







一、Kafka核心概念
1. 消息队列的两种模式
1)点对点模式
一个生产者生产的消息由一个消费者进行消费,消费者主动拉取(pull)。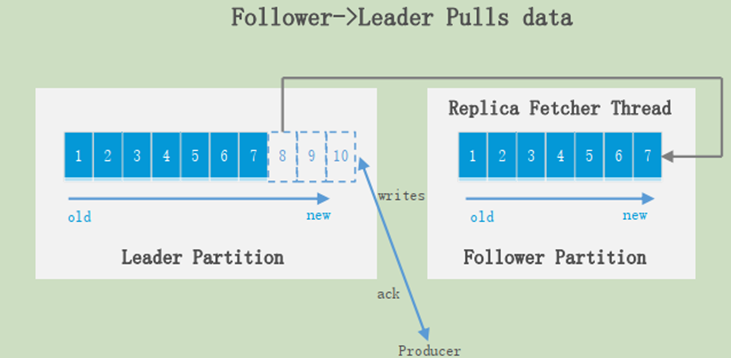
**优点:**消费者自由控制消费频率
**缺点:**消费者无法了解队列中是否有消息,需要另外用线程监控
2)发布-订阅模式
一个生产者或者多个生产者产生的消息能够被多个消费者同时消费的情况,队列将消息推送给消费者(push)。有点类似于订阅公众号,用户订阅之后,公众号有新的内容发布,会主动推送至订阅用户。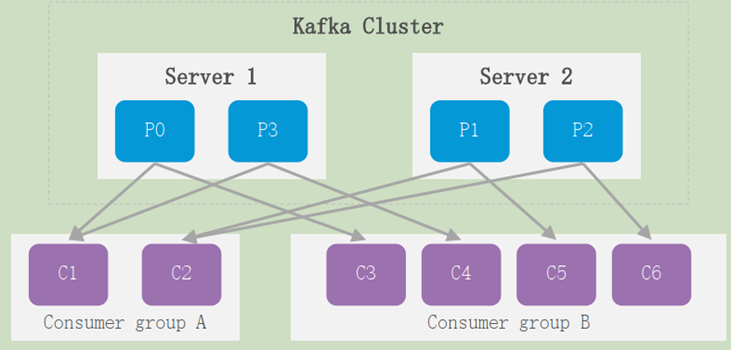
优点 : 有消息生产后,会直接推送给所有的消费者
缺点 : 消费者消费能力不一致
2. 核心概念介绍
- 消息/记录 :Kafka中的数据单元,类似于数据库表中某一行的记录;
- 批次: 一组消息;为了提高效率,消息分批次写入Kafka;
- 主题(Topic):消息的种类,一个主题代表了一类消息;相当于对消息进行分类,类似于数据库中的表;例如将告警信息作为一个topic,每天的告警消息就会存储在此topic;
- 分区(partition): 为了提高Kafka的吞吐量, 物理上把Topic分成一个或多个Partition, 每个Partition都是有序且不可变的消息队列。 每个Partition在物理上对应一个文件夹, 该文件夹下存储这个Partition的所有消息和索引文件。
- 段(Segment) : 将 Partition 进一步细分为若干个 segment,每个 segment 文件的大小相等;
- 生产者(Producer) : 向主题发布消息的客户端应用程序;用于持续不断的向某个主题发送消息;
- 消费者(Consumer) :订阅主题消息的客户端程序;用于处理生产者产生的消息;
- 消费者群组(Consumer Group):指的是由一个或多个消费者组成的群体;生产者与消费者的关系就如同餐厅中的厨师和顾客之间的关系一样,一个厨师对应多个顾客,也就是一个生产者对应多个消费者。
- 偏移量(Consumer Offest):每条消息在文件中的位置称为offset (偏移量), offset是一个long型数字, 它唯一标记一条消息。 消费者通过 (offset、 partition、 topic) 跟踪记录。
- broker :一个独立的Kafka服务器就被称为broker,broker接收来自生产者的消息,为消息设置偏移量,并提交消息到磁盘保存。
- broker集群 :broker 是集群 的组成部分,broker 集群由一个或多个 broker 组成,每个集群都有一个 broker 同时充当了集群控制器的角色(自动从集群的活跃成员中选举出来)。
- 副本(replica) : Kafka 中消息的备份又叫做 副本(Replica),副本的数量是可以配置的,默认副本的最大数量是10个,且副本的数量不能大于Broker的数量,Kafka 定义了两类副本: Leader Replica和 Follower Replica,前者对外提供服务,后者只是被动跟随。
- Controller :kafka集群中的其中一个服务器,用来进行leader election以及各种failover。
- 重平衡(Rebalance): 消费者组内某个消费者实例挂掉后,其他消费者实例自动重新分配订阅主题分区的过程。Rebalance 是 Kafka 消费者端实现高可用的重要手段
二、Kafka架构与工作流程
1. 架构
2. 数据写入
Producer采用push模式将数据发布到broker,每条消息追加到分区中,顺序写入磁盘,所以保证同意分区内的数据是有序的。
Producer永远找Leader,不会直接将数据写入follower;消息写入leader之后,follower会主动去leader进行同步。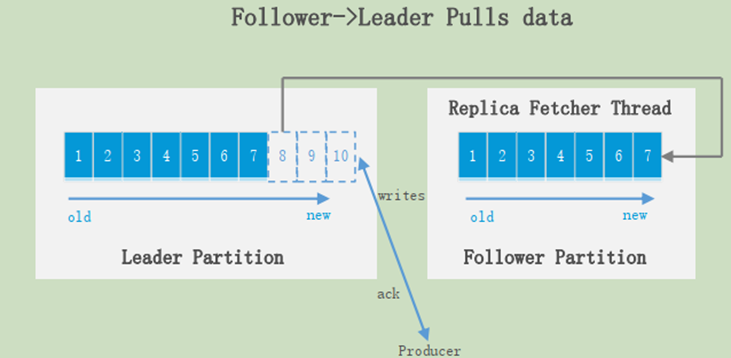
3. 消费数据
Kafka一般采用的为点对点模式,消费者主动找leader去拉取信息。
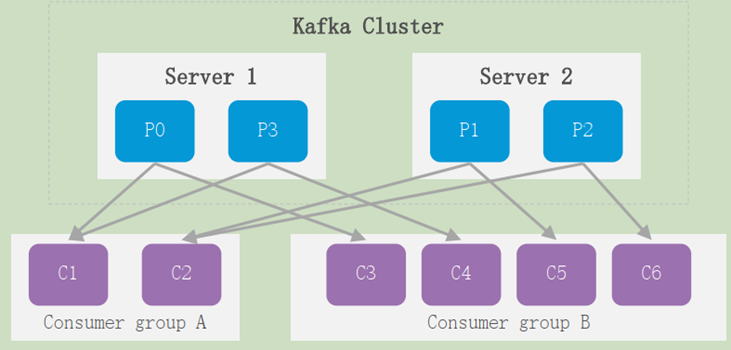
每个consumer 都属于一个consumer group,每条消息只能被consumer group中的一个 consumer消费但可以被多个consumer group消费;即组间数据是共享的,组内数据是竞争的 。
注:
- 当消费者组内的消费者数量小于partition时,会出现一个消费者消费多个partition情况;
- 当消费者组内的消费者数量大于partition时,会出现一个消费者不进行消费;
- 一般建议消费者群组的consumer数量等于partition的数量。
4. Kafka Failover
- 当partition对应的leader宕机时, 需要从follower中选举出新leader。 在选举新leader时,一个基本原则是,新的leader必须拥有旧leader commit过的所有消息;
- 由写入流程可知ISR里面的所有replica都跟上了leader, 只有ISR里面的成员才能选为 leader;
- 对于f+1个replica, partition可以在容忍f个replica失效的情况下保证消息不丢失。
5. 数据存储策略
Kafka把topic中一个partition大文件分成多个小文件段,通过多个小文件段,就容易定期清除或删除已经消费完文件,减少磁盘占用。
无论消息是否被消费,kafka都会保存所有的消息。
- 基于时间,默认配置是168小时(7天)。
- 基于大小,默认配置是1073741824。
配置文件:kafka/config/server.properties
log.retention.hours=168 # 默认消息的最大持久化时间,168小时,7天
message.max.byte=5242880 # 消息保存的最大值5M
6. Kafka和Zookeeper
在分布式系统中,消费者需要知道有哪些broker是可用的,如果每次消费者都需要和生产者建立连接并测试,效率会很低;通过使用zookeeper协调服务,kafka就能将Producer,Consumer,Broker等结合在一起,同时,借助zookeeper,kafka就能够将所有组件无状态的建立生产——消费的订阅关系,实现负载均衡。
具体作用如下:
- broker消息
在 Zookeeper 上会有一个专门用来进行 Broker 服务器列表记录的节点,节点路径为 /brokers/ids。Kafka 的每个 Broker 启动时,都会在 Zookeeper 中注册,创建 /brokers/ids/[0-N] 节点,写入 IP,端口等信息,每个Broker 都有一个 Broker Id。Broker 创建的是临时节点,在连接断开时节点就会自动删除,所以在 Zookeeper 上就可以通过 Broker 中节点的变化来得到 Broker 的可用性。
- Topic信息
在 Kafka 中可以定义很多个 Topic,每个 Topic 又被分为很多个 Partition。一般情况下,每个 Partition 独立存在一个 Broker 上,所有的这些 Topic 和 Broker 的对应关系都由 Zookeeper 进行维护。
- 负载均衡
生产者需要将消息发送给 Broker,消费者需要从 Broker 上获取消息,通过使用Zookeeper,就都能监听 Broker 上节点的状态信息,从而实现动态负载均衡。
- offset信息
offset 用于记录消费者消费到的位置,在老版本(0.9以前)里 offset 是保存在 Zookeeper 中的。新版本由kafka manager管理
- Controller选举
Kafka 的 Controller 选举就依靠 Zookeeper 来完成,成功竞选为 Controller 的 Broker 会在 Zookeeper 中创建 /controller 这个临时节点
三、kafka常用命令
查看topic列表
sh bin/kafka-topics.sh --zookeeper xxxxx:2181 --list
sh bin/kafka-topics.sh --bootstrap-server xxxxx:9092 --list
查看某个topic信息
列出指定topic的partition数量,replica因子以及每个partition的leader、replica信息;
sh bin/kafka-topics.sh --describe --zookeeper xxxxx:2181 --topic xxxxxxx
sh bin/kafka-topics.sh --bootstrap-server xxxxx:9092 --describe xxxxx
从左到右,命令结果参数如下:
- Topic:topic的名字;
- Partition:代表topic的分区数;
- Leader:代表leader 副本所在的broker,101为broker-id;
- Replicas:代表其余副本所在broker,101为broker-id;
- Isr:代表可以选举成为leader的副本,Isr(In-sync)。
使用某topic生产消息
sh bin/kafka-console-producer.sh --broker-list xxxxx:9092 --topic xxxxxxx
消费某个topic消息
sh bin/kafka-console-consumer.sh --zookeeper xxxxx:2181 --topic xxxxxxx (–from-beginning)
sh bin/kafka-console-consumer.sh --bootstrap-server xxxxx:9092 --topic xxxxxxx (–from-beginning)
–from-beginning:代表从头开始消费
查看topic某分区偏移量
sh bin/kafka-run-class.sh kafka.tools.GetOffsetShell --topic test --time -1 --broker-list xxxxx:9092 --partitions 0
创建topic
sh bin/kafka-topics.sh --zookeeper xxxxx:2181 --create --replication-factor 1 --partitions 1 --topic testtest
sh bin/kafka-topics.sh --create --bootstrap-server xxxxx:9092 --replication-factor 1 --partitions 3 --topic testtest
replication-factor: 设置topic的副本因子
partitions: 设置topic的分区数
删除topic
sh bin/kafka-topics.sh --zookeeper xxxxx:2181 --delete --topic test
修改topic的分区数
sh bin/kafka-topics.sh --zookeeper xxxxx:2181 --alter --partitions 10 --topic test_topic
查看消费组列表
sh bin/kafka-consumer-groups.sh --bootstrap-server xxxxxx:9092 --list
查看消费组信息
查看特定consumer group详情:
依次展示group名称、消费的topic名称、partition id、consumer group最后一次提交的offset、最后提交的生产消息offset、消费offset与生产offset之间的差值、当前消费topic-partition的group成员id(不一定包含hostname)。
sh bin/kafka-consumer-groups.sh --bootstrap-server xxxxxx:9092 --describe --group test_group
查看消费组消费进度
sh bin/kafka-run-class.sh kafka.tools.ConsumerOffsetChecker --group group1
删除消费组
sh bin/kafka-consumer-groups.sh --bootstrap-server xxxxxx:9092 --delete --group test_group
调整消费组offset
sh bin/kafka-consumer-groups.sh --bootstrap-server xxxxxx:9092 --group test_group --reset-offsets --topic test_topic --to-latest --execute
重设位移的几种选项:
–to-earliest: 设置到最早位移处,也就是0
–to-latest: 设置到最新处,也就是主题分区HW的位置
–to-offset NUM: 指定具体的位移位置
–shift-by NUM: 基于当前位移向前回退多少
–by-duration: 回退到多长时间
注意:【重设位移必须要停止消费者】查看到GROUP还有在消费其它topic消息,此时直接修改offset会提示如下报错(kafka防护机制),必须要先停掉客户端(以上HOST机器)的GROUP所有的消费才能修改。
“Error: Assignments can only be reset if the group ‘flumeGroup’ is inactive, but the current state is Stable.”
四、配置整理
consumer.properites: 消费者配置,用于配置消费者的配置信息,包括端口,ip
producer.properties: 生产者配置 ,与消费者配置类似
server.properties: kafka服务器的配置,此配置文件用来配置kafka服务器
broker.id :申明当前kafka服务器在集群中的唯一ID,需配置为正整数,并且集群中的每一个kafka服务器的id都应是唯一的,我们这里采用默认配置即可
listeners: 申明此kafka服务器需要监听的端口号,如果是在本机上跑虚拟机运行可以不用配置本项,默认会使用localhost的地址,如果是在远程服务器上运行则必须配置,例如:
listeners=PLAINTEXT://192.168.180.128:9092 并确保服务器的9092端口能够访问
zookeeper.connect 申明kafka所连接的zookeeper的地址 ,需配置为zookeeper的地址。
五、问题记录
1、修改某个topic的保留时间
kafka默认保留7天的临时数据,可以通过以下方式修改保留时间。
1)全局修改方式, 修改配置文件:server.properties
log.retention.hours=72 log.cleanup.policy=delete
2)临时修改方式,针对某个topic进行修改
sh bin/kafka-configs.sh --zookeeper xxxxx:2181 --alter --entity-name testtest --entity-type topics --add-config retention.ms=86400000
retention.ms: 毫秒为单位, 86400000代表一天
3) 立即删除某个topic 的数据sh bin/kafka-topics.sh --zookeeper xxxxx:2181 --alter --topic testtest --config cleanup.policy=delete
















 1264
1264

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











