







 本文详细介绍了libSVM的使用,包括自带的svm-toy工具演示SVM分类过程,以及svm-scale、svm-train、svm-predict等工具的使用。讲解了libSVM的结构体svm_node和svm_problem,以及svm_parameter参数设置,帮助理解libSVM的工作原理和调用方式。
本文详细介绍了libSVM的使用,包括自带的svm-toy工具演示SVM分类过程,以及svm-scale、svm-train、svm-predict等工具的使用。讲解了libSVM的结构体svm_node和svm_problem,以及svm_parameter参数设置,帮助理解libSVM的工作原理和调用方式。
鉴于libSVM中的readme文件有点长,而且,都是采用英文书写,这里,我把其中重要的内容提炼出来,并给出相应的例子来说明其用法,大家可以直接参考我的代码来调用libSVM库。
第一部分,利用libSVM自带的简易工具来演示SVM的两类分类过程。(以下内容只是利用libSVM自带的一个简易的工具供大家更好的理解SVM,如果你对SVM已经有了一定的了解,可以直接跳过这部分内容)
首先,你要了解的是libSVM只是众多SVM实现版本中的其中之一。而SVM是一种进行两类分类的分类器,在libSVM最新版(libSVM3.1)里面,已经自带了简单的工具,可以对二分类进行演示。以windows平台为例,将libSVM.zip解压之后,有一个名为windows的子文件夹,里面有一个名为svm-toy.exe的可执行文件。直接双击,运行该可执行文件,显示如下的界面
点击第二个按钮“Run”,然后,在左上部分,用鼠标左键随机点几下,代表你选择的第一类模式的数据分布,下图是我随即点了几下的结果:

之后,点击“Change”,接着,用鼠标左键在窗口右下方随便点击几下,代表你选择的第二类模式的数据分布,如下图所示:
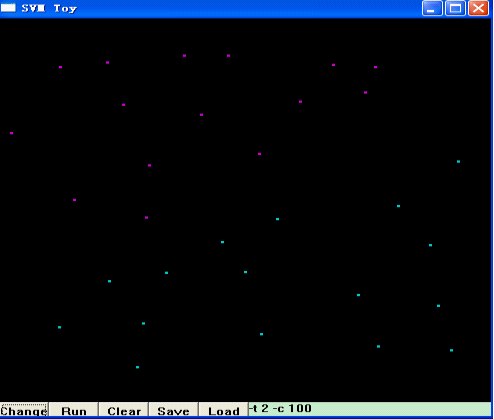
接着,点击“Run”,libSVM就帮你把这两类模式分开了,并用两种不同的颜色区域来代表两类不同的模式,如下图所示:

图中左上方紫色的区域,是第一类模式所在的区域,右下方的蓝色区域,是你选择的第二类模式所在的的区域,而两者的分界面,也就是SVM的最优分类面。当然,SVM是通过核函数将原始数据映射到高维空间,在高维空间进行线性分类。换句话说,在高维空间,这两类数据应该是线性可分的,即:最优分类面应该是一条直线,而这里看到的,是将高维空间分类的结果又映射回原始空间所呈现的分类结果,即:非线性的分类面。细心的朋友可能已经发现,在上述界面的右下角,有一个编辑框,里面写着“-t 2 -c 100”,显然,这是libSVM的一些参数,你也可以试着更改这些参数,来选择不同的核函数、不同的
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









