









【设置网络连接】
首先我们要设置虚拟机NAT方式(自动分配IP地址)连接外网
进行更新源的操作(具体操作见:http://blog.csdn.net/arnold_lee_yc/article/details/74846263)
【安装Mysql】
sudo apt install mysql-server验证是否安装成功
mysql -uroot -pa
show databases;
exit【创建jar包存放目录】
mkdir software
cd ~/software【上传jdk hadoop】
rz【在/目录下创建文件夹】
sudo mkdir mysoftware【更改mysoftware所属】
sudo chown -R hadoop:hadoop mysoftware【进入mysoftware并解压jdk、hadoop】
cd mysoftware
tar -zxvf ~/software/jdk-8u101-linux-x64.tar.gz
tar -zxvf ~/software/hadoop-2.7.3.tar.gz【配置环境变量】
vim ~/.profile
输入以下内容:
export JAVA_HOME=/mysoftware/jdk1.8.0_101
export HADOOP_HOME=/mysoftware/hadoop-2.7.3
export PATH="$JAVA_HOME/bin:$HADOOP_HOME/bin:$HOME/bin:$HOME/.local/bin:$PATH"【重启虚拟机检查是否安装成功】
sudo reboot
javac -version
java -version
hadoop version
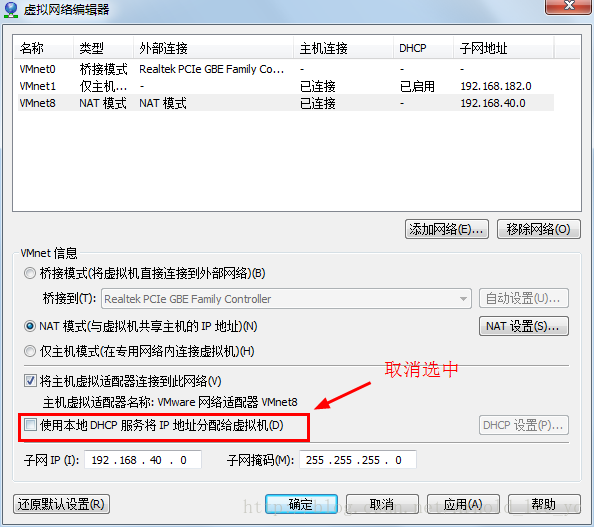
【将ip地址修改为静态ip】
sudo vim /etc/network/interfaces
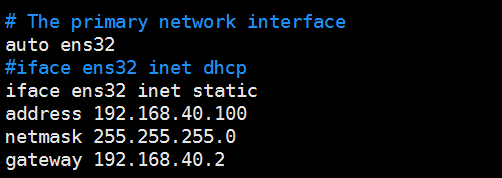
【配置主从机ip地址映射】
sudo vim /etc/hosts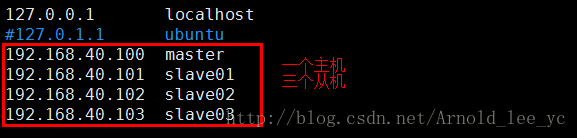
【初始化ssh(便于无密码登录)】
rm -rf .ssh
ssh-keygen -t rsa -P ""
cat id_rsa.pub >> authorized_keys【添加配置信息】
cd /mysoftware/hadoop-2.7.3/etc/hadoop/
vim hadoop-env.sh
输入以下内容:
export JAVA_HOME=/mysoftware/jdk1.8.0_101
vim core-site.xml
输入以下内容:
<configuration>
<!--外部访问hadoopURL-->
<property>
<name>fs.default.name</name>
<value>hdfs://master:9000</value>
</property>
<!--hadoop产生临时文件所存放的位置-->
<property>
<name>hadoop.tmp.dir</name>
<value>file:/mysoftware/hadoop-2.7.3/tmp</value>
</property>
</configuration>
vim hdfs-site.xml
输入以下内容:
<configuration>
<!--文件系统中每一个文件块的重复份数,建议使用奇数份-->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!--文件系统中元数据存放的位置-->
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/mysoftware/hadoop-2.7.3/dfs/name</value>
</property>
<!--文件系统数据块存放的位置,数据块的大小默认是128M-->
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/mysoftware/hadoop-2.7.3/dfs/data</value>
</property>
<!--对文件系统中数据访问时是否进行权限验证,默认true-->
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
cp mapred-site.xml.template mapred-site.xml
vim mapred-site.xml
输入以下内容:
<configuration>
<!--hadoop分布式计算框架的处理交给哪个平台处理-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
vim yarn-site.xml
输入以下内容:
<configuration>
<!--hadoop分布式计算框架的资源调度管理的主机-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<!--hadoop分布式计算框架的资源处理方式-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
vi slaves
输入以下内容:
slave01
slave02
slave03
进入每一个克隆机修改IP地址和主机名
sudo vim /etc/network/interface 配置IPv4 子网掩码 默认网关(网段要和VMnet8的网段一致)
sudo vim /etc/hostname 分别改为slave01 slave02 slave03 【启动hadoop】
第一次启动时执行格式化操作(仅第一次使用时执行,只有再也不用格式化)
hdfs namenode -formatcd /mysoftware/hadoop-2.7.3
sbin/start-yarn.sh查看java进程来确定hadoop是否启动成功
jps看从节点是否会出现datanode
出现代表,hdfs启动成功,否则,表示失败,返回日志查看原因
less logs/hadoop-hadoop-namenode-master.log 查看namenode-master日志信cd ~/data
hdfs dfs -put *.txt / 将data目录下的所有.txt文件上传至hdfs的根目录下sbin/start-yarn.shcd /mysoftware/hadoop-2.7.3/share/hadoop/mapreduce
hadoop jar hadoop-mapreduce-examples-2.7.3.jar wordcount /*.txt /out 统计单词数量
hdfs dfs -cat /out/* 查看结果【关闭hadoop】
cd /mysoftware/hadoop-2.7.3
sbin/stop-yarn.sh 关闭集群资源管理
sbin/stop-dfs.sh 关闭hdfs分布式文件系统【关闭虚拟机】
sudo shutdown -h now














 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









