







4.多层神经网络优化的一些技巧
在多层神经网络的实战中,很多参数看上去都是由设计人员直观的判断而得到的,例如网络的层数以及各个结点的数量。而诸如权值的初始化,下降梯度的选择,看似不论选择什么样的数值,总会迎来收敛(其区别仅在于收敛速度的快慢)。其实不然,多层神经网络由于其网络的复杂性,其问题往往会变成一个非凸的高维优化问题,这样,在构建高层神经网络的时候就必须注意到收敛速度以及最优解是否会出现的问题。
以下是笔者收集到的一些关于多层神经网络优化时的技巧。
4.1.随机梯度下降
在公式推导中,所得到的梯度为所有样本的一阶导数综合推得的值(batch gradient),在处理大量高维样本时,这样的梯度计算方法往往会因为要遍历所以样本数据得到梯度而表现出极慢的速度。所以在实例中一般使用随机梯度下降(stochastic gradient)。即仅对训练样本集中的一个样本求其梯度,并将此梯度作为全局梯度进行训练。尽管在单个梯度来看,随机选择一个梯度不能很好的代替全局梯度,但是其在统计意义上却能够很好的和整体收敛趋势相吻合。虽然随机梯度下降使得梯度在每一次没有完全和全局梯度一致而减缓了收敛速度,但是其凭借着出色的计算性能可以获得比计算全局梯度更快的速度。而且,使用随机梯度样本可以在一定程度上抑制过拟合问题。对于样本集合的变动也具有更高的适应性。
但是,全局梯度下降也有自身的优势:其可以获得理论意义上的全局最优,也有更多的优化手段可以选择(比如梯度共轭算法就需要使用全局梯度,以及一些二阶导数相关的操作),其在公式推导的意义上也更易于理解)。
所以部分学者综合前两者的优势,提出了最小集合梯度下降(min-batch gradient),在每一次优化使用一个样本集合的子集进行梯度计算,并且在后期逐渐增大集合的大小,以达成较好的收敛性能。
4.1.1随机梯度下降算法的收敛速度
随机梯度下降算法的收敛速度可能是很多学习者存疑的地方,虽然从直观上来理解,随机选择向量所得梯度其“趋势”与全局梯度可以达到近似,实际上这种近似所引入的不确定性和计算全局梯度所付出的代价实际上是一个均衡问题。下面我们援引[2]的文档对随机梯度下降的收敛做一个简单的说明:
- 随机梯度下降的收敛速度被数据集的噪声所制约着。其将影响随机梯度下降方法的性能,尤其是在错误样本较多的情况下,随机梯度下降算法可能会付出比全局梯度下降算法高很多的代价。
- 随机梯度下降算法的性能随着步长的缩减也在下降。因其本来已经是一种全局梯度下降的近似,在步长过小的情况下其性能也可能降低到很低。
4.2.样本标准化与随机选择原则
在随机梯度下降算法中,朴素的思路是完全随机的在样本集合中选择训练样本完成优化。但是从实践而言,网络通常在处理“最特殊”的样本的时候对其训练有着最大的帮助。这样,其实就引出了另外一个问题:如何选取最异常(abnormal)的样本。下面,我们将通过样本规范化的方法来导出一个最异常样本的选取原则。
为了便于计算,首先需要将样本的期望变为0,假设输入样本集合
{Z}∈Rn
,
Zij
表示其第i个样本的第j维,样本数目为m个。这样,对于每个样本:
使其期望变为0。这样,数据集的方差计算就变为了:
可以发现,这时候每个数据对于整体方差的贡献直接与其平方项有关了,这样,只要通过比较每个数据的模,就可以推断出其在数据集合的异常程度。由此,我们获得了选取异常量的一个标准。
但是,样本的各个维度之间可能仍然存在着严重的线性依赖关系,这对于我们训练得到一个良好的模型是不利的。为了消除样本各个维度之间的依赖关系,还需要对其进行更多的处理。KL变换并进行协方差均衡是一种有效的数据处理手段,KL变换将数据的协方差矩阵化为对角阵,此时的数据集合将会沿着几个主轴向量分布,各个维数据的依赖性会降低到最小。此时再使用协方差均衡化,可以使得特征选择的在各个维度都存在相同的标准。其处理流程如图所示。
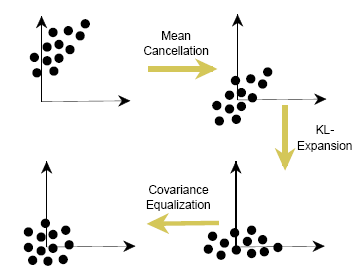
另一方面,样本的标准化是有助于优化系数的。设想一个高维向量,其多个维度都与某一个维度表现出强烈的线性依赖性。这样的数据进行训练的话,实际上会出现较多的没有什么作用的结点,从而增加网络的复杂程度并拖延训练速度。
5.优化系数初始化
5.1.sigmiod函数族
sigmiod函数族即形似S的一组函数,其在机器学习领域有着举足轻重的作用。通常目标的线性分割函数找到之后,需要一个映射函数将其赋予不同的标签。阶跃函数虽然有着很好的标签区分性能,但是其阶跃出难以求导,使其难以在梯度下降框架中进行优化。于是,人们使用sigmiod函数族来替代阶跃函数。常用的sigmiod函数用logist函数 f(x)=11+e−x 以及tanh函数 f(x)=ex−e−xex+e−x 。
5.2.初始值选取
因为激活函数使用了sigmiod函数,故而系数的初始值范围不能够过大,太大的值会使得输出过大,由于sigmiod函数在数值很大的时候函数曲线都趋于平稳,所以此时会得到一个很小的梯度,不利于收敛。所以,系数的初始化需要满足:
- 系数足够大以保证良好的决策性能
- 系数不会过大以确保梯度
在文献[3]中,指出对于tanh函数而言,其初始化系数应该在 [−6fanin+fanout−−−−−−−−−√均匀选择,6fanin+fanout−−−−−−−−−√] 其中 fanin,fanout 为该层的输入、输出结点数目。而对于logist函数来说,其系数区域应该为 [−46fanin+fanout−−−−−−−−−√,46fanin+fanout−−−−−−−−−√] .
5.3.步长选取
对于不同的输入输出结点,理应选择不同的优化步长进行处理。在迭代次数加深的同时缩短步长也是一种有效减少在目标值附近震荡的方法。但是其初始步长的选取依然是令人疑惑的一个问题。首先为了让每次的步长都能够让函数最优下降,我们需要在每次迭代解答
loss(a)=f(xk+αgrad)
的最小化问题,诚然,这是非常费时费力的一种做法。
现在,让我们重新审视梯度迭代公式:
目标函数的泰勒展开为:
取前两项,并且两边对于x求导,有:
假设 x=xmin 使得 df(xmin)dx=0 ,此时有:
可得:
可以发现,当步长为hession矩阵的逆的时候,函数可以达到最有效的下降。而在实际运用中,一般仅计算一次hession来估计应该选取的步长,再逐步降低步长的选择。
6.待解决问题
MLP的缺陷
- 网络的隐含节点个数选取问题至今仍是一个世界难题
在训练过程中,如果网络节点数目不足,会造成表示能力不够从而无法很好的分割出目标,但是当结点数目过多的时候同样会影响训练速度。造成训练难以收敛。所以选择合适数目的结点至关重要,但是现在并没有成熟的理论来指导选择结点的数目,一般来说只有按照计算机的计算性能通过多多益善的思路增加数目来达到良好的训练效果 - 停止阈值、学习率、动量常数需要采用”trial-and-error”法,极其耗时。
尽管在前文我们已经学习了一些系数的优化极其选择方法,仍然有部分系数难以确定其合适的具体数值。同网络结点的数目确定一样,现在一般也还是只有使用试错的方法去不断调整。 - 学习速度慢
学习速度的问题既和硬件条件有关,也和算法的设计有关。在感知机算法刚被发现的几年,人们曾经狂热于感知机算法的优越性,但是很快被多层网络所需要的极大计算量所打败。多年之后,计算机的性能和大数据时代成就了深度学习,但是如今的计算资源依然是有限的。所以我们无法全部仰仗计算机强劲的性能,仍需强大的算法或者新的架构来提升能力。 - 容易陷入局部极值,学习不够充分
由于其表达能力的强大,也似的多层神经网络容易陷入过拟合状态,陷入局部极值并难以摆脱。现代方法中诸如”drop realy”一定程度上改善了这样的情况,但是过拟合的仍然无法完全避免。强劲有力的算法仍等待人们发现。
参考资料
[1] Hornik K, Stinchcombe M, White H. Multilayer feedforward networks are universal approximators[J]. Neural networks, 1989, 2(5): 359-366.
[2] Bottou L. Stochastic gradient descent tricks[M]//Neural Networks: Tricks of the Trade. Springer Berlin Heidelberg, 2012: 421-436.
[3] Glorot X, Bengio Y. Understanding the difficulty of training deep feedforward neural networks[C]//International conference on artificial intelligence and statistics. 2010: 249-256.
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









