






0、前言
论文题目:KaFSP: Knowledge-Aware Fuzzy Semantic Parsing for Conversational
Question Answering over a Large-Scale Knowledge Base
论文地址:https://aclanthology.org/2022.acl-long.35.pdf
代码:https://github.com/tjunlp-lab/KaFSP
本文主要关注的问题有两个:
- 语法中定义的动作不足以处理现实世界场景中常见的不确定推理。
- 知识库信息没有被很好地利用和纳入语义解析中。
为了缓解这两个问题,我们提出了一个知识感知的模糊语义解析框架(KaFSP)。它在语法系统中定义了模糊比较操作,用于基于模糊集理论的不确定推理。为了加强语义分析和知识库之间的交互,我们将知识库中的实体三元组融入到一个知识感知的实体消歧模块中。此外,我们还提出了一种多标签分类框架,不仅可以捕捉实体类型和关系之间的相关性,还可以检测与当前话语相关的知识库信息。这两项改进都是基于预训练语言模型。在大规模对话式问答基准上的实验表明,该模型在10个问题类型中有8个问题设置了新的SOTA结果,在3个问题类型上获得了超过10%的F1或正确率,并将整体F1%从83.01%提高到85.33%。
1、引言
虽然在大规模的知识库上的对话式质量保证可以在没有明确的语义解析的情况下实现,但大部分的努力都是致力于探索上下文语义解析器。基于语义解析的方法通常将一个语料投射到可以在给定的知识库上执行的逻辑形式。早期的语义分析方法D2A存在着错误的逐步传播问题,这一点被MaSP所改进,该方法在多任务学习框架中联合学习了配备指针的语义分析和类型意识的实体检测。最近的工作LASAGNE通过一个图注意网络进一步加强了MaSP。一个图注意网络,利用实体类型和关系之间的相关性(在MaSP中缺失),进一步增强了MaSP,并在CSQA基准上取得了最好的效果。
D2A: TODO Flag
MaSP: TODO Flag
LASAGNE: TODO Flag
尽管有了上述的进展,但是目前大规模知识库上问答系统的语义分析方法仍然存在两个关键问题。
- 构成问题到逻辑形式映射的基础的语法规则,尽管在D2A、MASP和千层面中不断更新,但仍然不足以覆盖所有现实世界的情况,例如对数字的模糊推理。考虑这样一个问题:“哪些营养素可以与大约89种化学物质和药物相互作用?”现有的语法很难表示“大约89”。
- 其次,在语义句法分析中,问句与知识库之间的交互不能满足实体消歧和冗余检测的需要。实体消歧和冗余检测不能只靠问句与知识库之间的交互。
再比如说:王刚的母校是那个大学?这样的句子当中包含的实体信息太少,如果遇到重名的王刚,对语义解析来说分很困难的,根本不清楚到底是那个王刚。
为解决上面说的两个关键问题(语法规则表示问题,问句与知识库的交互无法支撑实体消歧),提出了一个知识感知模糊语义解析(KaFSP)模型,以加强语法规则和知识库与语义解析之间的互动。 特别是,我们将模糊操作引入到以前工作中使用的语法系统中,使该系统能够对数字进行不确定性推理。这种改进对回答定量和比较问题有很大影响。为了使知识库很好地促进语义解析,我们将给定知识库中的深层实体知识纳入所提出的语义解析框架的不同模块中。在实体消歧模块中,利用知识库中的实体三元组来消歧候选实体。在实体类型和关系预测模块中,我们提出了一个多标签分类框架,以捕捉实体类型和关系之间的相关性,并确定与当前问句相关的知识库信息。
2、相关工作
语义分析方法通常用于知识库问答(KBQA)。早期的工作通常是通过基于词典的解析将自然语言问题解析成逻辑形式。近年来,见证了语义解析已经从传统的具有特征工程的统计模型转向学习连续表征以生成逻辑形式的神经方法。例如,使用配备了神经注意机制的 encoder-decoder 框架,将语义解析投向 Seq2Seq 生成。
由于知识库越来越大,用于KBQA的语义分析通常是以逐步、模块化的框架进行的。 在第一阶段,识别问题中的实体并将其与给定的大规模知识图谱联系起来(实体链接),然后学习将实体联系起来的问题映射到逻辑形式(语义解析)。提出了一种由粗到精的两阶段语义分析解码方法,该方法在第一阶段为具有低层特征的问题生成粗略的草图,然后根据第一阶段的输出以及问题本身继续解码最终的逻辑形式。Dong and Mirella Lapata 2018 提出了一种由粗到精的两阶段语义分析解码方法,该方法在第一阶段为具有低层特征的问题生成粗略的草图,然后根据第一阶段的输出以及问题本身继续解码最终的逻辑形式。但是这种方法面临着步骤之间的错误传递,为了避免这个问题 Shen et al. (2019) and Kacupajet al. (2021) 等人使用多任务学习框架在单个模型中联合学习实体检测、链接和语义解析。Kacupaj et al. (2021) 使用图注意力网络来学习知识图谱中的实体类型与关系信息。
由于多任务学习在语义句法分析中的优势,我们的工作也是基于多任务学习框架。然而,我们的模型在模糊语法规则和知识感知的实体消歧以及实体类型和关系预测方面都与现有的工作有很大的不同。

3、KaFSP
我们使用多任务学习框架将输入(当前问题与上下文连接)映射为逻辑形式,其中实体被检测并链接到给定的知识库。KaFSP的主干网络与 LASAGNE(Kacupaj et al., 2021)一致,包含 seq2seq 、实体识别模块和图注意力网络。我们的贡献在于模糊语法(fuzzy grammar)(3.1节),知识感知实体消歧模块(3.3节),以及实体类型和关系预测模块(3.4节)。图1中的黑色虚线框中显示了两个知识感知模块。
3.1、模糊语法(Fuzzy Grammar)
在为会话KBQA定制的语义分析方法中,通常定义一个动作数量最少的语法来构造知识库可执行的逻辑形式(即语义分析树)。在之前的语法系统(Guo et al., 2018; Kacupaj et al., 2021)中定义的动作都是一种确定性的操作。而在现实的世界中模糊的概念是很常见的,例如:有多少艺术品的配音人数与另一个大致相同?依靠之前的确定性语法是不能回答这个问题的。LASAGNE 的语法包括一个称为 “大约” 的操作,该操作的目的是执行 “大致相等” 然而,两个数字如何被测量为大致相等并没有定义。因此,我们以 LASAGNE 的语法为起点来构建我们自己的语法,并在语法中加入模糊动作,以使其适应上述现实世界中的模糊问题。
广义钟形函数(a generalized bell-shaped membership function)是神经模糊系统和径向基函数神经网络的一个基本构建模块。用于计算模糊成员值。
广义钟形函数定义如下:
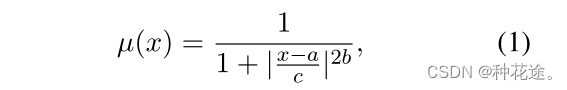
用于计算x与a之间是绝对的相等(结果为1),还是不等(结果为0)。
三个 fuzzy sets,其中
λ
∈
(
0
,
1
]
\lambda \in (0,1]
λ∈(0,1]

3.2 主干网络
-
Encoder and Decoder
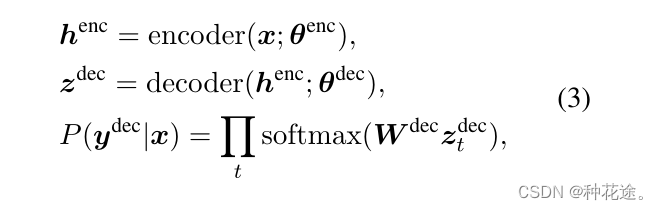
-
Entity Recognition
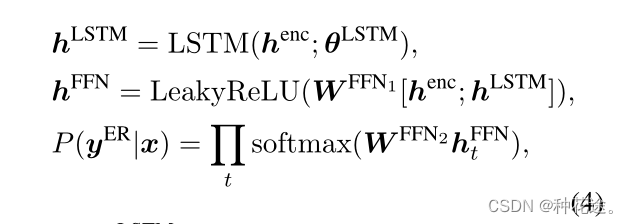
-
Graph Attention Network(GAT)
我们遵循LASAGNE,使用GAT模块来学习知识库中实体类型和他们的关系。它可以被定义为:

详情: Kacupaj et al. (2021) Conversational question answering over knowledge graphs with transformer and graph attention networks.
3.3、实体消歧
在大规模知识库中,具有不同含义的实体具有相同的表现形式是很常见的。预测实体类型有助于区分它们。然而,当候选对象同时具有相同的类型和表现形式时,实体类型预测很难再次区分它们。为了解决这个问题,我们从知识库中纳入了更多关于这些歧义实体的信息,以消除它们的歧义。本文将实体消歧问题建模为二分类问题:
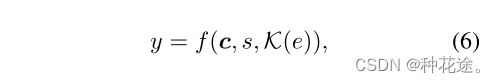
s 是候选实体 e 的表现形式,c 是 e 出现的上下文,k(e) 表示来源于 KB 的候选实体 e 的相关信息(就是一个三元组集合
)。如果 y = 1 ,那么 e 链接的是一个正确的实体。这样做的目的是最大化正样本和负样本。
我们将 e e e 的上下文 k ( e ) k(e) k(e) 作为输入记为 x 。Eq6 中 f f f 是一个用于消歧候选实体的分类器。分类器使用预训练语言模型 XLNet 进行训练。
Xlnet: Generalized autoregressive pretraining for language understanding.
为了将
s
、
c
s、c
s、c和
K
(
e
)
K(e)
K(e)送入预训练和微调的分类器中,我们将它们重组为一个串联的文本序列,各部分由标记 [SEP] 分开。KB 三元组都是用知识库中相应的词来实例化的,其中
e
h
、
r
、
e
t
e_h、r、e_t
eh、r、et是用空白隔开的。首先,将
K
(
e
)
K(e)
K(e) 中的前三个三元组输入到分离器当中,这些三元组已经通过IDs进行排序。这样的选择实际上是知识图覆盖率和内存消耗之间的权衡。如果从知识库中检索到的相关三元组的数量小于3,我们将使用候选实体本身来填充空的三元组。
3.4 实体类型与关系预测
这部分的模块主要执行两个子任务:实体类型和关系的统一识别,以及知识库引导的对堆叠在第一个子任务上的正确实体类型和关系的预测,如图1中的 Type&Relation Prediction module 所示。
我们将类型和关系识别子任务建模为多标签分类任务,并使用分类器从给定的输入序列预测输出序列的概率。
为了获得识别子任务的实体类型和实体关系的神经表示,我们使用了预训练模型 BERT,送入BERT的输入是以类似于实体消歧模块的方式形成的。不同的是,我们用实体类型代替实体。从形式上看,实体类型的神经表示
e
T
e^T
eT的计算方法如下。

其中 [CLS] 表示我们使用之前人工设置的 [CLS] 标记的表示作为实体类型 τ 的表示,s(τ) 和 K(τ) 分别代表 τ 的表达形式和三元组。类似地,关系的神经表征
e
r
e^r
er 被表述为:
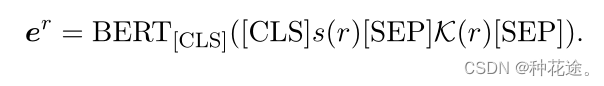
Kacupaj等人(2021)发现,对实体类型和关系之间的关联进行建模对于语义解析至关重要。在我们的KaFSP中,我们使用一个单一的分类器来预测实体类型和关系,而不是使用两个没有共同信息的独立分类器(Shen et al.,2019; Kacupaj et al., 2021)。因此,我们的分类器的预测空间是
T
∪
R
T \cup R
T∪R,entity type 和 relation 之间的相关性自然地被捕获在同一个分类器中。最后使用 sigmod 函数作为输出概率:
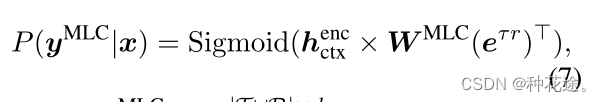
其中,
W
M
L
C
W^{MLC}
WMLC 是一个线性投影矩阵,e 是
τ
∈
T
τ∈T
τ∈T 和
r
∈
R
r∈R
r∈R 的嵌入的串联。KB指导下的实体类型和关系的预测,实际上是利用知识库中的相关信息对其进行最终决策。由于KB包含大量与当前语料u无关的三元组,为了使知识图谱嵌入提供与u相关的信息,我们使用所提出的多标签分类器的输出概率,从GAT编码的知识库中找出相关信息。特别是,我们计算
P
(
y
M
L
C
∣
x
)
P(y^MLC|x)
P(yMLC∣x) 和
h
G
A
T
h^GAT
hGAT 的 Hadamard 乘积。
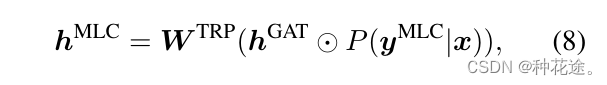
【了解了解思想,后面内容先放一放吧】















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









