






以C语言编写的Key-value键值对存储的NOSQL数据库。
redis五种存储形式:String,Map,Set,Zset,Hash。
五种形式的存储特点:
String:简单的key-value类型,value其实不仅是String,也可以是数字。
Hash:
也就是说,Key仍然是用户ID, value是一个Map,这个Map的key是成员的属性名,value是属性值,这样对数据的修改和存取都可以直接通过其内部Map的Key(Redis里称内部Map的key为field), 也就是通过 key(用户ID) + field(属性标签) 就可以操作对应属性数据了,既不需要重复存储数据,也不会带来序列化和并发修改控制的问题。很好的解决了问题。
这里同时需要注意,Redis提供了接口(hgetall)可以直接取到全部的属性数据,但是如果内部Map的成员很多,那么涉及到遍历整个内部Map的操作,由于Redis单线程模型的缘故,这个遍历操作可能会比较耗时,而另其它客户端的请求完全不响应,这点需要格外注意。
List:(本质上是一个双向链表---->可以变成是一个消息队列),比如twitter的关注列表,粉丝列表等都可以用Redis的list结构来实现。
Set:set是可以自动排重的,提供了求交集、并集、差集等操作,可以非常方便的实现如共同关注、共同喜好、二度好友等功能。
内部实现的是一个 value永远为null的HashMap,实际就是通过计算hash的方式来快速排重的,这也是set能提供判断一个成员是否在集合内的原因。
ZSet:内部是排序的(根据优先级)同时支持去重。
11.1redis持久化机制:
RDB
-
「save」:会阻塞当前 Redis 服务器响应其他命令,直到 RDB 快照生成完成为止,对于内存 比较大的实例会造成长时间阻塞,所以线上环境不建议使用
-
「bgsave」:Redis 主进程会 fork 一个子进程,RDB 快照生成有子进程来负责,完成之后,子进程自动结束,bgsave 只会在 fork 子进程的时候短暂的阻塞,这个过程是非常短的,所以推荐使用该命令来手动触发。
当有新的请求写入时,会执行写时复制的机制。
AOF
AOF会将命令放入到aof_buff中,也会调用fork()函数生成子进程,将内存中的数据先写入到缓冲区中。
当有新的请求需要处理时(写操作),会同时将这个命令追加到APOF缓冲区和AOF重写缓冲区。
-
AOF缓冲区的内容会定期被写入和同步到AOF文件中,对现有的AOF文件的处理工作会正常进行;
-
从创建子进程开始,服务器执行的所有写操作都会被记录到AOF重写缓冲区中;
当子进程完成对AOF文件重写之后,它会向父进程发送一个完成信号,父进程接到该完成信号之后,会调用一个信号处理函数,该函数完成以下工作:
将AOF重写缓存中的内容全部写入到新的AOF文件中;这个时候新的AOF文件所保存的数据库状态和服务器当前的数据库状态一致; 对新的AOF文件进行改名,原子的覆盖原有的AOF文件;完成新旧两个AOF文件的替换。(原来的文件冗余,需要替换)
优缺点:
RDB优点:(1)恢复信息速度快;(2)适合冷备份
缺点:(1)不能实时存储数据;(2)容易发生数据损失
AOF优点:(1)存储信息速度快(近乎秒级);(2)适合热备份
缺点:(1)恢复信息速度慢;(2)存储的信息容量比较大
11.2写时复制技术(在RDB中)
fork是类Unix操作系统上创建进程的主要方法。fork用于创建子进程(等同于当前进程的副本)。
新的进程要通过老的进程复制自身得到,这就是fork! 如果接触过Linux,我们会知道Linux下init进程是所有进程的爹(相当于Java中的Object对象)
Linux的进程都通过init进程或init的子进程fork(vfork)出来的。
从上面我们已经知道了fork会创建一个子进程。子进程的是父进程的副本。
exec函数的作用就是:装载一个新的程序(可执行映像)覆盖当前进程内存空间中的映像,从而执行不同的任务。
-
exec系列函数在执行时会直接替换掉当前进程的地址空间。
在Linux中的COW:
如果按传统的做法,会直接将父进程的数据拷贝到子进程中,拷贝完之后,父进程和子进程之间的数据段和堆栈是相互独立的。
但是,以我们的使用经验来说:往往子进程都会执行exec()来做自己想要实现的功能。
所以,如果按照上面的做法的话,创建子进程时复制过去的数据是没用的(因为子进程执行exec(),原有的数据会被清空) 既然很多时候复制给子进程的数据是无效的,于是就有了Copy On Write这项技术了,原理也很简单:
fork创建出的子进程,与父进程共享内存空间。也就是说,如果子进程不对内存空间进行写入操作的话,内存空间中的数据并不会复制给子进程,这样创建子进程的速度就很快了!(不用复制,直接引用父进程的物理空间)。 并且如果在fork函数返回之后,子进程第一时间exec一个新的可执行映像,那么也不会浪费时间和内存空间了。
Copy On Write技术实现原理:
fork()之后,kernel把父进程中所有的内存页的权限都设为read-only,然后子进程的地址空间指向父进程。当父子进程都只读内存时,相安无事。当其中某个进程写内存时,CPU硬件检测到内存页是read-only的,于是触发页异常中断(page-fault),陷入kernel的一个中断例程。中断例程中,kernel就会把触发的异常的页复制一份,于是父子进程各自持有独立的一份。
Redis中Copy On Write:
在Redis中触发RDB持久化操作:
-
SAVE:在主线程中执行,会导致主线程阻塞
-
BGSAVE:创建一个子进程,专门用于RDB持久化操作,避免了主线程阻塞,这也是Redis的默认配置。
下图为RDB中的写时复制技术示意图:(以BGSAVE为例)
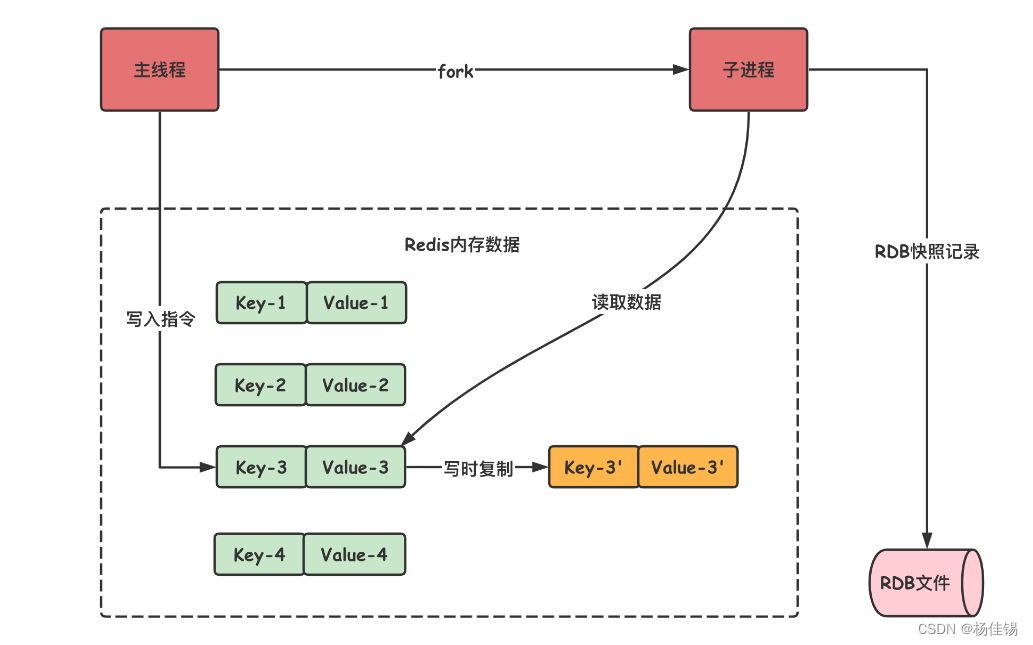
在上图可以看到主线程调用fork()函数生成一个子进程,父子进程都是共享信息的(共享内存),当有写入指令执行时,会将修改的数据复制到额外的空间进行存储,而其他未更改的信息还是共享的。当要存储信息时,子进程会读取共享的内存空间和修改过的数据。避免了要额外开辟空间,提高了效率。但是如果写的操作过多,也会出现内存的消耗,影响效率。















 3780
3780











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









