






 本文通过分析txhousing数据集,展示了如何利用可视化和统计模型揭示Texas各城市房屋销售随时间变化的趋势,包括对数变换处理量纲差异和季节性影响的消除。通过模型拟合和可视化,作者探讨了城市间的销售模式差异和潜在的季节模式变异系数。
本文通过分析txhousing数据集,展示了如何利用可视化和统计模型揭示Texas各城市房屋销售随时间变化的趋势,包括对数变换处理量纲差异和季节性影响的消除。通过模型拟合和可视化,作者探讨了城市间的销售模式差异和潜在的季节模式变异系数。
Texas房屋数据
接下来使用txhousing数据集来继续探索建模和可视化之间地联系
txhouisng
这个数据由德州农工大学地房地产研究中心所收集。这个数据集包含了Texas城市的数据,记录了房屋销售量(sales)、总销量(volume)、售价平均值(average)、售价中位数(median)、待售房屋数量(listings)、库存月份长短(inventory)。数据实践跨度是2000年1月到2015年4月,每个月记录一次,每个城市有187条记录
准备探究每一个城市随着时间变化销售数量的变化,因为这个分析展示出一些有趣的趋势,提出了一些有趣的挑战。从概况开始,由每个城市的销售数量组成的时间序列如下:
ggplot(txhousing, aes(date, sales)) +
geom_line(aes(group = city), alpha = 1/2)
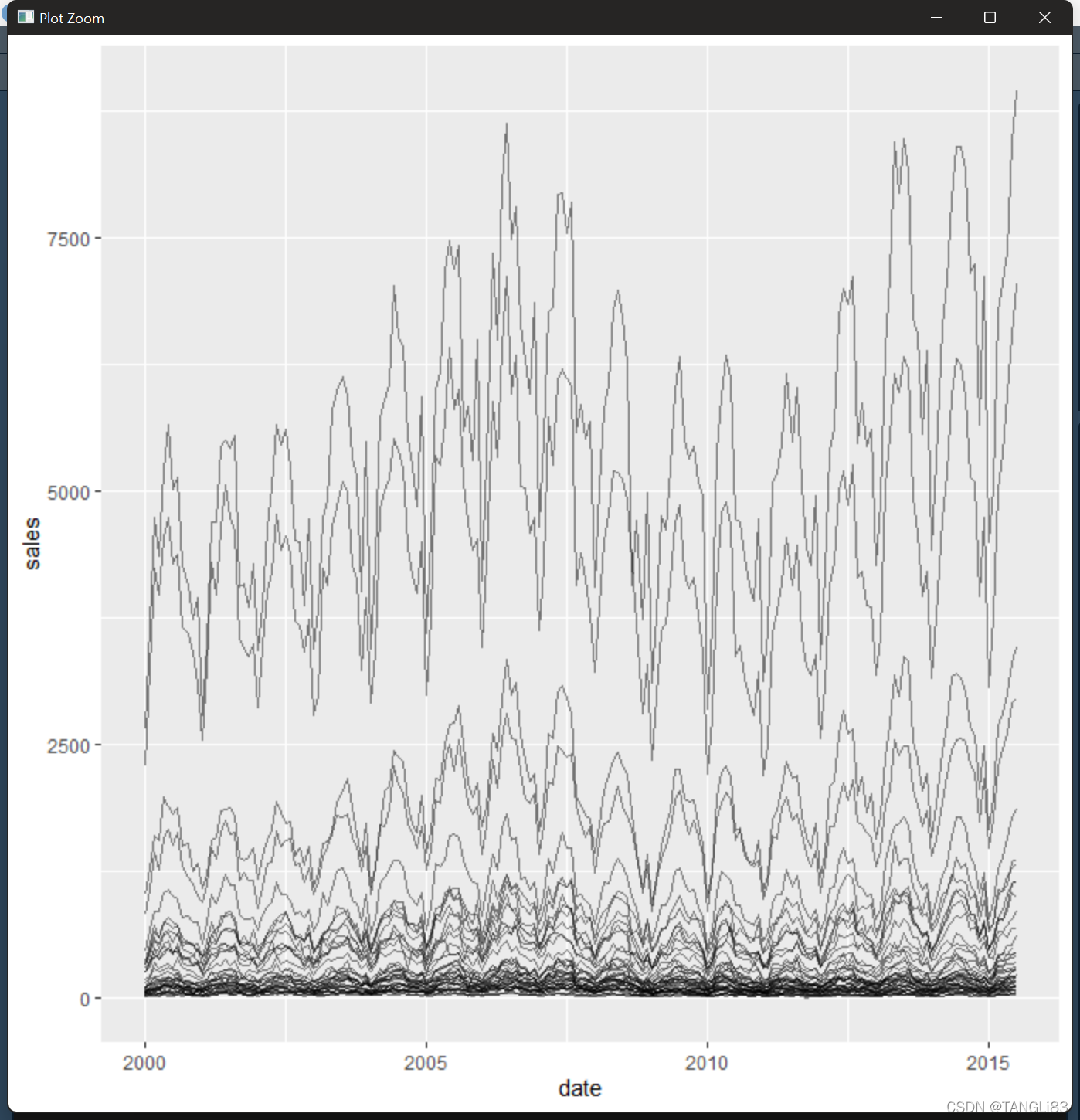
观察图像的长期趋势有两个难点
- 销售数量的范围覆盖了多个量纲。最大的城市Houston平均每个月售出约4000间房屋;而最小的城市San Marcos平均每个月只售出约20间
- 有强大的季节趋势:夏季的销售量比冬季的要高得多
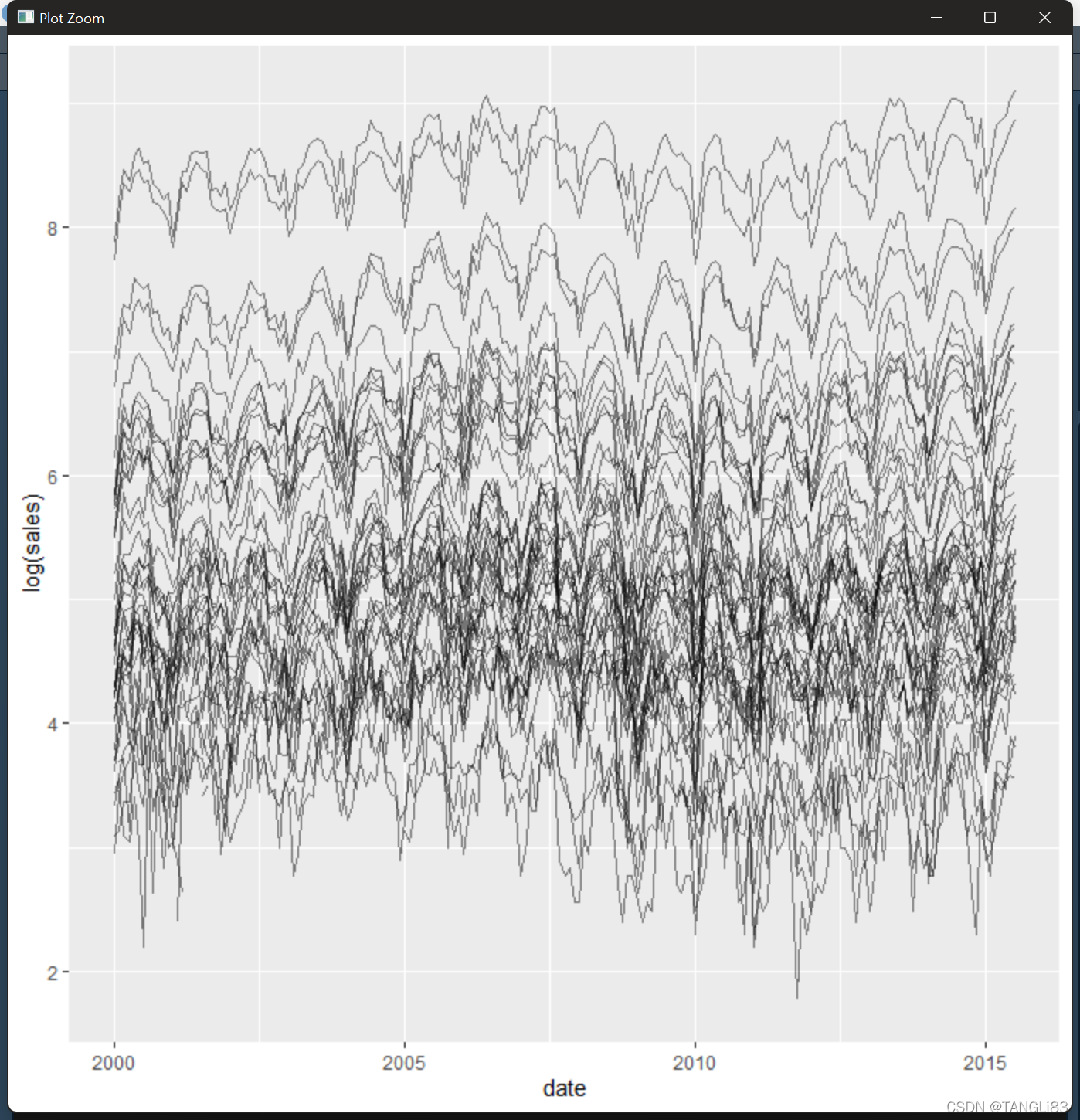
可以画出对数变换后的数据来解决第一个问题
ggplot(txhousing, aes(date, log(sales))) +
geom_line(aes(group = city), alpha = 1/2)
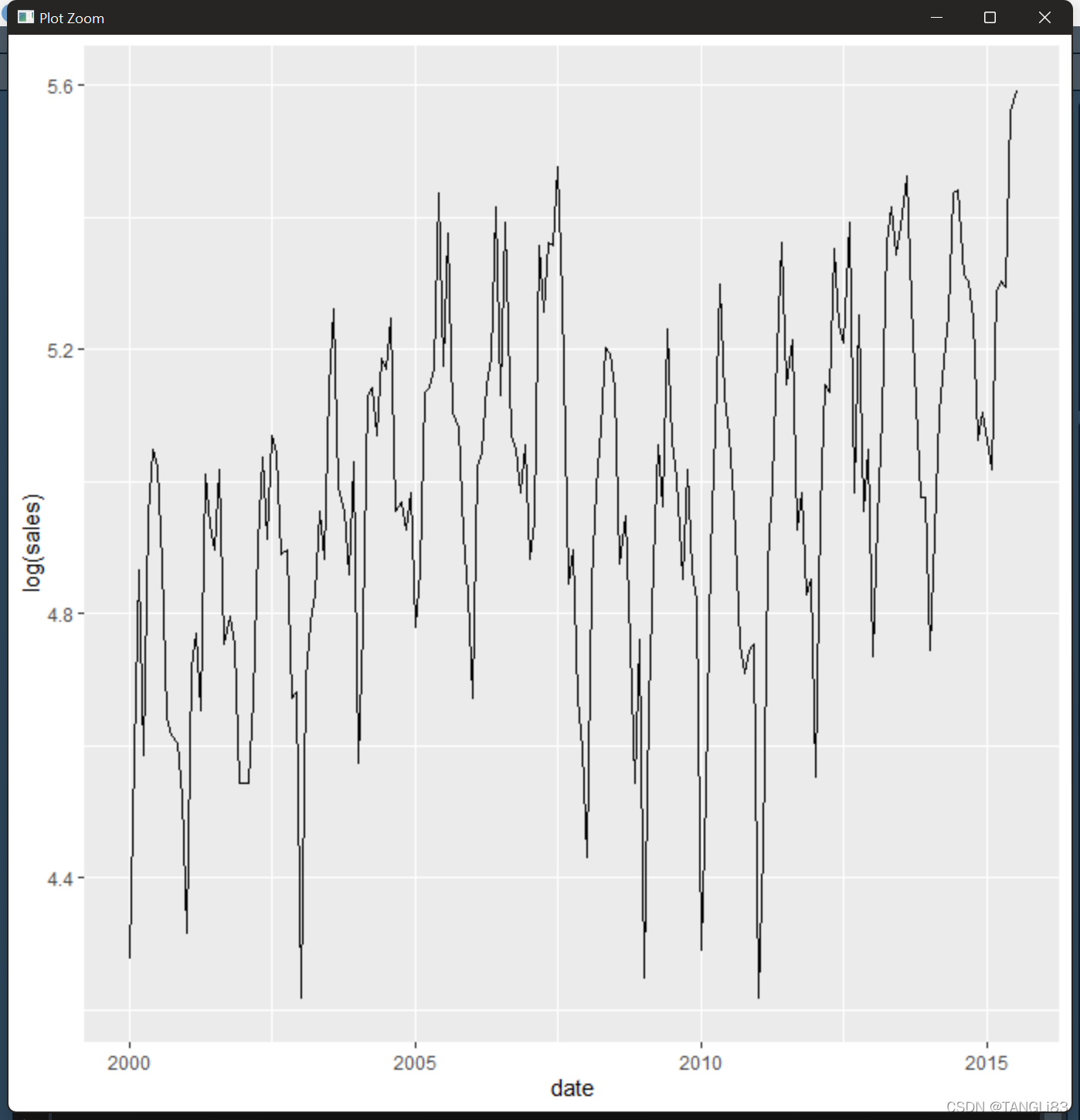
可以使用移除钻石数据趋势的相同技术来解决这里的第二个问题:拟合线性模型然后观察残差值。这次使用分类自变量来移除月份的影响。首先,对单个城市采用此技术,从而验证其有效性。从简单情形出发总是一个好注意,这样的话发生某些错误的时候可以更加容易地查明问题所在
abilene <- txhousing %>% filter(city == "Abilene")
ggplot(abilene, aes(date, log(sales))) + geom_line()
mod <- lm(log(sales) ~ factor(month), data = abilene)
abilene$rel_sales <- resid(mod)
ggplot(abilene, aes(date, rel_sales)) + geom_line()

可用group_by()和mutate()对每个城市都作出这些变换。注意,lm()使用了na.action = na.exclude 参数。尽管有些违反直觉,但是这些参数确保了缺失的输入值能够和缺失的输出预测值和输出残差对应起来。没有这个参数的话,缺失值会被舍弃掉,残差和输入对应不上
deseas <- function(x, month){
resid(lm(x ~ factor(month), na.action = na.exclude))
}
txhousing <- txhousing %>% group_by(city) %>%
mutate(rel_sales = deseas(log(sales), month))
利用这组数据,可以重复对此绘图。现在有了对数变换后的数据,移除了强季节趋势,能看到一个明显的模式:2000年到2007年之间稳定地上升,然后下降到2010年(有一些噪声数据),接下来逐步反弹。为了突出这个模式,加了一条汇总曲线,它展示了所有城市的平均相对销量
ggplot(txhousing, aes(date, rel_sales)) +
geom_line(aes(group = city), alpha = 1/5) +
geom_line(stat = "summary", fun.y = "mean", color = "red")
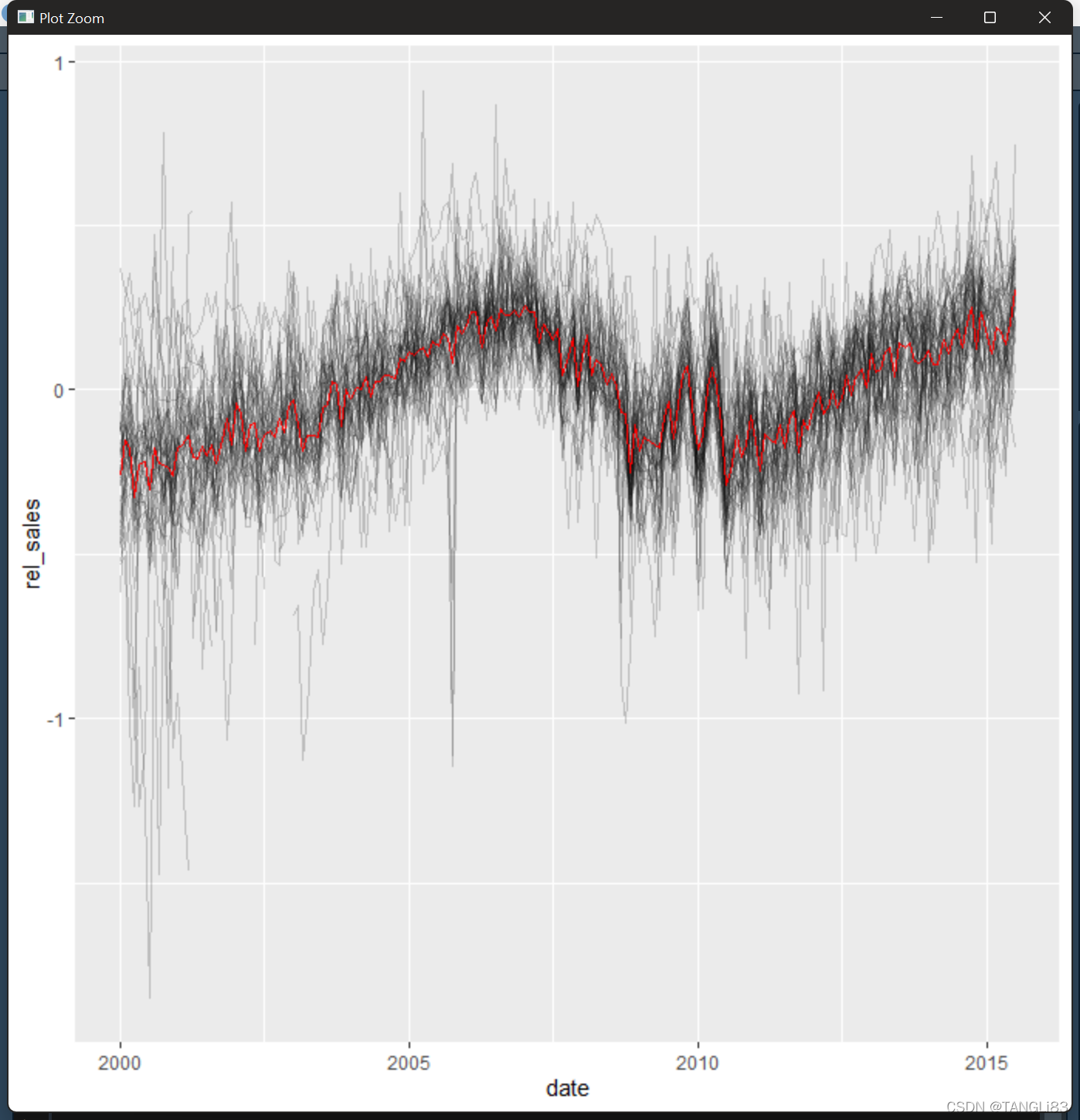
(注意,移除季节效应的同时也移除了截距——图中每个城市的趋势是相对于它的平均销售数量所说的)
对模型可视化
前一个例子只是把线性模型当作移除趋势的工具:拟合出模型,接着立刻丢掉它。并不关心模型本身,只关心它能干什么。但是模型本身其实涵盖了有用的数据,如果保留着它们的话,可以解决很多新的问题
- 对模型拟合效果不好的城市感兴趣:一个拟合效果差的模型意味着没有很明显的季节模式。这违背了隐含的设定:每个城市有着类似的模式
- 系数也可能是有趣的。这个案例里,系数揭示了城市之间季节模式的差异
- 也许想深入研究模型本身的细节,然后关注它对每个观测值所揭示的信息。对于这个数据集,它也许能帮助找到某些反映了数据录入错误的可疑数据点
为了有效利用这个数据,要保存拟合出来的模型。新的dplyr动词do()可用于这一任务。它帮助把任意的计算结果存储在一列里面。这里使用它来存储线性模型结果
models <- txhousing %>% group_by(city) %>% do(mod = lm(log2(scales) ~ factor(month), data = ., na.action = na.exclude))
models
这段代码有两个重点
- do()创建了一列数据,列名mod。这一列有着特殊的类型:它并不是像平常一样的存储着基本类型(逻辑值、整数值、数值或字符值)的向量,而是一个列表。列表是R里面最灵活的数据结构,可存储任意东西,包括线性模型
- .是do()使用到的特殊标记。它用于指代“当前的”数据框。这个例子中,do()拟合了46次模型,每次运算把.换成当前城市的数据
如果对建模比较有经验,也许会好奇为什么没有同时对所有城市拟合单个模型。这是接下来的一大步骤,但简单的起步总是有用的。一旦有了对每个城市都效果良好的模型,就可以搞清楚如何同时扩展到所有的城市上面了
为了可视化这些模型,会把它们转化成整齐的数据框。这里用到David Robinson的broom软件包
library(broom)
Broom提供三个主要动词,每一个对应着上文所述的挑战之一
- glance()提取模型层次的汇总信息,每行数据对应着每个模型。它包含了R2和自由度之类的汇总统计量
- tidy()提取系数层次的汇总信息,每行数据对应着每个模型的每个参数。它包含了拟合值和标准误之类的每个系数的信息
- augment()提取观测层次的汇总信息,每行数据对应着每个模型的每个观测信息。它包含了残差和有助于评估离群值的影响指标之类的变量

















 600
600

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









