







光头加跑车,不一定是郭达斯坦森在演速激,也可能是数据分析师在“汽车之家”搞调研。虽然咱买不起豪车,救不了世界,但分析点有意思的东西出来跟其他程序猿侃侃天吹吹牛也还蛮有趣的。

一、 导入数据集
df = pd.read_csv('D:/code_data/virtualization/mtcars.csv')
df.head(5)
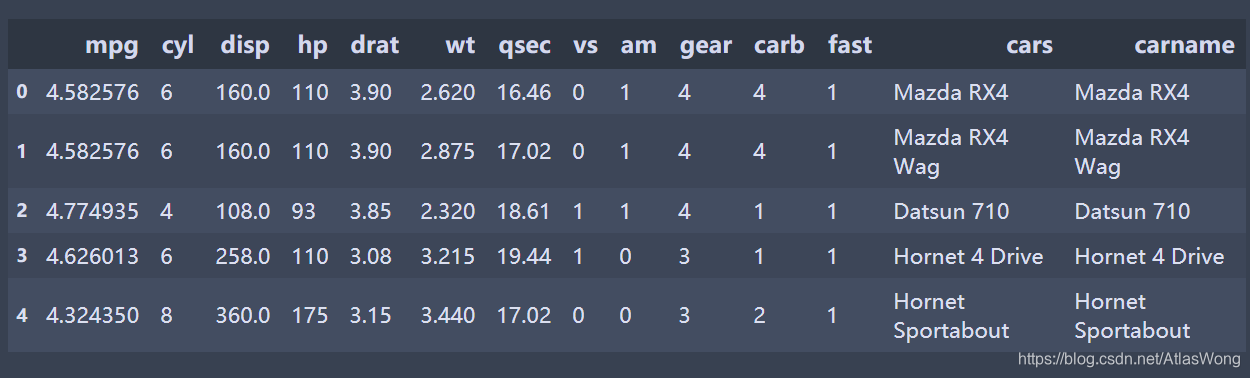
字段解释:
1.mpg:英里每加仑(Miles per gallon) 值越大性能越好,或是能源利用效率更高,或速度较快
2. cyl:气缸数量(Number of cylinders)
3. disp :排量(Displacement)
4.hp:总马力(horsepower)
5.drat:驱动轴比(drive axle ratio)
6.wt:重量(Weight (lb/1000))
7.qsec:1/4英里所用时间(quarter mile time(secend))
8.vs:引擎(0-V shape,1-straight)
9.am:变速器(Transmission,0-automatic,1-manual)
10.gear:前进档数(Number of forward gears) #除了倒挡之外还有几个档
11.carb:化油器数量(Number of carburetors) #内燃机中用于混合空气和液体燃料的精细喷雾的装置。
12.fast: 是否快速(mpg>4 即为1,反之为0)
13.cars:汽车名称
14.carname:汽车名称(与cars完全相同)
二、绘制基本图像
plt.figure(figsize=(12 ,8))
plt.hlines(y=df.cars,xmin=0,xmax=df.mpg
,linewidth=5
,color='red'
,alpha=0.5); #加分号和plt.show()效果一样
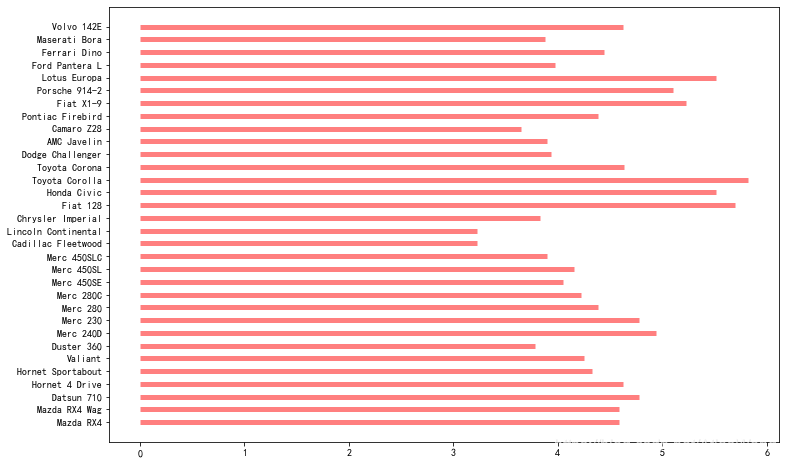
基本图像的数据分布无序且混乱,无法反映哪些汽车的性能在平均水平之上,哪些在平均水平以下,因此需要做标准化处理,使原始数据以标准水平线为中心,按递增顺序呈现。
三、对目标数据进行标准化处理
零-均值规范化也称为标准差标准化,经过处理的数据均值为0,标准差为1,转换公式:(x-原始数据均值)/原始数据标准差。标准差分数可以用来衡量“给定数据距离其均值多少个标准差”,经过标准化处理只是将原始数据进行了线性变换,并没有改变一个数据在该数据中的位置。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 869
869

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









