







第一部分,利用libSVM自带的简易工具来演示SVM的两类分类过程。(以下内容只是利用libSVM自带的一个简易的工具供大家更好的理解SVM,如果你对SVM已经有了一定的了解,可以直接跳过这部分内容)
首先,你要了解的是libSVM只是众多SVM实现版本中的其中之一。而SVM是一种进行两类分类的分类器,在libSVM最新版(libSVM3.1)里面,已经自带了简单的工具,可以对二分类进行演示。以windows平台为例,将libSVM.zip解压之后,有一个名为windows的子文件夹,里面有一个名为svm-toy.exe的可执行文件。直接双击,运行该可执行文件,显示如下的界面
点击第二个按钮“Run”,然后,在左上部分,用鼠标左键随机点几下,代表你选择的第一类模式的数据分布,下图是我随即点了几下的结果:

之后,点击“Change”,接着,用鼠标左键在窗口右下方随便点击几下,代表你选择的第二类模式的数据分布,如下图所示:
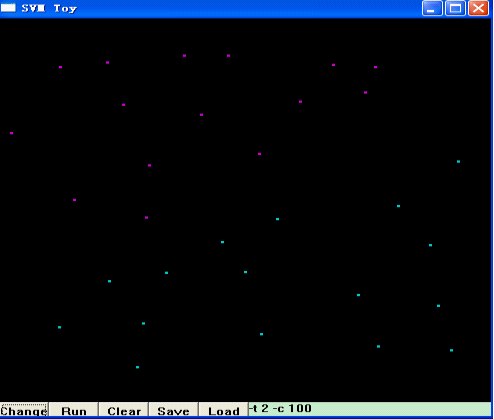
接着,点击“Run”,libSVM就帮你把这两类模式分开了,并用两种不同的颜色区域来代表两类不同的模式,如下图所示:

图中左上方紫色的区域,是第一类模式所在的区域,右下方的蓝色区域,是你选择的第二类模式所在的的区域,而两者的分界面,也就是SVM的最优分类面。当然,SVM是通过核函数将原始数据映射到高维空间,在高维空间进行线性分类。换句话说,在高维空间,这两类数据应该是线性可分的,即:最优分类面应该是一条直线,而这里看到的,是将高维空间分类的结果又映射回原始空间所呈现的分类结果,即:非线性的分类面。细心的朋友可能已经发现,在上述界面的右下角,有一个编辑框,里面写着“-t 2 -c 100”,显然,这是libSVM的一些参数,你也可以试着更改这些参数,来选择不同的核函数、不同的SVM类型等来达到最好的分类效果。
第二部分:libSVM中的小工具
libSVM中包含以下可执行程序文件(小工具):
(1)svm-scale:一个用于对输入数据进行归一化的简易工具
(2)svm-toy:一个带有图形界面的交互式SVM二分类功能演示小工具;
(3)svm-train:对用户输入的数据进行SVM训练。其中,训练数据是按照以下格式输入的:
<类别号> <索引1>:<特征值1> <索引2>:<特征值2>...
(4)svm-predict:根据SVM训练得到的模型,对输入数据进行预测,即分类。
第三部分:libSVM用法介绍:`
libSVM的所有函数申明及结构体定义均包含在libSVM.h文件当中,在使用过程中,你必须要包含该头文件,并且,对libSVM.cpp进行相应的链接。在对libSVM中的函数用法进行详细介绍之前,我们不妨先简单了解一下libSVM.h中一些结构体的含义。
struct svm_node
{
int index;
double value;
};
该结构体,定义了一个“SVM节点”,即:索引i及其所对应的第i个特征值。这样n个相同类别号的SVM节点,就构成了一个SVM输入向量。即:一个SVM输入向量可以表示为如下的形式:
类别标签 索引1:特征值1 索引2:特征值2 索引3:特征值3...
我们可以将若干个这样的输入向量输入到libSVM进行训练,或者,输入一个类别标签未知的向量对其进行预测。
struct svm_problem
{
int l;
double *y;
struct svm_node **x;
};
该结构体中的l代表训练样本的个数;double型指针y代表l个训练样本中每个训练样本的类别号,也就是我们常说的“标签”;而"SVM节点"x,则是一个指针的指针(如果你对指针的指针不熟悉,完全可以把x理解为一个矩阵),x所指向的内容就是所有训练样本所有的特征值数据。
假如我们有下面的训练样本数据:
类别标签 特征值1 特征值2 特征值3 特征值4 特征值5
1 0 0.1 0.2 0 0
2 0 0.1 0.3 -1.2 0
1 0.4 0 0 0 0
2 0 0.1 0 1.4 0.5
1 -0.1 -0.2 0.1 1.1 0.1
那么,svm_problem结构体中的l=5(共有5个训练样本),y=[1,2,1,2,1];指针x所指向的内容可以视为5个行向量,每个行向量有5列,即:x指代一个5*5的矩阵,其值为:
(1,0)(2,0.1)(3,0.2)(4,0)(5,0)(-1,?)
(1,0)(2,0.1)(3,0.3)(4,-1.2)(5,0)(-1,?)
(1,0.4)(2,0)(3,0)(4,0)(5,0)(-1,?)
(1,0)(2,0.1)(3,0)(4,1.4)(5,0.5)(-1,?)
(1,-0.1)(2,-0.2)(3,0.1)(4,1.1)(5,0.1)(-1,?)
需要提醒的是,这里,每一行最后一列都是以“-1”开头,这是libSVM规定的特征值向量的结束标识;此外,索引应该按照升序方式进行排列。
enum { C_SVC, NU_SVC, ONE_CLASS, EPSILON_SVR, NU_SVR };//libSVM规定的SVM类型
enum { LINEAR, POLY, RBF, SIGMOID, PRECOMPUTED };//libSVM规定的核函数的类型
struct svm_parameter
{
int svm_type;//取值为前面提到的枚举类型中的值
int kernel_type;//取值为前面提到的枚举类型中的值
int degree; //用于多项式核函数/
double gamma;//用于多项式、径向基、S型核函数
double coef0;//用于多项式和S型核函数
/* 以下参数仅仅用于训练阶段 */
double cache_size; //核缓存大小,以MB为单位
double eps; //误差精度小于eps时,停止训练
double C; //用于C_SVC,EPSILON_SVR,NU_SVR
int nr_weight; //用于C_SVC
int *weight_label;//用于C_SVC
double* weight;//用于C_SVC
double nu;//用于NU_SVC,ONE_CLASS,NU_SVR
double p;//用于EPSILON_SVR
int shrinking; //等于1代表执行启发式收缩
int probability;//等于1代表模型的分布概率已知
};
该结构体定义了libSVM中的用到的SVM参数。其中svm_type可以是C_SVC, NU_SVC, ONE_CLASS, EPSILON_SVR, NU_SVR中的任意一种,代表着SVM的类型;
C_SVC: C-SVM classification
NU_SVC: nu-SVM classification
ONE_CLASS: one-class-SVM
EPSILON_SVR: epsilon-SVM regression
NU_SVR: nu-SVM regression
kernel_type可以是LINEAR, POLY, RBF, SIGMOID中的一种,代表着核函数的类型;
LINEAR: u'*v,线性核函数;
POLY: (gamma*u'*v + coef0)^degree,多项式核函数;
RBF: exp(-gamma*|u-v|^2),径向基核函数;
SIGMOID: tanh(gamma*u'*v + coef0),S型核函数;
PRECOMPUTED: kernel values in training_set_file,自定义的核函数;
nr_weight, weight_label, and weight这三个参数用于改变某些类的惩罚因子。当输入数据不平衡,或者误分类的风险代价不对称的时候,这三个参数将会对样本训练起到非常重要的调节作用。
nr_weight是weight_label和weight的元素个数,或者称之为维数。Weight[i]与weight_label[i]之间是一一对应的,weight[i]代表着类别weight_label[i]的惩罚因子的系数是weight[i]。如果你不想设置惩罚因子,直接把nr_weight设置为0即可。
为了防止错误的参数设置,你还可以调用libSVM提供的接口函数svm_check_parameter()来对输入参数进行检查。
在使用libSVM进行分类之前,你需要通过样本学习,构建一个SVM分类模型。该分类模型也可以理解为生成一些用于分类的“数据”。当然,构建的分类模型需要保存为文件,以便后续使用。用于libSVM训练的函数,其申明如下所示:
struct svm_model *svm_train(const struct svm_problem *prob, const struct svm_parameter *param);
显然,该函数的输入,就是svm_problem结构体的prob指针所指向的内容。该结构体在前面已经介绍过,其内部,不仅包含了训练样本的个数,还包含每个训练样本的“标签”及该训练样本对应的特征数据。而svm_parameter类型的param指针则指定了libSVM所用到的诸如SVM类型,核函数类型,惩罚因子之类的参数。另外,该函数的返回值是一个svm_model结构体,该结构体的定义,在libSVM.cpp当中:
struct svm_model
{
svm_parameter param; //SVM参数设置
int nr_class; //类别数量,对于regression和ne-class SVM这两种情况,该值为2
int l; //支持向量的个数
svm_node **SV; //支持向量
double **sv_coef; //用于决策函数的支持向量系数
double *rho; //决策函数中的常数项
double *probA; // pariwise probability information
double *probB;
// for classification only
int *label; // 每个类类别标签
int *nSV; //每个类的支持向量个数
int free_sv; //如果svm_model已经通过svm_load_model创建,则该值为1;如果svm_model是通过svm_train创建的,该值为0
};
需要提醒的是,libSVM支持多类分类问题,当有k个待分类问题时,libSVM构建k*(k-1)/2种分类模型来进行分类,即:libSVM采用一对一的方式来构建多类分类器,如下所示:
1 vs 2, 1 vs 3, ..., 1 vs k, 2 vs 3, ..., 2 vs k, ..., k-1 vs k。
用户在得到SVM分类模型之后,需要将其进行保存。在这里,libSVM已经提供了相应的函数接口:
int svm_save_model(const char *model_file_name, const struct svm_model *model);
在调用训练函数之后,只需要指定保存位置,直接调用该函数,就可以进行相应的保存。
在对样本进行训练得到分类模型之后,就可以利用该分类模型对未知输入数据进行类别判断了,也就是我们常说的“预测”。用于libSVM预测的函数,其申明如下所示:
double svm_predict(const struct svm_model *model, const struct svm_node *x);
该函数的第一个参数就是利用样本训练得到的SVM分类模型,第二个参数,是输入的未知模式的特征数据,即:得到了表征某一类别的特征数据,根据这些数据,来判断它所对应的类别标签。而SVM分类模型,可以由libSVM定义的下面这个接口函数来进行加载:
struct svm_model *svm_load_model(const char *model_file_name);
此外,在使用上述函数过程中,需要对svm_model及svm_parameter申请内存,而不使用它们的时候,用户需要调用以下两个函数进行内存释放:
void svm_destroy_model(struct svm_model *model);
void svm_destroy_param(struct svm_parameter *param);















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









