让代码看起来更整洁,还能提高代码的可读性和可维护性。
比喻:如果代码是一篇文学作品,那么代码风格就是它的排版和语法规范,良好的风格让读者更容易理解和欣赏。
31.1.2 PEP8:Python的编码规范
PEP8是Python的官方编码规范,旨在提高Python代码的一致性和可读性。遵循PEP8可以让你的代码更符合社区标准,更易于被其他开发者理解和维护。
31.1.2.1 PEP8的主要规则
1. 缩进:
- 使用4个空格进行缩进,而不是制表符(Tab)。
- 示例:
def my_function(): if True: print("Hello, World!")
2. 行长度:
- 每行代码的最大长度建议为79个字符。
- 示例:
# 过长时可以换行 total = first_variable + second_variable + third_variable + fourth_variable
3. 空行:
使用两个空行分隔顶层函数和类定义。
使用一个空行分隔类中的方法定义。
示例:
def function_one():
pass
def function_two():
pass
class MyClass:
def method_one(self):
pass
def method_two(self):
pass
4. 导入:
导入语句应放在文件的顶部,分组顺序为:标准库、第三方库、本地应用。
示例:
import os
import sys
import numpy as np
import pandas as pd
from my_module import my_function
5. 命名规范:
- 变量和函数名:使用小写字母和下划线分隔(snake_case)。
- 示例:
my_variable,calculate_sum
- 示例:
- 类名:使用首字母大写的驼峰命名法(PascalCase)。
- 示例:
MyClass,DataProcessor
- 示例:
- 常量:使用全大写字母和下划线分隔。
- 示例:
MAX_SIZE,DEFAULT_TIMEOUT
- 示例:
6. 注释:
使用#号进行单行注释,注释应简洁明了。
示例:
# 计算两个数的和
def add(a, b):
return a + b
7. 文档字符串:
为模块、类和函数编写文档字符串(docstrings),描述其功能、参数和返回值。
示例:
def add(a, b):
"""
返回两个数的和。
参数:
a (int or float): 第一个数
b (int or float): 第二个数
返回:
int or float: 两个数的和
"""
return a + b
31.1.2.2 代码重构
代码重构是指在不改变代码外部行为的前提下,对代码进行修改,以提高其可读性、可维护性或性能。重构是提升代码质量的重要手段。
常见重构方法:
1. 提取方法:
2. 重命名变量:
3. 简化条件表达式:
4. 使用函数式编程:
将重复的代码提取到一个独立的方法中。
示例:
# 重构前
def process_data(data):
# 重复代码
cleaned_data = [x for x in data if x > 0]
# 重复代码
return cleaned_data
# 重构后
def clean_data(data):
return [x for x in data if x > 0]
def process_data(data):
cleaned_data = clean_data(data)
return cleaned_data
使用更具描述性的名称,提高代码可读性。
示例:
# 重构前
a = 10
b = 20
c = a + b
# 重构后
first_number = 10
second_number = 20
total = first_number + second_number
使用更简洁的条件判断,提高代码可读性。
示例:
# 重构前
if status == 'active' or status == 'pending':
print("Valid status")
# 重构后
if status in ('active', 'pending'):
print("Valid status")
使用高阶函数(如map, filter, reduce)简化代码。
示例:
# 重构前
numbers = [1, 2, 3, 4, 5]
squares = []
for num in numbers:
squares.append(num ** 2)
# 重构后
numbers = [1, 2, 3, 4, 5]
squares = list(map(lambda x: x ** 2, numbers))
31.1.3 小结:代码风格的魔法
通过本节,你已经学习了如何通过遵循PEP8标准和进行代码重构,来提升代码的可维护性,就像掌握了“代码风格”的魔法技巧。良好的代码风格和重构可以显著提高代码的可读性和可维护性,希望你能灵活运用这些“风格魔法”,让你的代码更加整洁、易懂,为编写更强大的Python程序打下坚实的基础。
31.2 单元测试与调试技巧:如何让你的代码无懈可击
欢迎来到“代码无懈可击”的魔法实验室!在软件开发过程中,单元测试和调试就像是守护代码健康的两位“守护魔法师”。单元测试确保代码按预期工作,而调试则帮助我们找到并修复代码中的问题。通过掌握这些技巧,你可以让代码更加健壮、可靠,并减少潜在的bug。今天,我们将深入探讨如何进行单元测试和调试,让你的代码无懈可击。
31.2.1 单元测试:确保代码的正确性
单元测试是对软件中的最小可测试单元(通常是函数或方法)进行验证的过程。单元测试的目的是确保每个单元都按照预期工作,从而提高代码的可靠性和稳定性。
31.2.1.1 为什么需要单元测试?
1. 提高代码质量:
- 通过测试可以发现并修复代码中的bug,提高代码的可靠性。
2. 便于维护和重构:
- 单元测试可以作为代码的“防护网”,在修改代码时确保现有功能不被破坏。
3. 促进更好的设计:
- 编写单元测试可以促使开发者编写更模块化、可测试的代码。
31.2.1.2 使用unittest模块进行单元测试
Python内置的unittest模块提供了一套丰富的工具来进行单元测试。
示例:测试一个简单的加法函数
import unittest
def add(a, b):
return a + b
class TestAddFunction(unittest.TestCase):
def test_add_positive_numbers(self):
self.assertEqual(add(2, 3), 5)
def test_add_negative_numbers(self):
self.assertEqual(add(-2, -3), -5)
def test_add_zero(self):
self.assertEqual(add(0, 0), 0)
def test_add_floats(self):
self.assertAlmostEqual(add(2.5, 3.1), 5.6)
if __name__ == '__main__':
unittest.main()
解释:
unittest.TestCase是所有测试用例的基类。self.assertEqual()断言两个值相等。self.assertAlmostEqual()断言两个浮点数几乎相等。
31.2.1.3 使用pytest进行单元测试
pytest是一个功能强大且易于使用的第三方测试框架,广泛应用于Python社区。
安装pytest:
pip install pytest
示例:使用pytest测试加法函数
# test_add.py
def add(a, b):
return a + b
def test_add_positive_numbers():
assert add(2, 3) == 5
def test_add_negative_numbers():
assert add(-2, -3) == -5
def test_add_zero():
assert add(0, 0) == 0
def test_add_floats():
assert add(2.5, 3.1) == 5.6
运行测试:
pytest test_add.py
31.2.1.4 模拟(Mocking)
在单元测试中,有时需要模拟外部依赖,如文件、网络请求、数据库等。unittest.mock模块提供了强大的模拟功能。
示例:模拟一个函数调用
from unittest.mock import patch
import unittest
def get_random_number():
import random
return random.randint(1, 100)
class TestGetRandomNumber(unittest.TestCase):
@patch('random.randint', return_value=42)
def test_get_random_number(self, mock_randint):
self.assertEqual(get_random_number(), 42)
mock_randint.assert_called_once_with(1, 100)
if __name__ == '__main__':
unittest.main()
31.2.2 调试技巧:找到并修复问题
调试是发现和修复代码中问题的过程。以下是一些常用的调试技巧:
31.2.2.1 使用print语句
在代码中插入print语句,输出变量的值和程序的执行流程。
示例:
def divide(a, b):
print(f"a = {a}, b = {b}")
result = a / b
print(f"result = {result}")
return result
31.2.2.2 使用logging模块
logging模块提供了更灵活的日志记录功能,可以设置不同的日志级别和输出方式。
示例:
import logging
logging.basicConfig(level=logging.DEBUG)
def divide(a, b):
logging.debug(f"a = {a}, b = {b}")
result = a / b
logging.debug(f"result = {result}")
return result
31.2.2.3 使用调试器(pdb)
pdb是Python的内置调试器,可以在代码中设置断点,逐步执行代码,检查变量。
示例:
import pdb
def divide(a, b):
pdb.set_trace() # 设置断点
return a / b
divide(10, 2)
常用命令:
n(next):执行下一行代码。c(continue):继续执行,直到下一个断点。l(list):查看当前代码上下文。p(print):打印变量值。
31.2.2.4 使用IDE的调试工具
现代IDE(如PyCharm、VSCode)提供了强大的图形化调试工具,可以设置断点、逐步执行、查看变量、评估表达式等。
示例(VSCode):
1.设置断点:点击行号左侧,设置断点。
2.启动调试:按F5启动调试模式。
3.逐步执行:使用调试工具栏上的按钮,逐步执行代码。
4.查看变量:在“变量”面板中查看变量的值。
31.2.3 小结:代码无懈可击的魔法
通过本节,你已经学习了单元测试和调试的基本技巧,就像掌握了“代码无懈可击”的魔法。单元测试和调试是确保代码质量和可靠性的重要手段,希望你能灵活运用这些“守护魔法”,让你的代码更加健壮、可靠,为编写更强大的Python程序打下坚实的基础。
第三十二章:项目管理与部署:将代码推向“实战”
- 使用Git进行版本控制与团队协作。
- 部署Python应用:如何把代码变成实际可用的应用。
32.1 使用Git进行版本控制与团队协作
欢迎来到“代码实战”的魔法战场!在软件开发的过程中,版本控制和团队协作就像是让你的代码从实验室走向战场的“指挥官”和“后勤官”。通过有效的版本控制,你可以确保代码的开发过程有序进行,而通过良好的团队协作,你可以充分发挥团队的力量,共同完成项目。今天,我们将深入探讨如何使用Git进行版本控制与团队协作,这是项目管理中至关重要的一环。
32.1.1 什么是版本控制?
版本控制是指系统地记录和管理代码在不同时间点的变化。它可以帮助开发者:
- 跟踪更改:记录每次代码修改的内容、时间和作者。
- 恢复旧版本:在需要时,可以轻松恢复到之前的代码版本。
- 协作开发:允许多个开发者同时在同一个项目上工作,而不会互相干扰。
32.1.2 Git的基本概念
在使用Git之前,了解一些基本概念是非常重要的:
仓库(Repository):
定义:仓库是存储代码和版本历史的地方。可以是本地的,也可以是远程的(如GitHub、GitLab)。
示例:
git init # 初始化本地仓库
git clone https://github.com/username/repository.git # 克隆远程仓库
提交(Commit):
定义:提交是代码的一个快照,记录了自上次提交以来的所有更改。
示例:
git commit -m "修复了登录功能的bug"
分支(Branch):
定义:分支是代码的一个独立版本,可以独立于主分支进行开发。
常用分支:
main或master:主分支,通常用于发布稳定的版本。
develop:开发分支,用于集成各个功能。
feature/xxx:功能分支,用于开发新功能。
bugfix/xxx:bug修复分支,用于修复特定bug。
示例:
git checkout -b feature/new-feature # 创建并切换到新功能分支
合并(Merge):
- 定义:合并是将一个分支的更改整合到另一个分支的过程。
- 示例:
git checkout main git merge feature/new-feature
拉取请求(Pull Request):
- 定义:拉取请求是向团队其他成员展示你的更改,并请求他们审查和合并的过程。
- 常用平台:GitHub、GitLab、Bitbucket。
32.1.3 Git的基本操作
32.1.3.1 初始化仓库
在现有项目中使用Git:
cd /path/to/your/project
git init
解释:在当前目录初始化一个Git仓库。
克隆远程仓库:
git clone https://github.com/username/repository.git
解释:将远程仓库克隆到本地。
32.1.3.2 查看状态
查看当前状态:
git status
解释:显示工作目录和暂存区的状态。
32.1.3.3 添加更改到暂存区
添加所有更改:
git add .
解释:将所有更改添加到暂存区。
添加特定文件:
git add filename.py
32.1.3.4 提交更改
提交更改:
git commit -m "描述更改内容"
解释:将暂存区的更改提交到本地仓库。
32.1.3.5 推送更改到远程仓库
推送更改:
git push origin main
解释:将本地main分支的更改推送到远程仓库的origin。
32.1.3.6 从远程仓库拉取更改
拉取更改:
git pull origin main
解释:从远程仓库的main分支拉取最新更改并合并到本地。
32.1.4 团队协作的最佳实践
1. 频繁提交:
解释:经常进行小的、描述性的提交,便于跟踪更改和回滚。
示例:
git commit -m "添加用户登录功能"
2. 使用分支:
解释:为每个新功能或bug修复创建独立的分支,避免直接在主分支上开发。
示例:
git checkout -b feature/user-authentication
3. 代码审查:
解释:使用拉取请求(Pull Request)进行代码审查,确保代码质量和一致性。
示例:
# 在GitHub上创建一个拉取请求
4. 保持同步:
解释:经常从远程仓库拉取最新更改,避免合并冲突。
示例:
git pull origin main
5. 解决冲突:
解释:当出现合并冲突时,及时解决,确保代码库的稳定性。
示例:
# 解决冲突后
git add conflicted_file.py
git commit
32.1.5 小结:Git的魔法
通过本节,你已经学习了如何使用Git进行版本控制与团队协作,就像掌握了“时间魔法”的技巧。Git是现代软件开发中不可或缺的工具,它可以帮助你有效地管理代码版本,促进团队协作。希望你能灵活运用这些“时间魔法”,让你的项目开发过程更加顺畅、高效,为编写更强大的Python应用打下坚实的基础。
32.2 部署Python应用:如何把代码变成实际可用的应用
欢迎来到“代码实战”的最终阶段——部署!在软件开发的过程中,部署就像是将你的代码从实验室推向战场的“后勤官”,它负责将你的代码转化为实际可用的应用,并确保其在生产环境中稳定运行。今天,我们将深入探讨如何将Python应用部署到生产环境,让你的代码真正“活”起来。
32.2.1 什么是部署?
部署是指将开发完成的软件应用发布到生产环境,使其能够被最终用户访问和使用。部署不仅仅是将代码上传到服务器,还包括配置服务器环境、设置数据库、配置网络、安全性设置、监控和维护等。
比喻:如果代码是一辆新车,那么部署就是将新车从工厂开上公路,并确保它在各种路况下都能平稳运行。
32.2.2 部署前的准备工作
在将应用部署到生产环境之前,需要进行一些准备工作:
1. 代码优化与测试:
- 确保代码经过充分的测试,没有明显的bug。
- 进行性能优化,确保应用在生产环境下的响应速度。
2. 环境配置:
- 确定生产环境所需的软件和依赖,如Python版本、库版本等。
- 使用虚拟环境(如
venv或virtualenv)隔离项目依赖。
3. 配置文件管理:
- 将敏感信息(如数据库密码、API密钥)存储在环境变量或配置文件中,并确保这些文件不被版本控制系统跟踪。
4. 数据库迁移:
- 如果应用使用数据库,确保数据库模式与代码同步,并进行必要的迁移。
32.2.3 常见的部署方式
32.2.3.1 使用平台即服务(PaaS)
平台即服务(PaaS)提供了一种简化的部署方式,开发者无需管理底层服务器,只需专注于应用代码。
常见平台:
- Heroku:
- 优点:易于使用,支持多种编程语言,集成CI/CD。
- 示例:
# 安装Heroku CLI heroku login git init heroku create git add . git commit -m "Initial commit" git push heroku master
- Google App Engine:
- 优点:与Google Cloud Platform集成,支持自动扩展。
- AWS Elastic Beanstalk:
- 优点:与AWS生态系统集成,支持多种语言和框架。
32.2.3.2 使用虚拟私有服务器(VPS)
虚拟私有服务器(VPS)提供了更大的灵活性和控制权,但需要开发者自行管理服务器环境。
-
常见平台:
- DigitalOcean、Linode、AWS EC2、Google Compute Engine。
-
部署步骤:
1.选择服务器:- 选择合适的VPS提供商和配置。
- 安装必要的软件,如Python、数据库、Web服务器(如Nginx、Gunicorn)。
- 使用Git、SCP或其他工具将代码上传到服务器。
- 配置环境变量和配置文件。
- 使用进程管理工具(如systemd、supervisor)启动应用。
- 配置Nginx等Web服务器作为反向代理,处理HTTP请求。
32.2.3.3 使用容器化技术
容器化是一种将应用及其依赖打包到一个容器中的技术,提供了更高的可移植性和一致性。
工具:
- Docker:
- 优点:轻量级,易于部署和扩展,支持版本控制。
- 示例:
# Dockerfile FROM python:3.9-slim WORKDIR /app COPY requirements.txt . RUN pip install --no-cache-dir -r requirements.txt COPY . . CMD ["gunicorn", "app:app", "--bind", "0.0.0.0:8000"]# 构建镜像 docker build -t my-python-app . # 运行容器 docker run -d -p 8000:8000 my-python-app
32.2.4 部署后的维护与监控
部署完成后,需要进行持续的维护和监控,以确保应用的稳定性和性能。
1. 日志管理:
- 收集和分析应用日志,及时发现和解决问题。
2. 性能监控:
- 使用监控工具(如Prometheus、Grafana)监控应用的性能指标,如CPU使用率、内存使用率、响应时间等。
3. 自动扩展:
- 根据流量和负载,自动调整应用实例的数量,确保应用在高负载下依然稳定。
4. 安全性更新:
- 定期更新软件和依赖,修补已知的安全漏洞。
32.2.5 小结:部署的魔法
通过本节,你已经学习了如何将Python应用部署到生产环境,就像掌握了“部署魔法”的技巧。部署是将代码转化为实际应用的关键步骤,希望你能灵活运用这些“部署魔法”,让你的Python应用能够在各种环境中稳定运行,为用户提供优质的服务。
附录部分:Python开发的实用资源
-
常见Python库与框架
-
Python工具链与开发环境
-
开源预训练模型的资源库
-
AI与深度学习领域的重要论文与研究资源
-
Python开发者社区与学习资源
-
Python开发中的调试工具与技巧
欢迎来到“Python开发实用资源”的知识宝库!在Python开发的过程中,了解和掌握各种库、框架、工具以及社区资源是至关重要的。这些资源不仅能帮助你更高效地开发应用,还能让你紧跟技术发展的前沿。今天,我们将深入探讨常见的Python库与框架,这些工具是Python开发者日常工作的基石。
F1. 常见Python库与框架
Python拥有丰富且强大的生态系统,涵盖了从数据分析到人工智能,从Web开发到自动化脚本的各个领域。以下是一些在Python开发中常见且广泛使用的库与框架,它们是Python开发者日常工作的基石。
1. 数据科学与数据分析
1.1 NumPy
- 简介:NumPy(Numerical Python)是Python中用于科学计算的基础库,提供了支持大型多维数组和矩阵运算的功能,以及大量的数学函数库。
- 用途:数据处理、数值计算、线性代数、傅里叶变换、随机数生成等。
- 特点:高性能的数组计算,底层实现为C语言,提供了与C/C++和Fortran代码的接口。
- 示例:
import numpy as np array = np.array([1, 2, 3, 4, 5]) print(array.mean()) # 输出: 3.0
1.2 Pandas
- 简介:Pandas是一个强大的数据分析库,提供了数据结构和数据分析工具,如DataFrame和Series。
- 用途:数据清洗、数据分析、数据可视化、时间序列分析等。
- 特点:易于使用的数据操作功能,支持多种数据格式(如CSV、Excel、SQL数据库等)。
- 示例:
import pandas as pd df = pd.DataFrame({'A': [1, 2], 'B': [3, 4]}) print(df)
1.3 Matplotlib
- 简介:Matplotlib是一个用于创建静态、动态和交互式可视化图表的库。
- 用途:数据可视化、绘制各种类型的图表(如折线图、柱状图、散点图、直方图等)。
- 特点:高度可定制,支持多种输出格式(如PNG、PDF、SVG等)。
- 示例:
import matplotlib.pyplot as plt plt.plot([1, 2, 3, 4], [10, 20, 25, 30]) plt.show()
1.4 Seaborn
- 简介:Seaborn是一个基于Matplotlib的高级数据可视化库,提供了更美观的图表和更简便的接口。
- 用途:统计图表绘制、数据探索性分析等。
- 特点:内置多种统计图表样式,支持Pandas数据结构。
- 示例:
import seaborn as sns sns.set(style="whitegrid") tips = sns.load_dataset("tips") sns.boxplot(x="day", y="total_bill", data=tips)
2. Web开发
2.1 Django
- 简介:Django是一个高级的Python Web框架,提供了全面的功能来快速构建Web应用。
- 用途:快速开发Web应用、RESTful API、内容管理系统、企业级应用等。
- 特点:内置用户认证、管理后台、ORM(对象关系映射)、模板引擎等。
- 示例:
from django.http import HttpResponse def hello(request): return HttpResponse("Hello, Django!")
2.2 Flask
- 简介:Flask是一个轻量级的Web框架,提供了简单的核心功能,但具有很高的扩展性。
- 用途:构建小型到中型的Web应用、微服务、RESTful API等。
- 特点:灵活性高,易于扩展,适合微框架爱好者。
- 示例:
from flask import Flask app = Flask(__name__) @app.route('/') def hello(): return "Hello, Flask!"
2.3 FastAPI
- 简介:FastAPI是一个现代、快速(高性能)的Web框架,用于基于标准Python类型提示构建API。
- 用途:构建高性能的Web API、微服务等。
- 特点:自动生成文档、支持异步编程、高性能、内置数据验证和序列化。
- 示例:
from fastapi import FastAPI app = FastAPI() @app.get("/") def read_root(): return {"Hello": "FastAPI"}
3. 机器学习与人工智能
3.1 Scikit-learn
- 简介:Scikit-learn是一个强大的机器学习库,提供了各种监督和无监督学习算法。
- 用途:分类、回归、聚类、降维、模型选择、预处理等。
- 特点:简单易用,文档丰富,支持多种算法和工具。
- 示例:
from sklearn.linear_model import LogisticRegression model = LogisticRegression() model.fit(X_train, y_train) predictions = model.predict(X_test)
3.2 TensorFlow
- 简介:TensorFlow是一个开源的深度学习框架,广泛应用于研究和生产环境。
- 用途:构建和训练深度学习模型、部署模型等。
- 特点:支持分布式训练、强大的计算图、丰富的预训练模型。
- 示例:
import tensorflow as tf model = tf.keras.Sequential([ tf.keras.layers.Dense(10, activation='relu'), tf.keras.layers.Dense(1, activation='sigmoid') ]) model.compile(optimizer='adam', loss='binary_crossentropy') model.fit(X_train, y_train, epochs=5)
3.3 PyTorch
- 简介:PyTorch是一个开源的深度学习框架,以其动态计算图和易用性而闻名。
- 用途:研究和开发深度学习模型、自然语言处理、计算机视觉等。
- 特点:动态计算图、易于调试、广泛的社区支持。
- 示例:
import torch model = torch.nn.Sequential( torch.nn.Linear(10, 10), torch.nn.ReLU(), torch.nn.Linear(10, 1), torch.nn.Sigmoid() ) criterion = torch.nn.BCELoss() optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
4. 自动化与脚本
4.1 Selenium
- 简介:Selenium是一个用于Web应用程序测试的工具,支持多种浏览器和编程语言。
- 用途:自动化Web测试、Web爬虫等。
- 特点:支持多种浏览器驱动,如ChromeDriver、GeckoDriver等。
- 示例:
from selenium import webdriver driver = webdriver.Chrome() driver.get('https://www.example.com') print(driver.title)
4.2 BeautifulSoup
- 简介:BeautifulSoup是一个用于解析HTML和XML文档的库,常用于Web爬虫和数据提取。
- 用途:网页解析、数据抓取等。
- 特点:易于使用,支持多种解析器(如html.parser、lxml、html5lib等)。
- 示例:
from bs4 import BeautifulSoup import requests response = requests.get('https://www.example.com') soup = BeautifulSoup(response.text, 'html.parser') print(soup.title.string)
5. 其他常用库
5.1 Requests
- 简介:Requests是一个简洁且功能强大的HTTP库,用于发送HTTP请求。
- 用途:网络请求、API调用等。
- 特点:简单易用,支持会话、Cookies、文件上传等。
- 示例:
import requests response = requests.get('https://api.example.com/data') print(response.json())
5.2 SQLAlchemy
- 简介:SQLAlchemy是一个强大的SQL工具包和对象关系映射(ORM)库。
- 用途:数据库操作、ORM、数据库迁移等。
- 特点:支持多种数据库,如MySQL、PostgreSQL、SQLite等。
- 示例:
from sqlalchemy import create_engine engine = create_engine('sqlite:///mydatabase.db')
6. 总结
通过了解这些常见的Python库与框架,你可以根据项目需求选择合适的工具,从而提高开发效率和质量。无论是进行数据分析、Web开发,还是机器学习与人工智能,Python的生态系统都能为你提供强大的支持。
F2. Python工具链与开发环境
在Python开发过程中,选择合适的工具链和开发环境对于提高开发效率和代码质量至关重要。工具链涵盖了从代码编辑、版本控制、依赖管理到测试和部署的各个环节。以下是一些常用且功能强大的Python工具链与开发环境,帮助你打造一个高效的开发流程。
1. 代码编辑器与集成开发环境(IDE)
1.1 VS Code(Visual Studio Code)
- 简介:VS Code是由微软开发的一个免费、开源且功能强大的代码编辑器,支持多种编程语言,包括Python。
- 特点:
- 扩展丰富:通过扩展市场,可以安装各种插件,如Python扩展、Debugger for Python、GitLens等。
- 内置终端:方便在编辑器内执行命令和运行脚本。
- 调试功能:支持断点调试、变量监视、调用堆栈查看等。
- 集成Git:内置Git支持,方便版本控制。
- 推荐插件:
- Python:提供代码补全、调试、Linting等功能。
- Pylance:提供快速的类型检查和代码分析。
- Live Share:支持实时协作编程。
1.2 PyCharm
- 简介:PyCharm是由JetBrains开发的专业Python IDE,分为社区版(免费)和专业版(付费)。
- 特点:
- 智能代码补全:基于上下文和类型提示的智能代码补全。
- 强大的调试器:支持断点、变量监视、表达式求值等。
- 集成工具:内置版本控制、数据库工具、测试运行器等。
- Web开发支持:对Django、Flask等Web框架有良好的支持。
- 适用场景:适合需要强大功能和深度集成的专业开发者。
1.3 Sublime Text
- 简介:Sublime Text是一个轻量级但功能强大的代码编辑器,支持多种编程语言。
- 特点:
- 速度快:启动和运行速度快,适合大型项目。
- 可定制性强:通过插件和配置文件,可以高度定制编辑器的功能。
- 多光标编辑:支持多光标操作,提高编辑效率。
- 推荐插件:
- Package Control:管理插件的包管理器。
- Anaconda:提供Python开发所需的工具,如代码补全、Linting等。
1.4 Atom
- 简介:Atom是由GitHub开发的开源代码编辑器,支持多种编程语言。
- 特点:
- 高度可定制:通过插件和主题,可以自定义编辑器的外观和功能。
- 内置Git和GitHub支持:方便版本控制和代码托管。
- 社区驱动:拥有活跃的社区和丰富的插件生态系统。
- 推荐插件:
- script:在编辑器内运行代码。
- autocomplete-python:提供Python代码补全功能。
2. 包管理与依赖管理
2.1 pip
- 简介:pip是Python的官方包管理工具,用于安装和管理Python包。
- 特点:
- 简单易用:通过命令行安装包,如
pip install package_name。 - 版本控制:支持指定包的版本,如
pip install package_name==1.2.3。 - 依赖管理:自动处理包的依赖关系。
- 简单易用:通过命令行安装包,如
2.2 virtualenv
- 简介:virtualenv是一个用于创建独立Python环境的工具,避免不同项目之间的依赖冲突。
- 特点:
- 隔离环境:每个项目可以有独立的包和依赖。
- 易于使用:通过命令行创建和激活虚拟环境。
2.3 Poetry
- 简介:Poetry是一个现代的Python包管理和打包工具,集成了依赖管理和版本控制功能。
- 特点:
- 简洁的配置文件:使用
pyproject.toml文件管理依赖和项目配置。 - 版本管理:支持语义化版本控制和版本冲突解决。
- 构建和发布:方便打包和发布Python包到PyPI。
- 简洁的配置文件:使用
3. 版本控制
3.1 Git
- 简介:Git是一个开源的分布式版本控制系统,广泛应用于软件开发中。
- 特点:
- 分布式架构:每个开发者都有完整的代码库副本。
- 分支管理:支持创建和管理多个分支,方便并行开发和版本控制。
- 协作功能:通过拉取请求(Pull Request)和代码审查(Code Review)促进团队协作。
3.2 GitHub/GitLab/Bitbucket
- 简介:这些是流行的代码托管平台,提供了Git仓库管理、问题跟踪、持续集成等功能。
- 特点:
- 协作功能:支持团队协作、代码审查、项目管理。
- 集成工具:与各种开发工具和平台集成,如CI/CD工具、IDE插件等。
4. 测试与调试
4.1 unittest
- 简介:unittest是Python的内置测试框架,提供了丰富的测试工具和断言方法。
- 特点:
- 简单易用:基于类的测试用例组织方式。
- 内置断言:提供多种断言方法,如
assertEqual,assertTrue等。
4.2 pytest
- 简介:pytest是一个功能强大且易于使用的第三方测试框架,广泛应用于Python社区。
- 特点:
- 简洁的语法:使用
assert语句进行断言,无需学习新的断言方法。 - 插件丰富:支持多种插件,如
pytest-django,pytest-cov等。 - 参数化测试:方便编写参数化的测试用例。
- 简洁的语法:使用
4.3 pdb
- 简介:pdb是Python的内置调试器,可以在代码中设置断点,逐步执行代码,检查变量。
- 特点:
- 命令行界面:通过命令行进行调试操作。
- 断点设置:支持条件断点、临时断点等。
5. 持续集成与持续部署(CI/CD)
5.1 Travis CI
- 简介:Travis CI是一个流行的持续集成平台,支持多种编程语言和版本控制系统。
- 特点:
- 易于配置:使用简单的配置文件(如
.travis.yml)进行设置。 - 集成GitHub:与GitHub紧密集成,方便触发构建和查看结果。
- 易于配置:使用简单的配置文件(如
5.2 GitHub Actions
- 简介:GitHub Actions是GitHub提供的持续集成和持续部署服务。
- 特点:
- 内置于GitHub:无需第三方平台,直接在GitHub仓库中配置。
- 工作流自动化:支持复杂的工作流和任务自动化。
5.3 Jenkins
- 简介:Jenkins是一个开源的自动化服务器,广泛应用于持续集成和持续部署。
- 特点:
- 高度可定制:通过插件和脚本,可以实现复杂的自动化任务。
- 社区支持:拥有庞大的社区和丰富的插件生态系统。
6. 总结
通过了解和使用这些Python工具链与开发环境,你可以构建一个高效的开发流程,提高代码质量和开发效率。无论是选择合适的代码编辑器、管理依赖关系,还是进行版本控制和测试,这些工具都能为你的开发工作提供强大的支持。
F3. 开源预训练模型的资源库
在人工智能和深度学习领域,预训练模型是推动技术进步的重要力量。预训练模型是指已经在大量数据上训练好的模型,可以用于各种下游任务,如图像识别、自然语言处理(NLP)、语音识别等。以下是一些常用的开源预训练模型资源库,这些平台提供了丰富的模型和工具,帮助开发者快速构建和部署AI应用。
1. Hugging Face Transformers
-
简介:
- Hugging Face Transformers 是一个开源的库,提供了大量预训练的深度学习模型,涵盖自然语言处理(NLP)、计算机视觉(CV)等领域。
- 该库支持多种深度学习框架,如 PyTorch、TensorFlow 和 JAX。
-
主要特点:
- 丰富的模型库:包括 BERT、GPT、RoBERTa、T5、ViT 等。
- 易于使用:提供了简单易用的 API,方便加载、微调和部署模型。
- 多语言支持:支持多种语言的预训练模型。
- 社区驱动:拥有活跃的社区和丰富的文档资源。
-
使用示例:
from transformers import BertTokenizer, BertModel # 加载预训练的 BERT tokenizer 和模型 tokenizer = BertTokenizer.from_pretrained('bert-base-uncased') model = BertModel.from_pretrained('bert-base-uncased') # 编码输入文本 inputs = tokenizer("Hello, my dog is cute", return_tensors="pt") # 获取模型输出 outputs = model(**inputs) -
资源链接:
2. TensorFlow Hub
-
简介:
- TensorFlow Hub 是一个由 Google 维护的模型库,提供了大量预训练的 TensorFlow 模型,涵盖图像、文本、音频等多种数据类型。
- 该平台支持模块化组件的复用,方便开发者快速集成预训练模型。
-
主要特点:
- 模块化设计:模型以模块的形式提供,易于集成和复用。
- 多领域支持:包括图像分类、对象检测、文本嵌入、音频处理等。
- 性能优化:模型经过优化,适合在各种硬件平台上运行。
-
使用示例:
import tensorflow as tf import tensorflow_hub as hub # 加载预训练的文本嵌入模型 embed = hub.load("https://tfhub.dev/google/universal-sentence-encoder/4") # 使用模型进行文本嵌入 sentences = ["Hello, world!", "TensorFlow Hub is great."] embeddings = embed(sentences) print(embeddings) -
资源链接:
3. PyTorch Hub
-
简介:
- PyTorch Hub 是由 Facebook 维护的模型库,提供了大量预训练的 PyTorch 模型,涵盖计算机视觉、自然语言处理等领域。
- 该平台旨在简化模型的发布和复用过程,方便开发者快速获取和使用预训练模型。
-
主要特点:
- 简洁的 API:通过
torch.hub.load方法可以轻松加载模型。 - 模型多样性:包括 ResNet、Inception、VGG、BERT、GPT 等。
- 社区驱动:拥有活跃的社区和丰富的模型资源。
- 简洁的 API:通过
-
使用示例:
import torch # 加载预训练的 ResNet-50 模型 model = torch.hub.load('pytorch/vision:v0.10.0', 'resnet50', pretrained=True) # 使用模型进行推理 from PIL import Image from torchvision import transforms img = Image.open("path_to_image.jpg") preprocess = transforms.Compose([ transforms.Resize(256), transforms.CenterCrop(224), transforms.ToTensor(), transforms.Normalize( mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225] ), ]) input_tensor = preprocess(img) input_batch = input_tensor.unsqueeze(0) # 创建 batch 轴 with torch.no_grad(): output = model(input_batch) -
资源链接:
4. OpenMMLab
-
简介:
- OpenMMLab 是一个开源的计算机视觉算法库,提供了大量预训练的模型和工具,涵盖图像分类、对象检测、语义分割、实例分割等领域。
- 该平台支持多种深度学习框架,如 PyTorch 和 TensorFlow。
-
主要特点:
- 丰富的算法库:包括 MMClassification、MMDetection、MMSegmentation 等。
- 模块化设计:各个模块可以独立使用,方便集成到不同的项目中。
- 高性能:模型经过优化,适合在各种硬件平台上运行。
-
使用示例:
from mmdet.apis import init_detector, inference_detector, show_result_pyplot # 加载预训练的检测模型 config_file = 'configs/faster_rcnn/faster_rcnn_r50_fpn_1x_coco.py' checkpoint_file = 'checkpoints/faster_rcnn_r50_fpn_1x_coco_20200130-047c9392.pth' model = init_detector(config_file, checkpoint_file, device='cuda:0') # 进行推理 img = 'path_to_image.jpg' result = inference_detector(model, img) # 显示结果 show_result_pyplot(model, img, result, score_threshold=0.3) -
资源链接:
5. 其他资源库
-
ONNX Model Zoo:
- 简介:ONNX Model Zoo 提供了大量预训练的 ONNX 模型,涵盖图像分类、对象检测、语义分割等领域。
- 资源链接:ONNX Model Zoo GitHub
-
Detectron2:
- 简介:Detectron2 是 Facebook 开发的开源对象检测库,提供了多种预训练的检测模型。
- 资源链接:Detectron2 GitHub
6. 总结
通过了解和利用这些开源预训练模型资源库,你可以快速获取和集成各种先进的AI模型,从而加速你的项目开发。无论是进行自然语言处理、计算机视觉,还是其他AI任务,这些资源库都能为你的开发工作提供强大的支持。
F4. AI与深度学习领域的重要论文与研究资源
在人工智能(AI)和深度学习领域,学术研究和重要论文是推动技术进步的核心驱动力。了解并跟踪该领域的前沿研究和经典论文,对于任何希望深入掌握AI技术的开发者来说都至关重要。以下是一些关键的研究资源、论文集和平台,帮助你获取最新的研究成果和深入理解AI与深度学习的核心概念。
1. arXiv
-
简介:
- arXiv 是一个由康奈尔大学运营的开放获取的学术论文预印本库,涵盖了物理、数学、计算机科学、统计学、定量生物学、定量金融学等多个领域。
- 在AI和深度学习领域,arXiv 是研究人员发布最新研究成果的主要平台。
-
特点:
- 及时性:研究人员通常在正式发表前将论文发布在 arXiv 上,因此可以快速获取最新的研究成果。
- 开放获取:所有论文都可以免费阅读和下载。
- 广泛覆盖:涵盖机器学习、计算机视觉、自然语言处理、强化学习等多个子领域。
-
使用建议:
- 定期浏览 arXiv 的 cs.LG(机器学习)、cs.CV(计算机视觉)、cs.CL(自然语言处理)等分类,获取最新的论文。
- 使用 arXiv Sanity Preserver 等工具来筛选和推荐感兴趣的论文。
-
资源链接:
2. Google Scholar
-
简介:
- Google Scholar 是一个免费的学术搜索引擎,涵盖了来自学术出版商、专业学会、预印本库、大学和其他学术组织的学术文献。
- 它是查找AI和深度学习领域经典论文和最新研究的重要工具。
-
特点:
- 全面性:涵盖广泛的学术资源,包括期刊文章、会议论文、书籍章节、专利等。
- 引用指标:提供论文的引用次数和引用关系,帮助识别高影响力的研究。
- 个性化推荐:根据用户的搜索历史和关注领域,推荐相关的学术文献。
-
使用建议:
- 使用关键词搜索,如“transformer architecture”, “reinforcement learning”, “image segmentation”等。
- 查看高引用次数的经典论文,如“Attention is All You Need”, “Deep Residual Learning for Image Recognition”等。
- 设置邮件提醒,获取特定主题或作者的最新论文。
-
资源链接:
3. Papers with Code
-
简介:
- Papers with Code 是一个将学术论文与开源代码相结合的网站,涵盖了机器学习、计算机视觉、自然语言处理等多个领域。
- 该平台不仅提供论文的链接,还提供代码实现、基准测试结果和排行榜。
-
特点:
- 代码链接:每篇论文都附有相应的代码实现,方便复现和验证研究结果。
- 基准测试:提供各种任务的基准测试结果和排行榜,帮助评估不同方法的性能。
- 社区驱动:拥有活跃的社区,用户可以提交论文、代码和基准测试结果。
-
使用建议:
- 浏览最新的论文和代码实现,了解最新的研究进展。
- 查看特定任务的排行榜,如图像分类、对象检测、机器翻译等,选择性能最佳的方法。
- 参与社区讨论,分享研究成果和经验。
-
资源链接:
4. 经典论文推荐
以下是一些在AI和深度学习领域具有重要影响力的经典论文,涵盖了不同的研究方向和主题:
4.1 深度学习基础
-
"Deep Learning" (Ian Goodfellow, Yoshua Bengio, Aaron Courville)
- 简介:深度学习领域的权威教材,涵盖了深度学习的基本概念、模型、算法和应用。
- 资源链接:在线阅读
-
"ImageNet Classification with Deep Convolutional Neural Networks" (Alex Krizhevsky, Ilya Sutskever, Geoffrey E. Hinton)
- 简介:介绍了AlexNet,一种深度卷积神经网络,在ImageNet大规模视觉识别挑战赛中取得了突破性的成果。
- 资源链接:论文链接
4.2 自然语言处理
-
"Attention is All You Need" (Ashish Vaswani, et al.)
- 简介:提出了Transformer架构,奠定了现代自然语言处理的基础。
- 资源链接:论文链接
-
"BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding" (Jacob Devlin, et al.)
- 简介:介绍了BERT,一种双向Transformer模型,在多种自然语言处理任务上取得了最先进的成果。
- 资源链接:论文链接
4.3 计算机视觉
-
"Deep Residual Learning for Image Recognition" (Kaiming He, et al.)
- 简介:提出了ResNet,一种深度卷积神经网络,解决了深层网络训练中的梯度消失问题。
- 资源链接:论文链接
-
"You Only Look Once: Unified, Real-Time Object Detection" (Joseph Redmon, et al.)
- 简介:介绍了YOLO,一种实时对象检测系统,实现了高速度和良好的准确性。
- 资源链接:论文链接
4.4 强化学习
- "Human-level control through deep reinforcement learning" (Volodymyr Mnih, et al.)
- 简介:介绍了DQN(深度Q网络),在电子游戏领域实现了超越人类的表现。
- 资源链接:论文链接
5. 总结
通过了解和跟踪这些研究资源和经典论文,你可以深入理解AI和深度学习领域的前沿技术和核心概念。希望这些资源能够帮助你在编写《Python开发进阶指南》时更加得心应手,并为你的研究和工作提供有价值的参考。如果你需要继续编写下一节,随时告诉我,我会继续为你提供帮助!
F5. Python开发者社区与学习资源
在Python开发的旅程中,社区和学习资源是你不可或缺的伙伴。无论你是初学者还是有经验的开发者,积极参与社区互动和利用丰富的学习资源,都能帮助你不断提升技能、解决问题并保持对技术发展的敏感度。以下是一些关键的Python开发者社区和学习资源,帮助你更好地学习和成长。
1. 官方文档与资源
1.1 Python官方文档
- 简介:Python的官方文档是学习和参考Python语言特性的权威资源,涵盖了从基础语法到高级特性的全面内容。
- 特点:
- 全面性:详细介绍了Python的内置函数、标准库、语法规则等。
- 更新及时:随着Python版本的更新,文档也会及时跟进。
- 资源链接:
1.2 PEPs (Python Enhancement Proposals)
- 简介:PEPs是Python社区提出的改进建议,涵盖了语言特性、库、标准等方面的提案。
- 特点:
- 权威性:PEPs是Python语言发展的正式提案,具有很高的权威性。
- 历史记录:记录了Python语言发展的历史和未来方向。
- 资源链接:
2. 在线学习平台
2.1 Coursera
- 简介:Coursera是一个知名的在线学习平台,提供了由顶尖大学和机构开设的Python课程。
- 特点:
- 高质量课程:由专家授课,内容系统全面。
- 灵活学习:可以按照自己的节奏学习,部分课程提供认证证书。
- 推荐课程:
2.2 edX
- 简介:edX是一个开源的在线学习平台,提供了来自全球顶尖大学的Python课程。
- 特点:
- 多样化课程:涵盖编程基础、数据科学、人工智能等多个领域。
- 免费学习:部分课程可以免费学习,认证证书需要付费。
- 推荐课程:
2.3 Udemy
- 简介:Udemy是一个提供各种主题在线课程的平台,拥有大量Python相关的课程。
- 特点:
- 价格实惠:经常有折扣和优惠活动。
- 多样化选择:涵盖从初学者到高级开发者的各种课程。
- 推荐课程:
3. 社区与论坛
3.1 Stack Overflow
- 简介:Stack Overflow是一个全球性的开发者问答社区,涵盖了各种编程语言和技术,包括Python。
-
特点:
- 活跃社区:拥有庞大的用户基础和活跃的讨论氛围。
- 高质量回答:许多问题都有详细的解答和示例代码。
-
使用建议:
- 搜索类似问题,避免重复提问。
- 积极参与讨论,分享经验和知识。
-
资源链接:
3.2 Reddit的r/Python
- 简介:Reddit的r/Python是一个大型的Python社区,涵盖了新闻、讨论、问题求助等多个方面。
-
特点:
- 多样化内容:包括教程、新闻、项目展示、问题讨论等。
- 互动性强:用户可以自由发帖和评论,参与讨论。
-
使用建议:
- 关注最新的Python新闻和趋势。
- 参与讨论,分享项目经验。
-
资源链接:
3.3 Python中文社区
- 简介:Python中文社区是一个面向中文用户的Python开发者社区,提供了丰富的资源和交流平台。
- 特点:
- 中文资源:包括教程、文档、问答等,方便中文用户学习和交流。
- 本地化活动:组织线下聚会、技术沙龙等活动,促进社区互动。
- 资源链接:
4. 博客与教程
4.1 Real Python
- 简介:Real Python是一个高质量的Python教程网站,提供了丰富的文章、视频和示例代码。
- 特点:
- 内容丰富:涵盖从基础到高级的各种主题。
- 实用性强:提供实用的编程技巧和项目示例。
- 资源链接:
4.2 Python Weekly
- 简介:Python Weekly是一个每周更新的Python新闻和资源汇总邮件列表,涵盖了最新的文章、教程、项目和工具。
- 特点:
- 及时性:每周更新,紧跟Python社区的最新动态。
- 多样化内容:包括新闻、教程、项目展示、工具推荐等。
- 资源链接:
5. 总结
通过积极参与Python开发者社区和利用丰富的学习资源,你可以不断提升自己的技能,解决开发中遇到的问题,并保持对技术发展的敏感度。希望这些社区和资源能够帮助你在编写《Python开发进阶指南》时更加得心应手,并为你的学习和成长提供有价值的支持。如果你需要继续编写下一节,随时告诉我,我会继续为你提供帮助!
F6. Python开发中的调试工具与技巧
在Python开发过程中,调试是确保代码质量和功能正确性的关键环节。无论是初学者还是有经验的开发者,掌握有效的调试工具和技巧都能帮助你快速定位和解决问题,提高开发效率。以下是一些常用的调试工具和技巧,帮助你更高效地进行代码调试。
1. 内置调试工具
1.1 print语句
- 简介:最简单直接的调试方法,通过在代码中插入
print语句,输出变量的值和程序的执行流程。 -
优点:
- 简单易用:无需额外配置,适合快速检查变量值和程序状态。
- 灵活性高:可以输出任何数据类型的信息。
-
缺点:
- 效率低下:大量使用
print语句会降低代码的可读性。 - 难以管理:需要手动添加和删除
print语句。
- 效率低下:大量使用
-
示例:
def add(a, b): print(f"Adding {a} and {b}") result = a + b print(f"Result: {result}") return result
1.2 logging模块
- 简介:Python的
logging模块提供了更灵活和强大的日志记录功能,可以设置不同的日志级别和输出方式。 - 优点:
- 灵活性高:可以设置不同的日志级别(DEBUG, INFO, WARNING, ERROR, CRITICAL)。
- 可配置性强:可以配置日志输出到文件、控制台、网络等。
- 示例:
import logging # 配置日志 logging.basicConfig(level=logging.DEBUG, format='%(asctime)s - %(levelname)s - %(message)s') def add(a, b): logging.debug(f"Adding {a} and {b}") result = a + b logging.debug(f"Result: {result}") return result
2. 调试器(Debugger)
2.1 pdb
- 简介:pdb是Python的内置调试器,提供了一个命令行界面,可以在代码中设置断点、逐步执行代码、检查变量等。
- 优点:
- 内置工具:无需安装额外的包。
- 功能强大:支持断点设置、逐步执行、变量监视、堆栈跟踪等。
- 使用示例:
import pdb def divide(a, b): pdb.set_trace() # 设置断点 return a / b divide(10, 2)
常用命令:
n(next):执行下一行代码。c(continue):继续执行,直到下一个断点。l(list):查看当前代码上下文。p(print):打印变量值。
2.2 IDE内置调试器
-
VS Code:
- 简介:VS Code的Python扩展提供了强大的调试功能,包括断点设置、逐步执行、变量监视、调用堆栈查看等。
- 使用步骤:
1.设置断点:点击行号左侧,设置断点。
2.启动调试:按F5启动调试模式。
3.逐步执行:使用调试工具栏上的按钮,逐步执行代码。
4.查看变量:在“变量”面板中查看变量的值。
-
PyCharm:
- 简介:PyCharm提供了专业的调试工具,支持断点、逐步执行、变量监视、表达式求值、远程调试等。
- 使用步骤:
1.设置断点:点击行号左侧,设置断点。
2.启动调试:点击调试按钮,选择调试配置。
3.逐步执行:使用调试工具栏上的按钮,逐步执行代码。
4.查看变量:在“变量”窗口中查看变量的值。
3. 高级调试技巧
3.1 使用断点条件
- 简介:在设置断点时,可以添加条件,只有当条件满足时,断点才会生效。
- 示例:
def process(n): pdb.set_trace() # 设置断点 if n > 10: print("n is greater than 10")- 设置条件:在pdb中,可以使用
condition命令设置断点条件。
- 设置条件:在pdb中,可以使用
3.2 调试多线程程序
- 简介:调试多线程程序时,可以使用pdb的
threading模块支持,或者使用IDE的调试工具来管理线程。 - 示例:
import threading import pdb def worker(): pdb.set_trace() # 设置断点 print("Worker thread") thread = threading.Thread(target=worker) thread.start() thread.join()
3.3 使用断言(assert)
- 简介:使用
assert语句在代码中插入断言,检查程序的不变量。 - 示例:
def divide(a, b): assert b != 0, "Division by zero" return a / b
4. 总结
通过掌握这些调试工具和技巧,你可以更高效地发现和解决问题,提高代码的质量和可靠性。无论是使用简单的print语句,还是借助强大的IDE调试器,调试都是开发过程中不可或缺的一部分。希望这些工具和技巧能够帮助你在编写《Python开发进阶指南》时更加得心应手,并为你的调试工作提供有价值的支持。如果你需要继续编写下一章,随时告诉我,我会继续为你提供帮助!

















 1476
1476

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









