






参考文献:Pattern Recognition and Machine Learning
Published by Springer | January 2006
https://www.microsoft.com/en-us/research/publication/pattern-recognition-machine-learning/
简介
在前面章节的学习中,已经可以看到如何解决多项式曲线拟合(polynomial curve fitting)的问题,可以采用误差最小(error minimization)的方式。现在从概率的角度(probabilistic perspective)回过头来看曲线拟合的问题,从而获得了一些关于误差函数(error functions)和正则化(regularization)的见解,以及走入一个完整的贝叶斯(Bayesian)处理方式。
曲线拟合
曲线拟合问题的目标是由N个输入值 x = ( x 1 , . . . , x N ) T x=(x_1,...,x_N)^T x=(x1,...,xN)T以及 t = ( t 1 , . . . , t N ) T t=(t_1,...,t_N)^T t=(t1,...,tN)T组成的一组训练数据的基础上,给定一组新的输入变量(input variable) x x x,对目标变量(target variable) t t t进行预测。这里可以使用概率分布(probability distribution)来表示目标变量值的不确定性(uncertainty)。为此,这里假设,给定 x x x的值,与其相应的 t t t值具有高斯分布(Gaussian distribution),其平均值等于(1.1)给出的多项式曲线的值 y ( x , w ) y(x,w) y(x,w)。所以, 可以得出公式(1.60): p ( t ∣ x , w , β ) = N ( t ∣ y ( w , x ) , 1 β ) p(t|x,w, \beta) = \Nu (t|y(w,x),\frac{1}{\beta}) p(t∣x,w,β)=N(t∣y(w,x),β1)
在这里,为了与后面的章节中的符号保持一致,定义了一个精度参数(precision parameter ) β \beta β,它对应于分布的反方差(inverse variance )。图1.16对此进行了示意性说明。

上图为由(1.60)基于给定的
x
x
x给出的
t
t
t的高斯条件分布的示意图,其中平均值由多项式函数
y
(
x
,
w
)
y(x,w)
y(x,w)给出,而精度由参数
β
\beta
β给出,其与方差有关
β
−
1
=
σ
2
\beta-1=\sigma^2
β−1=σ2
最大似然(maximum likelihood)
现在使用训练数据 x , t {x,t} x,t通过最大似然的方式来确定未知参数 w w w和 β \beta β的值。如果假设数据是基于(1.60)公式分布中独立(independently)拉取的,则似然函数为如下公式(1.61): p ( t ∣ x , w , β ) = ∏ n = 1 N N ( t n ∣ y ( x n , w ) , 1 β ) p(t|x,w, \beta) = \displaystyle \prod^{N}_{n=1}{\Nu(t_n|y(x_n,w),\frac{1}{\beta})} p(t∣x,w,β)=n=1∏NN(tn∣y(xn,w),β1)
正如1.2.4中对简单高斯分布所做的那样,将似然函数的对数最大化(maximize the logarithm)是更方便的。替换由(1.46)给出的高斯分布形式,将得到的对数似然函数形式为(1.62):
I
n
p
(
t
∣
x
,
w
,
β
)
=
−
β
2
∑
n
=
1
N
(
y
(
x
n
,
w
)
−
t
n
)
2
)
+
N
2
I
n
β
−
N
2
I
n
(
2
π
)
Inp(t|x,w, \beta) = -\frac{\beta}{2}\displaystyle \sum^{N}_{n=1}{(y(x_n,w)-t_n)^2)}+\frac{N}{2}In\beta-\frac{N}{2}In(2\pi)
Inp(t∣x,w,β)=−2βn=1∑N(y(xn,w)−tn)2)+2NInβ−2NIn(2π)
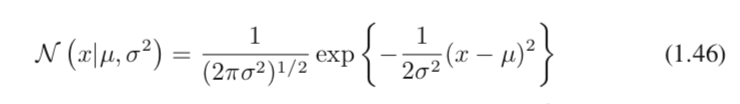
首先考虑确定多项式系数的最大似然解,这将由
w
M
L
wML
wML表示。 这些是通过相对于
w
w
w最大化(1.62)来确定的。 为此,这里可以省略(1.62)右侧的最后两项,因为它们不依赖于
w
w
w。 另外,这里注意到用正常数系数(positive constant coefficient)对数似然度进行缩放不会改变最大值相对于w的位置,因此可以将系数
β
\beta
β替换为1/2。 最后,代替最大化对数似然(log likelihood,),这里可以等效地使负对数似然最小化(minimize the negative log likelihood)。 因此,可以认为,就确定
w
w
w而言,最大似然等效于最小化由(1.2)定义的平方和误差函数(sum-of-squares error function)。 因此,在高斯噪声分布(Gaussian noise distribution)的假设下,平方和误差函数作为使似然最大化的结果而出现。
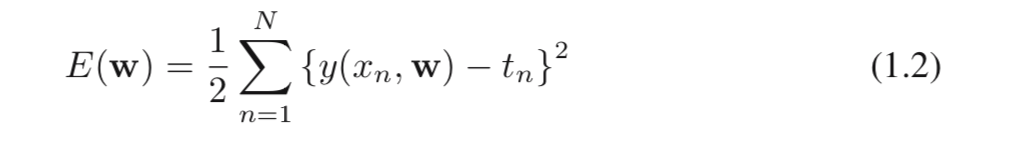
这里还可以使用最大似然来确定高斯条件分布的精度参数β。 相对于 β \beta β最大化(1.62)得到如下公式(1.63): 1 β M L = 1 N ∑ n = 1 N ( y ( x n , w M L ) − t n ) 2 \frac{1}{\beta ML} = \frac{1}{N}\displaystyle \sum^{N}_{n=1}{(y(x_n,wML)-t_n)^2} βML1=N1n=1∑N(y(xn,wML)−tn)2
同样,可以首先确定控制均值的参数向量 w M L wML wML,然后像简单的高斯分布一样使用它来找到精度 β M L \beta ML βML。
确定参数 w w w和 β \beta β后,现在可以预测 x x x的新值。 因为现在有一个概率模型(probabilistic model),并且它们用预测分布(predictive distribution)表示,该预测分布给出了 t t t上的概率分布(probability distribution),这不是简单的点估计,而是通过将最大似然参数代入(1.60)得到如下公式(1.64): p ( t ∣ x , w M L , β M L ) = N ( t ∣ y ( x , w M L ) , 1 β M L ) p(t|x,wML, \beta ML) = \Nu (t|y(x,wML),\frac{1}{\beta ML}) p(t∣x,wML,βML)=N(t∣y(x,wML),βML1)
最大后验(maximum posterior)
现在,迈向一种更加贝叶斯的方法,并介绍多项式系数 w w w的先验分布(prior distribution)。 为简单起见,这里考虑该形式的高斯分布,如下公式(1.65): p ( w ∣ α ) = N ( w ∣ 0 , I α ) = ( α 2 π ) ( M + 1 ) / 2 e x p ( − α 2 w T w ) p(w|\alpha)=\Nu(w|0,\frac{I}{\alpha})=(\frac{\alpha}{2\pi})^{(M+1)/2}exp(-\frac{\alpha}{2}w^Tw) p(w∣α)=N(w∣0,αI)=(2πα)(M+1)/2exp(−2αwTw)
其中 α \alpha α是分布的精度,M + 1是向量(vector) w w w中第M阶多项式的元素总数。 控制模型参数分布的变量(例如 α \alpha α)称为超参数(hyperparameters)。 使用贝叶斯定理, w w w的后验分布(posterior distribution)与先验分布(prior distribution)和似然函数的乘积成比例,如下公式(1.66)展示: p ( w ∣ x , t , α , β ) α p ( t ∣ x , w , β ) p ( w ∣ α ) p(w|x,t,\alpha,\beta) \alpha p(t|x,w,\beta)p(w|\alpha) p(w∣x,t,α,β)αp(t∣x,w,β)p(w∣α)
现在可以通过在给定数据的情况下找到 w w w最可能的值,换句话说,通过最大化后验分布(maximizing the posterior distribution)来确定 w w w。 此技术称为最大后验(maximum posterior),或简称为MAP。 取(1.66)的负对数并与(1.62)和(1.65)组合,发现后验的最大值由如下公式(1.67)的最小值给出: β 2 ∑ n = 1 N ( y ( x n , w ) − t n ) 2 + α 2 w T w \frac{\beta}{2}\displaystyle \sum^{N}_{n=1}{(y(x_n,w)-t_n)^2}+\frac{\alpha}{2}w^Tw 2βn=1∑N(y(xn,w)−tn)2+2αwTw
因此,看到最大化后验分布等效于最小化前面形式(1.4)中遇到的正则化平方和误差函数(regularized sum-of-squares error function),且正则化参数由 λ = α / β \lambda=\alpha/\beta λ=α/β给出。
总结
曲线拟合
- 目标:给定的输入值 x x x以及对应目标变量 t t t - > 建立模型,搭建参数 - > 输入新的输入值 x x x - > 对目标变量 t t t进行预测
- 给定的输入值 x x x以及对应目标变量 t t t具有高斯分布
- 精度参数 β \beta β与方差有关: β − 1 = σ 2 \beta-1=\sigma^2 β−1=σ2
最大似然
- 数据是独立(independently)拉取的 - > 确定未知参数 w w w和 β \beta β的值
- 对数最大化
- 确定 w w w而言,最大似然等效于最小化平方和误差函数
- 首先确定控制均值的参数向量 w M L wML wML,然后像简单的高斯分布一样使用它来找到精度 β M L \beta ML βML
- 确定参数 w w w和 β \beta β - > 概率模型 -> 预测 t t t上的概率分布
- 这不是简单的点估计,而是通过将最大似然参数代入
最大后验
- w w w的先验分布 - > 高斯分布
- α \alpha α是分布的精度;M + 1是向量(vector) w w w中第M阶多项式的元素总数
- 超参数(hyperparameters):控制模型参数分布的变量
- w w w的后验分布 与 先验分布和似然函数的乘积 成比例
- 最大化后验分布 (MAP) - > 找到 w w w最可能的值
- 最大化后验分布等效于最小化正则化平方和误差函数;正则化参数 λ = α / β \lambda=\alpha/\beta λ=α/β















 279
279











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









